SQL Server 2014 донесе много нови функции, които администраторите на база данни и разработчиците с нетърпение очакваха да тестват и използват в своите среди, като обновяемия клъстерен индекс на Columnstore, отложена издръжливост и разширения на буферния пул. Функция, която не се обсъжда често, е постепенната статистика. Освен ако не използвате разделяне, това не е функция, която можете да внедрите. Но ако имате разделени таблици във вашата база данни, инкременталните статистически данни може да са били нещо, което сте очаквали с нетърпение.
Забележка:Бенджамин Неварез обхвана някои основи, свързани с инкременталните статистически данни в публикацията си от февруари 2014 г., SQL Server 2014 Incremental Statistics. И макар че не се е променило много в начина на работа на тази функция след публикацията му и пускането през април 2014 г., изглежда е подходящ момент да се разровим как активирането на постепенната статистика може да помогне за ефективността на поддръжката.
Инкременталните статистики понякога се наричат статистика на ниво дял и това е така, защото за първи път SQL Server може автоматично да създава статистически данни, които са специфични за даден дял. Едно от предишните предизвикателства с разделянето беше, че въпреки че можеше да имате 1 до n дялове за таблица, имаше само една (1) статистика, която представляваше разпределението на данните във всички тези дялове. Можете да създадете филтрирани статистически данни за разделената таблица – по една статистика за всеки дял – за да предоставите на оптимизатора на заявки по-добра информация за разпределението на данни. Но това беше ръчен процес и изискваше скрипт за автоматичното им създаване за всеки нов дял.
В SQL Server 2014 използвате STATISTICS_INCREMENTAL опция SQL Server да създава автоматично тези статистически данни на ниво дял. Тези статистически данни обаче не се използват, както може би си мислите.
По-рано споменах, че преди 2014 г. можете да създавате филтрирани статистически данни, за да дадете на оптимизатора по-добра информация за дяловете. Тези нарастващи статистики? В момента те не се използват от оптимизатора. Оптимизаторът на заявки все още просто използва основната хистограма, която представлява цялата таблица. (Публикуване предстои, което ще демонстрира това!)
И така, какъв е смисълът на постепенната статистика? Ако приемете, че само данните в най-новия дял се променят, тогава в идеалния случай актуализирате статистиката само за този дял. Можете да направите това сега с постепенна статистика – и това, което се случва, е, че след това информацията се слива обратно в основната хистограма. Хистограмата за цялата таблица ще се актуализира, без да се налага да четете цялата таблица, за да актуализирате статистическите данни и това може да помогне при изпълнението на задачите ви по поддръжката.
Настройка
Ще започнем със създаване на функция и схема за разделяне и след това нова таблица, която ще разделим. Имайте предвид, че създадох файлова група за всяка функция на дял, както бихте могли в производствена среда. Можете да създадете схемата на дялове в същата файлова група (напр. PRIMARY ), ако не можете лесно да изпуснете тестовата си база данни. Всяка файлова група също е с размер от няколко GB, тъй като ще добавим почти 400 милиона реда.
