Има много случаи на използване за генериране на поредица от стойности в SQL Server. Не говоря за постоянен IDENTITY колона (или новата SEQUENCE в SQL Server 2012), а по-скоро преходен набор, който да се използва само за целия живот на заявка. Или дори най-простите случаи – като просто добавяне на номер на ред към всеки ред в набор от резултати – което може да включва добавяне на ROW_NUMBER() функция към заявката (или, още по-добре, в нивото на презентация, което така или иначе трябва да преглежда резултатите ред по ред).
Говоря за малко по-сложни случаи. Например, може да имате отчет, който показва продажбите по дата. Типична заявка може да бъде:
SELECT OrderDate = CONVERT(DATE, OrderDate), OrderCount = COUNT(*) FROM dbo.Orders GROUP BY CONVERT(DATE, OrderDate) ORDER BY OrderDate;
Проблемът с тази заявка е, че ако няма поръчки в определен ден, няма да има ред за този ден. Това може да доведе до объркване, подвеждащи данни или дори до неправилни изчисления (помислете за средните дневни стойности) за потребителите надолу по веригата на данните.
Така че има нужда да се запълнят тези празнини с датите, които не присъстват в данните. И понякога хората ще запишат своите данни в таблица #temp и ще използват WHILE цикъл или курсор, за да попълните липсващите дати една по една. Няма да показвам този код тук, защото не искам да се застъпвам за използването му, но съм го виждал навсякъде.
Преди да навлезем твърде дълбоко в датите обаче, нека първо поговорим за числата, тъй като винаги можете да използвате поредица от числа, за да извлечете поредица от дати.
Таблица с числа
Отдавна съм привърженик на съхраняването на спомагателна "таблица с числа" на диск (и, по този въпрос, календарна таблица също).
Ето един начин да генерирате проста таблица с числа с 1 000 000 стойности:
SELECT TOP (1000000) n = CONVERT(INT, ROW_NUMBER() OVER (ORDER BY s1.[object_id])) INTO dbo.Numbers FROM sys.all_objects AS s1 CROSS JOIN sys.all_objects AS s2 OPTION (MAXDOP 1); CREATE UNIQUE CLUSTERED INDEX n ON dbo.Numbers(n) -- WITH (DATA_COMPRESSION = PAGE) ;
Защо MAXDOP 1? Вижте публикацията в блога на Пол Уайт и неговия елемент Connect, свързан с целите на редовете.
Въпреки това, много хора са против подхода на спомагателната маса. Техният аргумент:защо да съхраняват всички тези данни на диск (и в паметта), когато могат да генерират данните в движение? Моят контра е да бъдете реалисти и да мислите какво оптимизирате; изчисленията могат да бъдат скъпи и сигурни ли сте, че изчисляването на диапазон от числа в движение винаги ще бъде по-евтино? Що се отнася до пространството, таблицата Numbers заема само около 11 MB компресирана и 17 MB некомпресирана. И ако таблицата се препраща достатъчно често, тя винаги трябва да е в паметта, което прави достъпа бърз.
Нека да разгледаме няколко примера и някои от по-често срещаните подходи, използвани за тяхното задоволяване. Надявам се, че всички можем да се съгласим, че дори при 1000 стойности не искаме да решаваме тези проблеми с помощта на цикъл или курсор.
Генериране на поредица от 1000 числа
Като започнем от простото, нека генерираме набор от числа от 1 до 1000.
Таблица с числа
Разбира се, с таблица с числа тази задача е доста проста:
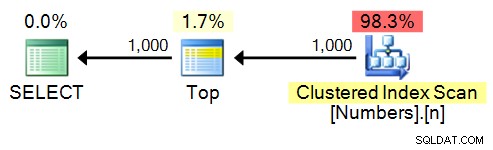
SELECT TOP (1000) n FROM dbo.Numbers ORDER BY n;
План:
spt_values
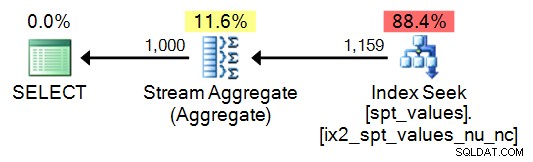
Това е таблица, която се използва от вътрешни съхранени процедури за различни цели. Използването му онлайн изглежда доста разпространено, въпреки че е недокументирано, неподдържано, може да изчезне един ден и тъй като съдържа само краен, неуникален и несвързан набор от стойности. Има 2164 уникални и 2508 общи стойности в SQL Server 2008 R2; през 2012 г. има 2 167 уникални и 2 515 общо. Това включва дубликати, отрицателни стойности и дори ако се използва DISTINCT , много пропуски, след като надхвърлите числото 2048. Така че решението е да използвате ROW_NUMBER() за генериране на непрекъсната последователност, започваща от 1, въз основа на стойностите в таблицата.
