SQL Server 2014 SP2 и по-късно създават планове за изпълнение („действителни“) по време на изпълнение, които могат да включват изминало време и използване на процесора за всеки оператор на план за изпълнение (вижте KB3170113 и тази публикация в блога на Педро Лопес).
Тълкуването на тези числа не винаги е толкова просто, колкото може да се очаква. Има важни разлики между редов режим и партиден режим изпълнение, както и трудни проблеми с паралелизъм в режим на ред . SQL Server прави някои корекции на времето паралелни планове за насърчаване на последователността, но те не се изпълняват перфектно. Това може да затрудни да се направят правилни заключения за настройка на производителността.
Тази статия има за цел да ви помогне да разберете откъде идват моментите във всеки отделен случай и как те могат да бъдат най-добре интерпретирани в контекста.
Настройка
Следните примери използват публичния Stack Overflow 2013 база данни (подробности за изтегляне), с добавен единичен индекс:
CREATE INDEX PP ON dbo.Posts (PostTypeId ASC, CreationDate ASC) INCLUDE (AcceptedAnswerId);
Тестовите заявки връщат броя на въпросите с приет отговор, групирани по месеци и година. Те се изпълняват на SQL Server 2019 CU9 , на лаптоп с 8 ядра и 16 GB памет, разпределена на екземпляра на SQL Server 2019. Ниво на съвместимост150 се използва изключително.
Серийно изпълнение в пакетен режим
SELECT
CA.TheYear,
CA.TheMonth,
AcceptedAnswers = COUNT_BIG(*)
FROM dbo.Posts AS Q
JOIN dbo.Posts AS A
ON A.Id = Q.AcceptedAnswerId
CROSS APPLY
(
VALUES
(
YEAR(Q.CreationDate),
MONTH (Q.CreationDate)
)
) AS CA (TheYear, TheMonth)
WHERE
Q.PostTypeId = 1
AND A.PostTypeId = 2
GROUP BY
CA.TheYear, CA.TheMonth
ORDER BY
CA.TheYear, CA.TheMonth
OPTION
(
MAXDOP 1,
USE HINT ('DISABLE_BATCH_MODE_ADAPTIVE_JOINS')
); Планът за изпълнение е (щракнете за уголемяване):
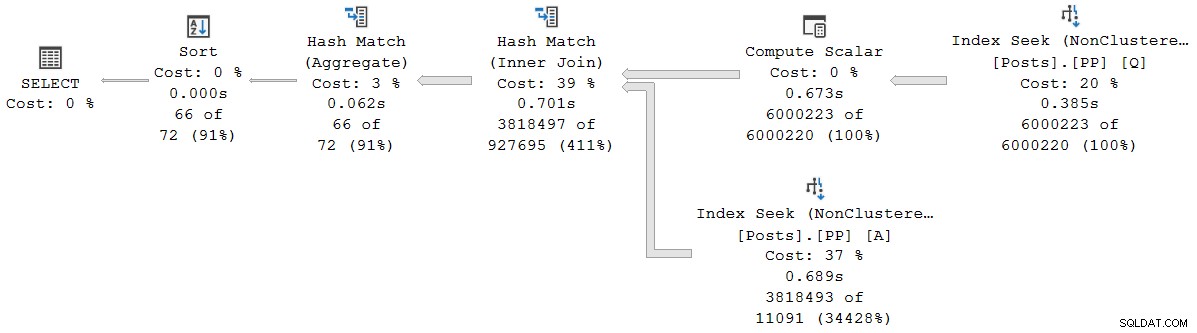
Всеки оператор в този план работи в пакетен режим, благодарение на пакетния режим на rowstore Функция за интелигентна обработка на заявки в SQL Server 2019 (не е необходим индекс на columnstore). Заявката се изпълнява за 2523 мс с използвано 2522 мс процесорно време, когато всички необходими данни вече са в буферния пул.
Както отбелязва Педро Лопес в публикацията в блога, свързана по-рано, отчетените изминали и процесорни времена за отделен партиден режим операторите представляват времето, използвано от само този оператор .
SSMS показва изминало време в графичното представяне. За да видите времената на процесора , изберете оператор на план, след което погледнете в Свойства прозорец. Този подробен изглед показва както изминалото, така и процесорното време, за оператор и за нишка.
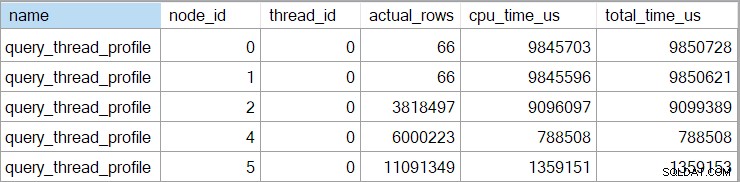
Времената на плана за показване (включително XML представянето) са съкратени до милисекунди. Ако имате нужда от по-голяма прецизност, използвайте query_thread_profile разширено събитие, което се отчита в микросекунди . Резултатът от това събитие за плана за изпълнение, показан по-горе, е:
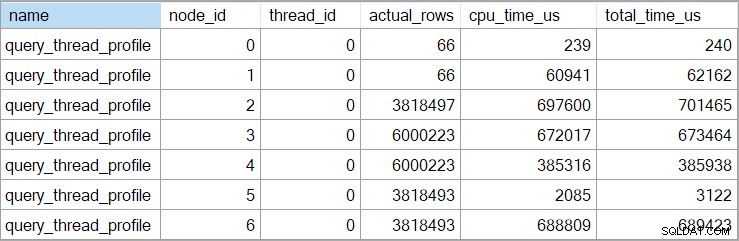
Това показва изминалото време за присъединяването (възел 2) е 701 465 µs (съкратено до 701 ms в showplan). Агрегатът има изминало време от 62,162µs (62ms). Търсенето на индекса на „въпроси“ се показва като работи за 385 ms, докато разширеното събитие показва, че истинската цифра за възел 4 е 385 938 µs (много почти 386 ms).
