Често срещам проблем с производителността, когато потребителите трябва да съпоставят част от низ със заявка като следната:
... WHERE SomeColumn LIKE N'%SomePortion%';
С водещ заместващ знак този предикат е „не-SARGable“ – просто изискан начин да кажем, че не можем да намерим съответните редове, като използваме търсене срещу индекс на SomeColumn .
Едно от решенията, за които се вълнуваме, е пълнотекстово търсене; това обаче е сложно решение и изисква шаблонът за търсене да се състои от пълни думи, да не използва стоп думи и т.н. Това може да помогне, ако търсим редове, където описанието съдържа думата "soft" (или други производни като "softer" или "softly"), но не помага, когато търсим низове, които биха могли да се съдържат в рамките на думи (или които изобщо не са думи, като всички артикули на продукти, които съдържат „X45-B“ или всички регистрационни номера, които съдържат последователността „7RA“).
Ами ако SQL Server по някакъв начин знае за всички възможни части от низ? Мисловният ми процес е по линия на trigram / trigraph в PostgreSQL. Основната концепция е, че машината има способността да извършва търсене в точков стил на поднизове, което означава, че не е нужно да сканирате цялата таблица и да анализирате всяка пълна стойност.
Конкретният пример, който използват там, е думата cat . В допълнение към цялата дума, тя може да бъде разбита на части:c , ca и at (те пропускат a и t по дефиниция – нито един краен подниз не може да бъде по-кратък от два знака). В SQL Server не е необходимо той да е толкова сложен; наистина се нуждаем само от половината от триграмата – ако мислим за изграждане на структура от данни, която съдържа всички поднизове на cat , трябват ни само тези стойности:
- котка
- в
- т
Не ни трябва c или ca , защото всеки, който търси LIKE '%ca%' може лесно да намери стойност 1, като използва LIKE 'ca%' вместо. По същия начин всеки, който търси LIKE '%at%' или LIKE '%a%' може да използва последващ заместващ знак само срещу тези три стойности и да намери тази, която съвпада (напр. LIKE 'at%' ще намери стойност 2 и LIKE 'a%' ще намери и стойност 2, без да се налага да намира тези поднизове вътре в стойност 1, откъдето ще дойде истинската болка).
И така, като се има предвид, че SQL Server няма вградено нещо подобно, как да генерираме такава триграма?
Таблица с отделни фрагменти
Ще спра да споменавам "trigram" тук, защото това не е наистина аналогично на тази функция в PostgreSQL. По същество това, което ще направим, е да изградим отделна таблица с всички "фрагменти" на оригиналния низ. (Така че в cat например, ще има нова таблица с тези три реда и LIKE '%pattern%' търсенията ще бъдат насочени към тази нова таблица като LIKE 'pattern%' предикати.)
Преди да започна да покажа как би работило предложеното от мен решение, нека да бъда абсолютно ясен, че това решение не трябва да се използва във всеки отделен случай, когато LIKE '%wildcard%' търсенията са бавни. Поради начина, по който ще „раздуваме“ изходните данни на фрагменти, вероятно е ограничено по практичност до по-малки низове, като адреси или имена, за разлика от по-големите низове, като описания на продукти или резюмета на сесиите.