USE [AdventureWorks2014_Partition]; GO /* add filesgroups */ ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2011]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2012]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2013]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2014]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2015]; /* add files */ ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2011.ndf', NAME = N'2011', SIZE = 1024MB, MAXSIZE = 4096MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2011]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2012.ndf', NAME = N'2012', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2012]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2013.ndf', NAME = N'2013', SIZE = 2048MB, MAXSIZE = 4096MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2013]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2014.ndf', NAME = N'2014', SIZE = 2048MB, MAXSIZE = 4096MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2014]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2015.ndf', NAME = N'2015', SIZE = 2048MB, MAXSIZE = 4096MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2015]; /* create partition function */ CREATE PARTITION FUNCTION [OrderDateRangePFN] ([datetime]) AS RANGE RIGHT FOR VALUES ( '20110101', -- everything in 2011 '20120101', -- everything in 2012 '20130101', -- everything in 2013 '20140101', -- everything in 2014 '20150101' -- everything in 2015 ); GO /* create partition scheme */ CREATE PARTITION SCHEME [OrderDateRangePScheme] AS PARTITION [OrderDateRangePFN] TO ([PRIMARY], [FG2011], [FG2012], [FG2013], [FG2014], [FG2015]); GO /* create the table */ CREATE TABLE [dbo].[Orders] ( [PurchaseOrderID] [int] NOT NULL, [EmployeeID] [int] NULL, [VendorID] [int] NULL, [TaxAmt] [money] NULL, [Freight] [money] NULL, [SubTotal] [money] NULL, [Status] [tinyint] NOT NULL, [RevisionNumber] [tinyint] NULL, [ModifiedDate] [datetime] NULL, [ShipMethodID] [tinyint] NULL, [ShipDate] [datetime] NOT NULL, [OrderDate] [datetime] NOT NULL, [TotalDue] [money] NULL ) ON [OrderDateRangePScheme] (OrderDate);
Преди да добавим данните, ще създадем клъстерирания индекс и ще отбележим, че синтаксисът включва WITH (STATISTICS_INCREMENTAL = ON) опция:
/* add the clustered index and enable incremental stats */ ALTER TABLE [dbo].[Orders] ADD CONSTRAINT [OrdersPK] PRIMARY KEY CLUSTERED ( [OrderDate], [PurchaseOrderID] ) WITH (STATISTICS_INCREMENTAL = ON) ON [OrderDateRangePScheme] ([OrderDate]);
Това, което е интересно да се отбележи тук, е, че ако погледнете ALTER TABLE запис в MSDN, той не включва тази опция. Ще го намерите само в ALTER INDEX влизане... но това работи. Ако искате да следвате документацията до буква, трябва да изпълните:
/* add the clustered index and enable incremental stats */ ALTER TABLE [dbo].[Orders] ADD CONSTRAINT [OrdersPK] PRIMARY KEY CLUSTERED ( [OrderDate], [PurchaseOrderID] ) ON [OrderDateRangePScheme] ([OrderDate]); GO ALTER INDEX [OrdersPK] ON [dbo].[Orders] REBUILD WITH (STATISTICS_INCREMENTAL = ON);
След като клъстерираният индекс бъде създаден за схемата на дяловете, ще заредим нашите данни и след това ще проверим колко реда съществуват на дял (обърнете внимание, че това отнема над 7 минути на моя лаптоп може да искате да добавите по-малко редове в зависимост от това колко място за съхранение (и време) имате на разположение):
/* load some data */
SET NOCOUNT ON;
DECLARE @Loops SMALLINT = 0;
DECLARE @Increment INT = 5000;
WHILE @Loops < 10000 -- adjust this to increase or decrease the number
-- of rows in the table, 10000 = 40 millon rows
BEGIN
INSERT [dbo].[Orders]
( [PurchaseOrderID]
,[EmployeeID]
,[VendorID]
,[TaxAmt]
,[Freight]
,[SubTotal]
,[Status]
,[RevisionNumber]
,[ModifiedDate]
,[ShipMethodID]
,[ShipDate]
,[OrderDate]
,[TotalDue]
)
SELECT
[PurchaseOrderID] + @Increment
, [EmployeeID]
, [VendorID]
, [TaxAmt]
, [Freight]
, [SubTotal]
, [Status]
, [RevisionNumber]
, [ModifiedDate]
, [ShipMethodID]
, [ShipDate]
, [OrderDate]
, [TotalDue]
FROM [Purchasing].[PurchaseOrderHeader];
CHECKPOINT;
SET @Loops = @Loops + 1;
SET @Increment = @Increment + 5000;
END
/* Check to see how much data exists per partition */
SELECT
$PARTITION.[OrderDateRangePFN]([o].[OrderDate]) AS [Partition Number]
, MIN([o].[OrderDate]) AS [Min_Order_Date]
, MAX([o].[OrderDate]) AS [Max_Order_Date]
, COUNT(*) AS [Rows In Partition]
FROM [dbo].[Orders] AS [o]
GROUP BY $PARTITION.[OrderDateRangePFN]([o].[OrderDate])
ORDER BY [Partition Number];
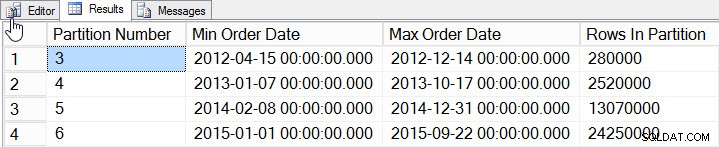 Данни на дял
Данни на дял
Добавихме данни за 2012 до 2015 г., със значително повече данни през 2014 и 2015 г. Нека видим как изглежда нашата статистика:
DBCC SHOW_STATISTICS ('dbo.Orders',[OrdersPK]);
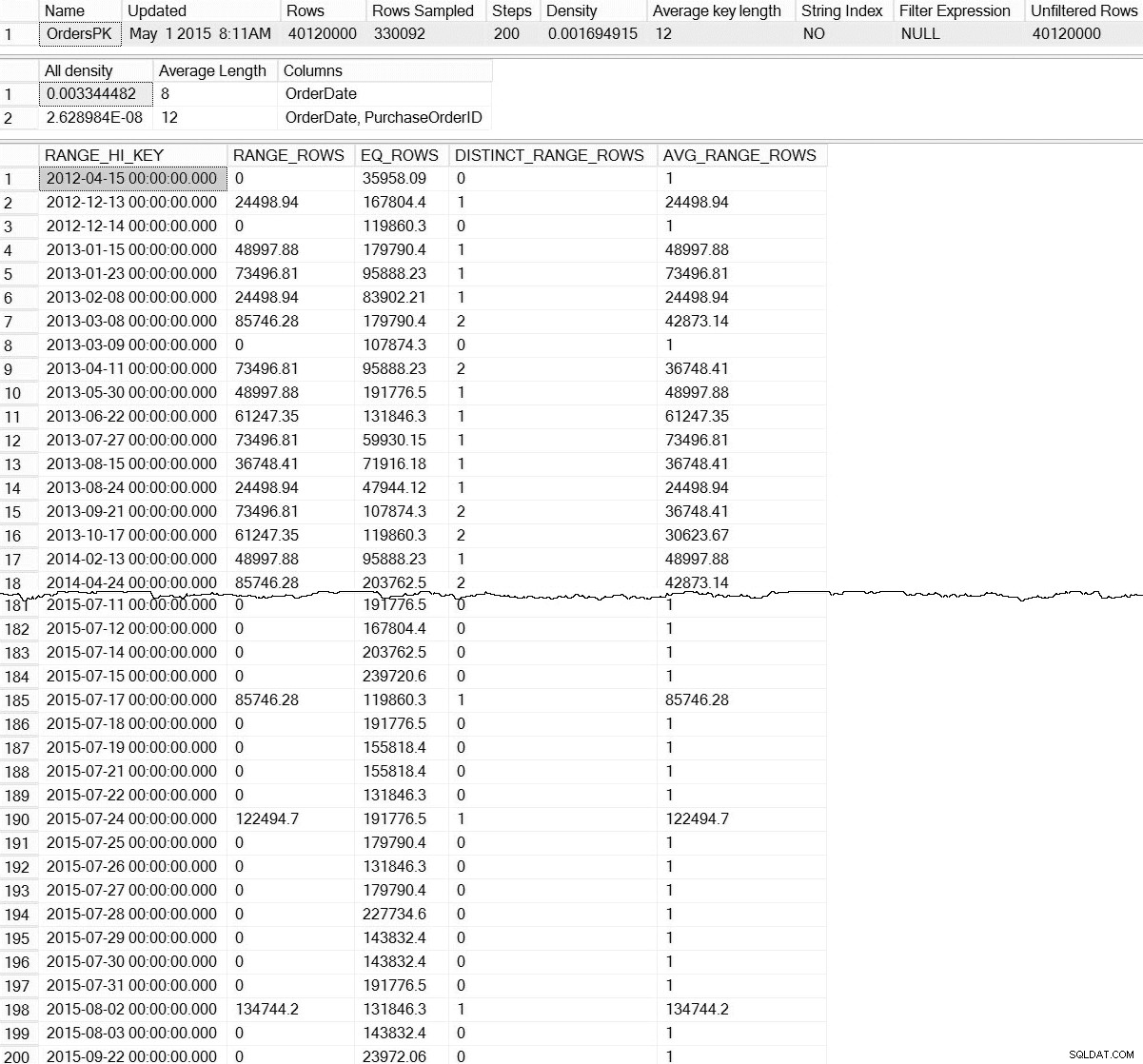 DBCC SHOW_STATISTICS изход за dbo.Orders (щракнете, за да увеличите)
DBCC SHOW_STATISTICS изход за dbo.Orders (щракнете, за да увеличите)
С DBCC SHOW_STATISTICS по подразбиране команда, нямаме никаква информация за статистиката на ниво дял. Не се страхувайте; не сме напълно обречени – има недокументирана функция за динамично управление, sys.dm_db_stats_properties_internal . Не забравяйте, че недокументиран означава, че не се поддържа (няма запис в MSDN за DMF) и че може да се промени по всяко време без предупреждение от Microsoft. Въпреки това, това е приличен старт, за да получите представа какво съществува за нашата допълнителна статистика:
SELECT *
FROM [sys].[dm_db_stats_properties_internal](OBJECT_ID('dbo.Orders'),1)
ORDER BY [node_id];