SQL Server използва високо прецизно QueryPerformanceCounter API за улавяне на данни за времето. Това използва хардуер, обикновено кристален осцилатор, който произвежда кърлежи с много висока постоянна скорост, независимо от скоростта на процесора, настройките на мощността или нещо от това естество. Часовникът продължава да работи със същата скорост дори по време на сън. Вижте свързаната много подробна статия, ако се интересувате от всички по-фини детайли. Краткото обобщение е, че можете да се доверите на числата в микросекундите, че са точни.
В този план за чисто пакетен режим общото време за изпълнение е много близко до сумата от изминалите времена на отделния оператор. Разликата до голяма степен се свежда до работата след изявлението, която не е свързана с планови оператори (които всички са приключили дотогава), въпреки че съкращаването на милисекундата също играе роля.
В плановете с чист пакетен режим трябва ръчно да сумирате текущото и дъщерното време на оператора, за да получите кумулативните изминало време във всеки даден възел.
Пакетен режим Паралелно изпълнение
SELECT
CA.TheYear,
CA.TheMonth,
AcceptedAnswers = COUNT_BIG(*)
FROM dbo.Posts AS Q
JOIN dbo.Posts AS A
ON A.Id = Q.AcceptedAnswerId
CROSS APPLY
(
VALUES
(
YEAR(Q.CreationDate),
MONTH (Q.CreationDate)
)
) AS CA (TheYear, TheMonth)
WHERE
Q.PostTypeId = 1
AND A.PostTypeId = 2
GROUP BY
CA.TheYear, CA.TheMonth
ORDER BY
CA.TheYear, CA.TheMonth
OPTION
(
MAXDOP 8,
USE HINT ('DISABLE_BATCH_MODE_ADAPTIVE_JOINS')
); Планът за изпълнение е:
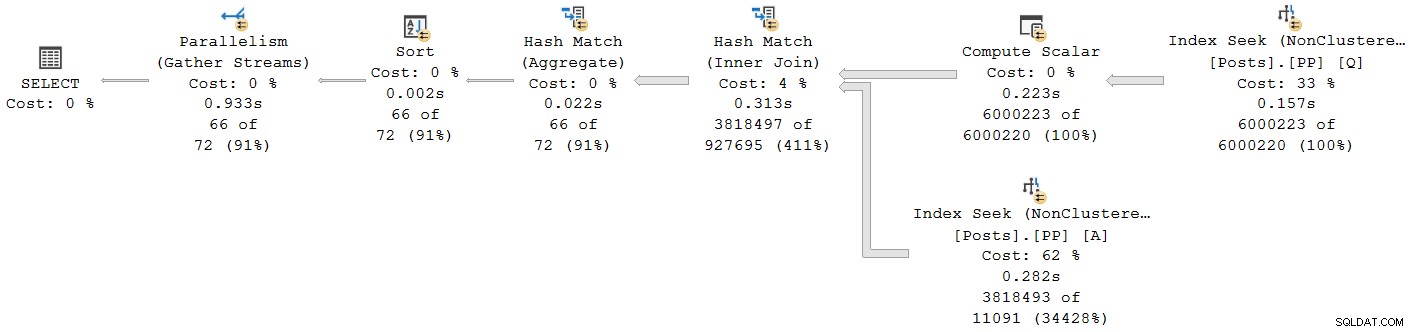
Всеки оператор с изключение на обмена на окончателния събирателен поток работи в пакетен режим. Общото изминало време е 933 мс с 6673 мс време на процесора с топъл кеш.
Избиране на хеш присъединяването и търсене в Свойства на SSMS прозорец, виждаме изтекло и процесорно време на нишка за този оператор:
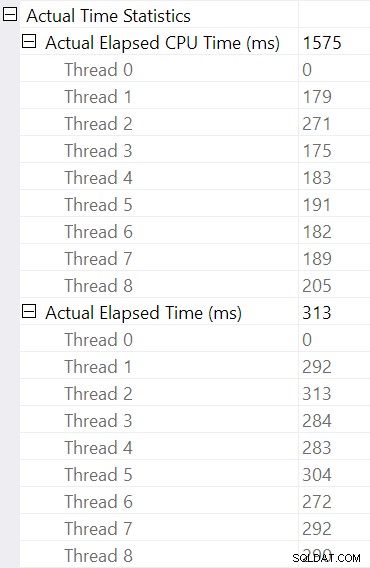
Времето на процесора отчетена за оператора е сборът от процесорните времена на отделната нишка. Съобщеният оператор изминало време е максималната от изминалите времена на нишка. И двете изчисления се извършват върху съкратените стойности за милисекунди за нишка. Както и преди, общото време за изпълнение е много близко до сумата от изминалите времена на отделните оператори.
Паралелните планове за пакетен режим не използват обмен за разпределение на работата между нишките. Пакетните оператори са внедрени така, че множество нишки да могат да работят ефективно в една споделена структура (напр. хеш таблица). Все още се изисква известна синхронизация между нишки в паралелни планове в пакетен режим, но точките за синхронизиране и други подробности не се виждат в изхода на showplan.
