Когато разработвате приложение или пишете код в системата на SQL база данни, е от решаващо значение да разберете как данните ще бъдат сортирани и сравнени. Можете да съхранявате данните си на конкретен език или може да искате SQL Server да третира отделно данни, чувствителни към малки и големи букви. Microsoft предостави настройка на SQL Server, наречена Сравняване да контролира и отговаря на такива изисквания.
Какво е Collation в SQL Server?
Можем да настроим съпоставянето на различни нива в SQL Server, както е посочено по-долу.
- Ниво на сървъра
- Ниво на база данни
- Ниво на колона
- Ниво на експресия
Съпоставянето на ниво сървър понякога може да се нарече Съпоставяне на ниво екземпляр на SQL сървър .
Съпоставянето на ниво база данни ще бъде наследено от настройката за съпоставяне на ниво сървър, ако не изберете никакво конкретно съпоставяне по време на създаването на база данни. Можете също да промените съпоставянето на ниво база данни по-късно. Имайте предвид, че промяната на съпоставянето на базата данни ще се прилага само за предстоящи или нови обекти, които ще бъдат създадени след промяната на съпоставянето.
Новото съпоставяне няма да промени съществуващите данни, съхранявани в таблици, които са били сортирани с последния тип съпоставяне. Екипът на приложението се нуждае от допълнително планиране, за да се справи с това преобразуване на съхранени данни поради новата настройка за съпоставяне.
Има няколко начина да го направите. Единият е да копирате данните от съществуващата таблица в нова таблица, създадена с новото съпоставяне и след това да замените старата таблица с новата. Можете също да преместите данните си от таблицата в нова база данни, като имате ново съпоставяне и замените старата база данни с новата.
ЗАБЕЛЕЖКА :Промяната на съпоставянето е сложна задача и трябва да я избягвате, освен ако нямате задължителен бизнес случай.
Как да намеря и промени съпоставянето на база данни в SQL Server?
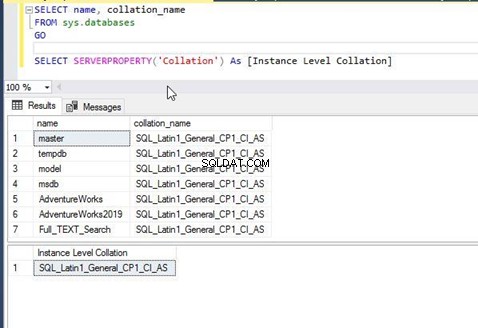
Нека да продължим и да проверим съпоставянето на екземпляр на SQL Server и всички бази данни, хоствани на този екземпляр. Можете да проверите съпоставянето чрез достъп до свойства на ниво база данни или екземпляр прозорец с помощта на SQL Server Management Studio или просто като изпълните по-долу T-SQL оператор. Съпоставянето за всяка база данни се съхранява в системния обект sys.databases – ще получим достъп до него, за да получим тази информация.
--Check Database Collation
SELECT name, collation_name
FROM sys.databases
GO
--Check Server or Instance level Collation
SELECT SERVERPROPERTY('Collation') As [Instance Level Collation]
Изпълних горния израз на T-SQL и получих изхода по-долу. Можем да видим, че всички бази данни и съпоставяне на ниво сървър имат същите настройки като SQL_Latin1_General_CP1_CI_AS . Това означава, че съпоставянето на базата данни е било наследено от съпоставянето на ниво сървър при създаването им и стойността по подразбиране не е променена.
Сега нека ви покажа как да проверите съпоставянето на базата данни с помощта на GUI в SQL Server Management Studio.
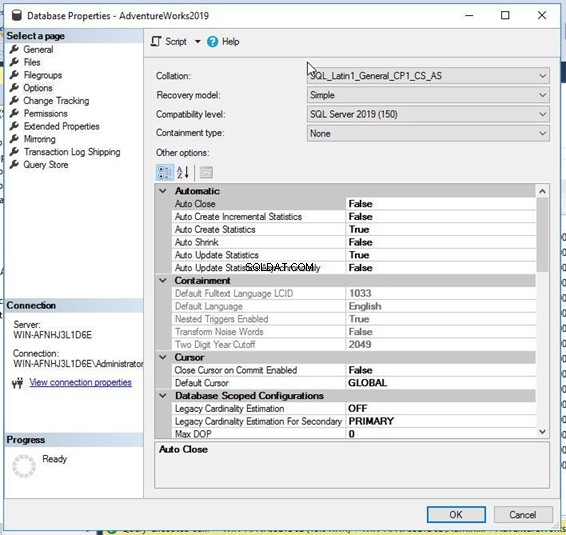
Първо, свържете се с вашия екземпляр на SQL Server, като използвате SQL Server Management Studio. Разгънете възела на екземпляра, последван от Бази данни папка. Щракнете с десния бутон върху целевата база данни и изберете Свойства :
Ще получите следните Свойства на базата данни прозорец.
