Една от многото нови функции, въведени още в SQL Server 2008, беше компресията на данни. Компресирането на ниво ред или страница предоставя възможност за спестяване на дисково пространство, като компромисът изисква малко повече CPU за компресиране и декомпресиране на данните. Често се твърди, че по-голямата част от системите са свързани с IO, а не с процесор, така че компромисът си заслужава. Уловката? Трябваше да сте на Enterprise Edition, за да използвате компресия на данни. С пускането на SQL Server 2016 SP1 това се промени! Ако използвате Standard Edition на SQL Server 2016 SP1 и по-нова версия, вече можете да използвате компресия на данни. Има и нова вградена функция за компресиране, COMPRESS (и нейния аналог DECOMPRESS). Компресирането на данни не работи върху данни извън ред, така че ако имате колона като NVARCHAR(MAX) във вашата таблица със стойности, обикновено по-големи от 8000 байта, тези данни няма да бъдат компресирани (благодаря на Adam Machanic за това напомняне) . Функцията COMPRESS решава този проблем и компресира данни с размер до 2GB. Освен това, макар да твърдя, че функцията трябва да се използва само за големи данни извън ред, смятах, че сравняването й директно с компресията на ред и страница е полезен експеримент.
НАСТРОЙКА
За тестови данни работя по скрипт, който Аарон Бертран е използвал преди, но направих някои промени. Създадох отделна база данни за тестване, но можете да използвате tempdb или друга примерна база данни и след това започнах с таблица Customers, която има три колони NVARCHAR. Обмислях да създам по-големи колони и да ги попълня с низове от повтарящи се букви, но използването на четим текст дава извадка, която е по-реалистична и по този начин осигурява по-голяма точност.
Забележка: Ако се интересувате от внедряване на компресия и искате да знаете как ще се отрази на съхранението и производителността във вашата среда, СИЛНО ПРЕПОРЪЧВАМ ДА ГО ТЕСТВАТЕ. Давам ви методологията с примерни данни; внедряването на това във вашата среда не трябва да включва допълнителна работа.
По-долу ще забележите, че след създаването на базата данни активираме Query Store. Защо да създаваме отделна таблица, за да се опитаме да проследяваме нашите показатели за ефективност, когато можем просто да използваме функционалност, вградена в SQL Server?!
USE [master]; GO CREATE DATABASE [CustomerDB] CONTAINMENT = NONE ON PRIMARY ( NAME = N'CustomerDB', FILENAME = N'C:\Databases\CustomerDB.mdf' , SIZE = 4096MB , MAXSIZE = UNLIMITED, FILEGROWTH = 65536KB ) LOG ON ( NAME = N'CustomerDB_log', FILENAME = N'C:\Databases\CustomerDB_log.ldf' , SIZE = 2048MB , MAXSIZE = UNLIMITED , FILEGROWTH = 65536KB ); GO ALTER DATABASE [CustomerDB] SET COMPATIBILITY_LEVEL = 130; GO ALTER DATABASE [CustomerDB] SET RECOVERY SIMPLE; GO ALTER DATABASE [CustomerDB] SET QUERY_STORE = ON; GO ALTER DATABASE [CustomerDB] SET QUERY_STORE ( OPERATION_MODE = READ_WRITE, CLEANUP_POLICY = (STALE_QUERY_THRESHOLD_DAYS = 30), DATA_FLUSH_INTERVAL_SECONDS = 60, INTERVAL_LENGTH_MINUTES = 5, MAX_STORAGE_SIZE_MB = 256, QUERY_CAPTURE_MODE = ALL, SIZE_BASED_CLEANUP_MODE = AUTO, MAX_PLANS_PER_QUERY = 200 ); GO
Сега ще настроим някои неща в базата данни:
USE [CustomerDB]; GO ALTER DATABASE SCOPED CONFIGURATION SET MAXDOP = 0; GO -- note: I removed the unique index on [Email] that was in Aaron's version CREATE TABLE [dbo].[Customers] ( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers] PRIMARY KEY CLUSTERED ([CustomerID]) ); GO CREATE NONCLUSTERED INDEX [Active_Customers] ON [dbo].[Customers]([FirstName],[LastName],[EMail]) WHERE ([Active]=1); GO CREATE NONCLUSTERED INDEX [PhoneBook_Customers] ON [dbo].[Customers]([LastName],[FirstName]) INCLUDE ([EMail]);
Със създадената таблица ще добавим някои данни, но добавяме 5 милиона реда вместо 1 милион. Това отнема около осем минути, за да работи на моя лаптоп.