Серийно изпълнение в режим на ред
SELECT
CA.TheYear,
CA.TheMonth,
AcceptedAnswers = COUNT_BIG(*)
FROM dbo.Posts AS Q
JOIN dbo.Posts AS A
ON A.Id = Q.AcceptedAnswerId
CROSS APPLY
(
VALUES
(
YEAR(Q.CreationDate),
MONTH (Q.CreationDate)
)
) AS CA (TheYear, TheMonth)
WHERE
Q.PostTypeId = 1
AND A.PostTypeId = 2
GROUP BY
CA.TheYear, CA.TheMonth
ORDER BY
CA.TheYear, CA.TheMonth
OPTION
(
MAXDOP 1,
USE HINT ('DISALLOW_BATCH_MODE')
); Планът за изпълнение визуално е същият като серийния план в пакетен режим, но всеки оператор вече работи в режим на ред:
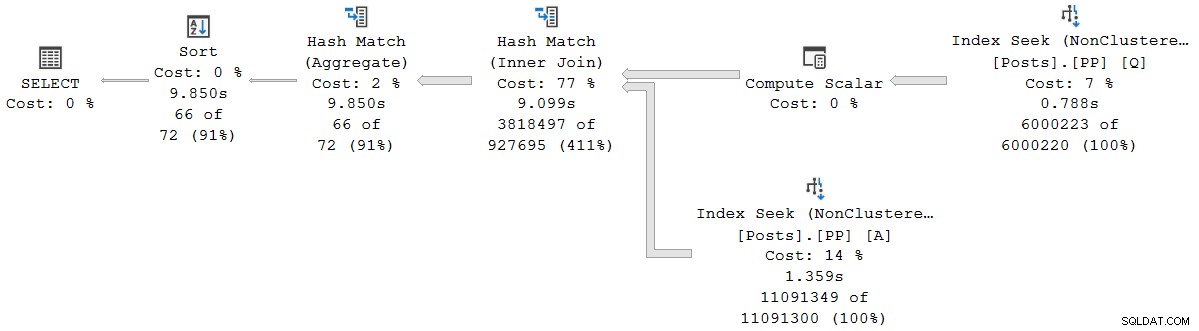
Заявката се изпълнява за 9 850 мс с 9 845 ms процесорно време. Това е много по-бавно от заявката в серийния пакетен режим (2523ms/2522ms), както се очакваше. По-важното за настоящата дискусия е редовият режим изминал оператор и времената на процесора представляват времето, използвано от текущия оператор и всички негови деца .
Разширеното събитие също така показва кумулативния процесор и изминалите времена на всеки възел (в микросекунди):
Няма данни за изчислителния скаларен оператор (възел 3), тъй като изпълнението в режим на ред може да отложи повечето изчисления на изрази към оператора, който консумира резултата. Това понастоящем не се прилага за изпълнение в пакетен режим.
Отчетенияткумулативно изминалото време за операторите в режим на ред означава, че времето, показано за оператора за окончателно сортиране, съвпада с общото време за изпълнение на заявката (все пак до разделителна способност от милисекунди). Изминалото време за хеш присъединяването също включва приноси от двата индекса за търсене под него, както и собственото му време. За да изчислите изминалото време само за хеш присъединяването в режим на ред, ще трябва да извадим и двете пъти на търсене от него.
И двете презентации имат предимства и недостатъци (кумулативно за режим на ред, индивидуален оператор само за пакетен режим). Каквото и да предпочитате, важно е да сте наясно с разликите.
Планове за смесен режим на изпълнение
Като цяло, съвременните планове за изпълнение могат да съдържат всякаква комбинация от оператори за редов и пакетен режим. Операторите на пакетен режим ще докладват времената само за себе си. Операторите на редовия режим ще включват кумулативна сума до този момент в плана, включително всички дъщерни оператори. За да е ясно:кумулативните времена на оператор в редов режим включват всички дъщерни оператори в групов режим.
Видяхме това по-рано в плана за паралелен пакетен режим:Операторът на окончателния (редов режим) на събиране на потоци имаше показано (кумулативно) изминало време от 0,933 s — включително всички негови оператори на дъщерния пакетен режим. Всички други оператори бяха в пакетен режим и така отчетените времена само за отделния оператор.
Тази ситуация, при която някои оператори планират в същия план имат кумулативни времена, а други не, без съмнение ще се счита за объркващо от много хора.
Режим на ред Паралелно изпълнение
SELECT
CA.TheYear,
CA.TheMonth,
AcceptedAnswers = COUNT_BIG(*)
FROM dbo.Posts AS Q
JOIN dbo.Posts AS A
ON A.Id = Q.AcceptedAnswerId
CROSS APPLY
(
VALUES
(
YEAR(Q.CreationDate),
MONTH (Q.CreationDate)
)
) AS CA (TheYear, TheMonth)
WHERE
Q.PostTypeId = 1
AND A.PostTypeId = 2
GROUP BY
CA.TheYear, CA.TheMonth
ORDER BY
CA.TheYear, CA.TheMonth
OPTION
(
MAXDOP 8,
USE HINT ('DISALLOW_BATCH_MODE')
); Планът за изпълнение е:

Всеки оператор е в редов режим. Заявката се изпълнява за 4677 мс с 23 311 ms CPU време (сума от всички нишки).
