Миналата седмица представих моята сесия T-SQL:лоши навици и най-добри практики по време на конференцията GroupBy. Видео повторение и други материали са достъпни тук:
- T-SQL:Лоши навици и най-добри практики
Един от елементите, които винаги споменавам в тази сесия, е, че обикновено предпочитам GROUP BY пред DISTINCT, когато премахвам дубликати. Въпреки че DISTINCT обяснява по-добре намерението, а GROUP BY се изисква само когато има агрегирания, те са взаимозаменяеми в много случаи.
Нека започнем с нещо просто, използвайки Wide World Importers. Тези две заявки дават един и същ резултат:
SELECT DISTINCT Description FROM Sales.OrderLines; SELECT Description FROM Sales.OrderLines GROUP BY Description;
И всъщност извличат резултатите си, като използват точно същия план за изпълнение:

Същите оператори, еднакъв брой четения, незначителни разлики в процесора и общата продължителност (те се редуват „печеливши“).
Така че защо бих препоръчал използването на по-дългия и по-малко интуитивен синтаксис GROUP BY вместо DISTINCT? Е, в този прост случай това е хвърляне на монета. Въпреки това, в по-сложни случаи, DISTINCT може да свърши повече работа. По същество DISTINCT събира всички редове, включително всички изрази, които трябва да бъдат оценени, и след това изхвърля дубликати. GROUP BY може (отново, в някои случаи) да филтрира дублиращите се редове преди извършване на която и да е от тази работа.
Да поговорим за агрегирането на низове, например. Докато в SQL Server v.Next ще можете да използвате STRING_AGG (вижте публикациите тук и тук), останалите трябва да продължим с FOR XML PATH (и преди да ми кажете колко невероятни рекурсивни CTE са за това, моля прочетете и тази публикация). Може да имаме заявка като тази, която се опитва да върне всички поръчки от таблицата Sales.OrderLines, заедно с описания на артикули като разделен с черти списък:
SELECT o.OrderID, OrderItems = STUFF((SELECT N'|' + Description FROM Sales.OrderLines WHERE OrderID = o.OrderID FOR XML PATH(N''), TYPE).value(N'text()[1]', N'nvarchar(max)'),1,1,N'') FROM Sales.OrderLines AS o;
Това е типична заявка за решаване на този вид проблем със следния план за изпълнение (предупреждението във всички планове е само за имплицитното преобразуване, излизащо от филтъра XPath):
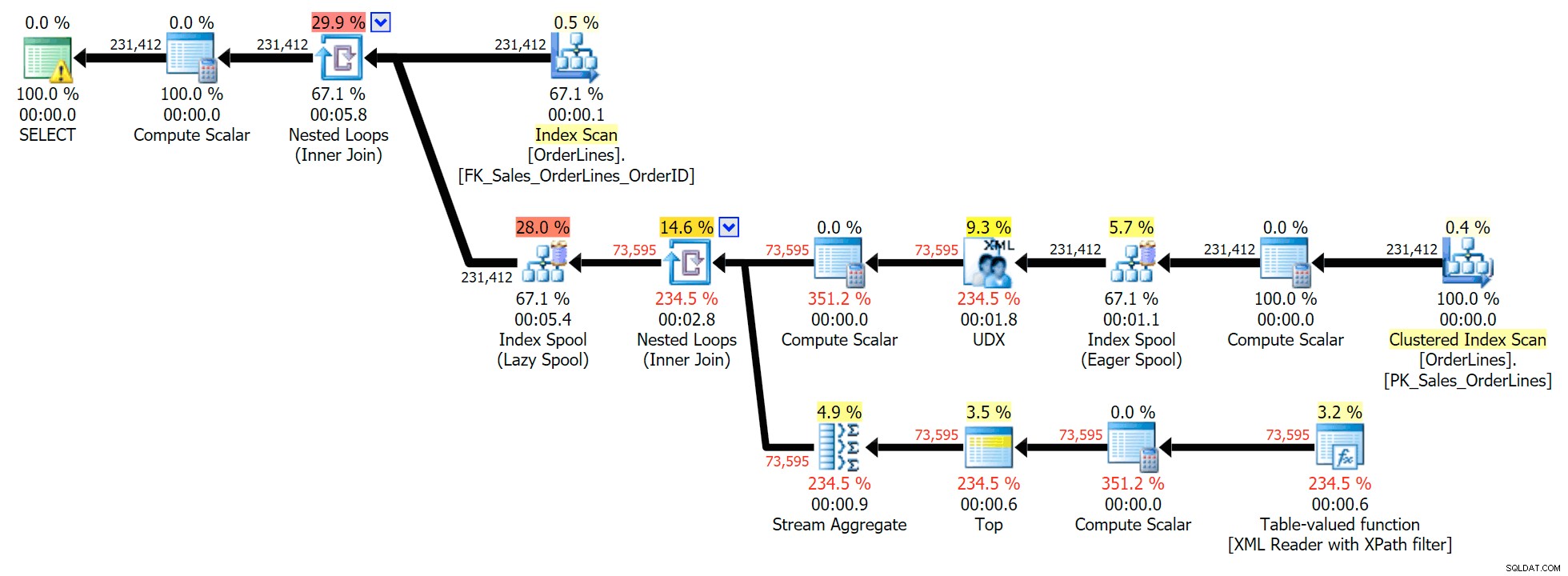
Въпреки това има проблем, който може да забележите в изходния брой редове. Със сигурност можете да го забележите, когато небрежно сканирате изхода:

