FILESTREAM е въведен от Microsoft през 2008 г. Целта е да се съхраняват и управляват по-ефективно неструктурирани файлове. Преди въвеждането на FILESTREAM бяха използвани следните подходи за съхраняване на данните в SQL сървър:
- Неструктурираните файлове могат да се съхраняват в колоната VARBINARY или IMAGE на таблица на SQL Server. Този подход е ефективен за поддържане на последователност на транзакциите и намалява сложността на управлението на файлове, но когато клиентското приложение чете данни от SQL таблицата, то използва SQL памет, което води до ниска производителност.
- Вместо да съхранявате целия файл в SQL таблицата, запазете физическото местоположение на неструктурирания файл в SQL таблица. Този подход осигурява значително подобрение на производителността, но не гарантира последователността на транзакциите, освен това управлението на файловете също беше трудно.
Функцията FILESTREAM е много ефективна, защото позволява съхраняване на BLOB файлове във файловата система NT и поддържа транзакционната последователност. Когато клиентско приложение чете данни от контейнера FILESTREAM, вместо да използва паметта на буфера на SQL Server, то използва системния кеш Nthe T, което подобрява производителността.
FILESTREAM не е тип данни. Това е атрибут, който може да бъде присвоен на колоната VARBINARY(MAX). Когато колоната VARBINARY(MAX) е присвоена на атрибута FILESTREAM, тя се нарича колона FILESTREAM. Данните, съхранени в колоната FILESTREAM, ще се съхраняват в NT системата като дисков файл, а указателят на файла се съхранява в таблицата. Колоната VARBINARY(max) с присвоен атрибут FILESTREAM няма ограничение за съхранение на 2 GB в таблицата. Следователно можем да съхраняваме и огромни файлове.
В тази статия ще демонстрирам следното:
- Как да активирам функцията FILESTREAM.
- Как да създадете и конфигурирате FILESTREAM файлови групи и контейнер за данни FILESTREAM.
- Как да съхранявате и осъществявате достъп до данни от таблиците с активиран FILESTREAM.
Демо:
В тази демонстрация ще използвам:
- Сървър за база данни :SQL Server 2017
- Софтуер :SQL Server Management Studio
- База данни :FileStream_Demo
Конфигуриране на достъп до FILESTREAM в база данни на SQL Server