INSERT dbo.Customers WITH (TABLOCKX)
(CustomerID, FirstName, LastName, EMail, [Active])
SELECT rn = ROW_NUMBER() OVER (ORDER BY n), fn, ln, em, a
FROM
(
SELECT TOP (5000000) fn, ln, em, a = MAX(a), n = MAX(NEWID())
FROM
(
SELECT fn, ln, em, a, r = ROW_NUMBER() OVER (PARTITION BY em ORDER BY em)
FROM
(
SELECT TOP (20000000)
fn = LEFT(o.name, 64),
ln = LEFT(c.name, 64),
em = LEFT(o.name, LEN(c.name)%5+1) + '.'
+ LEFT(c.name, LEN(o.name)%5+2) + '@'
+ RIGHT(c.name, LEN(o.name + c.name)%12 + 1)
+ LEFT(RTRIM(CHECKSUM(NEWID())),3) + '.com',
a = CASE WHEN c.name LIKE '%y%' THEN 0 ELSE 1 END
FROM sys.all_objects AS o CROSS JOIN sys.all_columns AS c
ORDER BY NEWID()
) AS x
) AS y WHERE r = 1
GROUP BY fn, ln, em
ORDER BY n
) AS z
ORDER BY rn;
GO Сега ще създадем още три таблици:една за компресиране на редове, една за компресиране на страници и една за функцията COMPRESS. Имайте предвид, че с функцията COMPRESS трябва да създадете колоните като типове данни VARBINARY. В резултат на това в таблицата няма неклъстерирани индекси (тъй като не можете да създадете индексен ключ на варбинарна колона).
CREATE TABLE [dbo].[Customers_Page] ( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers_Page] PRIMARY KEY CLUSTERED ([CustomerID]) ); GO CREATE NONCLUSTERED INDEX [Active_Customers_Page] ON [dbo].[Customers_Page]([FirstName],[LastName],[EMail]) WHERE ([Active]=1); GO CREATE NONCLUSTERED INDEX [PhoneBook_Customers_Page] ON [dbo].[Customers_Page]([LastName],[FirstName]) INCLUDE ([EMail]); GO CREATE TABLE [dbo].[Customers_Row] ( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers_Row] PRIMARY KEY CLUSTERED ([CustomerID]) ); GO CREATE NONCLUSTERED INDEX [Active_Customers_Row] ON [dbo].[Customers_Row]([FirstName],[LastName],[EMail]) WHERE ([Active]=1); GO CREATE NONCLUSTERED INDEX [PhoneBook_Customers_Row] ON [dbo].[Customers_Row]([LastName],[FirstName]) INCLUDE ([EMail]); GO CREATE TABLE [dbo].[Customers_Compress] ( [CustomerID] [int] NOT NULL, [FirstName] [varbinary](max) NOT NULL, [LastName] [varbinary](max) NOT NULL, [EMail] [varbinary](max) NOT NULL, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers_Compress] PRIMARY KEY CLUSTERED ([CustomerID]) ); GO
След това ще копираме данните от [dbo].[Customers] в другите три таблици. Това е направо INSERT за нашите таблици на страници и редове и отнема около две до три минути за всяко INSERT, но има проблем с мащабируемостта с функцията COMPRESS:опитът за вмъкване на 5 милиона реда с един замах просто не е разумен. Скриптът по-долу вмъква редове на партиди от 50 000 и вмъква само 1 милион реда вместо 5 милиона. Знам, това означава, че тук не сме истински ябълки за ябълки за сравнение, но съм ок с това. Вмъкването на 1 милион реда отнема 10 минути на моята машина; не се колебайте да коригирате скрипта и да вмъкнете 5 милиона реда за вашите собствени тестове.
