В един перфектен свят няма значение кой конкретен T-SQL синтаксис сме избрали, за да изразим заявка. Всяка семантично идентична конструкция би довела до абсолютно същия физически план за изпълнение, с точно същите характеристики на производителност.
За да постигне това, оптимизаторът на заявки на SQL Server ще трябва да знае всяка възможна логическа еквивалентност (ако приемем, че някога бихме могли да ги познаем всички) и да получи време и ресурси, за да проучи всички опции. Предвид огромния брой възможни начини, по които можем да изразим едно и също изискване в T-SQL, и огромния брой възможни трансформации, комбинациите бързо стават неуправляеми за всички, освен в най-простите случаи.
„Перфектният свят“ с пълна синтаксическа независимост може да не изглежда толкова перфектен за потребители, които трябва да чакат дни, седмици или дори години, за да се компилира една скромно сложна заявка. Така че оптимизаторът на заявки прави компромис:той изследва някои общи еквивалентности и се опитва усилено да избегне изразходването на повече време за компилация и оптимизация, отколкото спестява време за изпълнение. Целта му може да се обобщи като опит за намиране на разумен план за изпълнение в разумно време, като същевременно се изразходват разумни ресурси.
Един резултат от всичко това е, че плановете за изпълнение често са чувствителни към писмената форма на заявката. Оптимизаторът има известна логика за бързо трансформиране на някои широко използвани еквивалентни конструкции в обща форма, но тези способности не са нито добре документирани, нито (някъде близо) изчерпателни.
Със сигурност можем да увеличим максимално шансовете си да получим добър план за изпълнение, като пишем по-прости заявки, предоставяме полезни индекси, поддържаме добра статистика и се ограничаваме до повече релационни концепции (например като избягваме курсори, изрични цикли и не-вградени функции), но това е не е цялостно решение. Нито е възможно да се каже, че една T-SQL конструкция ще винаги създават по-добър план за изпълнение от семантично идентична алтернатива.
Обичайният ми съвет е да започнете с най-простата форма за релационна заявка, която отговаря на вашите нужди, като използвате какъвто и да е синтаксис на T-SQL, който смятате за предпочитан. Ако заявката не отговаря на изискванията след физическа оптимизация (например индексиране), може да си струва да опитате да изразите заявката по малко по-различен начин, като същевременно запазите оригиналната семантика. Това е трудната част. Коя част от заявката трябва да опитате да пренапишете? Кое пренаписване трябва да опитате? Няма прост универсален отговор на тези въпроси. Част от това се свежда до опит, макар че познаването на оптимизацията на заявките и вътрешните елементи на двигателя за изпълнение също може да бъде полезно ръководство.
Пример
Този пример използва таблицата AdventureWorks TransactionHistory. Скриптът по-долу прави копие на таблицата и създава клъстериран и неклъстериран индекс. Изобщо няма да променяме данните; тази стъпка е само да направи индексирането ясно (и да даде на таблицата по-кратко име):
SELECT * INTO dbo.TH FROM Production.TransactionHistory; CREATE UNIQUE CLUSTERED INDEX CUQ_TransactionID ON dbo.TH (TransactionID); CREATE NONCLUSTERED INDEX IX_ProductID ON dbo.TH (ProductID);
Задачата е да се създаде списък с идентификатори на продукти и история за шест конкретни продукта. Един от начините за изразяване на заявката е:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360);
Тази заявка връща 764 реда, използвайки следния план за изпълнение (показан в SentryOne Plan Explorer):

Тази проста заявка отговаря на изискванията за TRIVIAL компилация на план. Планът за изпълнение включва шест отделни операции за търсене на индекс в една:
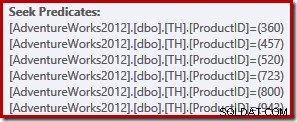
Читателите с орлови очи ще забележат, че шестте търсения са изброени във възходящ ред на идентификатора на продукта, а не в (произволния) ред, посочен в списъка IN на оригиналната заявка. Всъщност, ако изпълните заявката сами, има голяма вероятност да видите резултатите, които се връщат във възходящ ред на идентификатора на продукта. Заявката не е гарантирана да върне резултатите в този ред, разбира се, защото не сме посочили клауза ORDER BY от най-високо ниво. Можем обаче да добавим такава клауза ORDER BY, без да променяме плана за изпълнение, произведен в този случай:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360) ORDER BY ProductID;
Няма да повтарям графиката на плана за изпълнение, защото е абсолютно същата:заявката все още отговаря на изискванията за тривиален план, операциите по търсене са абсолютно еднакви и двата плана имат абсолютно еднакви прогнозни разходи. Добавянето на клаузата ORDER BY не ни струва абсолютно нищо, но ни спечели гаранция за подреждане на набора от резултати.