За да конфигурирате FileStream в SQL Server, направете следните промени в SQL Server.
- Активирайте функцията FILESTREAM от SQL Server Configuration Manager.
- Активирайте нивото на достъп FILESTREAM на екземпляр на SQL Server.
- Създайте файлова група FILESTREAM и контейнер FileStream за съхраняване на BLOB данни.
Активиране на функцията FILESTREAM
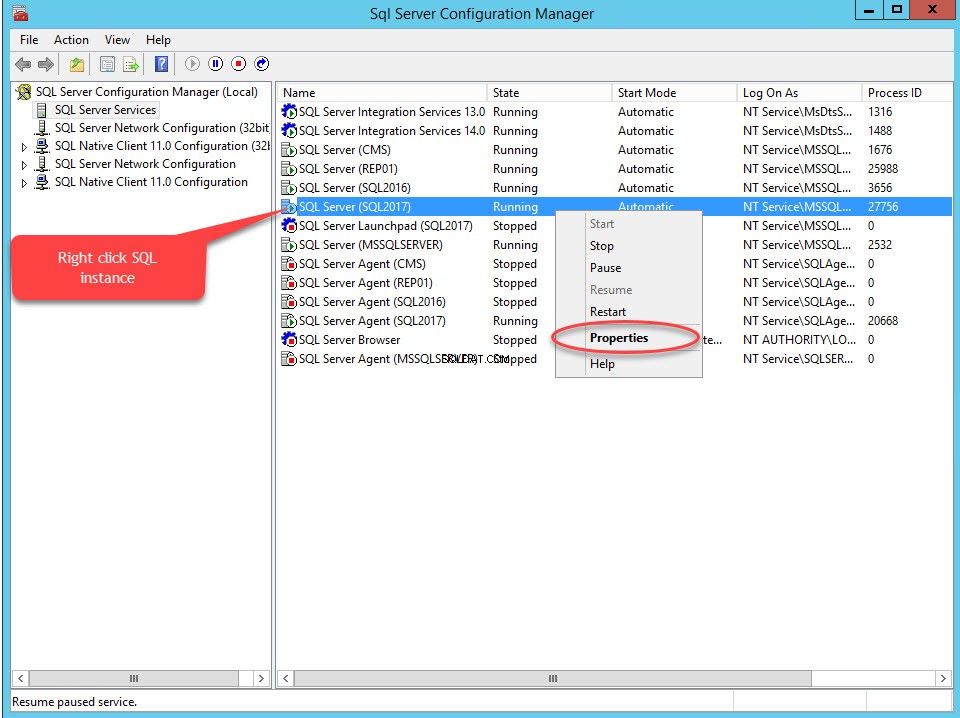
За да активирате FileStream във всяка база данни, първо активирайте функцията FileStream на екземпляра на SQL Server. За да направите това, отворете мениджъра на конфигурацията на SQL Server, щракнете с десния бутон върху SQL Instance, изберете Properties , както е показано на следното изображение:
Отваря се диалогов прозорец за конфигуриране на свойствата на сървъра. Превключете към FILESTREAM раздел. Изберете Активиране на FILESTREAM за T-SQL достъп . Изберете Активиране на FILESTREAM за I/O достъп и след това изберете Разрешаване на отдалечен клиентски достъп до FILESTREAM данни . В Име за споделяне на Windows текстово поле, посочете име на директорията за съхраняване на файловете. Вижте следното изображение:
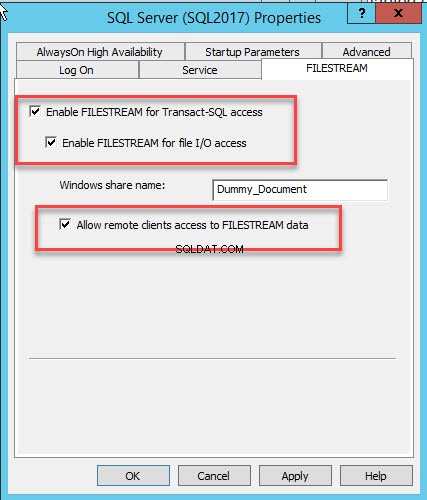
Щракнете върху OK и рестартирайте SQL услугата.
Активиране на ниво на достъп FILESTREAM на екземпляр на SQL Server
След като функцията FILESTREAM е активирана, променете нивото на достъп FILESTREAM. За да промените нивото на достъп FileStream, изпълнете следната заявка:
EXEC sp_configure filestream_access_level, 2 RECONFIGURE
В горната заявка параметрите по-долу са валидни стойности:
0 означава поддръжката на FILESTREAM за SQL екземпляр е деактивирана.
1 означава поддръжката на FILESTREAM за T-SQL е активирана.
2 означава поддръжката на FILESTREAM за T-SQL и Win32 стрийминг достъп е активирана.
Можете да промените нивото на достъп FILESTREAM с помощта на SQL Server Management Studio. За да направите това, щракнете с десния бутон върху връзка със SQL Server>> изберете Свойства>> В диалоговия прозорец със свойства на сървъра изберете Ниво на достъп на FileStream от падащото меню и изберете Разрешен пълен достъп , както е показано на следното изображение:
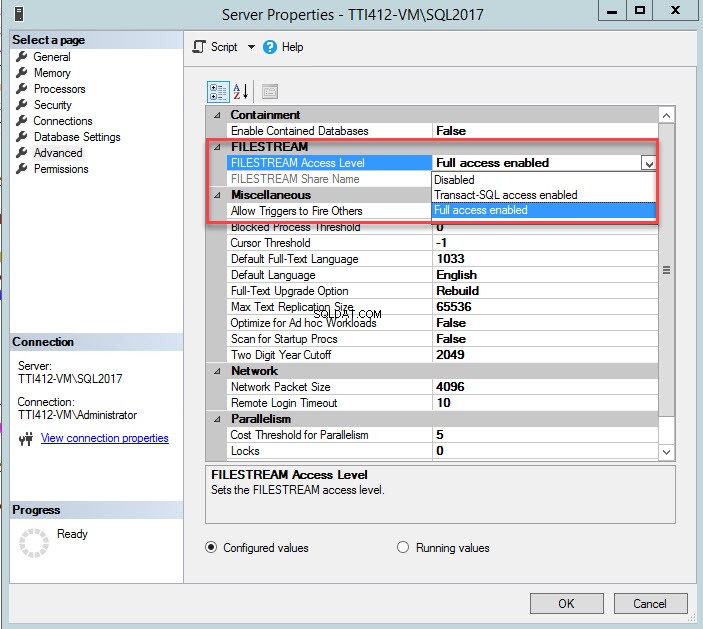
След като параметърът бъде променен, рестартирайте услугите на SQL Server.