По-практичен пример от cat е да погледнете Sales.Customer таблица в примерната база данни WideWorldImporters. Има адресни редове (и двата nvarchar(60)). ), с ценната информация за адреса в колоната DeliveryAddressLine2 (по неизвестни причини). Някой може да търси всеки, който живее на улица с име Hudecova , така че те ще извършват търсене по следния начин:
SELECT CustomerID, DeliveryAddressLine2
FROM Sales.Customers
WHERE DeliveryAddressLine2 LIKE N'%Hudecova%';
/* This returns two rows:
CustomerID DeliveryAddressLine2
---------- ----------------------
61 1695 Hudecova Avenue
181 1846 Hudecova Crescent
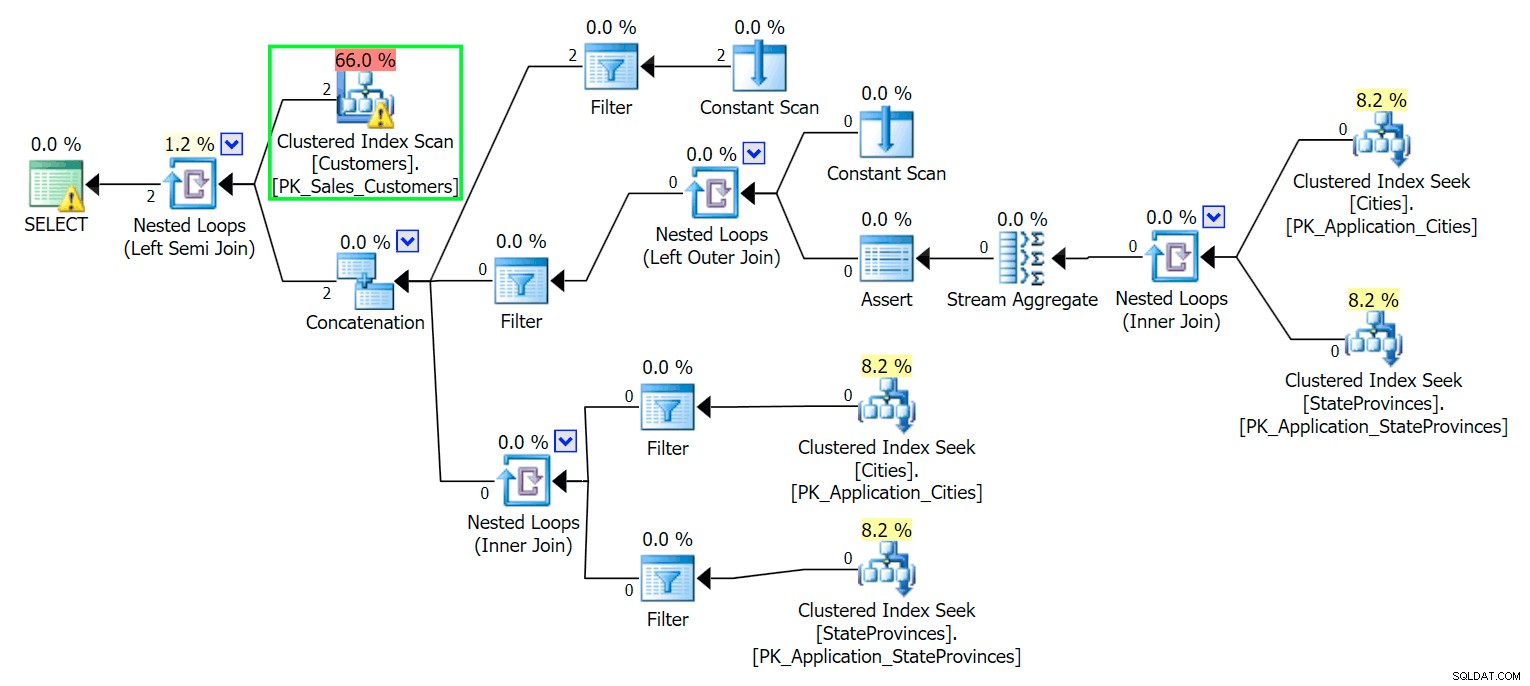
*/ Както бихте очаквали, SQL Server трябва да извърши сканиране, за да намери тези два реда. Което трябва да е просто; обаче, поради сложността на таблицата, тази тривиална заявка дава много объркан план за изпълнение (сканирането е маркирано и има предупреждение за остатъчен I/O):
Blecch. За да запазим живота си прост и за да сме сигурни, че няма да преследваме куп червени херинги, нека създадем нова таблица с подмножество от колони и за начало просто ще вмъкнем същите тези два реда отгоре:
CREATE TABLE Sales.CustomersCopy ( CustomerID int IDENTITY(1,1) CONSTRAINT PK_CustomersCopy PRIMARY KEY, CustomerName nvarchar(100) NOT NULL, DeliveryAddressLine1 nvarchar(60) NOT NULL, DeliveryAddressLine2 nvarchar(60) ); GO INSERT Sales.CustomersCopy ( CustomerName, DeliveryAddressLine1, DeliveryAddressLine2 ) SELECT CustomerName, DeliveryAddressLine1, DeliveryAddressLine2 FROM Sales.Customers WHERE DeliveryAddressLine2 LIKE N'%Hudecova%';
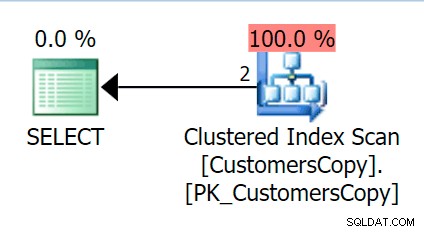