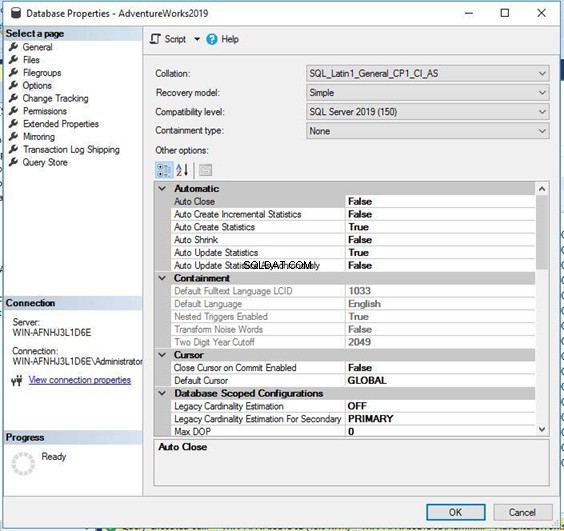
Сега щракнете върху Опции раздел от левия панел. Ще получите множество настройки за свойства в десния панел. Колекция е първото свойство на тази страница – можете да видите, че е същото като в горния T-SQL скрипт.
По същия начин можете да щракнете върху възела на екземпляра на SQL Server и да щракнете с десния бутон върху свойствата на ниво екземпляр за да видите съпоставянето на ниво сървър.
Ако искате да промените това съпоставяне с ново съпоставяне, просто трябва да щракнете върху Колекция падащо меню и изберете опцията, от която се нуждаете. Уверете се, че сте направили пълно архивиране на вашата база данни, преди да го направите.
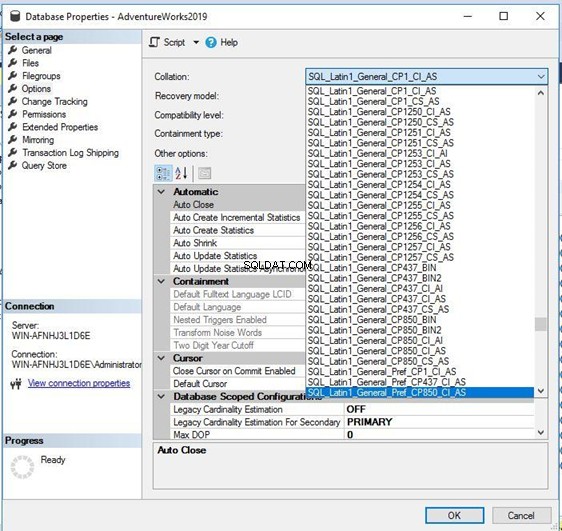
Избрах подобно съпоставяне с чувствителни към малки букви SQL_Latin1_General_CP1_CS _AS за тази база данни и щракнете върху OK да го приложим. Забележка:Уверете се, че никой не е свързан към целевата база данни по време на тази процедура, в противен случай ще трябва да превключите режима в един потребител и променете тази конфигурация.
Можете също да промените това съпоставяне на базата данни, като използвате израза T-SQL. За това използвайте СЪБОРЯВАНЕ клауза на израза ALTER DATABASE.
Първо, превключихме базата данни в еднопотребителска режим, след това промени съпоставянето и накрая премести базата данни в многопотребителски режим.
