Добавянето на филтриран индекс може да има изненадващи странични ефекти върху съществуващите заявки, дори когато изглежда, че новият филтриран индекс е напълно несвързан. Тази публикация разглежда пример, засягащ изрази DELETE, който води до лоша производителност и повишен риск от блокиране.
Тестова среда
Следната таблица ще се използва в цялата публикация:
CREATE TABLE dbo.Data
(
RowID integer IDENTITY NOT NULL,
SomeValue integer NOT NULL,
StartDate date NOT NULL,
CurrentFlag bit NOT NULL,
Padding char(50) NOT NULL DEFAULT REPLICATE('ABCDE', 10),
CONSTRAINT PK_Data_RowID
PRIMARY KEY CLUSTERED (RowID)
); Следващият израз създава 499 999 реда примерни данни:
INSERT dbo.Data WITH (TABLOCKX)
(SomeValue, StartDate, CurrentFlag)
SELECT
CONVERT(integer, RAND(n) * 1e6) % 1000,
DATEADD(DAY, (N.n - 1) % 31, '20140101'),
CONVERT(bit, 0)
FROM dbo.Numbers AS N
WHERE
N.n >= 1
AND N.n < 500000; Това използва таблица с числа като източник на последователни цели числа от 1 до 499 999. В случай, че нямате едно от тях във вашата тестова среда, следният код може да се използва за ефективно създаване на такъв, съдържащ цели числа от 1 до 1 000 000:
WITH
N1 AS (SELECT N1.n FROM (VALUES (1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) AS N1 (n)),
N2 AS (SELECT L.n FROM N1 AS L CROSS JOIN N1 AS R),
N3 AS (SELECT L.n FROM N2 AS L CROSS JOIN N2 AS R),
N4 AS (SELECT L.n FROM N3 AS L CROSS JOIN N2 AS R),
N AS (SELECT ROW_NUMBER() OVER (ORDER BY n) AS n FROM N4)
SELECT
-- Destination column type integer NOT NULL
ISNULL(CONVERT(integer, N.n), 0) AS n
INTO dbo.Numbers
FROM N
OPTION (MAXDOP 1);
ALTER TABLE dbo.Numbers
ADD CONSTRAINT PK_Numbers_n
PRIMARY KEY (n)
WITH (SORT_IN_TEMPDB = ON, MAXDOP = 1); Основата на по-късните тестове ще бъде изтриването на редове от тестовата таблица за определена начална дата. За да направите процеса на идентифициране на редове за изтриване по-ефективен, добавете този неклъстериран индекс:
CREATE NONCLUSTERED INDEX
IX_Data_StartDate
ON dbo.Data
(StartDate); Примерните данни
След като тези стъпки бъдат завършени, извадката ще изглежда така:
SELECT TOP (100)
D.RowID,
D.SomeValue,
D.StartDate,
D.CurrentFlag,
D.Padding
FROM dbo.Data AS D
ORDER BY
D.RowID;
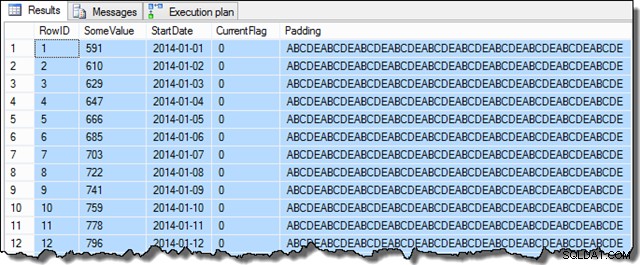
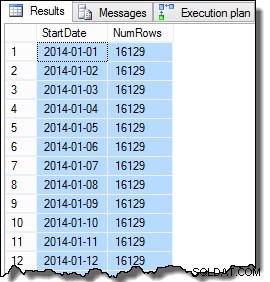
Данните в колоната SomeValue може да са малко по-различни поради псевдослучайното генериране, но тази разлика не е важна. Като цяло примерните данни съдържат 16 129 реда за всяка от 31-те начални дати през януари 2014 г.:
SELECT
D.StartDate,
NumRows = COUNT_BIG(*)
FROM dbo.Data AS D
GROUP BY
D.StartDate
ORDER BY
D.StartDate;
Последната стъпка, която трябва да извършим, за да направим данните донякъде реалистични, е да настроим колоната CurrentFlag на true за най-високия RowID за всяка начална дата. Следният скрипт изпълнява тази задача:
WITH LastRowPerDay AS
(
SELECT D.CurrentFlag
FROM dbo.Data AS D
WHERE D.RowID =
(
SELECT MAX(D2.RowID)
FROM dbo.Data AS D2
WHERE D2.StartDate = D.StartDate
)
)
UPDATE LastRowPerDay
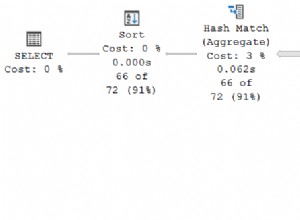
SET CurrentFlag = 1; Планът за изпълнение на тази актуализация включва комбинация от сегмент отгоре за ефективно намиране на най-високия RowID на ден:

Забележете как планът за изпълнение има малка прилика с писмената форма на заявката. Това е чудесен пример за това как оптимизаторът работи от логическата SQL спецификация, вместо да внедрява SQL директно. В случай, че се чудите, Eager Table Spool в този план се изисква за защита на Хелоуин.
