Случвало ли ви се е да се сблъскате със ситуация, в която трябва да управлявате състоянието на обект, което се променя с течение на времето? Има много примери. Нека започнем с едно лесно:сливане на клиентски записи.
Да предположим, че обединяваме списъци с клиенти от два различни източника. Може да възникне някое от следните състояния:Идентифицирани дубликати – системата е открила два потенциално дублиращи се субекта; Потвърдени дубликати – потребител потвърждава, че двете единици наистина са дублирани; или Потвърден уникален – потребителят решава, че двете единици са уникални. Във всяка от тези ситуации потребителят може да вземе само решение да/не.
Но какво да кажем за по-сложните ситуации? Има ли начин да се дефинира действителният работен поток между състоянията? Прочетете...
Как нещата могат лесно да се объркат
Много организации трябва да управляват заявленията за работа. В прост модел бихте могли да имате таблица, наречена JOB_APPLICATION , и можете да проследявате състоянието на приложението, като използвате таблица с референтни данни, съдържаща стойности като тези:
| Състояние на приложението |
|---|
APPLICATION_RECEIVED |
APPLICATION_UNDER_REVIEW |
APPLICATION_REJECTED |
INVITED_TO_INTERVIEW |
INVITATION_DECLINED |
INVITATION_ACCEPTED |
INTERVIEW_PASSED |
INTERVIEW_FAILED |
REFERENCES_SOUGHT |
REFERENCES_ACCEPTABLE |
REFERENCES_UNACCEPTABLE |
JOB_OFFER_MADE |
JOB_OFFER_ACCEPTED |
JOB_OFFER_DECLINED |
APPLICATION_CLOSED |
Тези стойности могат да бъдат избрани в произволен ред по всяко време. Той разчита на крайните потребители да гарантират, че на всеки етап се прави логичен и правилен избор. Нищо не забранява нелогична последователност от състояния.
Например, да кажем, че заявлението е отхвърлено. Текущото състояние очевидно би било APPLICATION_REJECTED . Не може да се направи нищо на ниво приложение, за да се попречи на неопитен потребител впоследствие да избере INVITED_TO_INTERVIEW или някакво друго нелогично състояние.
Това, което е необходимо, е нещо, което да насочи потребителя да избере следващото логическо състояние, нещо, което дефинира логически работен поток .
И какво ще стане, ако имате различни изисквания към различните видове кандидатури за работа? Например, някои работни места може да изискват от кандидата да премине тест за правоспособност. Разбира се, можете да добавите още стойности към списъка, за да ги покриете, но в настоящия дизайн няма нищо, което да пречи на крайния потребител да направи неправилен избор за въпросния тип приложение. Реалността е, че имаразлични работни процеси за различни контексти .
Друг момент, върху който трябва да помислите:изброените опции наистина ли са всички състояния ? Или са някои действителнорезултати ? Например, предложението за работа може да бъде прието или отхвърлено от кандидата. Следователно, JOB_OFFER_MADE наистина има два резултата:JOB_OFFER_ACCEPTED и JOB_OFFER_DECLINED .
Друг резултат може да бъде оттеглянето на предложение за работа. Може да искате да запишете причината, поради която е била оттеглена, като използвате квалификатор. Ако просто добавите тези причини към горния списък, нищо не насочва крайния потребител да прави логически избор.
Така че наистина, колкото по-сложни стават състоянията, резултатите и квалификациите, толкова повече трябва да дефинирате работния поток на процеса .
Организиране на процеси, състояния и резултати
Важно е да разберете какво се случва с вашите данни, преди да се опитате да ги моделирате. Отначало може да сте склонни да мислите, че тук има строга йерархия от типове:
Когато разгледаме по-отблизо горния пример, виждаме, че INVITED_TO_INTERVIEW и JOB_OFFER_MADE държавите споделят едни и същи възможни резултати, а именно ACCEPTED и DECLINED . Това ни казва, че има връзка много към много между състояния и резултати. Това често е вярно за други състояния, резултати и квалификации.
Тогава на концептуално ниво това всъщност се случва с нашите метаданни:
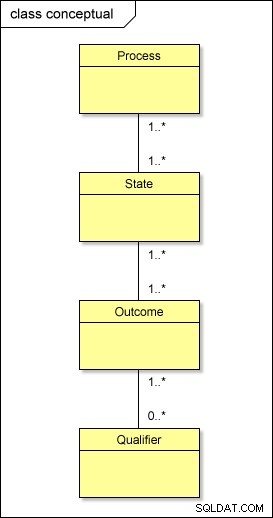
Ако трябваше да трансформирате този модел във физическия свят, използвайки стандартния подход, ще имате таблици, наречени PROCESS , STATE , OUTCOME и QUALIFIER; ще трябва да имате и междинни маси между тях – PROCESS_STATE , STATE_OUTCOME и OUTCOME_QUALIFIER –за разрешаване на връзките много към много . Това усложнява дизайна.