За всяка поръчка виждаме списъка, разделен с черти, но виждаме ред за всеки артикул във всяка поръчка. Реакцията на коляно е да хвърлите DISTINCT в списъка с колони:
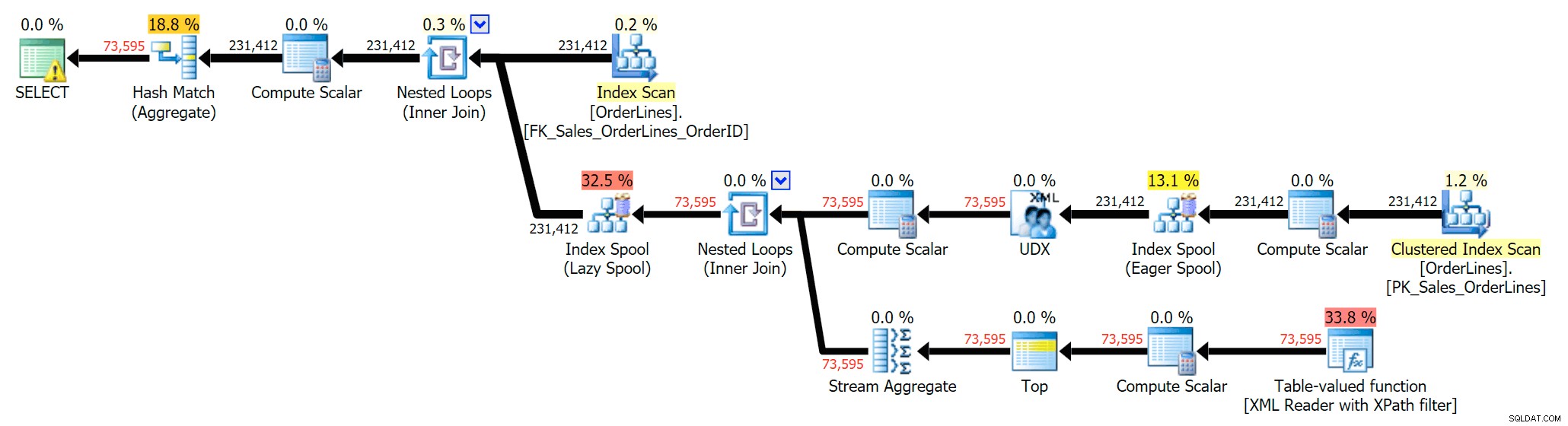
SELECT DISTINCT o.OrderID, OrderItems = STUFF((SELECT N'|' + Description FROM Sales.OrderLines WHERE OrderID = o.OrderID FOR XML PATH(N''), TYPE).value(N'text()[1]', N'nvarchar(max)'),1,1,N'') FROM Sales.OrderLines AS o;
Това елиминира дубликатите (и променя свойствата за подреждане на сканиранията, така че резултатите няма да се показват непременно в предвидим ред) и създава следния план за изпълнение:
Друг начин да направите това е да добавите GROUP BY за OrderID (тъй като подзаявката не е изрично необходима за позоваване отново в GROUP BY):
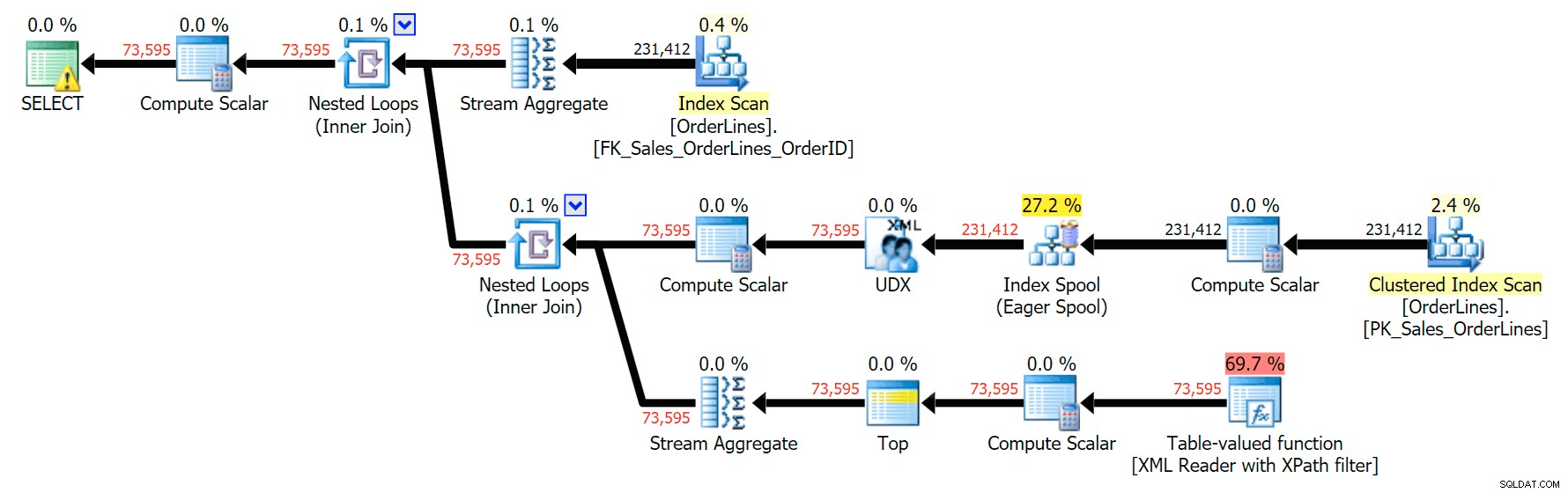
SELECT o.OrderID, OrderItems = STUFF((SELECT N'|' + Description FROM Sales.OrderLines WHERE OrderID = o.OrderID FOR XML PATH(N''), TYPE).value(N'text()[1]', N'nvarchar(max)'),1,1,N'') FROM Sales.OrderLines AS o GROUP BY o.OrderID;
Това дава същите резултати (въпреки че поръчката се е върнала) и малко по-различен план:
Показателите за ефективност обаче са интересни за сравняване.

