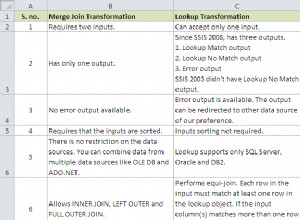
Филтрираните индекси са невероятно мощни, но все още виждам известно объркване около тях – особено за колоните, които се използват във филтрите, и какво се случва, когато искате да затегнете филтрите.
Скорошен въпрос на dba.stackexchange поиска помощ за това защо колоните, използвани във филтъра на филтриран индекс, трябва да бъдат включени във „включените“ колони на индекса. Отличен въпрос – с изключение на това, че имах чувството, че е започнало в лоша предпоставка, защото тези колони не трябва да се включват в индекса . Да, помагат, но не по начина, по който изглежда въпросът предполага.
За да ви спести разглеждането на самия въпрос, ето кратко обобщение:
За да задоволим тази заявка...
SELECT Id, DisplayName FROM Users WHERE Reputation > 400000;
…следният филтриран индекс е доста добър:
CREATE UNIQUE NONCLUSTERED INDEX Users_400k_Club ON dbo.Users ( DisplayName, Id ) INCLUDE ( Reputation ) WHERE Reputation > 400000;
Но въпреки наличието на този индекс, Оптимизаторът на заявки препоръчва следния индекс, ако филтрираната стойност е затегната до, да речем, 450 000.
CREATE NONCLUSTERED INDEX IndexThatWasMissing ON dbo.Users ( Reputation ) INCLUDE ( DisplayName, Id );
Тук перифразирам малко въпроса, който започва с позоваване на тази ситуация и след това изгражда различен пример, но идеята е същата. Просто не исках да усложнявам нещата, като включвам отделна таблица.
Въпросът е – индексът, предложен от QO, е оригиналният индекс, но обърнат на главата си. Оригиналният индекс имаше Reputation в списъка INCLUDE и DisplayName и Id като ключови колони, докато новият препоръчан индекс е обратното с Reputation като ключова колона и DisplayName &ID в INCLUDE. Нека да разгледаме защо.
Въпросът се отнася до публикация на Ерик Дарлинг, където той обяснява, че е настроил заявката „450 000“ по-горе, като е поставил Reputation в колоната INNCLUDE. Ерик показва, че без Reputation в списъка INNCLUDE, заявка, която се филтрира до по-висока стойност на Reputation, трябва да извърши търсене (лошо!), или може би дори да се откаже изцяло от филтрирания индекс (потенциално дори по-лошо). Той заключава, че наличието на колона Reputation в списъка INCLUDE позволява на SQL да има статистически данни, така че да може да прави по-добър избор, и показва, че с Reputation в INCLUDE различни заявки, които всички филтрират по по-високи стойности на репутацията, сканират неговия филтриран индекс.
В отговор на въпроса dba.stackexchange, Брент Озар посочва, че подобренията на Ерик не са особено големи, защото предизвикват сканиране. Ще се върна на това, защото това е интересно само по себе си и донякъде неправилно.
Първо нека помислим малко за индексите като цяло.
Индексът предоставя подредена структура на набор от данни. (Бих могъл да бъда педантичен и да отбележа, че четенето на данните в индекс от началото до края може да ви прескача от страница на страница по привидно хаотичен начин, но все пак, докато четете през страници, следвайки указателите от една страница на страница на следващия можете да сте сигурни, че данните са подредени. В рамките на всяка страница можете дори да прескачате, за да прочетете данните по ред, но има списък, който ви показва кои части (слотове) от страницата трябва да се четат в кой ред. Наистина няма смисъл от моята педантичност, освен да отговарям на онези също толкова педантични, които ще коментират, ако не го направя.)
И този ред е според ключовите колони – това е лесната част, която всеки получава. Полезно е не само за това, че можете да избегнете повторното подреждане на данните по-късно, но и за това, че можете бързо да намерите всеки конкретен ред или диапазон от редове по тези колони.
Листовите нива на индекса съдържат стойностите във всички колони в списъка INCLUDE или в случай на клъстериран индекс, стойностите във всички колони в таблицата (с изключение на несъхранени изчислени колони). Другите нива в индекса съдържат само ключовите колони и (ако индексът не е уникален) уникалния адрес на реда – който е или ключовете на клъстерирания индекс (с унификатора на реда, ако клъстерираният индекс също не е уникален ) или стойността на RowID за куп, достатъчно, за да позволи лесен достъп до всички други стойности на колоните за реда. Нивата на листа също включват цялата информация за „адрес“.
