Наличността, достъпността и производителността на данните са жизненоважни за успеха на бизнеса. Настройката на производителността и оптимизацията на SQL заявки са трудни, но необходими практики за професионалистите по бази данни. Те изискват разглеждане на различни колекции от данни с помощта на разширени събития, perfmon, планове за изпълнение, статистика и индекси за да назовем само няколко. Понякога собствениците на приложения искат да увеличат системните ресурси (процесор и памет), за да подобрят производителността на системата. Въпреки това, може да не се нуждаете от тези допълнителни ресурси и те могат да имат разходи, свързани с тях. Понякога всичко, което се изисква, е да направите малки подобрения, за да промените поведението на заявката.
В тази статия ще обсъдим няколко най-добри практики за оптимизиране на SQL заявки, които да приложите при писане на SQL заявки.
SELECT * срещу SELECT списък с колони
Обикновено разработчиците използват оператора SELECT *, за да четат данни от таблица. Той чете всички налични данни на колоната в таблицата. Да предположим, че таблица [AdventureWorks2019].[HumanResources].[Employee] съхранява данни за 290 служители и имате изискване да извлечете следната информация:
- Национален идентификационен номер на служител
- DOB
- Пол
- Дата на наемане
Неефективна заявка: Ако използвате оператора SELECT *, той връща всички данни на колоната за всички 290 служители.
Изберете * от [AdventureWorks2019].[Човешки ресурси].[Служител]
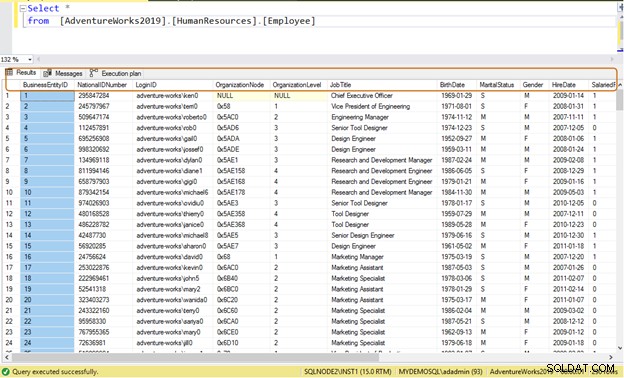
Вместо това използвайте конкретни имена на колони за извличане на данни.
ИЗБЕРЕТЕ [NationalIDNumber],[JobTitle],[BirthDate],[Gender],[HireDate]ОТ [AdventureWorks2019].[HumanResources].[Служител]
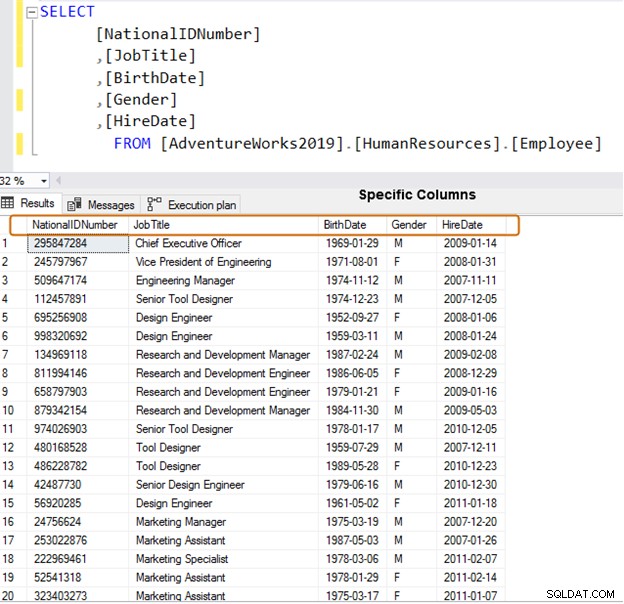
В плана за изпълнение по-долу отбележете разликата в приблизителния размер на редовете за същия брой редове. Ще забележите разлика в CPU и IO и за голям брой редове.
Използване на COUNT() спрямо EXISTS
Да предположим, че искате да проверите дали в SQL таблицата съществува конкретен запис. Обикновено използваме COUNT (*), за да проверим записа и той връща броя на записите в изхода.
Въпреки това можем да използваме функцията IF EXISTS() за тази цел. За сравнение активирах статистиката, преди да изпълня заявките.
