Когато потребителите искат данни от система, те обикновено обичат да ги виждат в определен ред... дори когато връщат хиляди редове. Както много администратори на база данни и разработчици знаят, ORDER BY може да внесе хаос в плана на заявката, тъй като изисква сортирането на данните. Това понякога може да изисква оператор SORT като част от изпълнението на заявка, което може да бъде скъпа операция, особено ако оценките са изключени и се разлива на диск. В идеалния свят данните вече са сортирани благодарение на индекс (индексите и сортирането са много взаимно допълващи се). Често говорим за създаване на покриващ индекс, за да удовлетвори заявка – така че оптимизаторът да не трябва да се връща към основната таблица или клъстерирания индекс, за да получи допълнителни колони. И може би сте чували хората да казват, че редът на колоните в индекса има значение. Замисляли ли сте се как това се отразява на вашите SORT операции?
Разглеждане на ORDER BY и сортиране
Ще започнем с ново копие на базата данни AdventureWorks2014 на екземпляр на SQL Server 2014 (версия 12.0.2000). Ако изпълним проста заявка SELECT срещу Sales.SalesOrderHeader без ORDER BY, виждаме обикновено старо сканиране на клъстериран индекс (с помощта на SQL Sentry Plan Explorer):
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader];
 Запитване без ORDER BY, клъстерно сканиране на индекс
Запитване без ORDER BY, клъстерно сканиране на индекс
Сега нека добавим ORDER BY, за да видим как се променя планът:
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] ORDER BY [CustomerID];
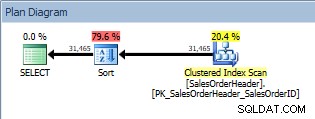 Заявка с ORDER BY, клъстерно сканиране на индекс и сортиране
Заявка с ORDER BY, клъстерно сканиране на индекс и сортиране
В допълнение към Clustered Index Scan, сега имаме сортиране, въведено от оптимизатора, и неговата прогнозна цена е значително по-висока от тази на сканирането. Сега прогнозната цена е току-що изчислена и тук не можем да кажем с абсолютна сигурност, че сортирането е отнело 79,6% от цената на заявката. За да разберем наистина колко скъпо е сортирането, ще трябва да разгледаме и IO STATISTICS, което е извън днешната цел.
Сега, ако това беше заявка, която се изпълняваше често във вашата среда, вероятно бихте помислили за добавяне на индекс, който да го поддържа. В този случай няма клауза WHERE, ние просто извличаме четири колони и подреждаме по една от тях. Логичен първи опит за индекс би бил:
CREATE NONCLUSTERED INDEX [IX_SalesOrderHeader_CustomerID_OrderDate_SubTotal] ON [Sales].[SalesOrderHeader]( [CustomerID] ASC) INCLUDE ( [OrderDate], [SubTotal]);
Ще изпълним отново нашата заявка, след като добавим индекса, който има всички колони, които искаме, и не забравяйте, че индексът е свършил работата по сортиране на данните. Сега виждаме индексно сканиране спрямо нашия нов неклъстериран индекс:
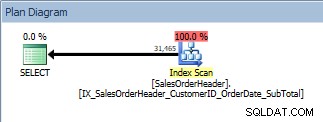 Запитване с ORDER BY, новият неклъстериран индекс се сканира
Запитване с ORDER BY, новият неклъстериран индекс се сканира
Това е добра новина. Но какво се случва, ако някой промени тази заявка – или защото потребителите могат да посочат по какви колони искат да подредят, или защото е поискана промяна от разработчик? Например, може би потребителите искат да видят CustomerID и SalesOrderID в низходящ ред:
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] ORDER BY [CustomerID] DESC, [SalesOrderID] DESC;