Сега, ако изпълним същата заявка, която изпълнихме към основната таблица, получаваме нещо много по-разумно, което да разглеждаме като отправна точка. Това все още ще бъде сканиране, независимо какво правим – ако добавим индекс с DeliveryAddressLine2 като водеща ключова колона, най-вероятно ще получим индексно сканиране, с ключово търсене в зависимост от това дали индексът покрива колоните в заявката. Както е, получаваме клъстерно сканиране на индекс:
След това нека създадем функция, която ще "раздуе" тези адресни стойности на фрагменти. Очакваме 1846 Hudecova Crescent , например, за да имате следния набор от фрагменти:
- 1846 Худецов полумесец
- 846 Худецов полумесец
- 46 Худецов полумесец
- 6 Худецов полумесец
- Худецов полумесец
- Худецов полумесец
- udecova Crescent
- decova Crescent
- ecova Crescent
- cova Crescent
- ova Crescent
- va Crescent
- полумесец
- Полумесец
- Полумесец
- съвременен
- същност
- аромат
- цент
- вх.
- не
- т
Доста тривиално е да се напише функция, която ще произведе този изход – просто ни трябва рекурсивен CTE, който може да се използва за преминаване през всеки знак по цялата дължина на входа:
CREATE FUNCTION dbo.CreateStringFragments( @input nvarchar(60) )
RETURNS TABLE WITH SCHEMABINDING
AS
RETURN
(
WITH x(x) AS
(
SELECT 1 UNION ALL SELECT x+1 FROM x WHERE x < (LEN(@input))
)
SELECT Fragment = SUBSTRING(@input, x, LEN(@input)) FROM x
);
GO
SELECT Fragment FROM dbo.CreateStringFragments(N'1846 Hudecova Crescent');
-- same output as above bulleted list Сега нека създадем таблица, която ще съхранява всички адресни фрагменти и на кой клиент принадлежат:
CREATE TABLE Sales.CustomerAddressFragments ( CustomerID int NOT NULL, Fragment nvarchar(60) NOT NULL, CONSTRAINT FK_Customers FOREIGN KEY(CustomerID) REFERENCES Sales.CustomersCopy(CustomerID) ); CREATE CLUSTERED INDEX s_cat ON Sales.CustomerAddressFragments(Fragment, CustomerID);
След това можем да го попълним така:
INSERT Sales.CustomerAddressFragments(CustomerID, Fragment) SELECT c.CustomerID, f.Fragment FROM Sales.CustomersCopy AS c CROSS APPLY dbo.CreateStringFragments(c.DeliveryAddressLine2) AS f;
За нашите две стойности това вмъква 42 реда (единият адрес има 20 знака, а другият има 22). Сега нашата заявка става:
SELECT c.CustomerID, c.DeliveryAddressLine2
FROM Sales.CustomersCopy AS c
INNER JOIN Sales.CustomerAddressFragments AS f
ON f.CustomerID = c.CustomerID
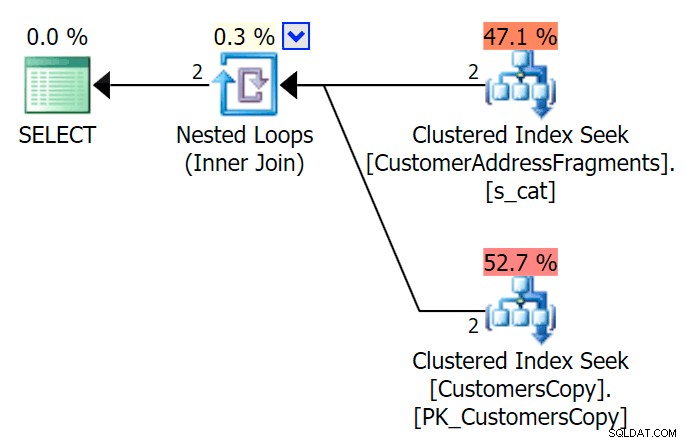
AND f.Fragment LIKE N'Hudecova%'; Ето един много по-хубав план – два клъстерирани индекса *търси* и вложени цикли се присъединяват:
Можем да направим това и по друг начин, като използваме EXISTS :
SELECT c.CustomerID, c.DeliveryAddressLine2
FROM Sales.CustomersCopy AS c
WHERE EXISTS
(
SELECT 1 FROM Sales.CustomerAddressFragments
WHERE CustomerID = c.CustomerID
AND Fragment LIKE N'Hudecova%'
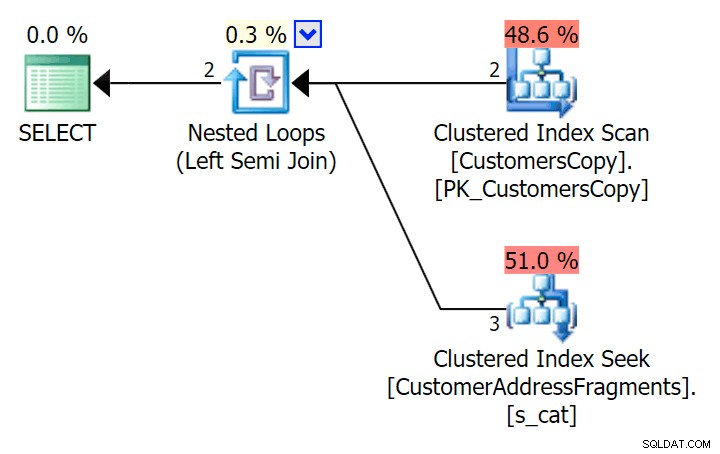
); Ето този план, който на пръв поглед изглежда по-скъп – избира да сканира таблицата CustomersCopy. Скоро ще видим защо това е по-добрият подход към заявката:
Сега, при този масивен набор от данни от 42 реда, разликите, наблюдавани в продължителността и I/O, са толкова минимални, че са без значение (и всъщност при този малък размер сканирането спрямо основната таблица изглежда по-евтино по отношение на I/O O от другите два плана, които използват таблицата с фрагменти):

Ами ако трябваше да попълним тези таблици с много повече данни? Моето копие на Sales.Customers има 663 реда, така че ако кръстосваме това срещу себе си, ще получим някъде близо 440 000 реда. Така че нека просто смесим 400K и генерираме много по-голяма таблица:
TRUNCATE TABLE Sales.CustomerAddressFragments; DELETE Sales.CustomersCopy; DBCC FREEPROCCACHE WITH NO_INFOMSGS; INSERT Sales.CustomersCopy WITH (TABLOCKX) (CustomerName, DeliveryAddressLine1, DeliveryAddressLine2) SELECT TOP (400000) c1.CustomerName, c1.DeliveryAddressLine1, c2.DeliveryAddressLine2 FROM Sales.Customers c1 CROSS JOIN Sales.Customers c2 ORDER BY NEWID(); -- fun for distribution -- this will take a bit longer - on my system, ~4 minutes -- probably because I didn't bother to pre-expand files INSERT Sales.CustomerAddressFragments WITH (TABLOCKX) (CustomerID, Fragment) SELECT c.CustomerID, f.Fragment FROM Sales.CustomersCopy AS c CROSS APPLY dbo.CreateStringFragments(c.DeliveryAddressLine2) AS f; -- repeated for compressed version of the table -- 7.25 million rows, 278MB (79MB compressed; saving those tests for another day)
Сега, за да сравня плановете за производителност и изпълнение, като се имат предвид различни възможни параметри за търсене, тествах горните три заявки с тези предикати:
| Запитване | Предикати | ||||
|---|---|---|---|---|---|
| КЪДЕ DeliveryLineAddress2 LIKE … | N'%Hudecova%' | N'%cova%' | N'%ova%' | N'%va%' | |
| Присъединете се... КЪДЕ Фрагмент КАТО... | N'Hudecova%' | N'cova%' | N'ova%' | N'va%' | |
| КЪДЕ СЪЩЕСТВУВА (... КЪДЕ Фрагмент КАТО...) | |||||
Докато премахваме букви от шаблона за търсене, бих очаквал да видя повече извеждани редове и може би различни стратегии, избрани от оптимизатора. Нека видим как се получи за всеки модел:
Худекова%
За този модел сканирането все още беше същото за условието LIKE; обаче с повече данни цената е много по-висока. Търсенето в таблицата с фрагменти наистина се изплаща при този брой редове (1206), дори и при наистина ниски оценки. Планът EXISTS добавя различен сорт, който бихте очаквали да добавите към цената, въпреки че в този случай в крайна сметка прави по-малко четения:

 Планирайте JOIN към таблицата с фрагменти