Заявката за COUNT()
ЗАДАВАНЕ НА СТАТИСТИКАТА IO ONИзберете брой(*) от [AdventureWorks2019].[Sales].[SalesOrderDetail]където [SalesOrderDetailID]=44824ЗАДАВАНЕ НА STATISTICS IO OFF
Заявката за IF EXISTS()
ЗАДАВАНЕ НА СТАТИСТИКАТА IO ONIF СЪЩЕСТВУВА(Изберете [CarrierTrackingNumber] от [AdventureWorks2019].[Sales].[SalesOrderDetail]където [SalesOrderDetailID]=44824)ПЕЧАТ 'YES'ELSEPRINT 'NO'OFF STATISTICS>
Използвах statisticsparser за анализ на статистическите резултати и на двете заявки. Вижте резултатите по-долу. Заявката с COUNT(*) има 276 логически четения, докато IF EXISTS() има 83 логически четения. Можете дори да получите по-значително намаляване на логическите четения с IF EXISTS(). Следователно, трябва да го използвате, за да оптимизирате SQL заявките за по-добра производителност.

Избягвайте използването на SQL DISTINCT
Винаги, когато искаме уникални записи от заявката, ние обикновено използваме клаузата SQL DISTINCT. Да предположим, че сте съединили две таблици заедно и в изхода тя връща дублираните редове. Бързо решение е да посочите оператора DISTINCT, който потиска дублирания ред.
Нека разгледаме простите оператори SELECT и да сравним плановете за изпълнение. Единствената разлика между двете заявки е оператор DISTINCT.
ИЗБЕРЕТЕ SalesOrderID ОТ Sales.SalesOrderDetailGoSELECT DISTINCT SalesOrderID ОТ Sales.SalesOrderDetailGo
С оператора DISTINCT цената на заявката е 77%, докато по-ранната заявка (без DISTINCT) има само 23% пакетна цена.
Можете да използвате GROUP BY, CTE или подзаявка за писане на ефективен SQL код, вместо да използвате DISTINCT за получаване на различни стойности от набора от резултати. Освен това можете да извлечете допълнителни колони за отделен набор от резултати.
ИЗБЕРЕТЕ SalesOrderID ОТ Sales.SalesOrderDetail група по SalesOrderID
Използване на заместващи знаци в SQL заявката
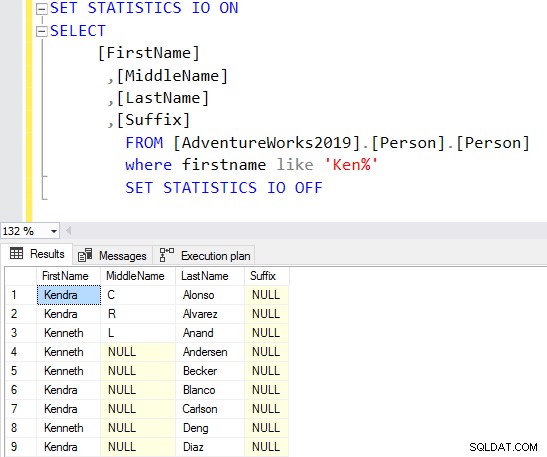
Да предположим, че искате да търсите конкретни записи, съдържащи имена, започващи с посочения низ. Разработчиците използват заместител за търсене на съвпадащите записи.
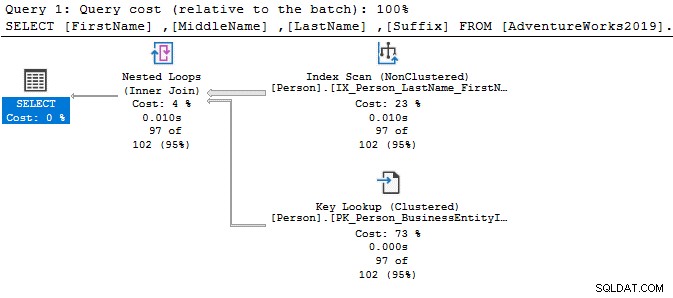
В заявката по-долу той търси низа Ken в колоната за първо име. Тази заявка извлича очакваните резултати от Ken дра и Кен нето Но също така предоставя и неочаквани резултати, например Macken зие и Нкени ge.
В плана за изпълнение виждате сканирането на индекса и ключовото търсене за горната заявка.
Можете да избегнете неочаквания резултат, като използвате заместващия знак в края на низа.