Изтриване на ден данни
Добре, така че след приключване на предварителните въпроси, задачата е да изтриете редове за определена начална дата. Това е видът заявка, която можете да изпълнявате рутинно на най-ранната дата в таблица, когато данните са достигнали края на полезния си живот.
Вземайки 1 януари 2014 г. като наш пример, тестовата заявка за изтриване е проста:
DELETE dbo.Data WHERE StartDate = '20140101';
Планът за изпълнение също е доста прост, но си струва да се разгледа малко подробно:

Анализ на плана
Търсенето на индекс в най-дясната част използва неклъстерирания индекс, за да намери редове за посочената стойност на StartDate. Той връща само стойностите на RowID, които намира, както подсказката на оператора потвърждава:
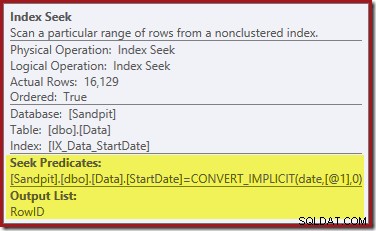
Ако се чудите как индексът StartDate успява да върне RowID, не забравяйте, че RowID е уникалният клъстериран индекс за таблицата, така че автоматично се включва в неклъстерния индекс на StartDate.
Следващият оператор в плана е Clustered Index Delete. Това използва стойността на RowID, намерена от Index Seek, за да намери редове за премахване.
Последният оператор в плана е Изтриване на индекс. Това премахва редове от неклъстерирания индекс IX_Data_StartDate които са свързани с RowID, премахнат от изтриването на клъстериран индекс. За да намери тези редове в неклъстерирания индекс, процесорът на заявки се нуждае от StartDate (ключът за неклъстерирания индекс).
Не забравяйте, че оригиналното търсене на индекс не върна началната дата, а само идентификатора на ред. И така, как процесорът на заявки получава началната дата за изтриването на индекса? В този конкретен случай оптимизаторът може да е забелязал, че стойността на StartDate е константа и да я оптимизира, но това не се е случило. Отговорът е, че операторът Clustered Index Delete чете стойността StartDate за текущия ред и я добавя към потока. Сравнете изходния списък на изтриването на клъстериран индекс, показан по-долу, с този на търсенето на индекс точно по-горе:
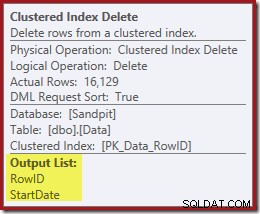
Може да изглежда изненадващо да видите оператор Delete да чете данни, но това е начинът, по който работи. Процесорът на заявки знае, че ще трябва да намери реда в клъстерирания индекс, за да го изтрие, така че може да отложи четенето на колони, необходими за поддържане на неклъстерирани индекси, до този момент, ако може.
Добавяне на филтриран индекс
Сега си представете, че някой има важна заявка към тази таблица, която се представя лошо. Полезният DBA извършва анализ и добавя следния филтриран индекс:
CREATE NONCLUSTERED INDEX
FIX_Data_SomeValue_CurrentFlag
ON dbo.Data (SomeValue)
INCLUDE (CurrentFlag)
WHERE CurrentFlag = 1; Новият филтриран индекс има желания ефект върху проблемната заявка и всички са доволни. Забележете, че новият индекс изобщо не препраща към колоната StartDate, така че не очакваме изобщо да засегне нашата заявка за изтриване на деня.