Като план с изключително редов режим бихме очаквали всички времена да бъдат кумулативни . Преминавайки от дете към родител (отдясно наляво), времето трябва да се увеличава в тази посока.
Нека разгледаме само най-десния раздел на плана:
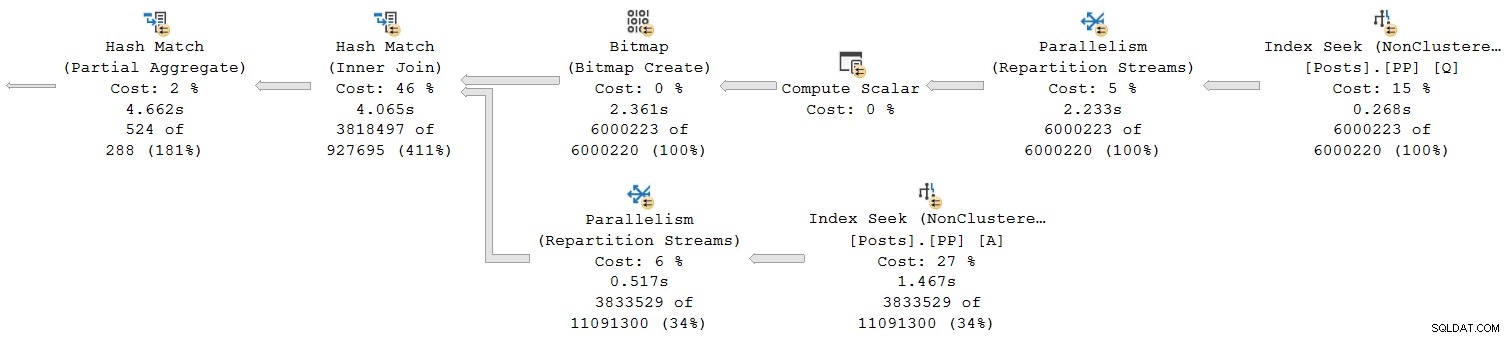
Работейки отдясно наляво на горния ред, кумулативните времена със сигурност изглежда са такива. Но има иизключение на долния вход към хеш присъединяването:Търсенето на индекс има изминало време от 1,467 s , докато неговият родител потоците за повторно разделяне имат изминало време от само 0,517 s .
Как може един родител оператор работи за по-малко време отколкото неговотодете ако изминалите времена са кумулативни в плановете за редов режим?
Непостоянни времена
Отговорът на този пъзел има няколко части. Нека го вземем парче по парче, защото е доста сложно:
Първо, припомнете си, че обменът (оператор на паралелизъм) има две части. Лявата ръка (потребитела ) страна е свързана с един набор от нишки, изпълняващи оператори в паралелния клон вляво. Дясната ръка (производител ) страната на обмена е свързана с различен набор от нишки, изпълняващи оператори в паралелния клон вдясно.
Редове от страна на производителя се сглобяват в пакети и след това се прехвърля на страната на потребителите. Това осигурява известна степен на буфериране и контрол на потока между двата комплекта свързани нишки. (Ако имате нужда от опресняване относно борси и клонове на паралелни планове, моля, вижте статията ми Планове за паралелно изпълнение – клонове и нишки.)
Обхватът на кумулативните времена
Гледайки паралелния клон на производителя страна на обмена:
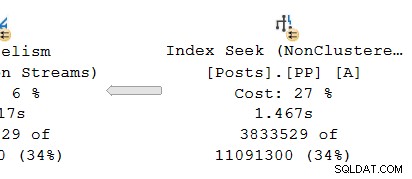
Както обикновено, DOP (степен на паралелизъм) допълнителни работни нишки изпълняват независим сериен копие на операторите на плана в този клон. И така, при DOP 8 има 8 независими сериен индекс за търсене, които си сътрудничат, за да изпълнят частта за сканиране на обхвата на цялостната (паралелна) операция за търсене на индекс. Всяко еднонишково търсене е свързано с различен вход (порт) от страна на производителя на единичното споделено обменен оператор.
Подобна ситуация съществува и при потребителя страна на борсата. В DOP 8 има 8 отделни еднонишкови копия на този клон, които работят независимо:
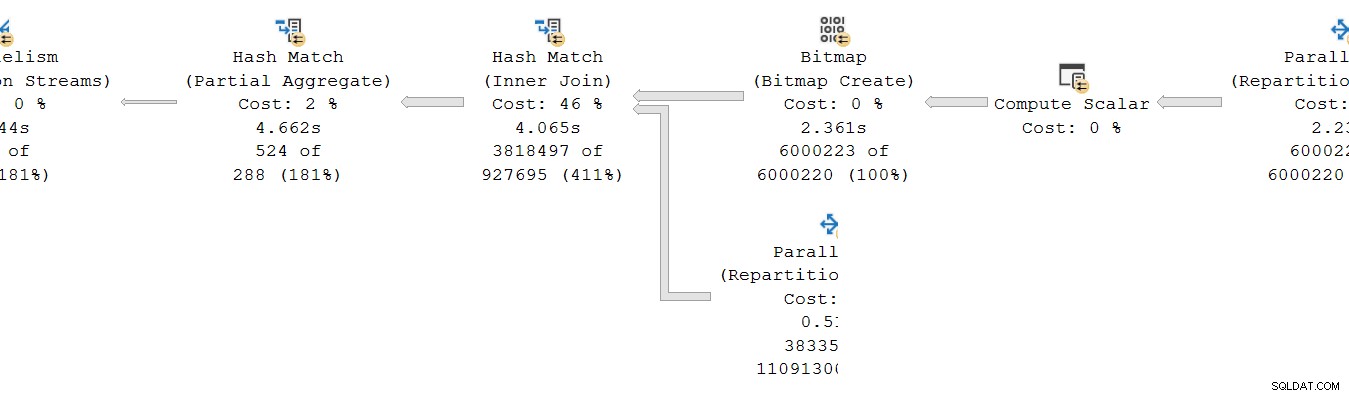
Всеки от тези еднонишкови подпланове работи по обичайния начин, като всеки оператор натрупва изтеклото и общото време на процесора на всеки възел. Като оператори в режим на ред, всяка обща сума представлява времето, прекарано от общата сума за текущия възел и всеки от неговите дъщерни точки.