Планирайте JOIN към таблицата с фрагменти 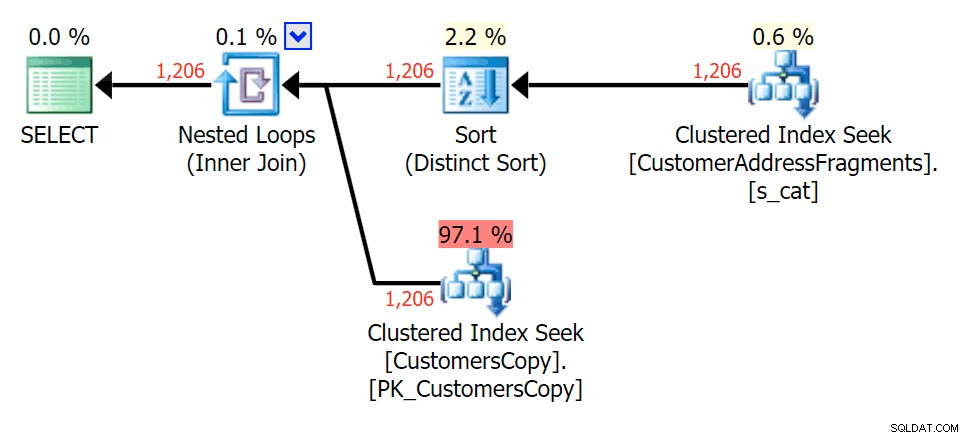 Планирайте EXISTS спрямо таблицата с фрагменти
Планирайте EXISTS спрямо таблицата с фрагменти cova%
Докато премахваме някои букви от нашия предикат, виждаме показанията всъщност малко по-високи, отколкото при оригиналното сканиране на клъстериран индекс, и сега над -оценете редовете. Дори и все пак нашата продължителност остава значително по-малка и при двете запитвания за фрагменти; разликата този път е по-фина – и двете имат сортове (отличително е само EXISTS):

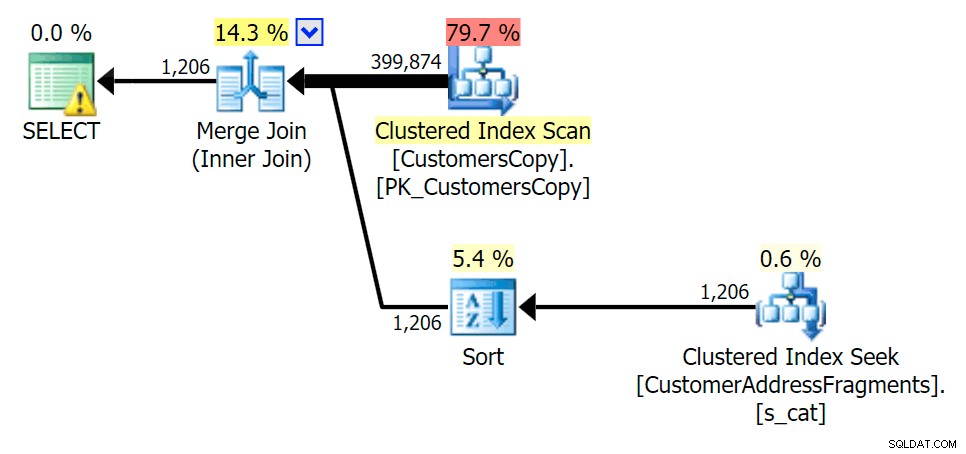 Планирайте JOIN към таблицата с фрагменти
Планирайте JOIN към таблицата с фрагменти 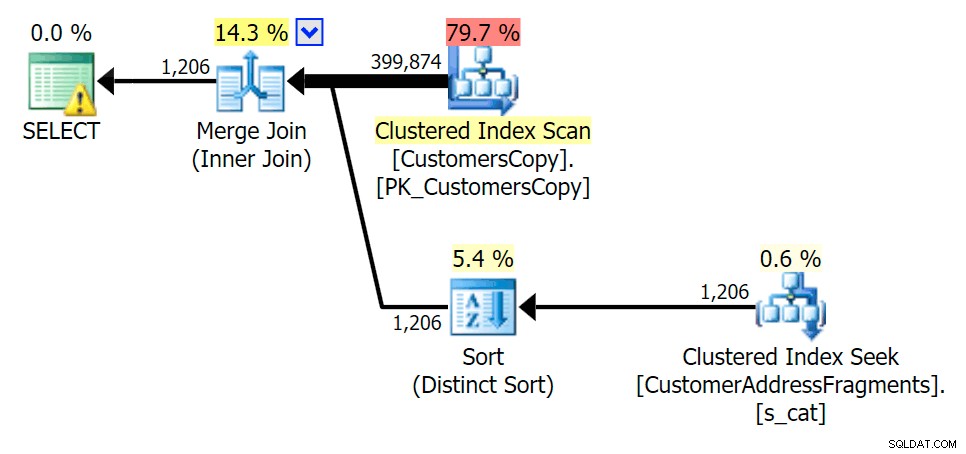 Планирайте EXISTS спрямо таблицата с фрагменти
Планирайте EXISTS спрямо таблицата с фрагменти ova%
Премахването на допълнителна буква не промени много; въпреки че си струва да се отбележи колко скачат изчислените и действителните редове тук – което означава, че това може да е често срещан модел на подниз. Оригиналната заявка LIKE все още е доста по-бавна от заявките за фрагменти.

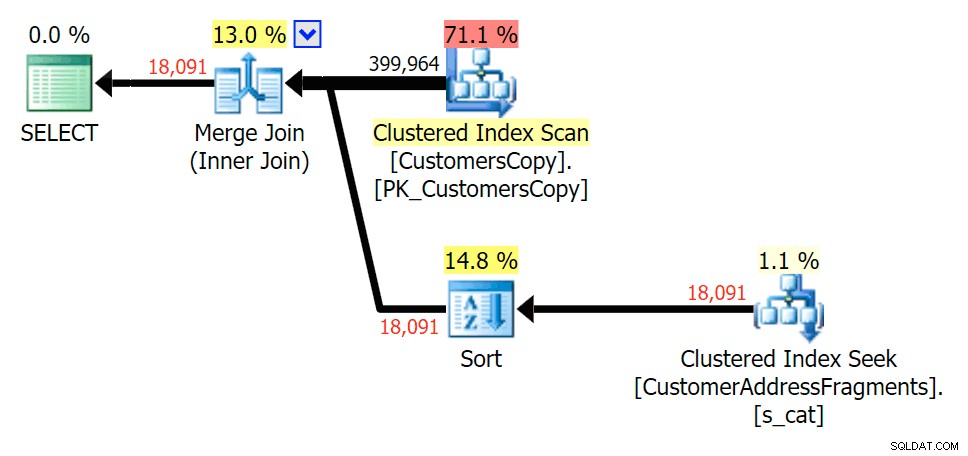 Планирайте JOIN към таблицата с фрагменти
Планирайте JOIN към таблицата с фрагменти 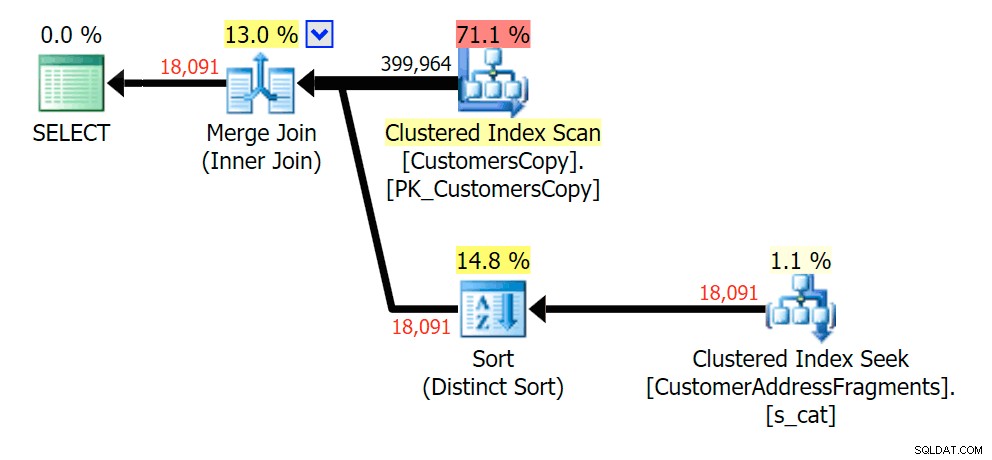 Планирайте EXISTS спрямо таблицата с фрагменти
Планирайте EXISTS спрямо таблицата с фрагменти va%
До две букви това въвежда първото ни несъответствие. Забележете, че JOIN произвежда повече редове от оригиналната заявка или EXISTS. Защо би било така?

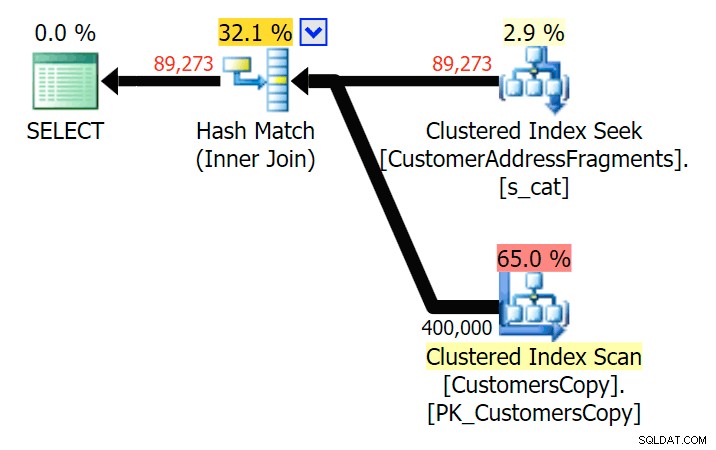 Планирайте JOIN към таблицата с фрагменти
Планирайте JOIN към таблицата с фрагменти 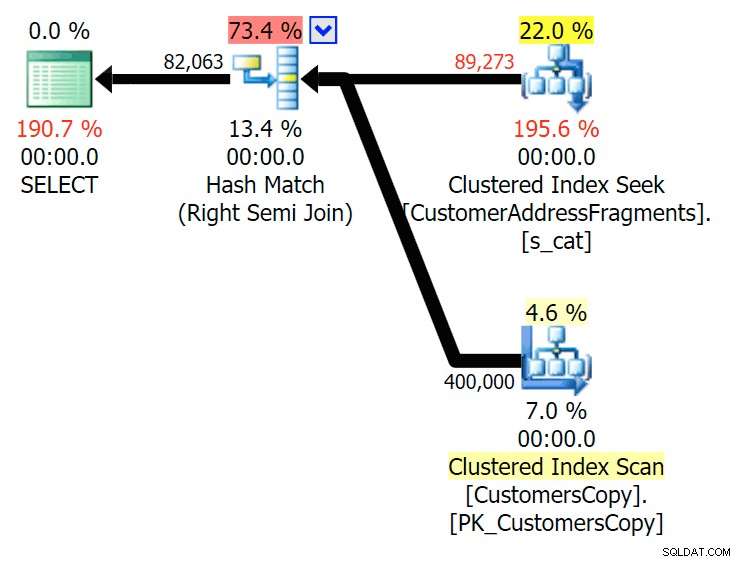 Планирайте EXISTS спрямо таблицата с фрагменти Не е нужно да търсим далеч. Не забравяйте, че има фрагмент, започващ от всеки следващ знак в оригиналния адрес, което означава нещо като