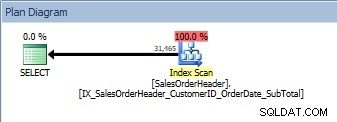 Заявка с две колони в ORDER BY, новият неклъстериран индекс се сканира
Заявка с две колони в ORDER BY, новият неклъстериран индекс се сканира
Имаме същия план; не е добавен оператор за сортиране. Ако разгледаме индекса, използвайки sp_helpindex на Кимбърли Трип (някои колони се свиха, за да спестят място), можем да видим защо планът не се е променил:
 Изход на sp_helpindex
Изход на sp_helpindex
Ключовата колона за индекса е CustomerID, но тъй като SalesOrderID е ключовата колона за клъстерирания индекс, тя също е част от ключа на индекса, така че данните се сортират по CustomerID, след това по SalesOrderID. Заявката изисква данните, сортирани по тези две колони, в низходящ ред. Индексът е създаден с нарастващи и двете колони, но тъй като това е двусвързан списък, индексът може да се чете назад. Можете да видите това в панела със свойства в Management Studio за оператора за сканиране на неклъстериран индекс:
 Екранът със свойства на неклъстерното сканиране на индекса, показващ, че е било обратно
Екранът със свойства на неклъстерното сканиране на индекса, показващ, че е било обратно
Чудесно, няма проблеми с тази заявка... но какво ще кажете за тази:
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] ORDER BY [CustomerID] DESC, [SalesOrderID] ASC;
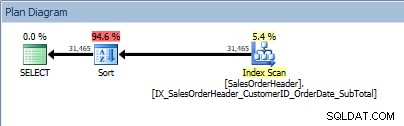 Заявка с две колони в ORDER BY и се добавя сортиране
Заявка с две колони в ORDER BY и се добавя сортиране
Нашият оператор SORT се появява отново, тъй като данните, идващи от индекса, не са сортирани в поискания ред. Ще видим същото поведение, ако сортираме по една от включените колони:
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] ORDER BY [CustomerID] ASC, [OrderDate] ASC;
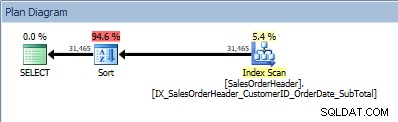 Заявка с две колони в ORDER BY и се добавя сортиране
Заявка с две колони в ORDER BY и се добавя сортиране
Какво ще стане, ако (най-накрая) добавим предикат и леко променим нашия ORDER BY?
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] WHERE [CustomerID] = 13464 ORDER BY [SalesOrderID];
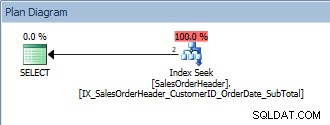 Заявка с един предикат и ORDER BY
Заявка с един предикат и ORDER BY
Тази заявка е наред, защото отново SalesOrderID е част от индексния ключ. За този CustomerID данните вече са подредени от SalesOrderID. Ами ако потърсим набор от CustomerID, сортирани по SalesOrderID?
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] WHERE [CustomerID] BETWEEN 13464 AND 13466 ORDER BY [SalesOrderID];
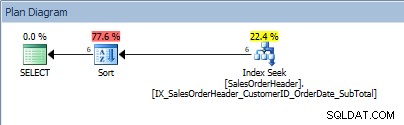 Запитване с диапазон от стойности в предиката и ORDER BY
Запитване с диапазон от стойности в предиката и ORDER BY
Плъхове, нашият SORT се завръща. Фактът, че данните са подредени от CustomerID само помага при търсене на индекса за намиране на този диапазон от стойности; за ORDER BY SalesOrderID оптимизаторът трябва да вметне сортирането, за да постави данните в заявения ред.
Сега в този момент може би се чудите защо съм фиксиран върху оператора Sort, който се появява в плановете за заявка. Това е защото е скъпо. Може да бъде скъпо по отношение на ресурси (памет, IO) и/или продължителност.
Продължителността на заявката може да бъде повлияна от сортиране, тъй като това е операция спиране и тръгване. Целият набор от данни трябва да бъде сортиран, преди да може да се извърши следващата операция в плана. Ако трябва да се поръчат само няколко реда данни, това не е толкова голяма работа. Ако са хиляди или милиони редове? Сега чакаме.
