Като цяло хората не обичат да получават непоискани имейли. Въпреки това те понякога се абонират за бюлетини, за да получат отстъпка или да бъдат в крак с новите продукти. Тази статия ще представи един подход за проектиране на база данни за бюлетин.
Защо да се притеснявате за имейлите с бюлетини?
Абонатите на бюлетин представляват изключително ценна група клиенти – интересуват се от нашите продукти, доверяват ни се и прекарват време в преглед на нашите оферти и промоции. Нещо повече, изпращането на имейли до клиенти е един от най-евтините инструменти в онлайн маркетинга. Това обаче трябва да се прави внимателно – данните трябва да се актуализират ежедневно (защото хората се абонират и отписват) и да бъдат с високо качество (не искаме да изпращаме нежелани имейли, тъй като това се отразява негативно на имиджа на марката).
Така възниква въпросът как да управляваме този процес на получаване на качествени данни и ежедневното им актуализиране. Има много опции ...
И победителят е...
Анализ на клиентите! В днешно време най-важният фактор за изпреварване на конкуренцията е намирането на прозрения от данните и вземането на бизнес решения на тази основа. Не би ли било чудесно да разгледате историята на изпращането на бюлетини и да анализирате тяхната интензивност и ефективност? За всеки клиент? И след това да се присъедините към него с данни за закупуване, да разкриете интересите на клиента, да подготвите индивидуални препоръки и да ги изпратите чрез персонализирани имейли?
Такъв подход със сигурност би увеличил нашия процент на конверсия (CR). Коефициентът на конверсия е един от най-важните ключови показатели за ефективността на онлайн маркетинга; показва колко хора правят покупка, след като са видели някои от нашите промоционални материали (реклами, бюлетини и т.н.). Високият CR означава повишена бизнес ефективност.
Сега, когато разбрахме част от маркетинга, нека влезем в модела на данните!
Нека започнем да моделираме база данни с бюлетин!
Ако се задълбочим, виждаме, че двете основни таблици в модела са client и newsletter таблици.
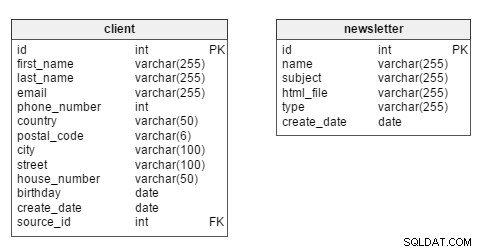
Тъй като най-вече ще се интересуваме от клиентски анализ, client масата трябва да остане в центъра на модела. В тази таблица всеки клиент има свой собствен уникален id . Ние също така ще съхраняваме такава информация като first_name на клиента и last_name , информация за връзка (email , phone_number , адрес), birthday , create_date (когато записът на клиента е въведен в базата данни) и техния source_id – т.е. дали са се регистрирали на нашия сайт или някой бизнес партньор ни е предоставил своите данни.
newsletter таблицата съхранява данни за всяко създаване на бюлетин. Бюлетините могат да бъдат идентифицирани въз основа на техния уникален id . Всеки е описан с name (напр. „Нова колекция дамски дрехи – есен 2016“), имейл subject („Най-модерните дрехи за нея – купете сега!”), html_file (файлът, съдържащ HTML кода за този конкретен бюлетин), бюлетин type (напр. „нова колекция“, „бюлетин за рожден ден“) и create_date .
Съгласия за маркетинг
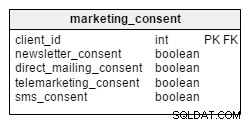
За да изпрати маркетингова информация (по поща, телефон, имейл или SMS), една компания трябва да получи съгласие от своите клиенти. В нашия модел съгласията се съхраняват в отделна таблица с име marketing_consent . Той съхранява информация за текущия набор от маркетингови съгласия за всички наши клиенти. Съгласията се кодират като булеви променливи – TRUE (съгласява се с маркетинговата комуникация) или FALSE (не е съгласен).
Много е важно да се съхранява информация за това кога клиентът се е съгласил да получава реклами по всеки комуникационен канал. Също така е полезно да записвате кога са оттеглили съгласието си за всеки канал. За такива цели consent_change таблицата е проектирана.
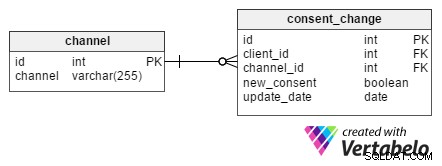
Всяка промяна има уникален id и се присвоява на конкретен клиент от техния client_id . Когато клиент поиска да бъде премахнат от имейлите на бюлетина, бюлетинът id от channel таблицата също ще се съхранява в consent_change channel_id на таблицата атрибут. new_consent атрибутът е булева стойност (TRUE или FALSE) и представлява нови маркетингови съгласия.
update_date колоната съдържа датата, на която клиент е поискал промяна. Тази структура ни позволява да извлечем набор от съгласия за всички клиенти в даден ден. Изключително полезно е, ако клиент се оплаква от получаване на имейл, след като вече се е отписал от нашия бюлетин. С тази информация можем да проверим кога е извършено отписването и да се надяваме, че това е направено след изпращането на имейл бюлетина.
Поддържане на изпращанията в ред
Проектирането на перфектен модел на база данни за изпращане на бюлетини не е просто парче. Защо? Е, очевидно трябва да можем да идентифицираме всяко едно създаване на бюлетин (което означава оформление, графики, продукти, връзки и т.н.). Знаем също, че едно творение може да бъде изпратено няколко пъти:мениджърите могат да решат, че една кофа с имейли ще бъде изпратена сутрин на половината клиенти и вечер на другата половина. Затова е от решаващо значение да запишете кои клиенти кой бюлетин са получили и кога. Ето защо тази част от модела се състои от три таблици:
newsletterтаблица – която описахме по-рано.newsletter_sendoutтаблица – която идентифицира едно изпращане. Например коледният бюлетин (id =“2512”) беше изпратено по имейл на 10 декември в 18:00 часа. Това водене на записи позволява на търговците да изпращат един и същ бюлетин до отделни групи клиенти по различно време.sendout_receiversтаблица – която събира данни за получателите на всяко изпращане. Ще има един запис за всеки имейл от всяко изпращане. Всеки ред има три колони:id(идентифициране на събитието за изпращане на имейл до клиент),client_id(идентифициране на клиенти от нашата база данни) иnl_sendout_id(идентифициране на изпращане на бюлетин).
Ето пълния модел на бюлетина:
Имате ли идеи как да подобрите този модел?
Един възможен начин е да добавите response маса. Това ще запази реакциите на клиентите – независимо дали са отворили имейла, щракнали върху рекламата или никога не са видели съобщението, защото е маркирано като спам. Къде да добавим response таблица към нашия модел и кое отношение трябва да се приложи? Споделете вашите мисли в секцията за коментари по-долу.