INSERT dbo.Customers_Page WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) SELECT CustomerID, FirstName, LastName, EMail, [Active] FROM dbo.Customers; GO INSERT dbo.Customers_Row WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) SELECT CustomerID, FirstName, LastName, EMail, [Active] FROM dbo.Customers; GO SET NOCOUNT ON DECLARE @StartID INT = 1 DECLARE @EndID INT = 50000 DECLARE @Increment INT = 50000 DECLARE @IDMax INT = 1000000 WHILE @StartID < @IDMax BEGIN INSERT dbo.Customers_Compress WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) SELECT top 100000 CustomerID, COMPRESS(FirstName), COMPRESS(LastName), COMPRESS(EMail), [Active] FROM dbo.Customers WHERE [CustomerID] BETWEEN @StartID AND @EndID; SET @StartID = @StartID + @Increment; SET @EndID = @EndID + @Increment; END
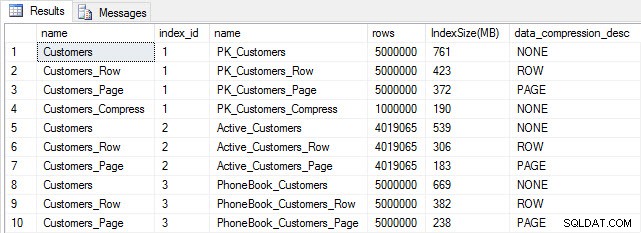
След като всички наши таблици са попълнени, можем да направим проверка на размера. В този момент не сме внедрили компресия на ROW или PAGE, но е използвана функцията COMPRESS:
SELECT [o].[name], [i].[index_id], [i].[name], [p].[rows], (8*SUM([au].[used_pages]))/1024 AS [IndexSize(MB)], [p].[data_compression_desc] FROM [sys].[allocation_units] [au] JOIN [sys].[partitions] [p] ON [au].[container_id] = [p].[partition_id] JOIN [sys].[objects] [o] ON [p].[object_id] = [o].[object_id] JOIN [sys].[indexes] [i] ON [p].[object_id] = [i].[object_id] AND [p].[index_id] = [i].[index_id] WHERE [o].[is_ms_shipped] = 0 GROUP BY [o].[name], [i].[index_id], [i].[name], [p].[rows], [p].[data_compression_desc] ORDER BY [o].[name], [i].[index_id];
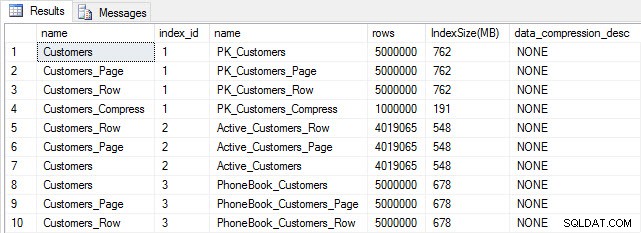 Размер на таблица и индекс след вмъкване
Размер на таблица и индекс след вмъкване
Както се очакваше, всички таблици с изключение на Customers_Compress са с приблизително еднакъв размер. Сега ще възстановим индексите на всички таблици, като приложим компресия на редове и страници съответно на Customers_Row и Customers_Page.