 Информация за хистограмата от dm_db_stats_properties_internal (щракнете, за да увеличите)
Информация за хистограмата от dm_db_stats_properties_internal (щракнете, за да увеличите)
Това е много по-интересно. Тук можем да видим доказателство, че статистиката на ниво дял (и повече) съществува. Тъй като този DMF не е документиран, трябва да направим известна интерпретация. За днес ще се съсредоточим върху първите седем реда в изхода, където първият ред представлява хистограмата за цялата таблица (обърнете внимание на rows стойност от 40 милиона), а следващите редове представляват хистограмите за всеки дял. За съжаление, partition_number стойността в тази хистограма не съвпада с номера на дяла от sys.dm_db_index_physical_stats за дясно-базирано разделяне (това корелира правилно за ляво-базирано разделяне). Също така имайте предвид, че този изход включва също last_updated и modification_counter колони, които са полезни при отстраняване на неизправности и може да се използва за разработване на скриптове за поддръжка, които интелигентно актуализират статистическите данни въз основа на възраст или модификации на редове.
Необходима е поддръжка до минимум
Основната стойност на инкременталните статистически данни в този момент е възможността да се актуализират статистическите данни за дял и да се слеят в хистограмата на ниво таблица, без да се налага да актуализирате статистиката за цялата таблица (и следователно да прочетете цялата таблица). За да видим това в действие, нека първо да актуализираме статистическите данни за дяла, който съдържа данните за 2015 г., дял 5, и ще запишем отнето време и ще направим моментна снимка на sys.dm_io_virtual_file_stats DMF преди и след, за да видите колко I/O се случва:
SET STATISTICS TIME ON; SELECT fs.database_id, fs.file_id, mf.name, mf.physical_name, fs.num_of_bytes_read, fs.num_of_bytes_written INTO #FirstCapture FROM sys.dm_io_virtual_file_stats(DB_ID(), NULL) AS fs INNER JOIN sys.master_files AS mf ON fs.database_id = mf.database_id AND fs.file_id = mf.file_id; UPDATE STATISTICS [dbo].[Orders]([OrdersPK]) WITH RESAMPLE ON PARTITIONS(6); GO SELECT fs.database_id, fs.file_id, mf.name, mf.physical_name, fs.num_of_bytes_read, fs.num_of_bytes_written INTO #SecondCapture FROM sys.dm_io_virtual_file_stats(DB_ID(), NULL) AS fs INNER JOIN sys.master_files AS mf ON fs.database_id = mf.database_id AND fs.file_id = mf.file_id; SELECT f.file_id, f.name, f.physical_name, (s.num_of_bytes_read - f.num_of_bytes_read)/1024 MB_Read, (s.num_of_bytes_written - f.num_of_bytes_written)/1024 MB_Written FROM #FirstCapture AS f INNER JOIN #SecondCapture AS s ON f.database_id = s.database_id AND f.file_id = s.file_id;
Изход:
Времена за изпълнение на SQL Server:CPU време =203 ms, изминало време =240 ms.