Докато логическата йерархия на нивата (процес → състояние → резултат → квалификатор) трябва да се поддържа, има по-прост начин за физическо организиране на нашите метаданни.
Моделът на работния процес
Диаграмата по-долу дефинира основните компоненти на модел на база данни на работния процес:
Жълтите таблици вляво съдържат метаданни за работния процес, а сините таблици вдясно съдържат бизнес данни.
Първото нещо, което трябва да се отбележи, е, че всяко лице може да се управлява без да се налагат големи промени в този модел. YOUR_ENTITIY_TO_MANAGE таблицата е тази под управление на работния поток. По отношение на нашия пример, това би било JOB_APPLICATION маса.
След това просто трябва да добавим wf_state_type_process_id колона към всяка таблица, която искаме да управляваме. Тази колона сочи към действителния процес на работния процес се използва за управление на субекта. Това не е строго колона за външен ключ, но ни позволява бързо да заявим WORKFLOW_STATE_TYPE за правилния процес. Таблицата, която ще съдържа историята на състоянието е MANAGED_ENTITY_STATE . Отново, вие ще изберете вашето собствено конкретно име на таблица тук и ще го промените според вашите собствени изисквания.
Метаданните
Различните нива на работен поток са дефинирани в WORKFLOW_LEVEL_TYPE . Тази таблица съдържа следното:
| Ключ за тип | Описание |
|---|---|
| ПРОЦЕС | Процес на работен поток на високо ниво. |
| ДЪРЖАВА | Състояние в процеса. |
| ИЗХОД | Как завършва едно състояние, неговият резултат. |
| КВАЛИФИКАТОР | Незадължителен, по-подробен квалификатор за резултат. |
WORKFLOW_STATE_TYPE и WORKFLOW_STATE_HIERARCHY формираткласическа структура на спецификациите (BOM) . Тази структура, която е много описателна за действителната производствена спецификация, е доста често срещана при моделирането на данни. Може да дефинира йерархии или да се прилага към много рекурсивни ситуации. Ще го използваме тук, за да дефинираме нашата логическа йерархия от процеси, състояния, резултати и незадължителни квалификатори.
Преди да можем да дефинираме йерархия, трябва да дефинираме отделните компоненти. Това са нашите основни градивни елементи. Просто ще ги посоча чрез TYPE_KEY (което е уникално) за краткост. За нашия пример имаме:
| Тип ниво на работния поток | Тип.Тип на състоянието на работния поток |
|---|---|
| ИЗХОД | ПРЕДЪРЖДАНО |
| ИЗХОД | НЕУСПЕШНО |
| ИЗХОД | ПРИЕМАНО |
| ИЗХОД | ОТКЛИНА |
| ИЗХОД | CANDIDATE_CANCELLED |
| ИЗХОД | EMPLOYER_CANCELLED |
| ИЗХОД | ОТХВЪРЛЕНО |
| ИЗХОД | РАБОТОДАТЕЛ_ОТТЕГЛЯН |
| ИЗХОД | НЕ_ШОУ |
| ИЗХОД | НАЕТИ |
| ИЗХОД | НЕ_НАЕТИ |
| ДЪРЖАВА | APPLICATION_RECEIVED |
| ДЪРЖАВА | ПРЕГЛЕД НА APPLICATION_PREGLED |
| ДЪРЖАВА | INVITED_TO_INTERVIEW |
| ДЪРЖАВА | ИНТЕРВЮ |
| ДЪРЖАВА | TEST_APTITUDE |
| ДЪРЖАВА | SEEK_REFERENCES |
| ДЪРЖАВА | ПРАВЕТЕ_ПРЕДЛОЖЕНИЕ |
| ДЪРЖАВА | APPLICATION_CLOSED |
| ПРОЦЕС | STANDARD_JOB_APPLICATION |
| ПРОЦЕС | ТЕХНИЧЕСКО_ЗАДАННО_ПРИЛОЖЕНИЕ |
Сега можем да започнем да дефинираме нашата йерархия. Тук вземаме нашите градивни елементи и дефинираме нашата структура. За всяко състояние ние дефинираме възможните резултати. Всъщност правилото на тази система на работния процес е, че всяко състояние трябва да приключи с резултат:
| Тип родител – STATES | Тип дете – РЕЗУЛТАТИ |
|---|---|
| APPLICATION_RECEIVED | ПРИЕМАНО |
| APPLICATION_RECEIVED | ОТХВЪРЛЕНО |
| ПРЕГЛЕД НА APPLICATION_PREGLED | ПРЕДЪРЖДАНО |
| ПРЕГЛЕД НА APPLICATION_PREGLED | НЕУСПЕШНО |
| ПОКАНЕНИ_ЗА_ИНТЕРЕВЮ | ПРИЕМАНО |
| ПОКАНЕНИ_ЗА_ИНТЕРЕВЮ | ОТКЛИНА |
| ИНТЕРВЮ | ПРЕДЪРЖДАНО |
| ИНТЕРВЮ | НЕУСПЕШНО |
| ИНТЕРВЮ | CANDIDATE_CANCELLED |
| ИНТЕРВЮ | НЕ_ШОУ |
| НАПРАВЕТЕ_ПРЕДЛОЖЕНИЕ | ПРИЕМАНО |
| НАПРАВЕТЕ_ПРЕДЛОЖЕНИЕ | ОТКЛИНА |
| SEEK_REFERENCES | ПРЕДЪРЖДАНО |
| SEEK_REFERENCES | НЕУСПЕШНО |
| APPLICATION_CLOSED | НАЕТИ |
| APPLICATION_CLOSED | НЕ_НАЕТИ |
| TEST_APTITUDE | ПРЕДЪРЖДАНО |
| TEST_APTITUDE | НЕУСПЕШНО |
Нашите процеси са просто набор от състояния, всяко от които съществува за определен период от време. В таблицата по-долу те са представени в логически ред, но това не определя действителния ред на обработка.