ALTER INDEX ALL ON dbo.Customers REBUILD; GO ALTER INDEX ALL ON dbo.Customers_Page REBUILD WITH (DATA_COMPRESSION = PAGE); GO ALTER INDEX ALL ON dbo.Customers_Row REBUILD WITH (DATA_COMPRESSION = ROW); GO ALTER INDEX ALL ON dbo.Customers_Compress REBUILD;
Ако проверим размера на таблицата след компресиране, сега можем да видим спестяването на дисково пространство:
SELECT [o].[name], [i].[index_id], [i].[name], [p].[rows], (8*SUM([au].[used_pages]))/1024 AS [IndexSize(MB)], [p].[data_compression_desc] FROM [sys].[allocation_units] [au] JOIN [sys].[partitions] [p] ON [au].[container_id] = [p].[partition_id] JOIN [sys].[objects] [o] ON [p].[object_id] = [o].[object_id] JOIN [sys].[indexes] [i] ON [p].[object_id] = [i].[object_id] AND [p].[index_id] = [i].[index_id] WHERE [o].[is_ms_shipped] = 0 GROUP BY [o].[name], [i].[index_id], [i].[name], [p].[rows], [p].[data_compression_desc] ORDER BY [i].[index_id], [IndexSize(MB)] DESC;
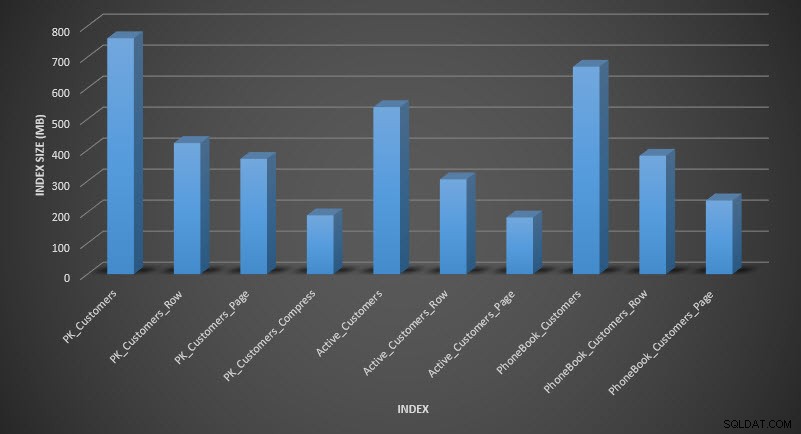 Размер на индекса след компресиране
Размер на индекса след компресиране
Както се очакваше, компресирането на редове и страници значително намалява размера на таблицата и нейните индекси. Функцията COMPRESS ни спести най-много място – клъстерираният индекс е една четвърт от размера на оригиналната таблица.
ПРОМЛЕЖДАНЕ НА ЕФЕКТИВНОСТТА НА ЗАЯВКАТА
Преди да тестваме ефективността на заявката, имайте предвид, че можем да използваме Query Store, за да разгледаме производителността INSERT и REBUILD:
SELECT [q].[query_id], [qt].[query_sql_text], SUM([rs].[count_executions]) [ExecutionCount], AVG([rs].[avg_duration])/1000 [AvgDuration_ms], AVG([rs].[avg_cpu_time]) [AvgCPU], AVG([rs].[avg_logical_io_reads]) [AvgLogicalReads], AVG([rs].[avg_physical_io_reads]) [AvgPhysicalReads] FROM [sys].[query_store_query] [q] JOIN [sys].[query_store_query_text] [qt] ON [q].[query_text_id] = [qt].[query_text_id] LEFT OUTER JOIN [sys].[objects] [o] ON [q].[object_id] = [o].[object_id] JOIN [sys].[query_store_plan] [p] ON [q].[query_id] = [p].[query_id] JOIN [sys].[query_store_runtime_stats] [rs] ON [p].[plan_id] = [rs].[plan_id] WHERE [qt].[query_sql_text] LIKE '%INSERT%' OR [qt].[query_sql_text] LIKE '%ALTER%' GROUP BY [q].[query_id], [q].[object_id], [o].[name], [qt].[query_sql_text], [rs].[plan_id] ORDER BY [q].[query_id];
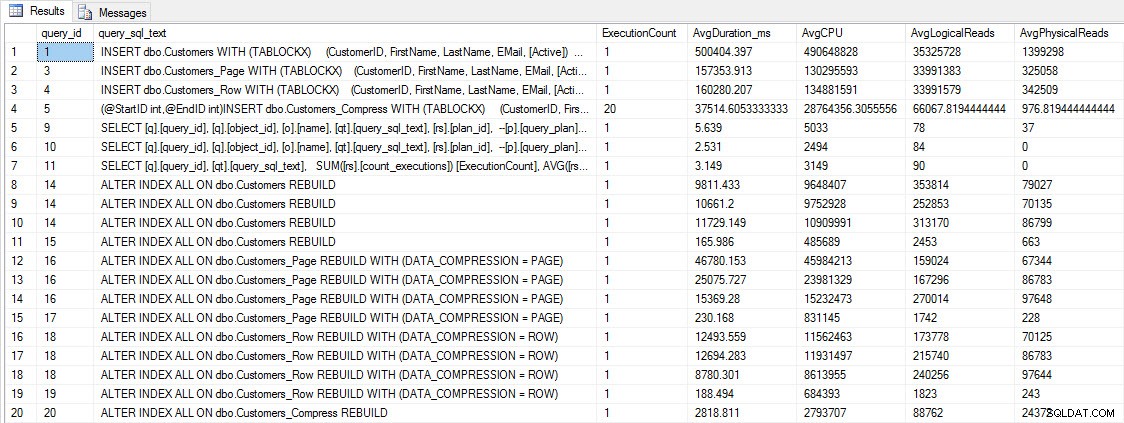 Показатели за ефективността INSERT и REBUILD
Показатели за ефективността INSERT и REBUILD
Въпреки че тези данни са интересни, аз съм по-любопитен как компресирането влияе на ежедневните ми SELECT заявки. Имам набор от три съхранени процедури, всяка от които има една заявка SELECT, така че всеки индекс да се използва. Създадох тези процедури за всяка таблица и след това написах скрипт за изтегляне на стойности за собствени и фамилни имена, които да използвам за тестване. Ето скрипта за създаване на процедурите.
