Още през март започнах серия за широко разпространените митове за производителността в SQL Server. Едно убеждение, с което се сблъсквам от време на време, е, че можете да оразмерите колоните varchar или nvarchar без никакво наказание.
Да предположим, че съхранявате имейл адреси. В предишен живот се занимавах доста с това – по това време RFC 3696 гласи, че имейл адресът може да бъде 320 знака (64 символа@255 символа). По-нов RFC, #5321, вече признава, че 254 знака е най-дългият имейл адрес. И ако някой от вас има толкова дълъг адрес, може би трябва да поговорим. :-)
Сега, независимо дали използвате стария стандарт или новия, трябва да поддържате възможността някой да използва всички разрешени знаци. Което означава, че трябва да използвате 254 или 320 знака. Но това, което видях хората да правят, е изобщо да не си правят труда да изследват стандарта и просто да приемат, че трябва да поддържат 1000 знака, 4000 знака или дори повече.
Така че нека да разгледаме какво се случва, когато имаме таблици с колона за имейл адрес с различен размер, но съхраняващи същите данни:
СЪЗДАВАНЕ НА ТАБЛИЦА dbo.Email_V320( id int ИДЕНТИФИКАЦИЯ ПЪРВИЧЕН КЛЮЧ, имейл varchar(320)); СЪЗДАВАНЕ НА ТАБЛИЦА dbo.Email_V1000( id int ИДЕНТИФИКАЦИЯ ПЪРВИЧЕН КЛЮЧ, имейл varchar(1000)); СЪЗДАВАНЕ НА ТАБЛИЦА dbo.Email_V4000( id int ИДЕНТИФИКАЦИЯ ПЪРВИЧЕН КЛЮЧ, имейл varchar(4000)); СЪЗДАЙТЕ ТАБЛИЦА dbo.Email_Vmax( id int ИДЕНТИФИКАЦИЯ ПЪРВИЧЕН КЛЮЧ, имейл varchar(max));
Сега нека генерираме 10 000 фиктивни имейл адреса от системните метаданни и да попълним всичките четири таблици със същите данни:
INSERT dbo.Email_V320(email) SELECT TOP (10000) REPLACE(LEFT(LEFT(c.name, 64) + '@' + LEFT(o.name, 128) + '.com', 254), ) ', '') ОТ sys.all_columns КАТО c ВЪТРЕШНО ПРИСЪЕДИНЕНЕ sys.all_objects КАТО o ON c.[object_id] =o.[object_id] INNER JOIN sys.all_columns КАТО c2 ON c.[object_id] =c2.[object_id] ПОРЪЧКА. ОТ NEWID(); INSERT dbo.Email_V1000(email) SELECT email FROM dbo.Email_V320;INSERT dbo.Email_V4000(email) SELECT email FROM dbo.Email_V320;INSERT dbo.Email_Vmax (email) SELECT email FROM dbo.Email_V320 -- нека да променим ИНДЕКС ВСИЧКИ НА dbo.Email_V320 REBUILD; ПРОМЕНИ ИНДЕКС ВСИЧКИ НА dbo.Email_V1000 REBUILD; ПРОМЕНИ ИНДЕКС ВСИЧКИ НА dbo.Email_V4000 REBUILD; ПРОМЕНИ ИНДЕКС ВСИЧКИ НА dbo.Email_Vmax За да потвърдите, че всяка таблица съдържа точно еднакви данни:ИЗБЕРЕТЕ AVG(LEN(имейл)), MAX(LEN(имейл)) ОТ dbo.Email_; И четирите от тях дават 35 и 77 за мен; вашият пробег може да варира. Нека също така се уверим, че и четирите таблици заемат еднакъв брой страници на диска:
ИЗБЕРЕТЕ o.name, COUNT(p.[object_id]) ОТ sys.objects КАТО o КРЪСТО ПРИЛОЖИ sys.dm_db_database_page_allocations (DB_ID(), o.object_id, 1, NULL, 'LIMITED') КАТО p КЪДЕ o.name. ХАРЕСАЙТЕ N'Email[_]V[^2]%' GROUP BY o.name;И четирите от тези заявки дават 89 страници (отново пробегът ви може да варира).