SELECT TOP (1000) n = ROW_NUMBER() OVER (ORDER BY number) FROM [master]..spt_values ORDER BY n;
План:

Въпреки това само за 1000 стойности можете да напишете малко по-проста заявка за генериране на същата последователност:
SELECT DISTINCT n = number FROM master..[spt_values] WHERE number BETWEEN 1 AND 1000;
Това води до по-опростен план, разбира се, но се разпада доста бързо (след като последователността ви трябва да бъде повече от 2048 реда):
Във всеки случай не препоръчвам използването на тази таблица; Включвам го за целите на сравнението, само защото знам колко от това има и колко изкушаващо може да е просто да използвате повторно кода, на който попаднете.
sys.all_objects
Друг подход, който беше един от любимите ми през годините, е да използвам sys.all_objects . Като spt_values , няма надежден начин за директно генериране на непрекъсната последователност и имаме същите проблеми, свързани с краен набор (малко под 2000 реда в SQL Server 2008 R2 и малко над 2000 реда в SQL Server 2012), но за 1000 реда можем да използваме същия ROW_NUMBER() трик. Причината, поради която харесвам този подход, е, че (а) има по-малко опасения, че този изглед ще изчезне скоро, (б) самият изглед е документиран и поддържан и (в) ще работи във всяка база данни във всяка версия след SQL Server 2005, без да се налага да преминават границите на базата данни (включително съдържащите се бази данни).
SELECT TOP (1000) n = ROW_NUMBER() OVER (ORDER BY [object_id]) FROM sys.all_objects ORDER BY n;
План:

Натрупани CTEs
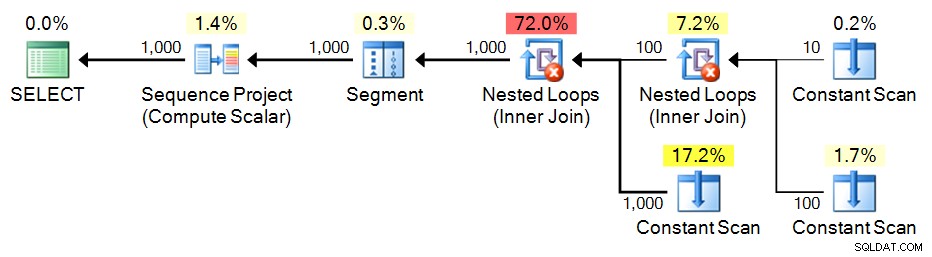
Вярвам, че Ицик Бен-Ган заслужава най-голямата заслуга за този подход; по принцип вие конструирате CTE с малък набор от стойности, след което създавате декартовия продукт срещу себе си, за да генерирате необходимия брой редове. И отново, вместо да се опитваме да генерираме непрекъснат набор като част от основната заявка, можем просто да приложим ROW_NUMBER() до крайния резултат.