Решаващият момент е, че кумулативните суми включват само оператори в същата нишка и само в рамките на текущия клон . Надяваме се, че това има интуитивен смисъл, защото всяка нишка няма представа какво може да се случва другаде.
Как се събират показателите за режим на ред
Втората част на пъзела се отнася до начина, по който броят на редовете и времевите показатели се събират в плановете за редов режим. Когато се изисква информация за план за време на изпълнение („действително“), машината за изпълнение добавя невидим профилиращ оператор отнепосредствено вляво (родител) на всеки оператор в плана, който ще бъде изпълнен по време на изпълнение.
Този оператор може да записва (наред с други неща) разликата между момента, в който е предал контрола на своя дъщерен оператор, и времето, когато контролът е върнат. Тази времева разлика представлява изминалото време за наблюдавания оператори всички негови деца , тъй като детето извиква своето собствено дете на ред и така нататък. Операторът може да бъде извикан много пъти (за инициализиране, след това веднъж на ред, накрая за затваряне), така че времето, събрано от оператора за профилиране, е натрупване над потенциално много повторения на ред.
За повече подробности относно данните за профилиране събрани с помощта на различни методи за улавяне, вижте документацията на продукта, обхващаща инфраструктурата за профилиране на заявки. За тези, които се интересуват от подобни неща, името на невидимия оператор за профилиране, използван от стандартната инфраструктура, е sqlmin!CQScanProfileNew . Както всички итератори на редов режим, той има Open , GetRow и Close методи, между другото. Всеки метод съдържа извиквания към QueryPerformanceCounter на Windows API за събиране на текущата стойност на таймера с висока разделителна способност.
Тъй като операторът за профилиране е вляво на целевия оператор, измерва само потребителя страна на борсата. Няма оператор за профилиране за приздатела страна на обмена (за съжаление). Ако имаше, то би съвпадало или би надвишило изминалото време, показано при търсенето на индекс, тъй като търсенето на индекс и страната производител изпълняват един и същи набор от нишки, а страната производител на обмена е операторът родител на търсенето на индекс.
Времето е преразгледано

С всичко казано, все още може да имате проблеми с времето, показано по-горе. Как може търсенето на индекс да отнеме 1,467 сек за да предаде редове в страната производител на обмен, но страната на потребителя отнема само 0,517 s да ги получи? Независимо от отделни нишки, буфериране и какво ли още не, със сигурност обменът трябва да работи (от край до край) по-дълго от търсенето?
Е, да, така е, но това е различно измерване от изминало или процесорно време. Нека бъдем точни за това, което измерваме тук.
За режим на ред изминало време , представете си хронометър на нишка при всеки оператор. Хронометърът започва когато SQL Server въведе кода за оператор от своя родител и спира (но не се нулира), когато този код остави оператора да върне контрола обратно на родителя (не на дете). Изминалото време включва всякакви изчаквания или закъснения при планиране – нито едно от тях не спира часовника.
За редов режим CPU време , представете си същия хронометър със същите характеристики, с изключение на това, че спира по време на изчакване и забавяне на графика. Той натрупва време само когато операторът или едно от неговите деца се изпълняват активно на планировчик (CPU). Общото време на хронометър за нишка на оператор се формира от цикъл старт-стоп за всеки ред.
Нека приложим това към текущата ситуация с потребителската страна на борсата и търсенето на индекс:
Не забравяйте, че потребителската страна на борсата и търсенето на индекси са в отделни клонове, така че те работят в отделни нишки . Потребителската страна няма деца в същата нишка. Търсенето на индекс има производителната страна на борсата като своя родител със същата нишка, но ние нямаме хронометър там.
Всяка потребителска нишка стартира своя часовник, когато нейният родителски оператор (пробната страна на хеш присъединяването) премине контрола (например за извличане на ред). Часовникът продължава да работи, докато потребителят извлича ред от текущия обменен пакет. Часовникътспира когато контролът напусне потребителя и се върне към страната на сондата за хеш присъединяване. Други родители (частичния агрегат и неговият родителски обмен) също ще работят върху този ред (и може да изчакат), преди контролът да се върне към потребителската страна на нашия обмен, за да извлече следващия ред. В този момент потребителската страна на нашия обмен започва да натрупва отново изтекло и процесорно време.
Междувременно, независимо от това, което може да правят нишките на потребителския клон, търсене на индекса нишките продължават да намират редове в индекса и да ги подават в обмена. Нишка за търсене на индекс стартира своя хронометър, когато страната производител на борсата я поиска ред. Хронометърът е на пауза, когато редът се предаде на борсата. Когато обменът поиска следващия ред, хронометърът за търсене на индекса се възобновява.