| Тип родител – PROCESSES | Тип дете – STATES |
|---|---|
| STANDARD_JOB_APPLICATION | APPLICATION_RECEIVED |
| STANDARD_JOB_APPLICATION | ПРЕГЛЕД НА APPLICATION_PREGLED |
| STANDARD_JOB_APPLICATION | INVITED_TO_INTERVIEW |
| STANDARD_JOB_APPLICATION | ИНТЕРВЮ |
| STANDARD_JOB_APPLICATION | ПРАВЕТЕ_ПРЕДЛОЖЕНИЕ |
| STANDARD_JOB_APPLICATION | SEEK_REFERENCES |
| STANDARD_JOB_APPLICATION | APPLICATION_CLOSED |
| ТЕХНИЧЕСКО_РАБОТА_ПРИЛОЖЕНИЕ | APPLICATION_RECEIVED |
| ТЕХНИЧЕСКО_РАБОТА_ПРИЛОЖЕНИЕ | ПРЕГЛЕД НА APPLICATION_PREGLED |
| ТЕХНИЧЕСКО_РАБОТА_ПРИЛОЖЕНИЕ | INVITED_TO_INTERVIEW |
| ТЕХНИЧЕСКО_РАБОТА_ПРИЛОЖЕНИЕ | TEST_APTITUDE |
| ТЕХНИЧЕСКО_РАБОТА_ПРИЛОЖЕНИЕ | ИНТЕРВЮ |
| ТЕХНИЧЕСКО_РАБОТА_ПРИЛОЖЕНИЕ | ПРАВЕТЕ_ПРЕДЛОЖЕНИЕ |
| ТЕХНИЧЕСКО_РАБОТА_ПРИЛОЖЕНИЕ | SEEK_REFERENCES |
| ТЕХНИЧЕСКО_РАБОТА_ПРИЛОЖЕНИЕ | APPLICATION_CLOSED |
Има важен момент, който трябва да се направи по отношение на йерархията на спецификацията. Точно както физическата спецификация на материалите дефинира възли и под-възли до най-малките компоненти, ние имаме подобно подреждане в нашата йерархия. Това означава, че можем да използваме повторно „сглобки“ и „под-сглобки“.
Като пример:И двата STANDARD_JOB_APPLICATION и TECHNICAL_JOB_APPLICATION процеси имате INTERVIEW състояние . От своя страна INTERVIEW състояние има PASSED , FAILED , CANDIDATE_CANCELLED и NO_SHOW резултати определени за него.
Когато използвате състояние в процес, вие автоматично получавате неговите дъщерни резултати с него, защото вече е сбор. Това означава, че има едни и същи резултати и за двата типа кандидатстване за работа на INTERVIEW сцена. Ако искате различни резултати от интервюта за различни типове кандидатури за работа, трябва да дефинирате, да речем, TECHNICAL_INTERVIEW и STANDARD_INTERVIEW заявява, че всеки има свои специфични резултати.
В този пример единствената разлика между двата типа заявления за работа е, че техническото заявление за работа включва тест за правоспособност.
Преди да тръгнете
Част 1 на тази статия от две части представя модела на база данни на работния процес. Той показа как можете да го включите, за да управлявате жизнения цикъл на всеки обект във вашата база данни.
Част 2 ще ви покаже как да дефинирате действителния работен процес използване на допълнителни таблици за конфигурация. Това е мястото, където на потребителя ще бъдат представени допустимите следващи стъпки. Ще демонстрираме също така техника за заобикаляне на стриктното повторно използване на „сглобки“ и „подсглобки“ в спецификациите.