Вече имаме гаранция, че резултатите ще бъдат върнати в поръчката с идентификатор на продукта, но нашата заявка понастоящем не уточнява как редовете с същите ще бъде поръчан идентификатор на продукта. Разглеждайки резултатите, може да забележите, че редовете за един и същ идентификационен номер на продукт изглежда са подредени по идентификатор на транзакцията, нарастващ.
Без изрично ORDER BY, това е просто още едно наблюдение (т.е. не можем да разчитаме на това подреждане), но можем да променим заявката, за да гарантираме, че редовете са подредени по идентификатор на транзакция във всеки идентификационен номер на продукт:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360) ORDER BY ProductID, TransactionID;
Отново планът за изпълнение на тази заявка е точно същият като преди; се произвежда същият тривиален план със същата прогнозна цена. Разликата е, че резултатите вече са гарантирани да се поръча първо по идентификатор на продукта и след това по идентификатор на транзакция.
Някои хора може да се изкушат да заключат, че двете предишни заявки също винаги ще връщат редове в този ред, тъй като плановете за изпълнение са едни и същи. Това не е безопасно внушение, тъй като не всички детайли на двигателя за изпълнение са изложени в плановете за изпълнение (дори в XML формата). Без изрична клауза за подреждане по ред, SQL Server е свободен да връща редовете в произволен ред, дори ако планът изглежда един и същ за нас (той може например да извърши търсенето в реда, посочен в текста на заявката). Въпросът е, че оптимизаторът на заявки знае и може да наложи определени поведения в двигателя, които не са видими за потребителите.
В случай, че се чудите как нашият неуникален неклъстериран индекс на Product ID може да върне редове в Product и Идентификатор на транзакция, отговорът е, че неклъстерираният индексен ключ включва Transaction ID (уникалният клъстериран индексен ключ). Всъщност, физическата структурата на нашия неклъстериран индекс е точно същото, на всички нива, сякаш сме създали индекса със следната дефиниция:
CREATE UNIQUE NONCLUSTERED INDEX IX_ProductID ON dbo.TH (ProductID, TransactionID);
Можем дори да напишем заявката с изрично DISTINCT или GROUP BY и пак да получим точно същия план за изпълнение:
SELECT DISTINCT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360) ORDER BY ProductID, TransactionID;
За да бъде ясно, това не изисква промяна на оригиналния неклъстериран индекс по никакъв начин. Като последен пример, имайте предвид, че можем също да изискваме резултати в низходящ ред:
SELECT DISTINCT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360) ORDER BY ProductID DESC, TransactionID DESC;
Свойствата на плана за изпълнение сега показват, че индексът се сканира назад:

Освен това планът е същият – създаден е на етапа на тривиална оптимизация на плана и все още има същата прогнозна цена.
Пренаписване на заявката
Няма нищо лошо в предишната заявка или план за изпълнение, но може да сме избрали да изразим заявката по различен начин:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 520 OR ProductID = 723 OR ProductID = 457 OR ProductID = 800 OR ProductID = 943 OR ProductID = 360;
Ясно е, че този формуляр посочва точно същите резултати като оригинала и наистина новата заявка произвежда същия план за изпълнение (тривиален план, многократно търсене в едно, една и съща прогнозна цена). Формулярът OR може би прави малко по-ясно, че резултатът е комбинация от резултатите за шестте отделни идентификатора на продукта, което може да ни накара да опитаме друг вариант, който прави тази идея още по-ясна:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 520 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 723 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 457 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 800 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 943 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 360;
Планът за изпълнение на заявката UNION ALL е доста различен:
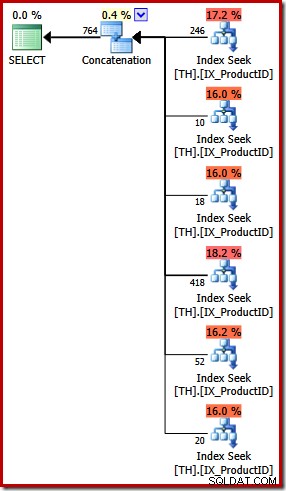
Освен очевидните визуални разлики, този план изискваше оптимизация на базата на разходите (ПЪЛНА) (не отговаряше на изискванията за тривиален план), а прогнозната цена е (относително казано) доста по-висока, около 0,02 единици спрямо около 0,005 единици преди.
Това се връща към началните ми бележки:оптимизаторът на заявки не знае за всяка логическа еквивалентност и не винаги може да разпознае алтернативните заявки като посочващи едни и същи резултати. Това, което искам да кажа на този етап, е, че изразяването на тази конкретна заявка с помощта на UNION ALL вместо IN доведе до по-малко оптимален план за изпълнение.
