Открояването на удари е функция, която много хора желаят да поддържа пълнотекстово търсене на SQL Server. Това е мястото, където можете да върнете целия документ (или откъс) и да посочите думите или фразите, които са помогнали за съответствието на този документ с търсенето. Правенето на това по ефективен и точен начин не е лесна задача, както разбрах от първа ръка.
Като пример за маркиране на удари:когато извършвате търсене в Google или Bing, получавате удебелен шрифт на ключовите думи както в заглавието, така и в откъса (щракнете върху някое изображение, за да го увеличите):

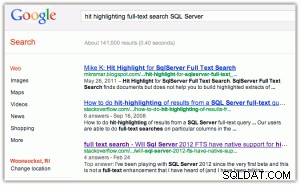
[Като настрана, намирам две неща за забавни тук:(1) че Bing предпочита собствеността на Microsoft много повече, отколкото Google, и (2) че Bing се притеснява да връща 2,2 милиона резултата, много от които вероятно са без значение.]
Тези откъси обикновено се наричат „фрагменти“ или „обобщения, пристрастни към заявките“. От известно време искаме тази функционалност в SQL Server, но все още не сме чули добри новини от Microsoft:
- Свързване #295100 :Резюме за търсене в пълен текст (открояване на натискане)
- Свързване #722324 :Би било добре, ако SQL Full Text Search предоставя поддръжка за фрагмент/маркиране
Въпросът се появява и в Stack Overflow от време на време:
- Как да направите маркиране на резултати от заявка за пълен текст на SQL Server
- Ще има ли Sql Server 2012 FTS вградена поддръжка за подчертаване на хитове?
Има някои частични решения. Този скрипт от Майк Крамар, например, ще създаде извлечен от удара подчертан, но не прилага същата логика (като специфични за езика прекъсвачи на думи) към самия документ. Той също така използва абсолютен брой знаци, така че откъсът може да започне и да завърши с частични думи (както ще демонстрирам скоро). Последното е доста лесно за поправяне, но друг проблем е, че зарежда целия документ в паметта, вместо да извършва какъвто и да е вид поточно предаване. Подозирам, че в пълнотекстови индекси с големи размери на документи това ще бъде забележим удар в производителността. Засега ще се съсредоточа върху сравнително малък среден размер на документа (35 KB).
Прост пример
Така че да кажем, че имаме много проста таблица с дефиниран индекс на пълен текст:
СЪЗДАЙТЕ ПЪЛНОТЕКСТОВ КАТАЛОГ [FTSDemo]; ОТКРИТЕ СЪЗДАЙТЕ ТАБЛИЦА [dbo].[Документ]( [ID] INT IDENTITY(1001,1) NOT NULL, [Url] NVARCHAR(200) NOT NULL, [Дата] DATE NOT NULL , [Заглавие] NVARCHAR(200) NOT NULL, [Съдържание] NVARCHAR(MAX) NOT NULL, ОГРАНИЧЕНИЕ PK_DOCUMENT ПРАВИЛЕН КЛЮЧ(ID));СЪЗДАДЕТЕ ПЪЛЕН ИНДЕКС НА [dbo].[Документ]( [Съдържание] ЕЗИК [английски] , [Title] LANGUAGE [English])KEY INDEX [PK_Document] ON ([FTSDemo]);
Тази таблица е попълнена с няколко документа (по-конкретно 7), като Декларацията за независимост и речта на Нелсън Мандела „Готов съм да умра“. Типичното търсене в пълен текст в тази таблица може да бъде:
SELECT d.Title, d.[Content]FROM dbo.[Document] AS d INNER JOIN CONTAINSTABLE(dbo.[Document], *, N'states') AS t ON d.ID =t.[KEY] ПОРЪЧАЙТЕ ПО [РАНГ] DESC;
Резултатът връща 4 реда от 7:

Сега използвам UDF функция като тази на Майк Крамар:
SELECT d.Title, Excerpt =dbo.HighLightSearch(d.[Content], N'states', 'font-weight:bold', 80)ОТ dbo.[Document] AS DINNER JOIN CONTAINSTABLE(dbo.[Document]). ], *, N'състояния') КАТО tON d.ID =t.[KEY]ПОРЪЧАЙТЕ ПО [RANK] DESC;
Резултатите показват как работи откъсът:a <SPAN> маркерът се инжектира при първата ключова дума и извадката се изрязва въз основа на отместване от тази позиция (без да се взема предвид използването на пълни думи):

(Отново, това е нещо, което може да се поправи, но искам да съм сигурен, че представям правилно това, което има сега.)
ThinkHighlight
Еран Меючас от Interactive Thoughts е разработил компонент, който решава много от тези проблеми. ThinkHighlight се реализира като CLR асембли с две функции със скаларна стойност на CLR:
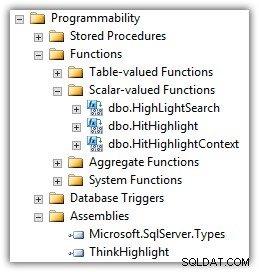
(Ще видите също UDF на Майк Крамар в списъка с функции.)
Сега, без да навлизате във всички подробности за инсталирането и активиране на сборката във вашата система, ето как горната заявка ще бъде представена с ThinkHighlight:
SELECT d.Title, Excerpt =dbo.HitHighlight(dbo.HitHighlightContext('Document', 'Content', N'states', -1), 'top-fragment', 100, d.ID)FROM dbo. [Документ] КАТО ВЕЧЕРЯ ПРИСЪЕДИНЕТЕ CONTAINSTABLE(dbo.[Document], *, N'states') КАТО tON d.ID =t.[KEY]ПОРЪЧАЙТЕ ПО t.[RANK] DESC; Резултатите показват как се открояват най-подходящите ключови думи и извадка от това се извлича въз основа на пълни думи и отместване от маркирания термин:

Някои допълнителни предимства, които не съм демонстрирал тук, включват възможността за избор на различни стратегии за обобщаване, контролиране на представянето на всяка ключова дума (а не всички) с помощта на уникален CSS, както и поддръжка на множество езици и дори документи в двоичен формат (повечето IFilters се поддържат).
Резултати от производителността
Първоначално тествах показателите по време на изпълнение за трите заявки, използвайки SQL Sentry Plan Explorer, спрямо 7-редовата таблица. Резултатите бяха:

След това исках да видя как ще се сравняват при много по-голям размер на данните. Вмъкнах таблицата в себе си, докато стигнах до 4000 реда, след което изпълних следната заявка:
ЗАДАДЕТЕ ВРЕМЕТО НА СТАТИСТИКАТА ON;GO SELECT /* FTS */ d.Title, d.[Content]FROM dbo.[Document] AS d INNER JOIN CONTAINSTABLE(dbo.[Document], *, N'states') AS tON d.ID =t.[KEY]ПОРЪЧАЙТЕ ПО [РАНГ] DESC;GO SELECT /* UDF */ d.Title, Excerpt =dbo.HighLightSearch(d.[Content], N'states', 'font-weight:удебелен', 100)ОТ dbo.[Документ] КАТО ВЕЧЕРЯ ПРИСЪЕДИНЯВА СЪДЪРЖАВАНЕ(dbo.[Документ], *, N'състояния') КАТО tON d.ID =t.[КЛЮЧ]ПОРЪЧАЙТЕ ПО [РАНГ] DESC;ИЗБИРАЙТЕ ИЗБЕРЕТЕ / * ThinkHighlight */ d.Title, Excerpt =dbo.HitHighlight(dbo.HitHighlightContext('Document', 'Content', N'states', -1), 'top-fragment', 100, d.ID)FROM dbo. [Документ] КАТО ВЕЧЕРЯ ПРИСЪЕДИНЯВА CONTAINSTABLE(dbo.[Document], *, N'states') КАТО tON d.ID =t.[КЛЮЧ]ПОРЪЧКА ПО t.[РАНГ] DESC;GO SET СТАТИСТИКА ВРЕМЕ ИЗКЛЮЧВАНЕ;GO предварително>
Също така наблюдавах sys.dm_exec_memory_grants, докато заявките се изпълняваха, за да открия всякакви несъответствия в предоставените памет. Резултати средно над 10 проби:
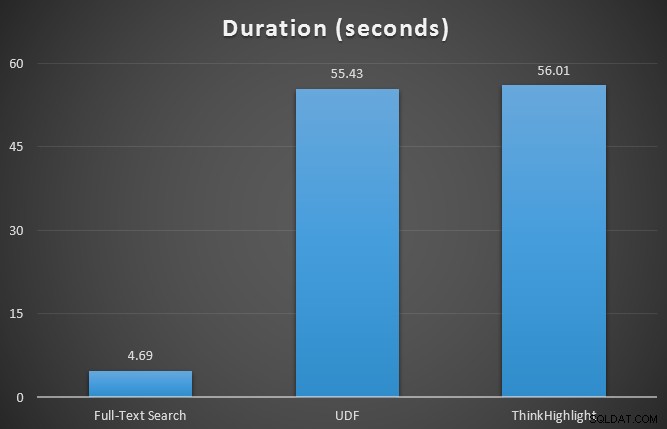
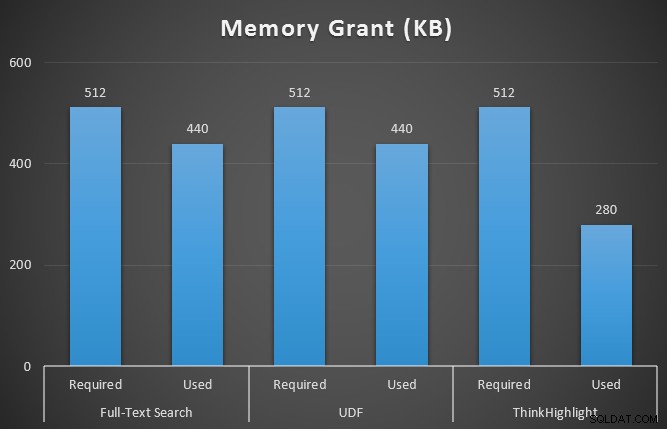
Докато и двете опции за открояване на удари носят значително наказание за това, че изобщо не се открояват, решението ThinkHighlight – с по-гъвкави опции – представлява много незначителни допълнителни разходи по отношение на продължителност (~1%), като същевременно използва значително по-малко памет (36%) отколкото варианта на UDF.
Заключение
Не трябва да е изненада, че открояването на хитове е скъпа операция и въз основа на сложността на това, което трябва да се поддържа (мислете, че има много езици), съществуват много малко решения. Мисля, че Майк Крамар е свършил отлична работа, създавайки базова UDF, която ви дава добър начин за решаване на проблема, но бях приятно изненадан да открия по-стабилно търговско предложение – и открих, че е много стабилно, дори в бета форма. Планирам да извърша по-задълбочени тестове, използвайки по-широк набор от размери и типове документи. Междувременно, ако маркирането на удари е част от изискванията на приложението ви, трябва да изпробвате UDF на Майк Крамар и да помислите да вземете ThinkHighlight за тест драйв.