--Change Database Collation using T-SQL
USE master;
GO
Alter DATABASE [AdventureWorks2019] SET SINGLE_USER WITH ROLLBACK IMMEDIATE
GO
ALTER DATABASE [AdventureWorks2019]
COLLATE SQL_Latin1_General_CP1_CI_AS;
GO
Alter DATABASE [AdventureWorks2019] SET MULTI_USER
Избройте всички поддържани съпоставяния в SQL Server
Този раздел ще ви покаже как да намерите всички налични съпоставяния в SQL Server. Първо, нека ви покажа как да получите списъка с всички поддържани съпоставяния за екземпляра на SQL Server.
SQL Server има системна функция, наречена fn_helpcollations() които можете да използвате за извличане на всички съпоставяния.
Изпълнете командата по-долу, за да покажете списъка.
--Display the list of all collations
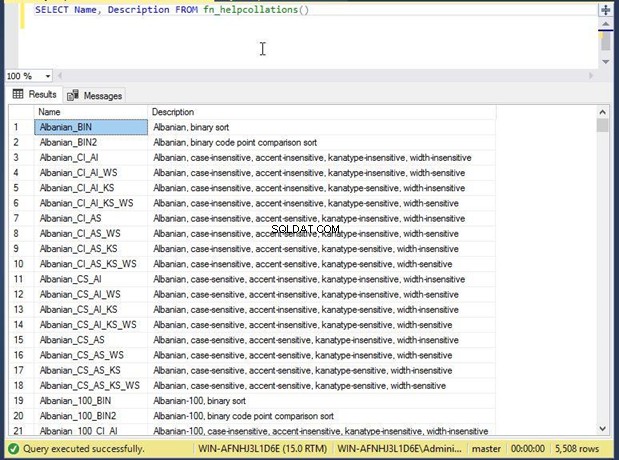
SELECT name, description FROM fn_helpcollations()
Можем да видим всички 5508 поддържани съпоставяния в секцията за изход. Ако не сте сигурни кое съпоставяне да изберете, можете да използвате клаузата WHERE в скрипта по-долу, за да филтрирате всички възможни съпоставяния, които могат да бъдат зададени в базата данни.
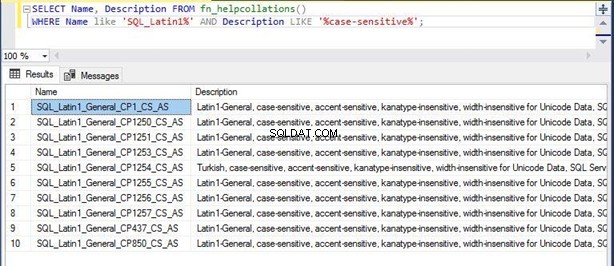
Да кажем, че трябва да съхранявате данните си на американски английски език и искате SQL Server да ги обработва във формат, чувствителен към малки и големи букви. Можете да използвате командата по-долу, за да извлечете списъка с възможни и поддържани съпоставяния за вашата заявка:
--Display the list of all collations with WHERE clause
SELECT Name, Description FROM fn_helpcollations()
WHERE Name like 'SQL_Latin1%' AND Description LIKE '%case-sensitive%’
Резултатът показва само 10 сортировки, удовлетворяващи вашата заявка. Можете да използвате горния скрипт, за да филтрирате различни сортировки.
Влияние на промяната на съпоставянето на базата данни върху изхода на заявката
В този раздел ще ви покажа разликата между двата изхода на една и съща заявка, когато се изпълняват с различни съпоставяния.
Първо, ще създам база данни с име MSSQL със съпоставяне (SQL_Latin1_General_CP1_CS _AS ). След това ще изпълня една и съща заявка два пъти, за да получа изхода. По-късно ще променя съпоставянето на SQL_Latin1_General_CP1_CI _AS и отново стартирайте същите заявки, за да получите техния резултат. Можете да сравните и двата изхода и да разберете въздействието на промяната на съпоставяне на база данни. И така, нека започнем със създаването на база данни.
Стартирайте прозореца за създаване на нова база данни, както е показано на изображението по-долу. Можете също да създадете тази база данни с помощта на T-SQL. След това можете да видите името на базата данни и нейните файлове с данни. Сега щракнете върху втория раздел в панела отляво, за да превключите към прозореца със свойства за съпоставяне.