Изтриване на ден с филтрирания индекс на място
Можем да тестваме това очакване, като изтрием данните за втори път:
DELETE dbo.Data WHERE StartDate = '20140102';
Изведнъж планът за изпълнение се промени на паралелно сканиране на клъстериран индекс:

Забележете, че няма отделен оператор Index Delete за новия филтриран индекс. Оптимизаторът е избрал да поддържа този индекс в оператора Clustered Index Delete. Това е подчертано в SQL Sentry Plan Explorer, както е показано по-горе („+1 неклъстерирани индекси“) с пълни подробности в подсказката:
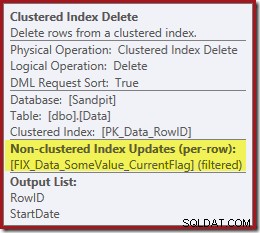
Ако таблицата е голяма (помислете за склад за данни), тази промяна към паралелно сканиране може да е много значителна. Какво се случи с хубавото търсене на индекс на StartDate и защо напълно несвързан филтриран индекс промени нещата толкова драматично?
Откриване на проблема
Първата улика идва от разглеждането на свойствата на Clustered Index Scan:
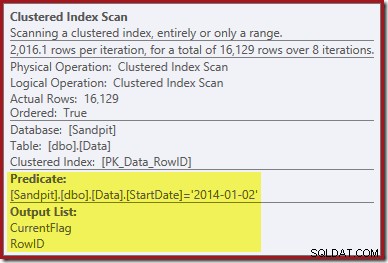
Освен че намира стойности на RowID за оператора Clustered Index Delete за изтриване, този оператор вече чете стойностите на CurrentFlag. Необходимостта от тази колона е неясна, но тя поне започва да обяснява решението за сканиране:колоната CurrentFlag не е част от нашия неклъстериран индекс на StartDate.
Можем да потвърдим това, като пренапишем заявката за изтриване, за да принудим използването на неклъстерирания индекс на StartDate:
DELETE D
FROM dbo.Data AS D
WITH (INDEX(IX_Data_StartDate))
WHERE StartDate = '20140103'; Планът за изпълнение е по-близо до първоначалната си форма, но вече включва Key Lookup:
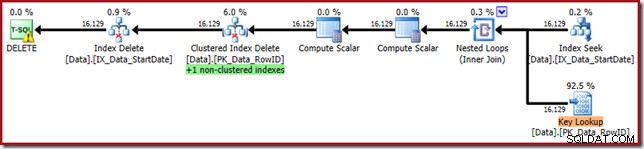
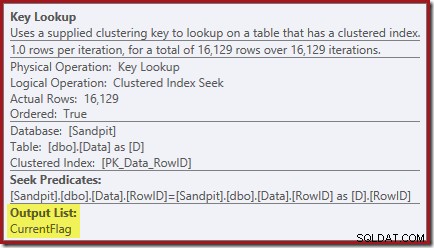
Свойствата на Key Lookup потвърждават, че този оператор извлича стойности на CurrentFlag:
Може също да сте забелязали предупредителните триъгълници в последните два плана. Това са липсващи предупреждения за индекси:
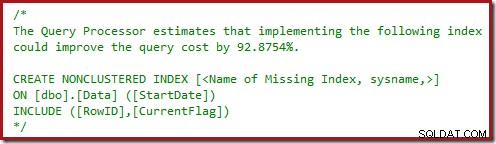
Това е допълнително потвърждение, че SQL Server би искал да види колоната CurrentFlag включена в неклъстерирания индекс. Причината за промяната към паралелно сканиране на клъстериран индекс вече е ясна:процесорът на заявки решава, че сканирането на таблицата ще бъде по-евтино от извършването на ключови търсения.
Да, но защо?
Всичко това е много странно. В първоначалния план за изпълнение SQL Server можеше да чете допълнителни данни в колоните, необходими за поддържане на неклъстерирани индекси при оператора Clustered Index Delete. Стойността на колоната CurrentFlag е необходима за поддържане на филтрирания индекс, така че защо SQL Server просто не го обработва по същия начин?
