В последната си публикация показах някои ефективни подходи за групирана конкатенация. Този път исках да говоря за няколко допълнителни аспекта на този проблем, които можем лесно да постигнем с FOR XML PATH подход:подреждане на списъка и премахване на дубликати.
Има няколко начина, по които съм виждал хората да искат списъкът, разделен със запетая, да бъде подреден. Понякога те искат артикулът в списъка да бъде подреден по азбучен ред; Показах го вече в предишния си пост. Но понякога те искат да се сортира по някакъв друг атрибут, който всъщност не е въведен в изхода; например, може би искам първо да подредя списъка по най-новия артикул. Нека вземем прост пример, където имаме таблица Employees и CoffeeOrders. Нека просто попълним поръчките на един човек за няколко дни:
CREATE TABLE dbo.Employees
(
EmployeeID INT PRIMARY KEY,
Name NVARCHAR(128)
);
INSERT dbo.Employees(EmployeeID, Name) VALUES(1, N'Jack');
CREATE TABLE dbo.CoffeeOrders
(
EmployeeID INT NOT NULL REFERENCES dbo.Employees(EmployeeID),
OrderDate DATE NOT NULL,
OrderDetails NVARCHAR(64)
);
INSERT dbo.CoffeeOrders(EmployeeID, OrderDate, OrderDetails)
VALUES(1,'20140801',N'Large double double'),
(1,'20140802',N'Medium double double'),
(1,'20140803',N'Large Vanilla Latte'),
(1,'20140804',N'Medium double double');
Ако използваме съществуващия подход, без да посочим ORDER BY , получаваме произволно подреждане (в този случай най-вероятно е да видите редовете в реда, в който са били вмъкнати, но не зависи от това с по-големи набори от данни, повече индекси и т.н.):
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Резултати (не забравяйте, че може да получите *различни* резултати, освен ако не посочите ORDER BY ):
Джак | Голямо двойно двойно, Средно двойно двойно, Голямо ванилово лате, Средно двойно двойно
Ако искаме да подредим списъка по азбучен ред, това е просто; ние просто добавяме ORDER BY c.OrderDetails :
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID ORDER BY c.OrderDetails -- only change FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Резултати:
Име | ПоръчкиДжак | Голямо двойно двойно, голямо ванилово лате, средно двойно двойно, средно двойно двойно
Можем също да подредим по колона, която не се появява в набора от резултати; например, можем да поръчаме първо по най-новата поръчка на кафе:
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID ORDER BY c.OrderDate DESC -- only change FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Резултати:
Име | ПоръчкиДжак | Средно двойно двойно, голямо ванилово лате, средно двойно двойно, голямо двойно двойно
Друго нещо, което често искаме да направим, е да премахнем дубликатите; в края на краищата, има малка причина да видите "Medium double double" два пъти. Можем да премахнем това, като използваме GROUP BY :
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID GROUP BY c.OrderDetails -- removed ORDER BY and added GROUP BY here FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Сега това *се случва* да подреди изхода по азбучен ред, но отново не можете да разчитате на това:
Име | ПоръчкиДжак | Голямо двойно двойно, голямо ванилово лате, средно двойно двойно
Ако искате да гарантирате, че поръчвате по този начин, можете просто да добавите отново ORDER BY:
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID GROUP BY c.OrderDetails ORDER BY c.OrderDetails -- added ORDER BY FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Резултатите са едни и същи (но ще повторя, в този случай това е просто съвпадение; ако искате този ред, винаги го казвайте):
Име | ПоръчкиДжак | Голямо двойно двойно, голямо ванилово лате, средно двойно двойно
Но какво ще стане, ако искаме първо да премахнем дубликатите * и* да сортираме списъка по най-новата поръчка на кафе? Първото ви желание може да бъде да запазите GROUP BY и просто променете ORDER BY , като това:
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID GROUP BY c.OrderDetails ORDER BY c.OrderDate DESC -- changed ORDER BY FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Това няма да работи, тъй като OrderDate не е групиран или обобщен като част от заявката:
Колоната "dbo.CoffeeOrders.OrderDate" е невалидна в клаузата ORDER BY, защото не се съдържа нито в агрегатна функция, нито в клаузата GROUP BY.
Заобиколно решение, което действително прави заявката малко по-грозна, е първо да групирате поръчките отделно и след това да вземете само редовете с максималната дата за тази поръчка за кафе на служител:
;WITH grouped AS ( SELECT EmployeeID, OrderDetails, OrderDate = MAX(OrderDate) FROM dbo.CoffeeOrders GROUP BY EmployeeID, OrderDetails ) SELECT e.Name, Orders = STUFF((SELECT N', ' + g.OrderDetails FROM grouped AS g WHERE g.EmployeeID = e.EmployeeID ORDER BY g.OrderDate DESC FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Резултати:
Име | ПоръчкиДжак | Средно двойно двойно, голямо ванилово лате, голямо двойно двойно
Това постига и двете ни цели:елиминирахме дубликати и сме подредили списъка по нещо, което всъщност не е в списъка.