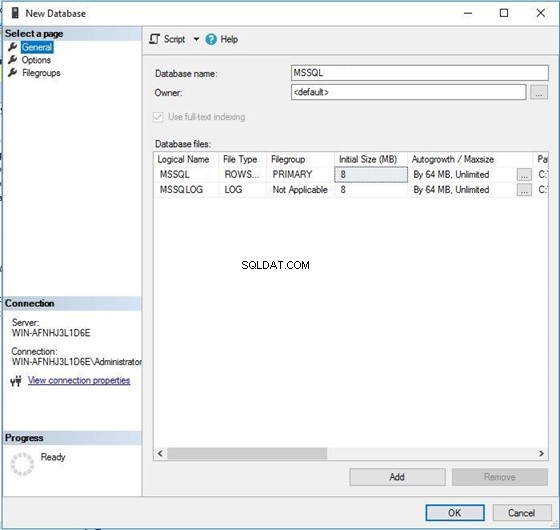
Можете да видите, че името на съпоставянето за тази база данни е по подразбиране . Това означава, че тази база данни ще наследи съпоставяне от типа на съпоставяне на ниво сървър. Щракнете върху Колекция падащо меню, за да изберете новото си съпоставяне.
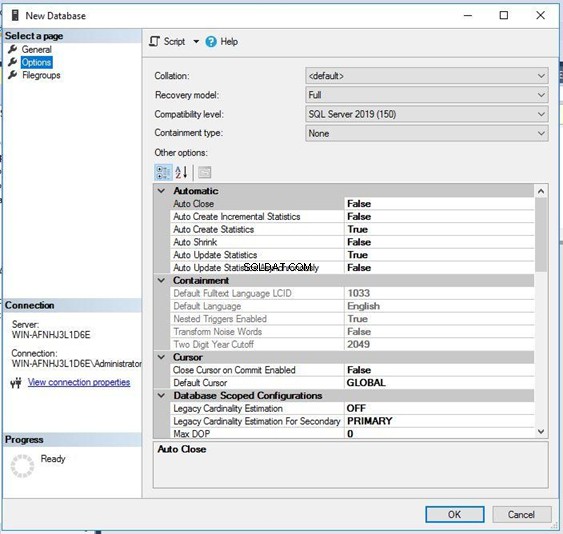
Избрах по-долу съпоставяне SQL_Latin1_General_CP1_CS _AS за тази база данни – не по подразбиране. Щракнете върху OK за да продължите със създаването на база данни.
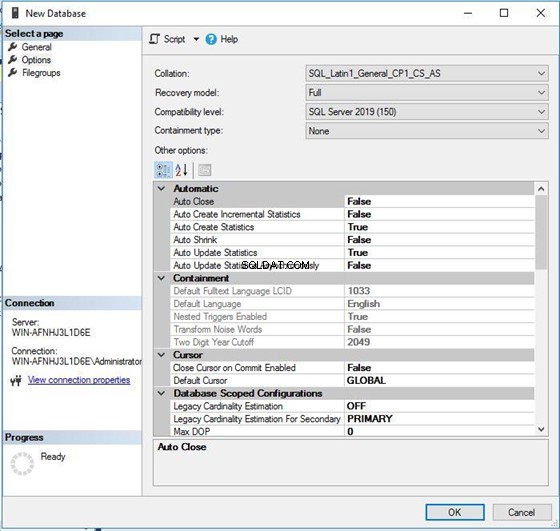
Сега проверете съпоставянето на базата данни за новосъздадена база данни. Виждаме, че е SQL_Latin1_General_CP1_CS _AS както избрахме в предишната стъпка.
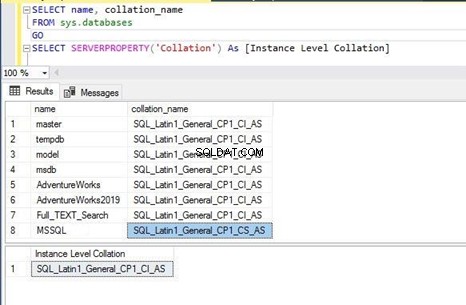
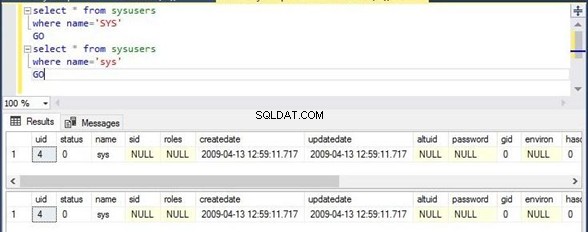
В SQL_Latin1_General_CP1_CS _AS , CS съкращение от регистри и малки букви режим и CI означава нечувствителни на главни букви режим. Сега можете да стартирате или долния T-SQL код, или който и да е код, за да получите изхода.