Планирайте EXISTS спрямо таблицата с фрагменти Не е нужно да търсим далеч. Не забравяйте, че има фрагмент, започващ от всеки следващ знак в оригиналния адрес, което означава нещо като 899 Valentova Road ще има два реда в таблицата с фрагменти, които започват с va (настрана чувствителността към главни и малки букви). Така че ще съвпадате и на двете Fragment = N'Valentova Road' и Fragment = N'va Road' . Ще ви спестя търсенето и ще дам един-единствен пример от много: SELECT TOP (2) c.CustomerID, c.DeliveryAddressLine2, f.Fragment FROM Sales.CustomersCopy AS c INNER JOIN Sales.CustomerAddressFragments AS f ON c.CustomerID = f.CustomerID WHERE f.Fragment LIKE N'va%' AND c.DeliveryAddressLine2 = N'899 Valentova Road' AND f.CustomerID = 351; /* CustomerID DeliveryAddressLine2 Fragment ---------- -------------------- -------------- 351 899 Valentova Road va Road 351 899 Valentova Road Valentova Road */
Това лесно обяснява защо JOIN произвежда повече редове; ако искате да съпоставите изхода на оригиналната заявка LIKE, трябва да използвате EXISTS. Фактът, че правилните резултати обикновено могат да бъдат получени и по по-малко ресурсоемък начин, е просто бонус. (Бих се притеснявал да видя как хората избират JOIN, ако това беше многократно по-ефективната опция – винаги трябва да предпочитате правилните резултати, вместо да се притеснявате за производителността.)
Резюме
Ясно е, че в конкретния случай – с адресна колона nvarchar(60) и максимална дължина от 26 знака – разделянето на всеки адрес на фрагменти може да донесе известно облекчение на иначе скъпите търсения с „водещи заместващи знаци“. По-добрата печалба изглежда се случва, когато моделът на търсене е по-голям и в резултат на това по-уникален. Също така демонстрирах защо EXISTS е по-добър в сценарии, при които са възможни множество съвпадения – с JOIN ще получите излишен изход, освен ако не добавите някаква логика „най-голямо n на група“.