Краткият отговор е, че може, но само ако филтрираният индекс се поддържа в отделен оператор Index Delete. Можем да принудим това за текущата заявка, използвайки недокументиран флаг за проследяване 8790. Без този флаг оптимизаторът избира дали да поддържа всеки индекс в отделен оператор или като част от операцията на основната таблица.
-- Forced wide update plan DELETE dbo.Data WHERE StartDate = '20140105' OPTION (QUERYTRACEON 8790);
Планът за изпълнение се връща към търсене на неклъстерирания индекс на StartDate:
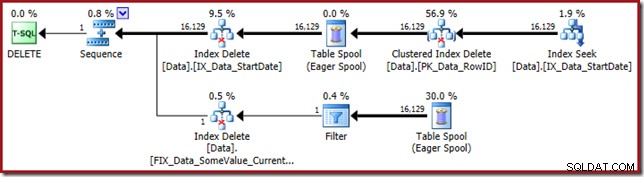
Търсенето на индекс връща само стойности на RowID (без CurrentFlag):
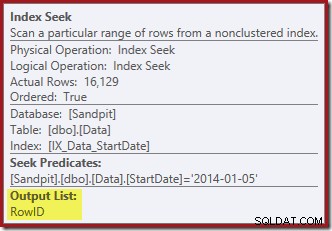
И Clustered Index Delete чете колоните, необходими за поддържане на неклъстерираните индекси, включително CurrentFlag:
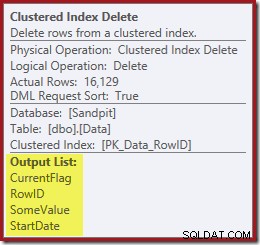
Тези данни се записват с нетърпение в таблица за пул, която се възпроизвежда за всеки индекс, който се нуждае от поддръжка. Обърнете внимание и на изричния оператор Filter преди оператора Index Delete за филтрирания индекс.
Друг модел, за който трябва да внимавате
Този проблем не винаги води до сканиране на таблица вместо търсене на индекс. За да видите пример за това, добавете друг индекс към тестовата таблица:
CREATE NONCLUSTERED INDEX
IX_Data_SomeValue_CurrentFlag
ON dbo.Data (SomeValue, CurrentFlag); Обърнете внимание, че този индекс е не филтриран и не включва колоната StartDate. Сега опитайте отново заявка за изтриване на ден:
DELETE dbo.Data WHERE StartDate = '20140104';
Оптимизаторът сега излиза с това чудовище:
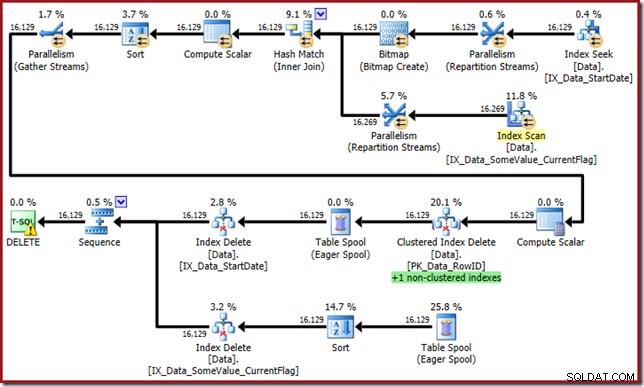
Този план за заявка има висок фактор на изненада, но основната причина е същата. Колоната CurrentFlag все още е необходима, но сега оптимизаторът избира стратегия за пресичане на индекси, за да я получи вместо сканиране на таблица. Използването на флага за проследяване налага план за поддръжка за всеки индекс и здравият разум отново се възстановява (единствената разлика е допълнително повторно възпроизвеждане на макара за поддържане на новия индекс):
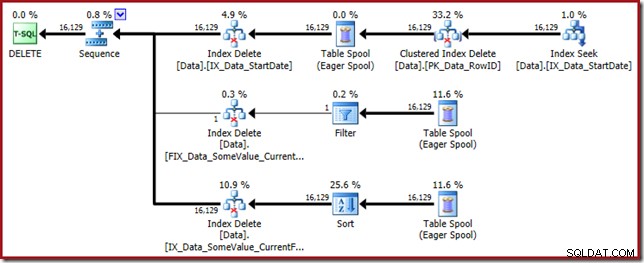
Само филтрираните индекси причиняват това
Този проблем възниква само ако оптимизаторът избере да поддържа филтриран индекс в оператор за изтриване на клъстериран индекс. Нефилтрираните индекси не са засегнати, както показва следващият пример. Първата стъпка е да премахнете филтрирания индекс:
DROP INDEX FIX_Data_SomeValue_CurrentFlag ON dbo.Data;
Сега трябва да напишем заявката по начин, който да убеди оптимизатора да поддържа всички индекси в Clustered Index Delete. Моят избор за това е да използвам променлива и намек за намаляване на очакванията за броя на редовете на оптимизатора:
-- All qualifying rows will be deleted
DECLARE @Rows bigint = 9223372036854775807;
-- Optimize the plan for deleting 100 rows
DELETE TOP (@Rows)
FROM dbo.Data
OUTPUT
Deleted.RowID,
Deleted.SomeValue,
Deleted.StartDate,
Deleted.CurrentFlag
WHERE StartDate = '20140106'
OPTION (OPTIMIZE FOR (@Rows = 100)); Планът за изпълнение е:
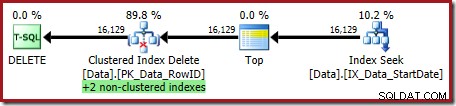
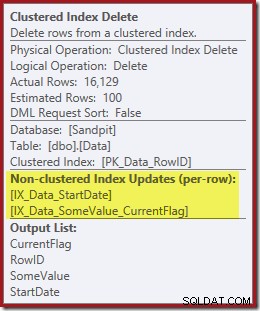
И двата неклъстерирани индекса се поддържат от Clustered Index Delete:
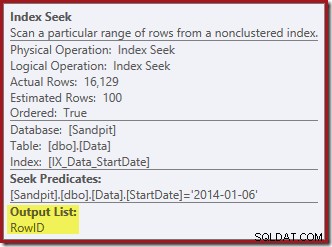
Търсенето на индекс връща само RowID:
Колоните, необходими за поддръжката на индекса, се извличат вътрешно от оператора delete; тези подробности не са изложени в изхода на плана за показване (така че списъкът с изходите на оператора за изтриване ще бъде празен). Добавих OUTPUT клауза към заявката, за да покаже Clustered Index Delete отново, връщайки данни, които не е получил при входа си:
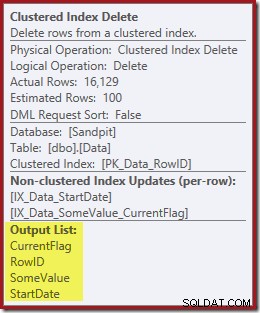
Последни мисли
Това е трудно ограничение за заобикаляне. От една страна, обикновено не искаме да използваме недокументирани флагове за проследяване в производствените системи.
Естествената „поправка“ е да добавите колоните, необходими за поддръжка на филтриран индекс към всички неклъстерирани индекси, които могат да се използват за намиране на редове за изтриване. Това не е много привлекателно предложение от редица гледни точки. Друга алтернатива е просто да не се използват филтрирани индекси изобщо, но и това едва ли е идеално.
Чувството ми е, че оптимизаторът на заявки трябва автоматично да обмисли алтернатива за поддръжка на индекси за филтрирани индекси, но разсъжденията му изглеждат непълни в тази област в момента (и се основават на прости евристики, а не на правилно изчисляване на разходите за индекс/на ред алтернативи).
За да поставим някои числа около това изявление, избраният от оптимизатора план за сканиране на паралелни клъстери дойде на 5.5 единици в моите тестове. Същата заявка с флага за проследяване изчислява цена от 1,4 единици. С третия индекс на място, планът за паралелен индекс-пресичане, избран от оптимизатора, имаше прогнозна цена от 4,9 , докато планът на флага за проследяване беше на 2.7 единици (всички тестове на SQL Server 2014 RTM CU1 build 12.0.2342 по модела за оценка на кардиналността 120 и с активиран флаг за проследяване 4199).
Считам това като поведение, което трябва да се подобри. Можете да гласувате за съгласие или несъгласие с мен за този елемент на Connect.