След като създадем съхранените процедури, можем да изпълним скрипта по-долу, за да ги извикаме. Започнете това и след това изчакайте няколко минути...
SET NOCOUNT ON; GO DECLARE @RowNum INT = 1; DECLARE @Round INT = 1; DECLARE @ID INT = 1; DECLARE @FN NVARCHAR(64); DECLARE @LN NVARCHAR(64); DECLARE @SQLstring NVARCHAR(MAX); DROP TABLE IF EXISTS #FirstNames, #LastNames; SELECT DISTINCT [FirstName], DENSE_RANK() OVER (ORDER BY [FirstName]) AS RowNum INTO #FirstNames FROM [dbo].[Customers] SELECT DISTINCT [LastName], DENSE_RANK() OVER (ORDER BY [LastName]) AS RowNum INTO #LastNames FROM [dbo].[Customers] WHILE 1=1 BEGIN SELECT @FN = ( SELECT [FirstName] FROM #FirstNames WHERE RowNum = @RowNum) SELECT @LN = ( SELECT [LastName] FROM #LastNames WHERE RowNum = @RowNum) SET @FN = SUBSTRING(@FN, 1, 5) + '%' SET @LN = SUBSTRING(@LN, 1, 5) + '%' EXEC [dbo].[usp_FindActiveCustomer_C] @FN; EXEC [dbo].[usp_FindAnyCustomer_C] @LN; EXEC [dbo].[usp_FindSpecificCustomer_C] @ID; EXEC [dbo].[usp_FindActiveCustomer_P] @FN; EXEC [dbo].[usp_FindAnyCustomer_P] @LN; EXEC [dbo].[usp_FindSpecificCustomer_P] @ID; EXEC [dbo].[usp_FindActiveCustomer_R] @FN; EXEC [dbo].[usp_FindAnyCustomer_R] @LN; EXEC [dbo].[usp_FindSpecificCustomer_R] @ID; EXEC [dbo].[usp_FindActiveCustomer_CS] @FN; EXEC [dbo].[usp_FindAnyCustomer_CS] @LN; EXEC [dbo].[usp_FindSpecificCustomer_CS] @ID; IF @ID < 5000000 BEGIN SET @ID = @ID + @Round END ELSE BEGIN SET @ID = 2 END IF @Round < 26 BEGIN SET @Round = @Round + 1 END ELSE BEGIN IF @RowNum < 2260 BEGIN SET @RowNum = @RowNum + 1 SET @Round = 1 END ELSE BEGIN SET @RowNum = 1 SET @Round = 1 END END END GO
След няколко минути погледнете какво има в магазина за заявки:
SELECT [q].[query_id], [q].[object_id], [o].[name], [qt].[query_sql_text], SUM([rs].[count_executions]) [ExecutionCount], CAST(AVG([rs].[avg_duration])/1000 AS DECIMAL(10,2)) [AvgDuration_ms], CAST(AVG([rs].[avg_cpu_time]) AS DECIMAL(10,2)) [AvgCPU], CAST(AVG([rs].[avg_logical_io_reads]) AS DECIMAL(10,2)) [AvgLogicalReads], CAST(AVG([rs].[avg_physical_io_reads]) AS DECIMAL(10,2)) [AvgPhysicalReads] FROM [sys].[query_store_query] [q] JOIN [sys].[query_store_query_text] [qt] ON [q].[query_text_id] = [qt].