Добавяне на файлова група FILESTREAM и файлове с данни
След като FILESTREAM е активиран, добавете файловата група FILESTREAM и контейнера FILESTREAM.
За да направите това, щракнете с десния бутон върху FileStream-Demo база данни>> изберете Свойства>> В левия панел на Свойства на базата данни диалогов прозорец, изберете Файлови групи>> В мрежата FILESTREAM щракнете върху Добавяне на файлова група бутон>> Име на файловата група като Фактичен документ . Вижте следното изображение:
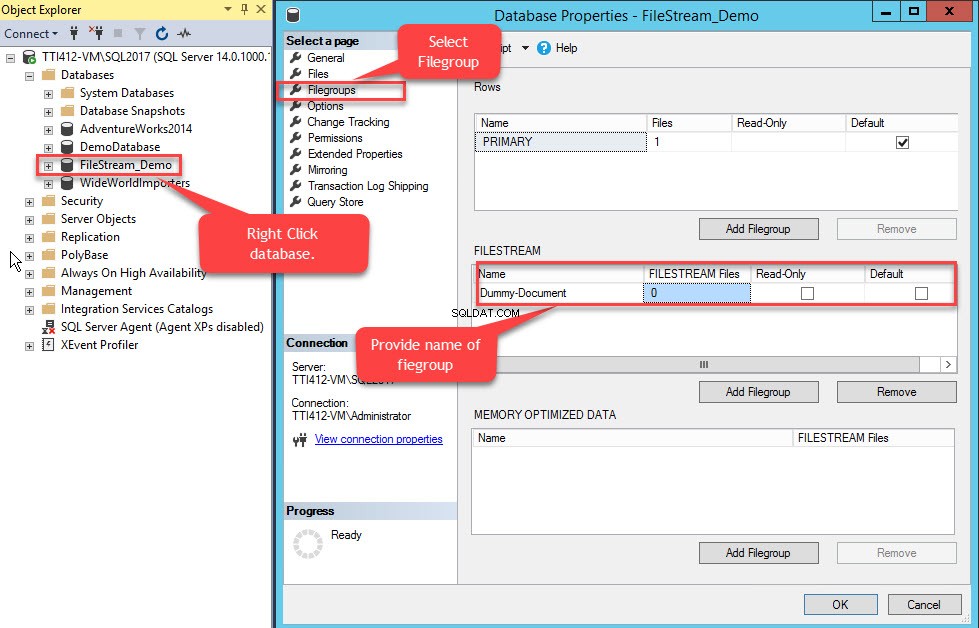
След като файловата група е създадена, в диалоговия прозорец Свойства на базата данни изберете файлове и щракнете върху бутона Добавяне. Решетката с файлове на базата данни активира. В колоната Логическо име посочете името – Фактичен документ . Изберете FILESTREAM Data в Тип на файл падащо меню. Изберете Фактичен документ вФайловата група колона. В Пътят колона, посочете местоположението на директорията, където ще се съхраняват файловете (E:\Dummy-Documents). Вижте следното изображение:
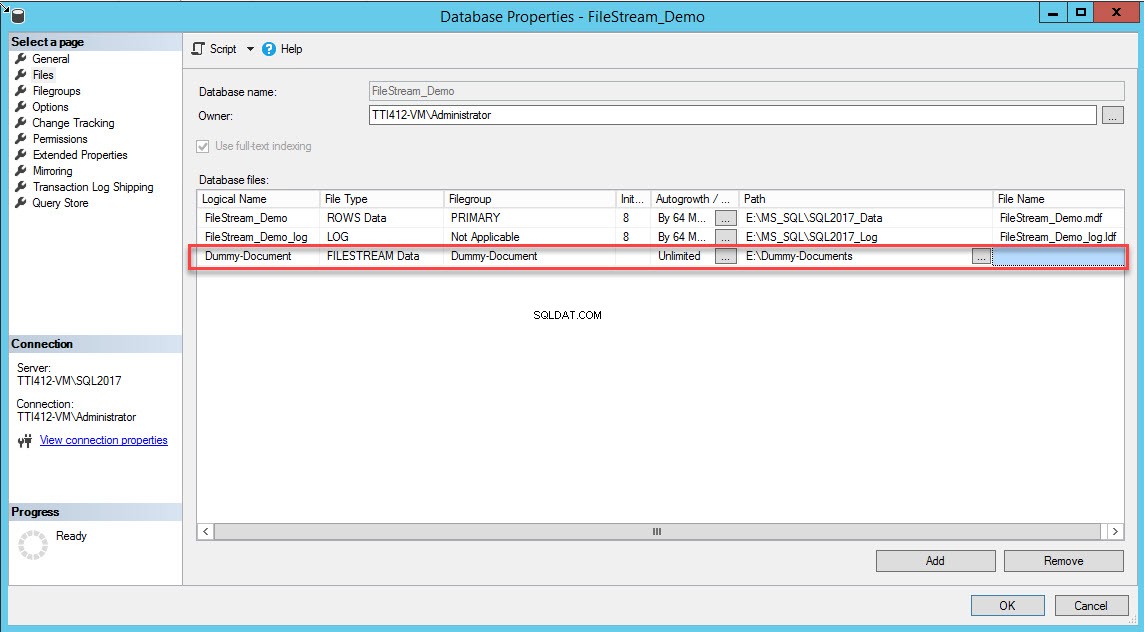
Като алтернатива можете да добавите файловата група и контейнери FILESTREAM, като изпълните следната T-SQL заявка:
USE [master] GO ALTER DATABASE [FileStream_Demo] ADD FILEGROUP [Dummy-Documents] CONTAINS FILESTREAM GO ALTER DATABASE [FileStream_Demo] ADD FILE ( NAME = N'Dummy-Documents', FILENAME = N'E:\Dummy-Documents' ) TO FILEGROUP [Dummy-Documents] GO