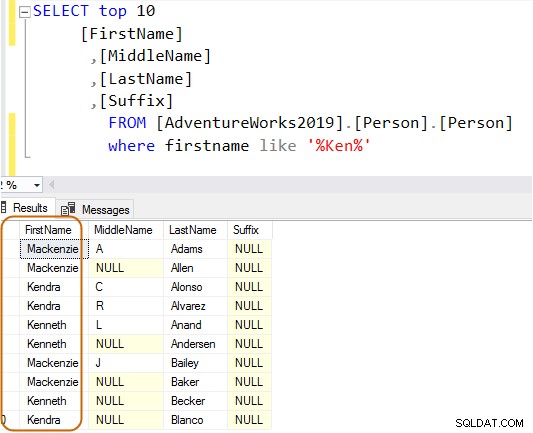
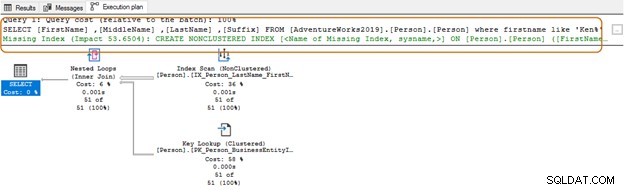
ИЗБЕРЕТЕ Топ 10[FirstName],[MiddleName],[LastName],[Suffix]ОТ [AdventureWorks2019].[Person].[Person]Където собствено име като „Ken%“
Сега получавате филтриран резултат въз основа на вашите изисквания.
При използването на заместващия знак в началото, оптимизаторът на заявки може да не е в състояние да използва подходящия индекс. Както е показано на екранната снимка по-долу, със завършващ див знак, оптимизаторът на заявки предлага и липсващ индекс.
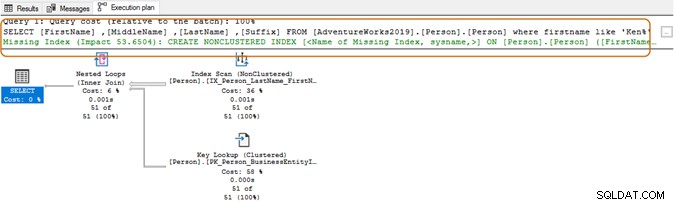
Тук ще искате да оцените изискванията за кандидатстване. Трябва да се опитате да избегнете използването на заместващ знак в низовете за търсене, тъй като това може да принуди оптимизатора на заявки да използва сканиране на таблица. Ако таблицата е огромна, тя ще изисква по-високи системни ресурси за IO, CPU и памет и може да причини проблеми с производителността на вашата SQL заявка.
Използване на клаузите WHERE и HAVING
Клаузите WHERE и HAVING се използват като филтри за редове с данни. Клаузата WHERE филтрира данните преди да приложи логиката на групиране, докато клаузата HAVING филтрира редове след обобщените изчисления.
Например в заявката по-долу използваме филтър за данни в клаузата HAVING без клауза WHERE.
Изберете SalesOrderID,SUM(UnitPrice* OrderQty) като OrderTotalFrom Sales.salesOrderDetailGROUP BY SalesOrderIDHAVING SalesOrderID>30000 и SalesOrderID<55555 и SUM(UnitPrice* OrderQty)>1 Go
Следната заявка филтрира данните първо в клаузата WHERE и след това използва клаузата HAVING за филтъра за обобщени данни.
Изберете SalesOrderID,SUM(UnitPrice* OrderQty) като OrderTotalFrom Sales.salesOrderDetailwhere SalesOrderID>30000 и SalesOrderID<55555GROUP BY SalesOrderIDHAVING SUM(UnitPrice* OrderQty)>1000Препоръчвам да използвате клаузата WHERE за филтриране на данни и клаузата HAVING за вашия филтър за обобщени данни като най-добра практика.
Използване на клаузите IN и EXISTS
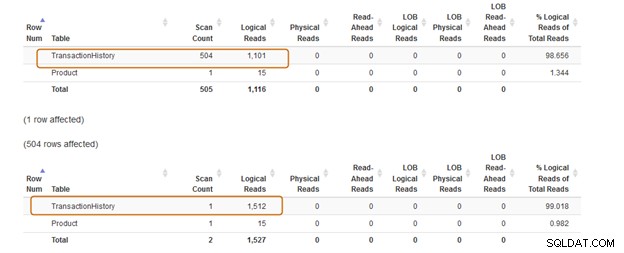
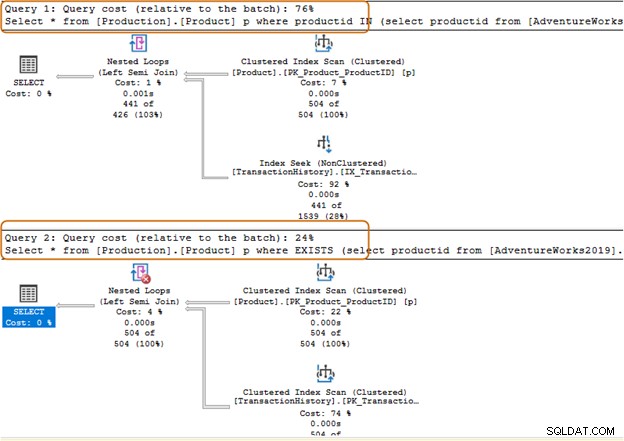
Трябва да избягвате използването на клаузата IN-оператор за вашите SQL заявки. Например, в заявката по-долу, първо намерихме идентификатора на продукта от таблицата [Production].[TransactionHistory]) и след това потърсихме съответните записи в таблицата [Production].[Product].