[query_text_id] JOIN [sys].[objects] [o] ON [q].[object_id] = [o].[object_id] JOIN [sys].[query_store_plan] [p] ON [q].[query_id] = [p].[query_id] JOIN [sys].[query_store_runtime_stats] [rs] ON [p].[plan_id] = [rs].[plan_id] WHERE [q].[object_id] <> 0 GROUP BY [q].[query_id], [q].[object_id], [o].[name], [qt].[query_sql_text], [rs].[plan_id] ORDER BY [o].[name];
Ще видите, че повечето съхранени процедури са се изпълнили само 20 пъти, защото две процедури срещу [dbo].[Customers_Compress] са наистина бавен. Това не е изненада; нито [FirstName], нито [LastName] са индексирани, така че всяка заявка ще трябва да сканира таблицата. Не искам тези две заявки да забавят тестването ми, така че ще променя работното натоварване и ще коментирам EXEC [dbo].[usp_FindActiveCustomer_CS] и EXEC [dbo].[usp_FindAnyCustomer_CS] и след това ще го стартирам отново. Този път ще го оставя да работи за около 10 минути и когато отново погледна изхода на Query Store, сега имам добри данни. Необработените числа са по-долу, с графиките на любимите на мениджъра по-долу.
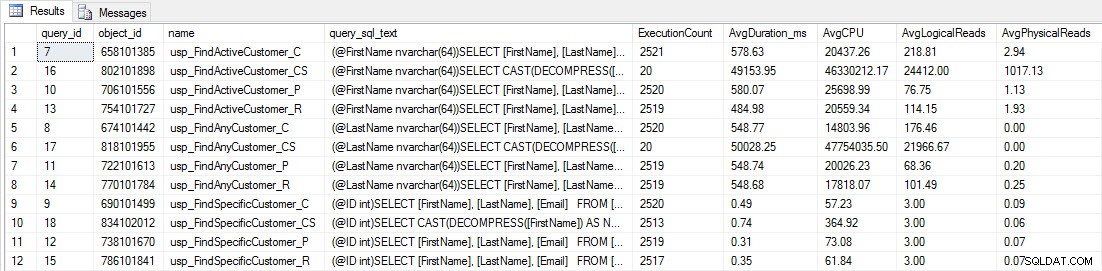 Данни за ефективността от Query Store
Данни за ефективността от Query Store
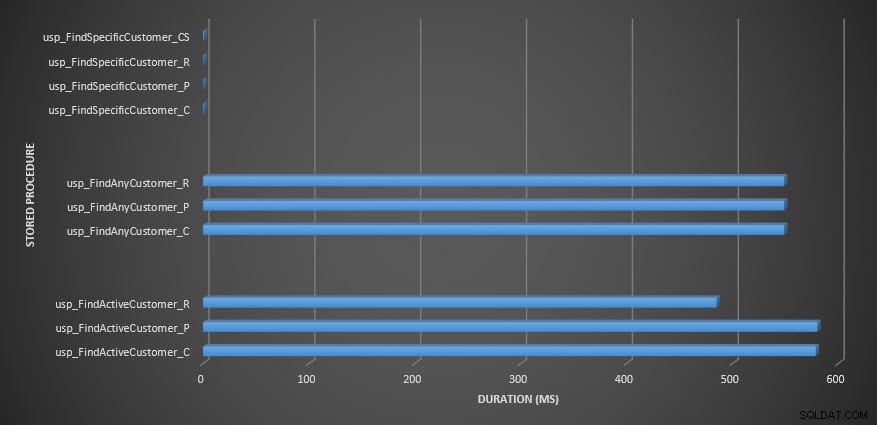 Продължителност на съхранената процедура
Продължителност на съхранената процедура
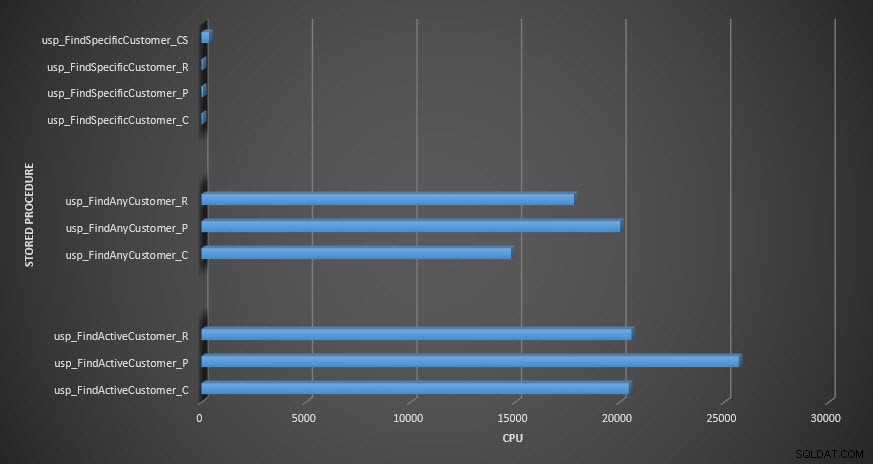 ЦП със съхранена процедура
ЦП със съхранена процедура
Напомняне:Всички съхранени процедури, които завършват с _C, са от некомпресираната таблица. Процедурите, завършващи с _R, са таблицата с компресиран ред, тези, завършващи с _P, са компресирани на страница, а тази с _CS използва функцията COMPRESS (махнах резултатите за споменатата таблица за usp_FindAnyCustomer_CS и usp_FindActiveCustomer_CS, тъй като те изкривиха графиката толкова много, че загубихме разлики в останалите данни). Процедурите usp_FindAnyCustomer_* и usp_FindActiveCustomer_* използваха неклъстерирани индекси и връщаха хиляди редове за всяко изпълнение.