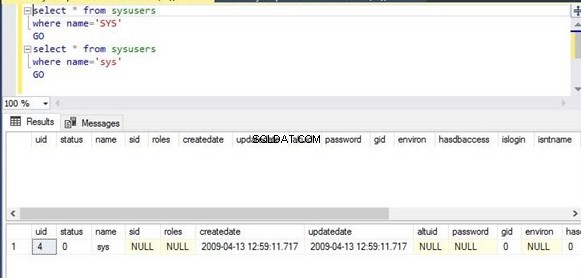
Изпълних една и съща команда два пъти. Първият скрипт филтрира имената на колоните със стойност SYS в столица букви, докато вторият скрипт ще филтрира същата колона със същата стойност sys в малък писма. Разделът за изход показва, че първият скрипт не е показал никакъв изход, докато вторият скрипт е показал изхода поради поведението му, което е чувствително към малки и големи букви.
Select * from sysusers
Where name=’SYS’
Go
Select * from sysusers
Where name=’sys’
GO
Сега ще променим съпоставянето на тази база данни на съпоставянето без значение на малки и големи букви SQL_Latin1_General_CP1_CI _AS чрез изпълнение на посочените по-долу T-SQL оператори. Можете също да го промените чрез GUI, като отворите прозореца Свойства на базата данни в SQL Server Management Studio.
--Change database collation to SQL_Latin1_General_CP1_CI_AS
USE master;
GO
Alter DATABASE [MSSQL] SET SINGLE_USER WITH ROLLBACK IMMEDIATE
GO
ALTER DATABASE [MSSQL]
COLLATE SQL_Latin1_General_CP1_CI_AS;
GO
Alter DATABASE [MSSQL] SET MULTI_USER
Изпълних горния скрипт наведнъж и съпоставянето на базата данни беше успешно променено на ново съпоставяне с поддръжка, независимо от главните букви.
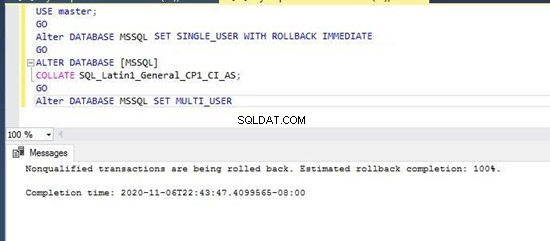
Можете да проверите тази промяна, като изпълните скриптовете по-долу, за да проверите сортирането на новосъздадената база данни MSSQL. Можем да видим, че новото съпоставяне е зададено за тази база данни на изображението по-долу.
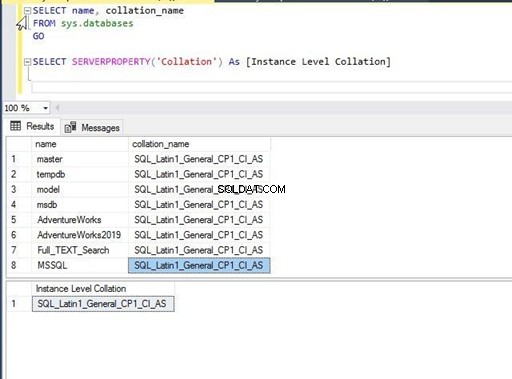
Ще изпълним отново същия израз на T-SQL, преди да променим съпоставянето, за да видим ефекта от тази промяна. Както виждаме сега, и двата T-SQL оператора са в изхода.
Заключение
Надявам се, че е очевидно, че съпоставянето в SQL Server е от решаващо значение. Дефинирахме какво въздействие оставя, ако правите промени в съпоставянето на всяко ниво в SQL Server. Винаги правете правилно планиране и първо тествайте модификациите във вашата среда с по-нисък жизнен цикъл.
Очаквайте следващата ми статия, където ще ви покажа метод стъпка по стъпка за промяна на съпоставянето на ниво сървър.
Моля, споделете тази статия и дайте отзивите си, тя ни помага да се подобрим.