За да проверите дали контейнерът FileStream е създаден, отворете Windows Explorer и отидете до директорията „E:\Dummy-Document“.
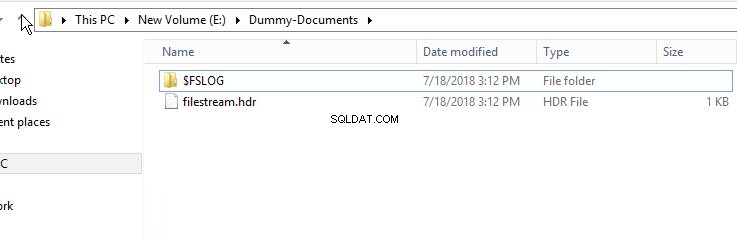
Както е показано на изображението по-горе, директорията $FSLOG и filestream.hdr файл са създадени. $FSLOG е като T-Log на SQL сървъра и filestream.hdr съдържа метаданни на FILESTREAM. Уверете се, че не променяте или редактирате тези файлове.
Съхраняване на файлове в SQL таблица
В тази демонстрация ще създадем таблица за съхраняване на различни файлове от компютъра. Таблицата има следните колони:
- „RootDirectory ” за съхраняване на местоположението на файла.
- „Име на файл ” за съхраняване на името на файла.
- Атрибутът „FileAttribute ” колона за съхраняване на атрибута на файла (Raw/Directory.
- „FileCreateDate ” за съхраняване на времето за създаване на файла.
- „Размер на файла ” за съхраняване на размера на файла.
- „FileStreamCol ” за съхраняване на съдържанието на файла в двоичен формат.
Създайте SQL таблица с колона FILESTREAM
След като FILESTREAM се конфигурира, създайте SQL таблица с колоните FILESTREAM, за да съхранявате различни файлове в таблицата на SQL сървъра. Както споменах по-горе, FILESTREAM не е тип данни. Това е атрибут, който добавяме към колоната varbinary(max) в таблицата с активиран FILESTREAM. Когато създавате таблица с активиран FILESTREAM, уверете се, че сте добавили UNIQUEIDENTIFIER колона, която съдържа ROWGUIDCOL и УНИКАЛНО атрибути.