Имайте предвид, че от страна на производителя на борсата може да се появи CXPACKET изчаква, докато буферите за обмен се запълнят, но това няма да добави към изминалите времена, записани при търсенето на индекс, тъй като неговият хронометър не работи, когато това се случи. Ако имахме хронометър за производителя на борсата, липсващото изминало време щеше да се покаже там.
За визуално приближаване на обобщението на ситуацията, следната диаграма показва кога всеки оператор натрупва изминало време в двата паралелни клона:
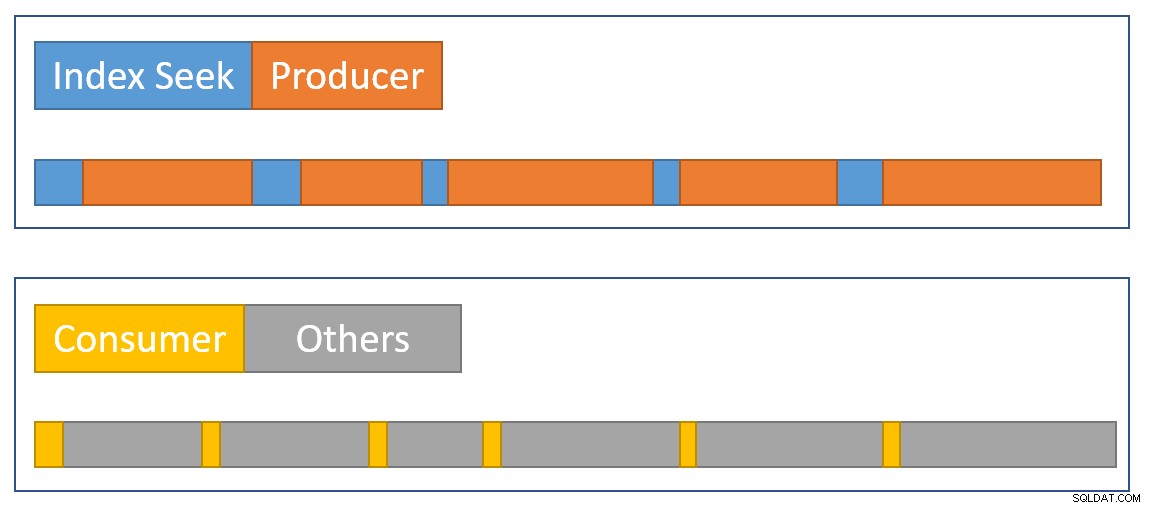
Синьото Времевите ленти за търсене на индекс са кратки, защото извличането на ред от индекс е бързо. Портокалата времената на производителя може да са дълги поради CXPACKET чака. Вжълтото времената на потребителите са кратки, защото е бързо да се извлече ред от обмена, когато има налични данни. Сивото Времевите сегменти представляват времето, използвано от другите оператори (от страната на пробната хеш присъединяване, частичния агрегат и от страната производител на основната борса) над потребителската страна на обмена.
Очакваме обменните пакети да бъдат попълнени бързо от търсенето на индекса, ноизпразва се бавно (относително казано) от операторите от страна на потребителите, защото те имат повече работа за вършене. Това означава, че пакетите в обмена обикновено ще бъдат пълни или близо до пълни. Потребителят ще може бързо да извлече чакащ ред, но производителят може да трябва да изчака, докато се появи пространство за пакети.
Жалко е, че не можем да видим изминали времена от страна на производителя на борсата. Отдавна съм на мнение, че една борса трябва да се представлява отдвама различни оператори в планове за изпълнение. Това би затруднило CXPACKET /CXCONSUMER анализът на чакане е много по-малко необходим, а плановете за изпълнение са много по-лесни за разбиране. Операторът производител на обмен естествено ще получи свой собствен оператор за профилиране.
Алтернативни дизайни
Има много начини, по които SQL Server може да постигне последователно кумулативно изминало и процесорно време в паралелни клонове по принцип . Вместо профилиращи оператори, всеки ред може да носи информация за това колко изминало и процесорно време е натрупал досега по време на пътуването си през плана. С историята, свързана с всеки ред, няма да има значение как обмените преразпределят редовете между нишки и т.н.
Продуктът не е проектиран така, така че не е това, което имаме (и така или иначе може да е неефективно). За да бъдем честни, оригиналният дизайн на режима на ред се занимаваше само с неща като събиране на действителен брой редове и броя на повторенията при всеки оператор. Добавянето на изминало време за оператор към плановете беше много търсена функция , но не беше лесно да се включи в съществуващата рамка.
Когато пакетната обработка беше добавена към продукта, различен подход (време само за текущия оператор) можеше да бъде приложен като част от първоначалната разработка, без да се нарушава нищо. Отново, по принцип , операторите за редов режим биха могли да бъдат модифицирани да работят по същия начин като операторите в пакетен режим, но това би изисквало много работа по реинженеринг на всеки съществуващ оператор в режим на ред. Добавянето на нова точка от данни към съществуващите оператори за профилиране в редов режим беше много по-лесно. Предвид ограничените инженерни ресурси и дълъг списък от желани подобрения на продуктите, често трябва да се правят компромиси като този.
Вторият проблем
Друго кумулативно несъответствие във времето се появява в настоящия план от лявата страна:

На пръв поглед това изглежда като същия проблем:частичният агрегат има изминало време от 4,662 s , но обменът над него работи само за 2.844s . Разбира се, действат същата основна механика, както преди, но има и друг важен фактор. Една улика се крие в подозрително равни времена, отчетени за обмена на потока за събиране, сортиране и преразпределяне.