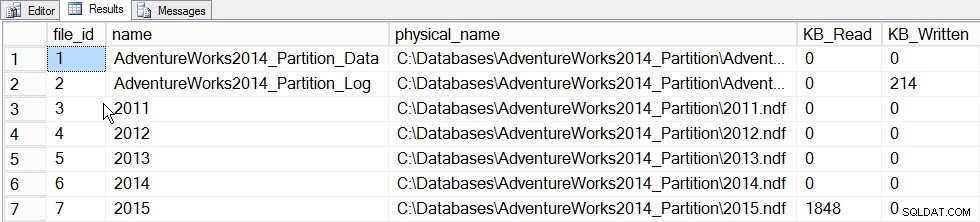 Данни File_stats след актуализиране на един дял
Данни File_stats след актуализиране на един дял
Ако погледнем sys.dm_db_stats_properties_internal изход, виждаме, че last_updated променено както за хистограмата от 2015 г., така и за хистограмата на ниво таблица (както и за няколко други възли, които са за по-късно разследване):
 Актуализирана информация за хистограмата от dm_db_stats_properties_internal
Актуализирана информация за хистограмата от dm_db_stats_properties_internal
Сега ще актуализираме статистическите данни с FULLSCAN за таблицата и ще направим моментна снимка file_stats преди и след това отново:
SET STATISTICS TIME ON; SELECT fs.database_id, fs.file_id, mf.name, mf.physical_name, fs.num_of_bytes_read, fs.num_of_bytes_written INTO #FirstCapture2 FROM sys.dm_io_virtual_file_stats(DB_ID(), NULL) AS fs INNER JOIN sys.master_files AS mf ON fs.database_id = mf.database_id AND fs.file_id = mf.file_id; UPDATE STATISTICS [dbo].[Orders]([OrdersPK]) WITH FULLSCAN SELECT fs.database_id, fs.file_id, mf.name, mf.physical_name, fs.num_of_bytes_read, fs.num_of_bytes_written INTO #SecondCapture2 FROM sys.dm_io_virtual_file_stats(DB_ID(), NULL) AS fs INNER JOIN sys.master_files AS mf ON fs.database_id = mf.database_id AND fs.file_id = mf.file_id; SELECT f.file_id, f.name, f.physical_name, (s.num_of_bytes_read - f.num_of_bytes_read)/1024 MB_Read, (s.num_of_bytes_written - f.num_of_bytes_written)/1024 MB_Written FROM #FirstCapture2 AS f INNER JOIN #SecondCapture2 AS s ON f.database_id = s.database_id AND f.file_id = s.file_id;
Изход:
Време за изпълнение на SQL Server:Време на процесора =12720 ms, изминало време =13646 ms
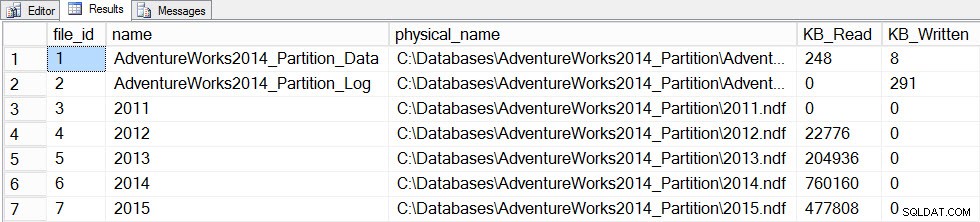 Файлстати данни след актуализиране с пълно сканиране
Файлстати данни след актуализиране с пълно сканиране
Актуализацията отне значително повече време (13 секунди срещу няколкостотин милисекунди) и генерира много повече I/O. Ако проверим sys.dm_db_stats_properties_internal отново откриваме, че last_updated променено за всички хистограми:
 Информация за хистограмата от dm_db_stats_properties_internal след пълно сканиране
Информация за хистограмата от dm_db_stats_properties_internal след пълно сканиране
Резюме
Въпреки че инкременталните статистики все още не се използват от оптимизатора на заявки за предоставяне на информация за всеки дял, те осигуряват предимство на производителността при управление на статистически данни за разделени таблици. Ако статистиката трябва да се актуализира само за избрани дялове, само те могат да бъдат актуализирани. След това новата информация се обединява в хистограмата на ниво таблица, предоставяйки на оптимизатора по-актуална информация, без да струва разходите за четене на цялата таблица. В бъдеще се надяваме, че тези статистически данни на ниво дял ще да се използва от оптимизатора. Следете...