Вариантът DISTINCT отне 4 пъти повече време, използва 4 пъти процесора и почти 6 пъти повече от показанията в сравнение с варианта GROUP BY. (Не забравяйте, че тези заявки връщат точно същите резултати.)
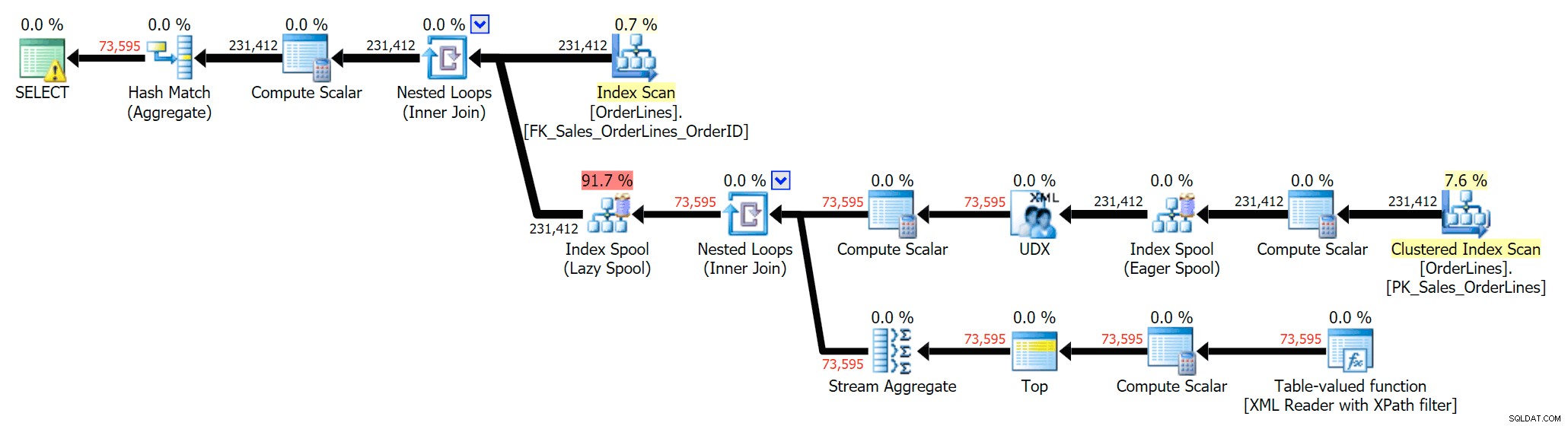
Можем също да сравним плановете за изпълнение, когато променим разходите от CPU + I/O комбинирани към I/O само, функция, изключителна за Plan Explorer. Ние също така показваме преоценените стойности (които се основават на действителните разходи, наблюдавани по време на изпълнение на заявка, функция, която също се намира само в Plan Explorer). Ето плана DISTINCT:
А ето и плана GROUP BY:
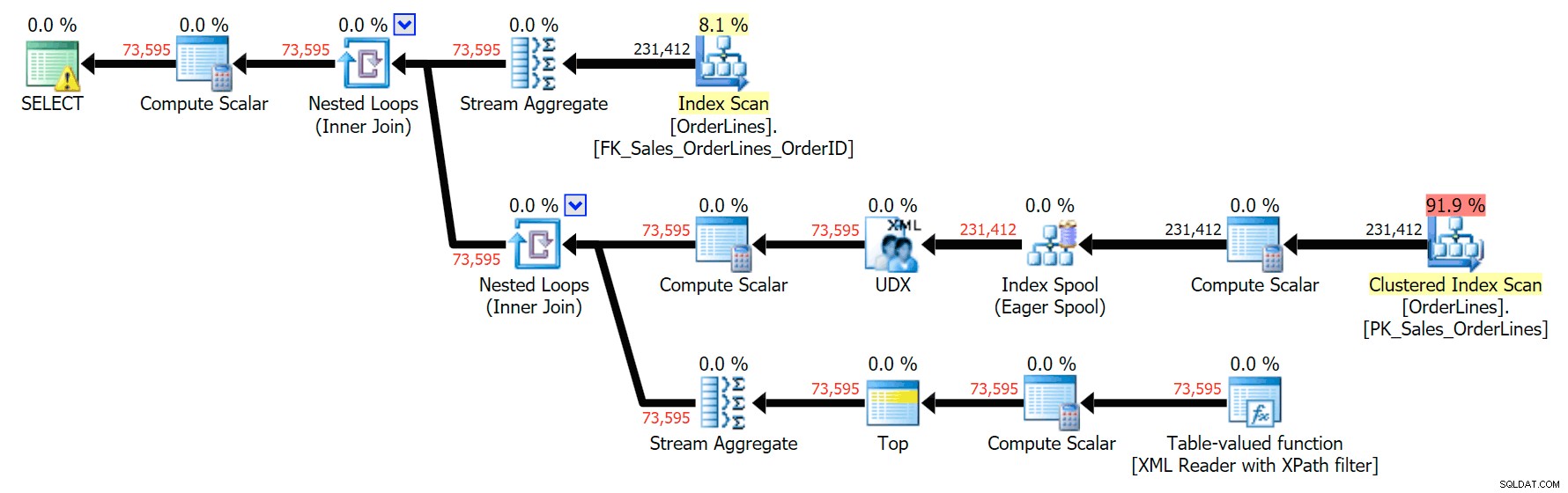
Можете да видите, че в плана GROUP BY почти всички разходи за I/O са в сканиранията (ето подсказката за CI сканирането, показваща I/O цена от ~3,4 „заявка долара“). И все пак в плана DISTINCT по-голямата част от разходите за I/O е в шпулата на индекса (и ето тази подсказка; цената на I/O тук е ~41,4 "заявка долара"). Имайте предвид, че процесорът е много по-висок с индексната шпула. Ще говорим за "доларите за заявка" друг път, но въпросът е, че индексната шпула е повече от 10 пъти по-скъпа от сканирането - но сканирането все още е същите 3.4 и в двата плана. Това е една от причините винаги да ме притеснява, когато хората казват, че трябва да „поправят“ оператора в плана с най-висока цена. Някои оператори в плана винаги бъде най-скъпият; това не означава, че трябва да се поправи.