;WITH e1(n) AS
(
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
), -- 10
e2(n) AS (SELECT 1 FROM e1 CROSS JOIN e1 AS b), -- 10*10
e3(n) AS (SELECT 1 FROM e1 CROSS JOIN e2) -- 10*100
SELECT n = ROW_NUMBER() OVER (ORDER BY n) FROM e3 ORDER BY n; План:
Рекурсивен CTE
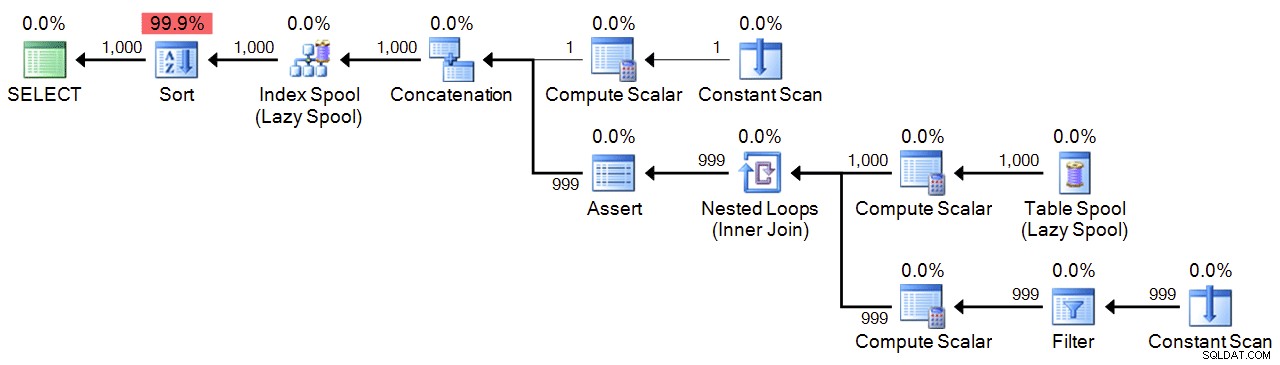
И накрая, имаме рекурсивна CTE, която използва 1 като котва и добавя 1, докато достигнем максимума. За безопасност посочвам максимума и в двата WHERE клауза на рекурсивната част и в MAXRECURSION настройка. В зависимост от това колко числа имате нужда, може да се наложи да зададете MAXRECURSION до 0 .
;WITH n(n) AS
(
SELECT 1
UNION ALL
SELECT n+1 FROM n WHERE n < 1000
)
SELECT n FROM n ORDER BY n
OPTION (MAXRECURSION 1000); План:
Ефективност
Разбира се при 1000 стойности разликите в производителността са незначителни, но може да е полезно да видите как се представят тези различни опции:
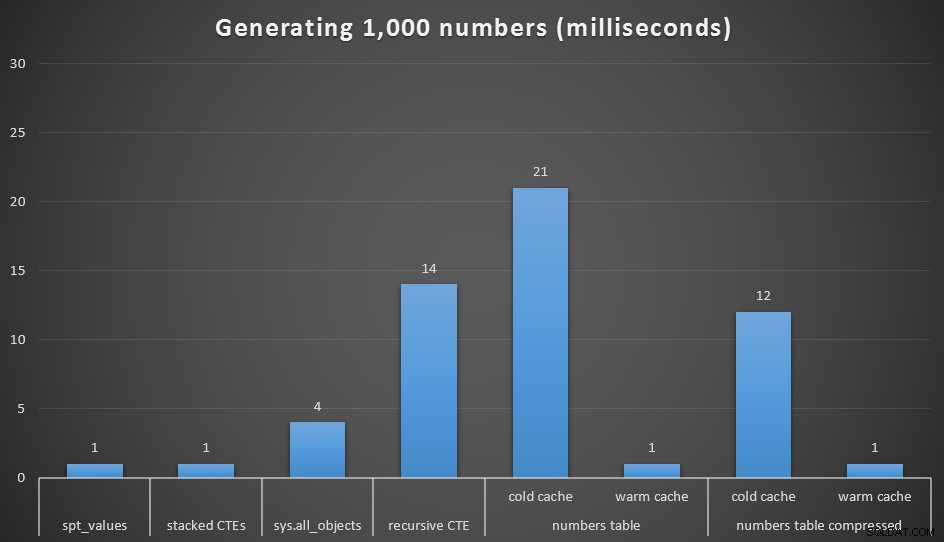
Време на изпълнение, в милисекунди, за генериране на 1000 последователни числа
Изпълних всяка заявка 20 пъти и взех средно време на изпълнение. Тествах и dbo.Numbers таблица, както в компресиран, така и в некомпресиран формат, както и със студен и топъл кеш. С топъл кеш, той много съперничи на другите най-бързи опции (spt_values , не се препоръчва и подредени CTE), но първият хит е сравнително скъп (въпреки че почти се смея, като го наричам така).
Продължава...
Ако това е вашият типичен случай на използване и няма да се осмелите далеч отвъд 1000 реда, тогава се надявам, че съм показал най-бързите начини за генериране на тези числа. Ако вашият случай на използване е по-голям брой или ако търсите решения за генериране на поредици от дати, следете за нас. По-късно в тази поредица ще изследвам генерирането на поредици от 50 000 и 1 000 000 числа и периоди от дати, вариращи от седмица до година.
[ Част 1 | Част 2 | Част 3 ]