Изберете * от [Production].[Product] p, където productid IN (изберете productid от [AdventureWorks2019].[Production].[TransactionHistory]);GoВ заявката по-долу заменихме клаузата IN с клауза EXISTS.
Изберете * от [Production].[Product] p, където СЪЩЕСТВУВА (изберете productid от [AdventureWorks2019].[Production].[TransactionHistory])Сега нека сравним статистическите данни след изпълнение на двете заявки.
Клаузата IN използва 504 сканирания, докато клаузата EXISTS използва 1 сканиране за таблицата [Production].[TransactionHistory]).
Пакетът за заявка за клауза IN струва 74%, докато цената на клаузата EXISTS е 24%. Следователно трябва да избягвате клаузата IN, особено ако подзаявката връща голям набор от данни.
Липсващи индекси
Понякога, когато изпълняваме SQL заявка и търсим действителния план за изпълнение в SSMS, получавате предложение за индекс, който може да подобри SQL заявката ви.
Като алтернатива можете да използвате изгледите за динамично управление, за да проверите подробностите за липсващи индекси във вашата среда.
- sys.dm_db_missing_index_details
- sys.dm_db_missing_index_group_stats
- sys.dm_db_missing_index_groups
- sys.dm_db_missing_index_columns
Обикновено DBA следват съветите от SSMS и създават индексите. Това може да подобри производителността на заявката за момента. Въпреки това, не трябва да създавате индекса директно въз основа на тези препоръки. Това може да повлияе на изпълнението на други заявки и да забави вашите оператори INSERT и UPDATE.
- Първо прегледайте съществуващите индекси за вашата SQL таблица.
- Забележка, и свръх-индексирането, и недостатъчното индексиране са лоши за ефективността на заявката.
- Приложете препоръките за липсващи индекси с най-голямо въздействие, след като прегледате съществуващите си индекси и ги внедрете в по-ниската среда. Ако работното ви натоварване работи добре след внедряване на новия липсващ индекс, струва си да добавите ит.
Предлагам ви да разгледате тази статия за подробни най-добри практики за индексиране: 11 най-добри практики за индексиране на SQL Server за подобрена настройка на производителността.
Съвети за заявка
Разработчиците посочват изрично намеците на заявката в своите t-SQL оператори. Тези подсказки за заявка отменят поведението на оптимизатора на заявки и го принуждават да изготви план за изпълнение въз основа на вашия намек за заявка. Често използвани съвети за заявка са NOLOCK, Optimize For и Recompile Merge/Hash/Loop. Те са краткосрочни поправки за вашите заявки. Въпреки това, трябва да работите върху анализирането на вашата заявка, индекси, статистика и план за изпълнение за постоянно решение.
Съгласно най-добрите практики, трябва да сведете до минимум използването на всякакъв намек за заявка. Искате да използвате подсказките за заявката в SQL заявката, след като първо разберете последиците от нея, и не я използвайте ненужно.
Напомняния за оптимизиране на SQL заявки
Както обсъдихме, оптимизацията на SQL заявки е отворен път. Можете да приложите най-добри практики и малки поправки, които могат значително да подобрят производителността. Обмислете следните съвети за по-добро разработване на заявки:
- Винаги преглеждайте разпределенията на системните ресурси (дискове, процесор, памет)
- Прегледайте вашите флагове за проследяване при стартиране, индекси и задачи за поддръжка на база данни
- Анализирайте работното си натоварване с помощта на разширени събития, инструменти за профилиране или инструменти за наблюдение на бази данни на трети страни
- Винаги внедрявайте всяко решение (дори ако сте 100% уверени) първо в тестовата среда и анализирайте въздействието му; след като сте доволни, планирайте внедряването на продукцията