@AaronBertrand тези заявки не са наистина логически еквивалентни — DISTINCT е и в двете колони, докато вашата GROUP BY е само в една
— Адам Мачаник (@AdamMachanic) 20 януари 2017 г.
Макар че Адам Мачаник е прав, когато казва, че тези заявки са семантично различни, резултатът е същият – получаваме същия брой редове, съдържащи абсолютно същите резултати, и го направихме с много по-малко четения и процесор.
Така че докато DISTINCT и GROUP BY са идентични в много сценарии, ето един случай, при който подходът GROUP BY определено води до по-добра производителност (с цената на по-малко ясно декларативно намерение в самата заявка). Ще ми е интересно да знам дали смятате, че има сценарии, при които DISTINCT е по-добър от GROUP BY, поне по отношение на производителността, която е далеч по-малко субективна от стила или дали дадено изявление трябва да се самодокументира.
Тази публикация се вписва в моята поредица „изненади и предположения“, защото много неща, които смятаме за истини, базирани на ограничени наблюдения или конкретни случаи на употреба, могат да бъдат тествани, когато се използват в други сценарии. Просто трябва да не забравяме да отделим време да го направим като част от оптимизацията на SQL заявки...
Препратки
- Групирана конкатенация в SQL Server
- Групирана конкатенация:Подреждане и премахване на дубликати
- Четири практически случая на използване на групирана конкатенация
- SQL Server v.Next:производителност STRING_AGG()
- SQL сървър v. Next:STRING_AGG производителност, част 2