Помните ли „корекциите на времето“, които споменах във въведението? Тук идват тези. Нека да разгледаме отделните изминали времена за нишки от страна на потребителя на обмена на потоци за преразпределение:
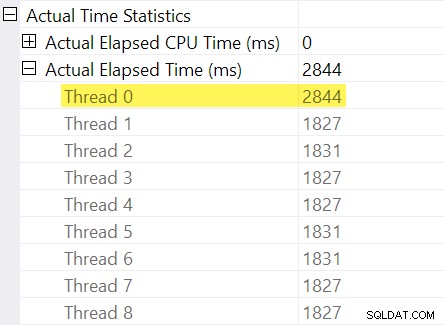
Припомнете си, че плановете показват изминалото време за паралелен оператор като максимум от времената за нишка. Всичките 8 нишки имат изминало време около 1830 ms, но има допълнителен запис за „Нишка 0“ с 2 844 ms. Наистина всеки оператор в този паралелен клон (консуматорът на обмен, сортирането и агрегатът на потока) имат същото 2844 мс принос от „Нишка 0“.
Нулева нишка (известна още като родителска задача или координатор) само директно изпълнява оператори вляво от оператора за окончателно събиране на потоци. Защо му е възложена работа тук, в паралелен клон?
Обяснение
Този проблем може да възникне, когато има блокиращ оператор в паралелния клон по-долу (вдясно от) текущия. Без тази корекция операторите в текущия клон ще отчитат недостатъчно изминало време от времето, необходимо за отваряне на дъщерния клон (има сложни архитектурни причини за това).
SQL Server търси да отчете това, като записва забавянето на дъщерното разклонение при обмена в невидимия оператор за профилиране. Стойността на времето се записва спрямо родителската задача („Нишка 0“) в разликата между нейната първа активна и последно активен пъти. (Може да изглежда странно да се записва числото по този начин, но в момента, в който номерът трябва да бъде записан, допълнителните паралелни работни нишки все още не са създадени).
В настоящия случай, 2844ms корекция възниква предимно поради времето, необходимо на хеш присъединяването, за да изгради своята хеш таблица. (Обърнете внимание, че това време е различно от общото време на изпълнение на хеш присъединяването, което включва времето, необходимо за обработка на пробната страна на съединението).
Необходимостта от корекция възниква, тъй като хеш присъединяването блокира входа си за изграждане. (Интересно е, че хешът частичен агрегат в плана не се счита за блокиране в този контекст, тъй като му е присвоено само минимално количество памет, никога не се разлива в tempdb и просто спира агрегирането, ако паметта му свърши (по този начин се връща към режим на поточно предаване). Крейг Фридман обяснява това в публикацията си, Частично агрегиране).
Като се има предвид, че корекцията на изминалото време представлява забавяне на инициализацията в дъщерния клон, SQL Server трябва за да третирате стойността „Нишка 0“ като отместване за измерените числа за изминало време за нишка в текущия клон. Вземаната от всички нишки, тъй като изминалото време е разумно като цяло, тъй като нишките са склонни да започват по едно и също време. Това не има смисъл да се прави това, когато една от стойностите на нишката е отместване за всички останали стойности!
Можем да направим правилното изчисление на отместване ръчно, използвайки наличните данни в плана. От страната на потребителите на борсата имаме:
Максималното изминало време между допълнителните работни нишки е 1831 ms (с изключение на стойността на отместване, съхранена в „Нишка 0“). Добавяне на отместване от 2844ms дава общо 4675ms .
Във всеки план, при който времето за нишка е по-малко отколкото отместването, операторът щенеправилно покажете изместването като общото изминало време. Това вероятно ще се случи, когато по-ранният блокиращ оператор е бавен (може би сортиране или глобален агрегат върху голям набор от данни) и по-късните оператори на клон отнемат по-малко време.
Преразглеждане на тази част от плана:
Замяна на отместването от 2 844 мс, погрешно присвоено на операторите за преразпределяне на потоци, сортиране и обобщение на потока с нашите изчислени 4 675 мс стойността поставя техните кумулативни изминали времена точно между 4 662 ms при частичен агрегат и 4 676 ms на финалния събиране на потоци. (Сортирането и агрегатът работят на малък брой редове, така че техните изчисления за изминалото време излизат същите като сортирането, но като цяло често биха били различни):

Всички оператори във фрагмента на плана по-горе имат 0ms изминало време на процесора във всички нишки (освен частичния агрегат, който има 14,891ms). Следователно планът с нашите изчислени числа има много по-голям смисъл от показания:
- 4675 мс – 4662 мс =13 мс elapsed е много по-разумно число за времето, изразходвано от потоците за преразпределение само . Този оператор не консумира процесорно време и обработва само 524 реда.
- 0 мс изтеклото (до милисекунда разделителна способност) е разумно за малкия агрегат за сортиране и поток (отново, с изключение на техните деца).
- 4676ms – 4675ms =1ms изглежда добре крайните потоци за събиране да събират 66 реда в нишката на родителската задача за връщане към клиента.
Освен очевидното несъответствие в дадения план между частичния агрегат (4 662 ms) и потоците за преразпределение (2 844 ms), неразумно е да се смята, че окончателните потоци за събиране от 66 реда биха могли да бъдат отговорни за 4 676 ms – 2 844 ms = 1832 мси на изминалото време. Коригираното число (1ms) е много по-точно и няма да подведе тунерите на заявки.