Но това не е интересното за тази публикация. Интересното за тази публикация е това, което имам предвид под "набор от данни". Не забравяйте, че казах „Индексът предоставя подредена структурана набор от данни ".
В клъстериран индекс този набор от данни е цялата таблица, но може да е нещо друго. Вероятно вече можете да си представите как повечето неклъстерирани индекси не включват всички колони на таблицата. Това е едно от нещата, които правят неклъстерните индекси толкова полезни, защото обикновено са много по-малки от основната таблица.
В случай на индексиран изглед, нашият набор от данни може да бъде резултат от цяла заявка, включително обединения в много таблици! Това е за друга публикация.
Но във филтриран индекс това не е просто копие на подмножество от колони, но и подмножество от редове. Така че в примера тук индексът е само за потребителите с повече от 400 000 репутация.
CREATE UNIQUE NONCLUSTERED INDEX Users_400k_Club_NoInclude ON dbo.Users ( DisplayName, Id ) WHERE Reputation > 400000;
Този индекс взема потребителите, които имат повече от 400 000 репутация, и ги подрежда по DisplayName и Id. Тя може да бъде уникална, защото (предполага се) колоната Id вече е уникална. Ако опитате нещо подобно на собствената си маса, може да се наложи да внимавате с това.
Но в този момент индексът не се интересува каква е репутацията за всеки потребител – просто се интересува дали репутацията е достатъчно висока, за да бъде в индекса или не. Ако репутацията на потребителя се актуализира и надхвърли прага, показваното име и идентификатор на потребителя ще бъдат вмъкнати в индекса. Ако падне по-долу, ще бъде изтрит от индекса. Това е точно като да имаме отделна маса за високите играчи, с изключение на това, че вкарваме хората в тази маса, като увеличаваме стойността им на репутация над прага от 400k в основната таблица. Може да направи това, без да се налага действително да съхранява самата стойност на репутацията.
Така че сега, ако искаме да намерим хора, които имат праг над 450 000, в този индекс липсва някаква информация.
Разбира се, можем с увереност да кажем, че всички, които ще намерим, са в този индекс – но индексът не съдържа достатъчно информация сам по себе си, за да филтрира допълнително по Reputation. Ако ви кажа, че имах азбучен списък с филми, носители на Оскар за най-добър филм от 90-те години (Красавица по-американска, Смело сърце, Танци с вълци, Английски пациент, Форест Гъмп, Списъкът на Шиндлер, Влюбеният Шекспир, Мълчанието на агнетата, Титаник, Непростено) , тогава мога да ви уверя, че победителите за 1994-1996 г. биха били подмножество от тях, но не мога да отговоря на въпроса, без първо да получа повече информация.
Очевидно моят филтриран индекс би бил по-полезен, ако бях включил годината и потенциално дори повече, ако годината беше ключова колона, тъй като новата ми заявка иска да намери тези за 1994-1996. Но вероятно създадох този индекс около заявка, за да изброя всички филми от 90-те години на миналия век по азбучен ред. Тази заявка не се интересува каква е действителната година, само дали е през 90-те години на миналия век или не, и дори не е нужно да връщам годината – само заглавието – за да мога да сканирам моя филтриран индекс, за да получа резултатите. За тази заявка дори не е необходимо да пренареждам резултатите или да намирам началната точка – моят индекс наистина е перфектен.
По-практичен пример да не се интересувате от стойността на колоната във филтъра е на състояние, като например:
WHERE IsActive = 1
Често виждам код, който премества данни от една таблица в друга, когато редовете престанат да бъдат „активни“. Хората не искат стари редове да претрупват таблицата им и те осъзнават, че техните „горещи“ данни са само малка част от всичките им данни. Така те преместват данните си за охлаждане в архивна таблица, като поддържат тяхната активна таблица малка.
Филтриран индекс може да направи това вместо вас. Зад сцената. Веднага след като актуализирате реда и промените тази колона IsActive на нещо различно от 1. Ако ви интересува само да имате активни данни в повечето от вашите индекси, тогава филтрираните индекси са идеални. Дори ще върне редове обратно в индексите, ако стойността IsActive се промени обратно на 1.