В допълнение към общата продължителност на заявката, трябва да помислим и за използването на ресурсите. Нека вземем 31 465 реда, с които работихме, и ги натиснем в таблична променлива, след което изпълним тази първоначална заявка с ORDER BY на CustomerID:
DECLARE @t TABLE (CustomerID INT, SalesOrderID INT, OrderDate DATETIME, SubTotal MONEY); INSERT @t SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader]; SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM @t ORDER BY [CustomerID];
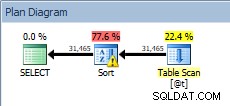 Запитване към променливата на таблицата, със сортиране
Запитване към променливата на таблицата, със сортиране
Нашият SORT се завръща и този път има предупреждение (обърнете внимание на жълтия триъгълник с удивителния знак). Предупрежденията не са добри. Ако погледнем свойствата от този сорт, можем да видим предупреждение „Операторът използва tempdb за разпръскване на данни по време на изпълнение с ниво на разлив 1“:
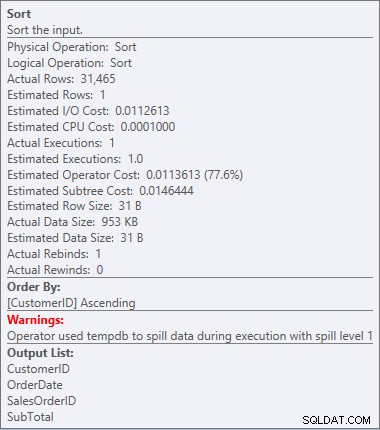 Предупреждение за сортиране
Предупреждение за сортиране
Това не е нещо, което искам да видя в план. Оптимизаторът направи оценка колко място ще му е необходимо в паметта, за да сортира данните, и поиска тази памет. Но когато всъщност разполагаше с всички данни и отиде да ги сортира, двигателят осъзна, че няма достатъчно памет (оптимизаторът поиска твърде малко!), така че операцията Сортиране се разля. В някои случаи това може да се разлее на диск, което означава четене и запис, които са бавни. Не само, че чакаме само да подредим данните, но е още по-бавно, защото не можем да направим всичко в паметта. Защо оптимизаторът не поиска достатъчно памет? Имаше лоша оценка за данните, които трябваше да сортира:
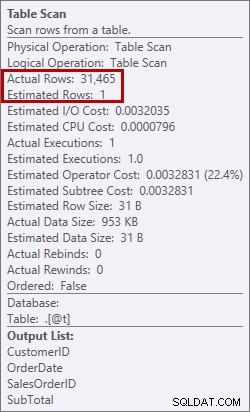 Оценка на 1 ред спрямо действителните 31 465 реда
Оценка на 1 ред спрямо действителните 31 465 реда
В този случай принудих лоша оценка, като използвах таблична променлива. Известни са проблеми със статистическите оценки и променливите на таблицата (Аарон Бертран има страхотна публикация относно опциите за опити за справяне с това) и тук оптимизаторът смяташе, че от сканирането на таблицата ще бъде върнат само 1 ред, а не 31 465.
Опции
И така, какво можете да направите, като DBA или разработчик, за да избегнете SORTs в плановете си за заявки? Бързият отговор е „Не поръчвайте данните си“. Но това не винаги е реалистично. В някои случаи можете да разтоварите това сортиране на клиента или на приложния слой – но потребителите все още трябва да чакат, за да сортират данните в този слой. В ситуациите, когато не можете да промените как работи приложението, можете да започнете, като разгледате вашите индекси.
Ако поддържате приложение, което позволява на потребителите да изпълняват ad-hoc заявки или променяте реда на сортиране, така че да могат да виждат данните, подредени така, както искат... ще имате най-трудното време (но това не е загубена кауза, така че не спирайте да четете все още!). Не можете да индексирате за всяка опция. Това е неефективно и ще създадете повече проблеми, отколкото решите. Най-добрият залог тук е да говорите с потребителите (знам, че понякога е страшно да напуснете ъгъла на гората, но опитайте). За заявките, които потребителите изпълняват най-често, разберете как обикновено обичат да виждат данните. Да, можете да получите това и от кеша на плановете – можете да извличате заявки и планове, докато сте доволни, за да видите какво правят. Но е по-бързо да се говори с потребителите. Допълнителното предимство е, че можете да обясните защо питате и защо тази идея да „сортирам по всички колони, защото мога“ не е толкова добра. Да знаеш е половината от битката. Ако можете да отделите известно време за обучение на вашите опитни потребители и потребителите, които обучават нови хора, може да успеете да направите нещо добро.
Ако поддържате приложение с ограничени опции ORDER BY, тогава можете да направите реален анализ. Прегледайте какви вариации на ORDER BY съществуват, определете кои комбинации се изпълняват най-често и индексирайте, за да поддържате тези заявки. Вероятно няма да ударите всеки един, но все пак можете да окажете влияние. Можете да направите още една крачка напред, като говорите с вашите разработчици и ги обучите за проблема и как да го решат.
И накрая, когато разглеждате планове за заявки с операции SORT, не се фокусирайте само върху премахването на сортирането. Вижте къде Сортирането се случва в плана. Ако това се случи отляво на плана и е типично няколко реда, може да има други области с по-голям фактор на подобрение, върху които да се съсредоточите. Сортирането вляво е моделът, върху който се фокусирахме днес, но сортирането не винаги се случва поради ORDER BY. Ако видите сортиране в най-дясната част на плана и има много редове, движещи се през тази част от плана, знаете, че сте намерили добро място да започнете настройката.