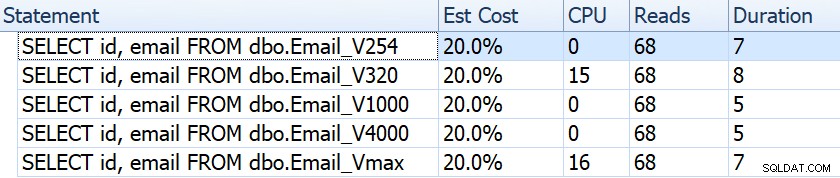
Сега, нека вземем типична заявка, която води до сканиране на клъстерен индекс:
ИЗБЕРЕТЕ идентификатор, имейл ОТ dbo.Email_; Ако разгледаме неща като продължителност, четене и прогнозни разходи, всички те изглеждат еднакви:
Това може да приспи хората в погрешно предположение, че изобщо няма влияние върху производителността. Но ако погледнем малко по-отблизо, в подсказката за клъстерното сканиране на индекс във всеки план виждаме разлика, която може да влезе в игра при други, по-сложни заявки:
От тук виждаме, че колкото по-голяма е дефиницията на колоната, толкова по-голям е прогнозният размер на реда и данните. В тази проста заявка цената на I/O (0,0512731) е една и съща за всички заявки, независимо от дефиницията, тъй като сканирането на клъстерирания индекс трябва да прочете всички данни така или иначе.
Но има и други сценарии, при които този приблизителен ред и общият размер на данните ще имат влияние:операции, които изискват допълнителни ресурси, като сортиране. Нека вземем тази нелепа заявка, която не служи на никаква реална цел, освен да изисква множество операции за сортиране:
SELECT /* V*/ ROW_NUMBER() НАД (РАЗДЕЛЯНЕ ПО имейл ПОРЪЧКА ПО имейл DESC), имейл, REVERSE(email), SUBSTRING(email, 1, CHARINDEX('@', email)) ОТ dbo .Email_V GROUP BY REVERSE(имейл), имейл, SUBSTRING(email, 1, CHARINDEX('@', имейл)) ПОРЪЧАЙТЕ ОБРАТ (имейл), имейл; Изпълняваме тези четири заявки и виждаме, че всички планове изглеждат така:
Въпреки това, тази предупредителна икона на оператора SELECT се появява само в таблиците 4000/max. Какво е предупреждението? Това е предупреждение за прекомерно предоставяне на памет, въведено в SQL Server 2016. Ето предупреждението за varchar(4000):
И за varchar(max):
Нека погледнем малко по-отблизо и да видим какво се случва, поне според sys.dm_exec_query_stats:
SELECT [таблица] =SUBSTRING(t.[текст], 1, CHARINDEX(N'*/', t.[текст])), s.last_elapsed_time, s.last_grant_kb, s.max_ideal_grant_kbFROM sys.dm_exec_query_stats AS s s. КРЪСТО ПРИЛОЖИ sys.dm_exec_sql_text(s.sql_handle) КАТО tWHERE t.[text] LIKE N'%/*%dbo.'+N'Email_V%' ПОРЪЧАЙТЕ ПО s.last_grant_kb;Резултати:
В моя сценарий продължителността не беше повлияна от разликите в предоставянето на памет (с изключение на максималния случай), но можете ясно да видите линейната прогресия, която съвпада с декларирания размер на колоната. Което можете да използвате, за да екстраполирате какво би се случило на система с недостатъчно памет. Или по-сложна заявка срещу много по-голям набор от данни. Или значително паралелност. Всеки от тези сценарии може да изисква разливи, за да се обработят операциите по сортиране, и продължителността почти сигурно ще бъде засегната в резултат.
Но откъде идват тези по-големи дарения за памет? Не забравяйте, че това е същата заявка срещу същите данни. Проблемът е, че за определени операции SQL Server трябва да вземе предвид колко данни *може да има* в колона. Той не прави това въз основа на действително профилиране на данните и не може да прави никакви предположения въз основа на стойностите на стъпката <=201 на хистограмата. Вместо това трябва да изчисли, че всеки ред съдържа стойност, половината от декларирания размер на колоната . Така че за varchar(4000), той приема, че всеки имейл адрес е дълъг 2000 знака.
Когато не е възможно да имате имейл адрес, по-дълъг от 254 или 320 знака, няма какво да спечелите от преоразмеряването и има какво потенциално да загубите. Увеличаването на размера на колона с променлива ширина по-късно е много по-лесно, отколкото да се справяте с всички недостатъци сега.
Разбира се, оразмеряване на
charилиncharколоните могат да имат много по-очевидни наказания.