Сега, дори ако това изчисление на отместването е извършено правилно, плановете за паралелен ред може да не показват последователни кумулативни времена във всички случаи поради причините, обсъдени по-рано. Постигането на пълна последователност може да бъде трудно или дори невъзможно без големи архитектурни промени.
За да предвидим въпрос, който може да възникне в този момент:Не, по-ранният анализ на обмен и търсене на индекс не включва грешка при изчисляване на отместване „Нишка 0“. Под този обмен няма блокиращ оператор, така че не възниква забавяне на инициализацията.
Последен пример
Следващата примерна заявка използва същата база данни и индекс, както преди. Няма да го изследвам твърде подробно, защото служи само за разширяване на точките, които вече направих, за заинтересования читател.
Характеристиките на тази демонстрация са:
- Без
ORDER GROUPнамек, показва как частичния агрегат не се счита за блокиращ оператор, така че при обмена на потоци за преразпределение не възниква корекция „Нишка 0“. Изминалите времена са последователни. - С намека се въвеждат блокиращи сортове вместо частичен агрегат за хеширане. Дваразлни Корекциите на „Нишка 0“ се появяват при двете обмени за преразпределение. Изминалите времена са несъвместими и в двата клона по различни начини.
Запитване:
SELECT * FROM
(
SELECT
yr = YEAR(P.CreationDate),
mth = MONTH(P.CreationDate),
mx = MAX(P.CreationDate)
FROM dbo.Posts AS P
WHERE
P.PostTypeId = 1
GROUP BY
YEAR(P.CreationDate),
MONTH(P.CreationDate)
) AS C1
JOIN
(
SELECT
yr = YEAR(P.CreationDate),
mth = MONTH(P.CreationDate),
mx = MAX(P.CreationDate)
FROM dbo.Posts AS P
WHERE
P.PostTypeId = 2
GROUP BY
YEAR(P.CreationDate),
MONTH(P.CreationDate)
) AS C2
ON C2.yr = C1.yr
AND C2.mth = C1.mth
ORDER BY
C1.yr ASC,
C1.mth ASC
OPTION
(
--ORDER GROUP,
USE HINT ('DISALLOW_BATCH_MODE')
);
План за изпълнение без ORDER GROUP (без корекция, последователни времена):

План за изпълнение с ORDER GROUP (две различни корекции, непоследователни времена):

Обобщение и заключения
Row mode plan operators report cumulative times inclusive of all child operators in the same thread. Batch mode operators record the time used inside that operator alone .
A single plan can include both row and batch mode operators; the row mode operators will record cumulative elapsed time, including any batch operators. Correctly interpreting elapsed times in mixed-mode plans can be challenging.
For parallel plans, total CPU time for an operator is the sum of individual thread contributions. Total elapsed time is the maximum of the per-thread numbers.
Row mode actual plans include an invisible profiling operator to the immediate left (parent) of executing visible operators to collect runtime statistics like total row count, number of iterations, and timings. Because the row mode profiling operator is a parent of the target operator, it captures activity for that operator and all children (but only in the same thread).
Exchanges are row mode operators. There is no separate hidden profiling operator for the producer side, so exchanges only show details and timings for the consumer side . The consumer side has no children in the same thread so it reports timings for itself only.
Long elapsed times on an exchange with low CPU usage generally mean the consumer side has to wait for rows (CXCONSUMER ). This is often caused by a slow producer side (with various root causes). For an example of that with a super investigation, see CXCONSUMER As a Sign of Slow Parallel Joins by Josh Darneli.
Batch mode operators do not use separate profiling operators. The batch mode operator itself contains code to record timing on every entry and exit (e.g. per batch). Passing control to a child operator counts as an exit . This is why batch mode operators record only their own activity (exclusive of their child operators).
Internal architectural details mean the way parallel row mode plans start up would cause elapsed times to be under-reported for operators in a parallel branch when a child parallel branch contains a blocking operator. An attempt is made to adjust for the timing offset caused by this, but the implementation appears to be incomplete, resulting in inconsistent and potentially misleading elapsed times. Multiple separate adjustments may be present in a single execution plan. Adjustments may accumulate when multiple branches contain blocking operators, and a single operator may combine more than one adjustment (e.g. merge join with an adjustment on each input).
Without the attempted adjustments, parallel row-mode plans would only show consistent elapsed times within a branch (i.e. between parallelism operators). This would not be ideal, but it would arguably be better than the current situation. As it is, we simply cannot trust elapsed times in parallel row-mode plans to be a true reflection of reality.
Look out for “Thread 0” elapsed times on exchanges, and the associated branch plan operators. These will sometimes show up as implausibly identical times for operators within that branch. You may need to manually add the offset to the maximum per-thread times for each affected operator to get sensible results.
The same adjustment mechanism exists for CPU times , but it appears non-functional at the moment. Unfortunately, this means you should not expect CPU times to be cumulative across branches in row mode parallel plans. This is somewhat ironic because it does make sense to sum CPU times (including the “Thread 0” value). I doubt many people rely on cumulative CPU times in execution plans though.
With any luck, these calculations will be improved in a future product update, if the required corrective work is not too onerous.
In the meantime, this all represents another reason to prefer batch mode plans when dealing with even moderately large numbers of rows. Performance will usually be improved, and the timing numbers will make more sense. Remember, SQL Server 2019 makes batch mode processing easier to achieve in practice because it does not require a columnstore index.