Но не е нужно да поставяте IsActive в списъка INNCLUDE, за да постигнете това. Защо искате да съхранявате стойността – вече знаете каква е стойността – тя е 1! Освен ако не поискате да върнете стойността, не би трябвало да се нуждаете от нея. И защо ще връщате стойността, когато вече знаете, че отговорът е 1, нали?! Само дето е разочароващо, статистиката, на която Ерик се позовава в публикацията си, ще се възползва от това, че е в списъка ВКЛЮЧВАНЕ. Не ви е нужен за заявката, но трябва да го включите за статистиката.
Нека помислим какво трябва да направи Оптимизаторът на заявки, за да разбере полезността на даден индекс.
Преди да може да направи много, трябва да прецени дали индексът е кандидат. Няма смисъл да използвате индекс, ако няма всички редове, които може да са необходими – освен ако нямаме ефективен начин да получим останалите. Ако искам филми от 1985-1995 г., тогава моят индекс на филми от 1990-те е доста безсмислен. Но за 1994-1996 г. може би не е лошо.
В този момент, точно като всяко разглеждане на индекса, трябва да помисля дали ще помогне достатъчно за намирането на данните и привеждането им в поръчка, която ще помогне за изпълнението на останалата част от заявката (евентуално за Merge Join, Stream Aggregate, удовлетворяващо ПОРЪЧКА ОТ или различни други причини). Ако моят филтър за заявки съвпада точно с индексния филтър, тогава няма нужда да филтрирам повече – достатъчно е само използването на индекса. Това звучи страхотно, но ако не съвпада точно, ако филтърът ми за заявки е по-строг от индексния филтър (като примера ми от 1994-1996 г. или 450 000 на Ерик), ще трябва да имам тези стойности за годината или стойностите на репутацията за проверка – надявам се да ги получа или от ВКЛЮЧЕНО на ниво лист или някъде в моите ключови колони. Ако те не са в индекса, ще трябва да направя справка за всеки ред в моя филтриран индекс (и в идеалния случай да имам представа колко пъти ще бъде извикан моята Lookup, какви са статистическите данни, които Ерик иска колоната, включена за).
В идеалния случай всеки индекс, който смятам да използвам, е подреден правилно (чрез ключовете), ВКЛЮЧВА всички колони, които трябва да върна, и е предварително филтриран само до редовете, от които се нуждая. Това би бил идеалният индекс и моят план за изпълнение ще бъде сканиране.
Точно така, СКАНИРАНЕ. Не търсене, а сканиране. Ще започне от първата страница на моя индекс и ще продължи да ми дава редове, докато не получа толкова, колкото са ми необходими, или докато няма повече редове за връщане. Не пропускам никакви, не ги сортирам – просто ми давам редовете в ред.
Търсенето предполага, че нямам нужда от целия индекс, което означава, че губя ресурси за поддържане на тази част от индекса и за да го потърся, трябва да намеря началната точка и да продължа да проверявам редовете, за да видя дали съм удари края или не. Ако моето сканиране има предикат, тогава разбира се, трябва да преглеждам (и тествам) повече данни, отколкото ми е необходимо, но ако индексните ми филтри са перфектни, тогава оптимизаторът на заявки трябва да разпознае това и не трябва да извършва тези проверки .
Последни мисли
INCLUDE не са критични за филтрираните индекси. Те са полезни за осигуряване на лесен достъп до колони, които може да са полезни за вашата заявка, и ако случайно стегнете това, което има във вашия филтриран индекс с която и да е колона, независимо дали е спомената във филтъра или не, трябва да помислите за тази колона в сместа. Но в този момент трябва да се запитате дали филтърът на вашия индекс е правилният, какво друго трябва да имате в списъка си INCLUDE и дори каква трябва да бъде ключовата колона(и). Заявките на Ерик не играха добре, защото той се нуждаеше от информация, която не беше в индекса, въпреки че беше споменал колоната във филтъра. Той намери добра употреба и за статистиката и все пак бих ви насърчил да включите филтърните колони поради тази причина. Но поставянето им в INCLUDE не им позволява внезапно да започнат да извършват търсене, защото не работи нито един индекс, независимо дали е филтриран или не.
Искам ти, читателю, да разбираш наистина добре филтрираните индекси. Те са невероятно полезни и когато започнете да ги представяте като таблици със собствени права, могат да станат част от цялостния дизайн на базата данни. Те също така са причина винаги да използвате настройките ANSI_NULL и QUOTED_IDENTIFIER, защото ще получавате грешки от филтриран индекс, освен ако тези настройки не са ВКЛЮЧЕНИ, но се надяваме, че вече сте сигурни, че така или иначе винаги са включени.
О, и тези филми бяха Форест Гъмп, Смело сърце и Английският пациент.
@rob_farley