Ефективност
Може би се чудите колко зле се представят тези методи спрямо по-стабилен набор от данни. Ще попълня нашата таблица със 100 000 реда, ще видя как се справят без допълнителни индекси и след това ще изпълня същите заявки отново с малко настройка на индекса, за да поддържам нашите заявки. И така, първо, получаване на 100 000 реда, разпределени между 1000 служители:
-- clear out our tiny sample data
DELETE dbo.CoffeeOrders;
DELETE dbo.Employees;
-- create 1000 fake employees
INSERT dbo.Employees(EmployeeID, Name)
SELECT TOP (1000)
EmployeeID = ROW_NUMBER() OVER (ORDER BY t.[object_id]),
Name = LEFT(t.name + c.name, 128)
FROM sys.all_objects AS t
INNER JOIN sys.all_columns AS c
ON t.[object_id] = c.[object_id];
-- create 100 fake coffee orders for each employee
-- we may get duplicates in here for name
INSERT dbo.CoffeeOrders(EmployeeID, OrderDate, OrderDetails)
SELECT e.EmployeeID,
OrderDate = DATEADD(DAY, ROW_NUMBER() OVER
(PARTITION BY e.EmployeeID ORDER BY c.[guid]), '20140630'),
LEFT(c.name, 64)
FROM dbo.Employees AS e
CROSS APPLY
(
SELECT TOP (100) name, [guid] = NEWID()
FROM sys.all_columns
WHERE [object_id] < e.EmployeeID
ORDER BY NEWID()
) AS c; Сега нека просто стартираме всяка от нашите заявки два пъти и да видим какво е времето при втория опит (тук ще направим скок на вяра и ще приемем, че – в идеалния свят – ще работим с подготвен кеш ). Пуснах ги в SQL Sentry Plan Explorer, тъй като това е най-лесният начин, който познавам, за да преценя и сравнявам куп отделни заявки:
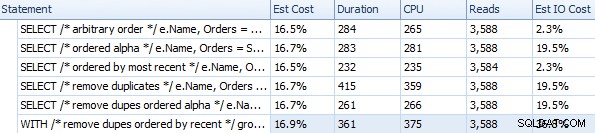 Продължителност и други показатели по време на изпълнение за различни подходи FOR XML PATH
Продължителност и други показатели по време на изпълнение за различни подходи FOR XML PATH
Тези тайминги (продължителността е в милисекунди) наистина не са толкова лоши IMHO, като се замислите какво всъщност се прави тук. Най-сложният план, поне визуално, изглеждаше този, при който премахнахме дубликати и ги сортирахме по най-нов ред:
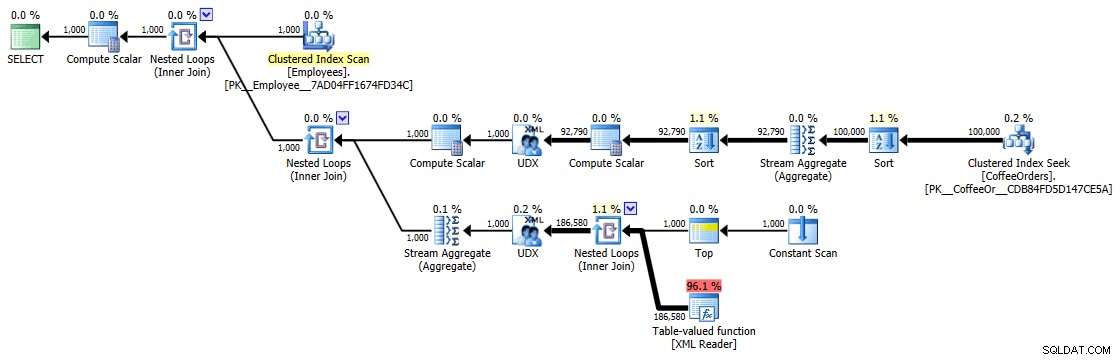 План за изпълнение на групирана и сортирана заявка
План за изпълнение на групирана и сортирана заявка
Но дори и най-скъпият оператор тук – функцията с таблица с стойност на XML – изглежда е изцяло CPU (въпреки че свободно ще призная, че не съм сигурен каква част от действителната работа е изложена в подробностите за плана на заявката):
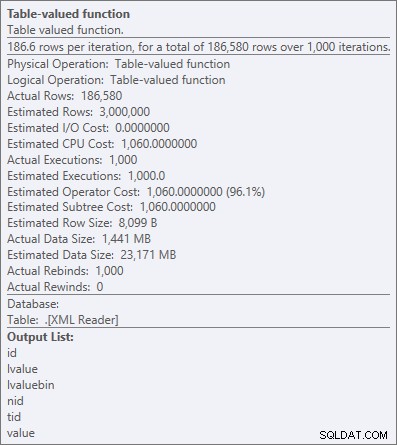 Свойства на оператора за функцията с таблица с стойност на XML
Свойства на оператора за функцията с таблица с стойност на XML
"Всички CPU" обикновено е наред, тъй като повечето системи са свързани с I/O и/или с памет, а не с CPU. Както казвам доста често, в повечето системи ще заменя част от паметта или диска на моя процесор всеки ден от седмицата (една от причините да харесвам OPTION (RECOMPILE) като решение на широко разпространените проблеми с подслушването на параметри).
Въпреки това, силно ви насърчавам да тествате тези подходи спрямо подобни резултати, които можете да получите от подхода GROUP_CONCAT CLR на CodePlex, както и да извършите агрегирането и сортирането на нивото на презентацията (особено ако поддържате нормализираните данни в някакъв вид на слоя за кеширане).