Изпълнете следния скрипт, за да създадете таблица с активиран FILESTREAM:
Use [FileStream_Demo]
go
Create Table [DummyDocuments]
(
ID uniqueidentifier ROWGUIDCOL unique NOT NULL,
RootDirectory varchar(max),
FileName varchar(max),
FileAttribute varchar(150),
FileCreateDate datetime,
FileSize numeric(10,5),
FileStreamCol varbinary (max) FILESTREAM
) Вмъкване на данни в таблица
Имам WorldWide_Importors.xls документ, съхранен в компютъра в местоположението “E:\Documents”. Използвайте OPENROWSET(групово) за да заредите съдържанието му от диска в VARBINARY(max) променлива. След това запазете променливата в FileStreamCol (VARBINARY(max)) колона на DummyDocumen t таблица. За да направите това, изпълнете следния скрипт:
Use [FileStream-Demo]
Go
DECLARE @Document AS VARBINARY(MAX)
-- Load the image data
SELECT @Document = CAST(bulkcolumn AS VARBINARY(MAX))
FROM OPENROWSET(
BULK
'E:\Documents\WorldWide_Importors.xls',
SINGLE_BLOB ) AS Doc
-- Insert the data to the table
INSERT INTO [DummyDocuments] (ID, RootDirectory,FileName, FileAttribute, FileCreateDate,FileSize,FileStreamCol)
SELECT NEWID(), 'E:\Documents','WorldWide_Importors.xls','Raw',getdate(),10, @Document Достъп до данни на FILESTREAM
Данните на FILESTREAM могат да бъдат достъпни с помощта на T-SQL и управляван API. Когато колоната FILESTREAM е осъществена чрез T-SQL заявка, тя използва SQL памет, за да прочете съдържанието на файла с данни и да изпрати данните до клиентското приложение. Когато се осъществява достъп до колоната FILESTREAM чрез Win32 Managed API, тя не използва памет на SQL Server. Той използва възможностите за стрийминг на файловата система NT, което дава предимства на производителността.
Достъп до FILESTREAM данни с помощта на T-SQL
Както споменах в началото на статията, FILESTREAM е атрибут, присвоен на колона на таблица, която има тип данни varbinary(max), следователно може да бъде достъпна като всяка друга колона на таблицата. За да извлечете данни от FILESTREAM заедно с цялата информация на таблицата, изпълнете заявката по-долу
Use [FileStream-Demo] go select RootDirectory,FileName,FileAttribute,FileCreateDate,FileSize,FileStreamCol from DummyDocuments
По-долу е изходът от заявката:

Както е показано на изображението по-горе, документът „WorldWide_Importors.xls“ е преобразуван в BLOB, който се съхранява в колоната „FileStreamCol“.
Достъп до данни на FILESTREAM с помощта на управляван API
Въпреки че достъпът до FILESTREAM чрез Win32 API дава производителност и други предимства, той има различни и трудни синтаксиси от синтаксиса на T-SQL, което затруднява достъпа до данни. Първо, за да намерим файла в хранилището за данни на FILESTREAM, трябва да идентифицираме логическия път, за да идентифицираме файла в хранилището за данни на FILESTREAM. Можем да го направим с помощта на Pathname() метод на колона FILESTREAM. Регистърът на буквите е чувствителен.
След като извлечем пътя на файла, за достъп, трябва да получим контекста на транзакцията, като използваме Начало на транзакцията метод. След като контекстът на транзакцията бъде получен, можем да получим достъп до него чрез SQLFileStream клас.
Кодът по-долу получава локалния път към WorldWide_Importors.xls документ в хранилището за данни FILESTREAM.
SELECT
RootDirectory,
FileName,
FileAttribute,
FileCreateDate,
FileSize,
FileStreamCol.PathName() AS FilePath
FROM DummyDocuments Изход на заявка:

Изтриване на файлове от контейнера FILESTREAM
Изтриването на файлове е лесно. Трябва да изпълните заявката за изтриване, за да премахнете файла от SQL таблицата с активиран FILESTREAM. Въпреки че записът е изтрит от таблици, файлът ще бъде физически достъпен в хранилището за данни на FILSTREAM. Той ще бъде изтрит от Garbage Collector. Процесът Garbage Collector се изпълнява, когато настъпи събитието на контролната точка. Като дадете изрична контролна точка, можете да я изтриете веднага след изтриването от таблицата.
Запитване за изтриване на файлове от SQL таблица:
Use [FileStream_Demo] go delete from DummyDocuments where ID='0D640ABC-8CF1-41E0-9FA8-28171047129F'
Резюме
В тази статия разгледах:
- Въведение на FILESTREAM и какви са предимствата.
- Как да активирам функцията FILESTREAM на екземпляр на SQL сървър.
- Създайте и конфигурирайте хранилището за данни FILESTREAM и файловите групи.
- Извършване на вмъкване и изтриване на файлове от хранилището за данни на FILESTREAM.
В бъдещи статии ще обясня:
- Как да архивирам и възстановим база данни с активиран FILESTREAM.
- Настройване на репликация и разделяне на таблици в таблици FILESTREAM.
Останете на линия!