Предупреждения
Ще бъда първият, който ще признае, че това решение е несъвършено, непълно и неизчерпателно:
- Ще трябва да поддържате таблицата с фрагменти синхронизирана с основната таблица с помощта на тригери – най-простото е за вмъкване и актуализации, изтриване на всички редове за тези клиенти и повторно вмъкване, а за изтривания очевидно премахване на редовете от фрагментите маса.
- Както споменахме, това решение работи по-добре за този конкретен размер на данни и може да не се справи толкова добре за други дължини на низове. Би наложило допълнително тестване, за да се гарантира, че е подходящо за размера на колоната, средната дължина на стойността и типичната дължина на параметъра за търсене.
- Тъй като ще имаме много копия на фрагменти като „Crescent“ и „Street“ (без значение на всички същите или подобни имена на улици и номера на къщи), можем допълнително да го нормализираме, като съхраняваме всеки уникален фрагмент в таблица с фрагменти, и след това още една таблица, която действа като свързваща маса много към много. Това би било много по-тромаво за настройване и не съм съвсем сигурен, че ще спечеля много.
- Все още не съм изследвал напълно компресията на страници, изглежда – поне на теория – това би могло да осигури известна полза. Също така имам чувството, че внедряването на columnstore също може да е от полза в някои случаи.
Както и да е, всичко казано, просто исках да го споделя като развиваща се идея и да поискам всякаква обратна връзка относно нейната практичност за конкретни случаи на употреба. Мога да разровя повече подробности за бъдеща публикация, ако можете да ми кажете какви аспекти на това решение ви интересуват.