Втори пример
Този пример избира различен набор от шест идентификатора на продукти и иска да доведе до поръчка на идентификатор на транзакция:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (870, 873, 921, 712, 707, 711) ORDER BY TransactionID;
Нашият неклъстериран индекс не може да предостави редове в заявения ред, така че оптимизаторът на заявки има избор да направи между търсене на неклъстерирания индекс и сортиране или сканиране на клъстерирания индекс (който се насочва само към идентификатора на транзакцията) и прилагане на предикатите на идентификатора на продукта като остатък. Изброените идентификатори на продукти имат по-ниска селективност от предишния набор, така че в този случай оптимизаторът избира клъстерно сканиране на индекс:
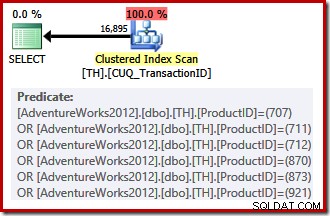
Тъй като има избор, основан на разходите, този план за изпълнение не отговаря на изискванията за тривиален план. Прогнозната цена на окончателния план е около 0,714 единици. Сканирането на клъстерирания индекс изисква 797 логически четения по време на изпълнение.
Може би, изненадани, че заявката не е използвала продуктовия индекс, може да опитаме да принудим търсене на неклъстерирания индекс, използвайки намек за индекс, или като посочим FORCESEEK:
SELECT ProductID, TransactionID FROM dbo.TH WITH (FORCESEEK) WHERE ProductID IN (870, 873, 921, 712, 707, 711) ORDER BY TransactionID;
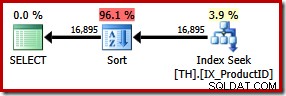
Това води до изрично сортиране по идентификатор на транзакция. Новият сорт се очаква да съставлява 96% от 1.15 на новия план единична цена. Тази по-висока прогнозна цена обяснява защо оптимизаторът е избрал очевидно по-евтиното сканиране на клъстерни индекси, когато е оставен на собствените си устройства. Цената на I/O на новата заявка обаче е по-ниска:когато се изпълни, търсенето на индекс консумира само 49 логически четения (надолу от 797).
Може също да сме избрали да изразим тази заявка с помощта на (по-рано неуспешната) идея UNION ALL:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 870 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 873 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 921 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 712 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 707 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 711 ORDER BY TransactionID;
Създава следния план за изпълнение (щракнете върху изображението, за да го увеличите в нов прозорец):

Този план може да изглежда по-сложен, но има приблизителна цена от само 0,099 единици, което е много по-ниско от сканирането на клъстерирания индекс (0,714 единици) или търсене плюс сортиране (1.15 единици). Освен това новият план консумира само 49 логически четения по време на изпълнение – същото като плана за търсене + сортиране и много по-ниско от 797, необходими за клъстерното сканиране на индекса.
Този път изразяването на заявката с помощта на UNION ALL създаде много по-добър план, както по отношение на приблизителните разходи, така и по отношение на логическите показания. Изходният набор от данни е твърде малък, за да се направи наистина смислено сравнение между продължителността на заявката или използването на процесора, но сканирането на клъстерирания индекс отнема два пъти по-дълго (26 мс) от другите две в моята система.
Допълнителното сортиране в загатнатия план вероятно е безобидно в този прост пример, защото е малко вероятно да се разлее на диск, но много хора така или иначе ще предпочетат плана UNION ALL, тъй като той не е блокиращ, избягва предоставяне на памет и не изисква намек за заявка.
Заключение
Видяхме, че синтаксисът на заявката може да повлияе на плана за изпълнение, избран от оптимизатора, въпреки че заявките логически определят точно същия набор от резултати. Едно и също пренаписване (напр. UNION ALL) понякога ще доведе до подобрение, а понякога ще доведе до избор на по-лош план.
Пренаписването на заявки и изпробването на алтернативен синтаксис е валидна техника за настройка, но е необходимо известно внимание. Един риск е, че бъдещите промени в продукта могат да накарат различната форма на заявка внезапно да спре да произвежда по-добрия план, но може да се твърди, че това винаги е риск и смекчен чрез тестване преди надграждане или използването на ръководства за планове.
Съществува и риск да се увлечете с тази техника: използването на „странни“ или „необичайни“ конструкции на заявка за получаване на план с по-добро представяне често е знак, че линията е била пресечена. Точно къде се крие разликата между валиден алтернативен синтаксис и „необичайно/странно“ вероятно е доста субективно; моето лично ръководство е да работя с еквивалентни форми на релационни заявки и да поддържам нещата възможно най-прости.