Очаквах продължителността да бъде по-висока за процедурите usp_FindAnyCustomer_* и usp_FindActiveCustomer_* спрямо компресирани таблици на редове и страници, в сравнение с некомпресираната таблица, поради излишните разходи за декомпресиране на данните. Данните от хранилището на заявки не подкрепят очакванията ми – продължителността на тези две съхранени процедури е приблизително еднаква (или по-малко в един случай!) в тези три таблици. Логическата IO за заявките беше почти еднаква в некомпресираните таблици и таблици с компресирани страници и редове.
По отношение на CPU, в съхранените процедури usp_FindActiveCustomer и usp_FindAnyCustomer винаги е било по-високо за компресираните таблици. CPU беше сравним с процедурата usp_FindSpecificCustomer, която винаги беше еднократно търсене спрямо клъстерирания индекс. Обърнете внимание на високия CPU (но относително ниска продължителност) за процедурата usp_FindSpecificCustomer спрямо таблицата [dbo].[Customer_Compress], която изисква функцията DECOMPRESS за показване на данните в четим формат.
ОБОБЩЕНИЕ
Допълнителният процесор, необходим за извличане на компресирани данни, съществува и може да бъде измерен с помощта на Query Store или традиционните базови методи. Въз основа на това първоначално тестване, процесорът е сравним за еднократно търсене, но се увеличава с повече данни. Исках да принудя SQL Server да декомпресира повече от само 10 страници – исках поне 100. Изпълних вариации на този скрипт, където бяха върнати десетки хиляди редове и констатациите бяха в съответствие с това, което виждате тук. Моето очакване е, че за да видите значителни разлики в продължителността поради времето за декомпресиране на данните, заявките ще трябва да върнат стотици хиляди или милиони редове. Ако сте в OLTP система, не искате да връщате толкова много редове, така че тестовете тук трябва да ви дадат представа как компресията може да повлияе на производителността. Ако сте в склад за данни, тогава вероятно ще видите по-висока продължителност заедно с по-високия процесор при връщане на големи набори от данни. Докато функцията COMPRESS осигурява значителни спестявания на пространство в сравнение с компресирането на страници и редове, по-високата производителност по отношение на процесора и невъзможността за индексиране на компресираните колони поради техния тип данни, я правят жизнеспособна само за големи обеми данни, които няма да бъдат търсен.