В тази статия продължавам отразяването на решенията на Питър Ларсон за примамливото предизвикателство за търсене и предлагане. Благодаря отново на Лука, Камил Косно, Даниел Браун, Брайън Уокър, Джо Обиш, Райнер Хофман, Пол Уайт, Чарли и Питър Ларсън за изпращането на вашите решения.
Миналия месец покрих решение, базирано на интервални пресичания, използвайки класически предикатен тест за интервално пресичане. Ще наричам това решение класически кръстовища . Класическият подход за пресичане на интервали води до план с квадратично мащабиране (N^2). Демонстрирах слабото му представяне спрямо входни проби, вариращи от 100K до 400K редове. Завършването на решението отне 931 секунди срещу 400K-редов вход! Този месец ще започна, като ви напомня накратко за решението от миналия месец и защо то се мащабира и работи толкова зле. След това ще представя подход, базиран на ревизия на теста за пресичане на интервали. Този подход беше използван от Лука, Камил и вероятно също Даниел и дава възможност за решение с много по-добра производителност и мащабиране. Ще наричам това решение ревизирани кръстовища .
Проблемът с класическия тест за пресичане
Нека започнем с кратко напомняне за решението от миналия месец.
Използвах следните индекси на входната таблица dbo.Auctions, за да поддържам изчисляването на текущите суми, които произвеждат интервали на търсене и предлагане:
-- Index to support solution CREATE UNIQUE NONCLUSTERED INDEX idx_Code_ID_i_Quantity ON dbo.Auctions(Code, ID) INCLUDE(Quantity); -- Enable batch-mode Window Aggregate CREATE NONCLUSTERED COLUMNSTORE INDEX idx_cs ON dbo.Auctions(ID) WHERE ID = -1 AND ID = -2;
Следният код има цялостно решение, внедряващо класическия подход за пресичане на интервали:
-- Drop temp tables if exist
SET NOCOUNT ON;
DROP TABLE IF EXISTS #MyPairings, #Demand, #Supply;
GO
WITH D0 AS
-- D0 computes running demand as EndDemand
(
SELECT ID, Quantity,
SUM(Quantity) OVER(ORDER BY ID ROWS UNBOUNDED PRECEDING) AS EndDemand
FROM dbo.Auctions
WHERE Code = 'D'
),
-- D extracts prev EndDemand as StartDemand, expressing start-end demand as an interval
D AS
(
SELECT ID, Quantity, EndDemand - Quantity AS StartDemand, EndDemand
FROM D0
)
SELECT ID,
CAST(ISNULL(StartDemand, 0.0) AS DECIMAL(19, 6)) AS StartDemand,
CAST(ISNULL(EndDemand, 0.0) AS DECIMAL(19, 6)) AS EndDemand
INTO #Demand
FROM D;
WITH S0 AS
-- S0 computes running supply as EndSupply
(
SELECT ID, Quantity,
SUM(Quantity) OVER(ORDER BY ID ROWS UNBOUNDED PRECEDING) AS EndSupply
FROM dbo.Auctions
WHERE Code = 'S'
),
-- S extracts prev EndSupply as StartSupply, expressing start-end supply as an interval
S AS
(
SELECT ID, Quantity, EndSupply - Quantity AS StartSupply, EndSupply
FROM S0
)
SELECT ID,
CAST(ISNULL(StartSupply, 0.0) AS DECIMAL(19, 6)) AS StartSupply,
CAST(ISNULL(EndSupply, 0.0) AS DECIMAL(19, 6)) AS EndSupply
INTO #Supply
FROM S;
CREATE UNIQUE CLUSTERED INDEX idx_cl_ES_ID ON #Supply(EndSupply, ID);
-- Trades are the overlapping segments of the intersecting intervals
SELECT
D.ID AS DemandID, S.ID AS SupplyID,
CASE WHEN EndDemand < EndSupply THEN EndDemand ELSE EndSupply END - CASE WHEN StartDemand > StartSupply THEN StartDemand ELSE StartSupply END
AS TradeQuantity
INTO #MyPairings
FROM #Demand AS D
INNER JOIN #Supply AS S WITH (FORCESEEK)
ON D.StartDemand < S.EndSupply AND D.EndDemand > S.StartSupply; Този код започва с изчисляване на интервалите между търсенето и предлагането и записването им във временни таблици, наречени #Demand и #Supply. След това кодът създава клъстериран индекс на #Supply с EndSupply като водещ ключ, за да поддържа възможно най-добрия тест за пресичане. И накрая, кодът обединява #Supply и #Demand, идентифицирайки сделките като припокриващи се сегменти на пресичащите се интервали, използвайки следния предикат за свързване въз основа на класическия тест за пресичане на интервали:
D.StartDemand < S.EndSupply AND D.EndDemand > S.StartSupply
Планът за това решение е показан на Фигура 1.
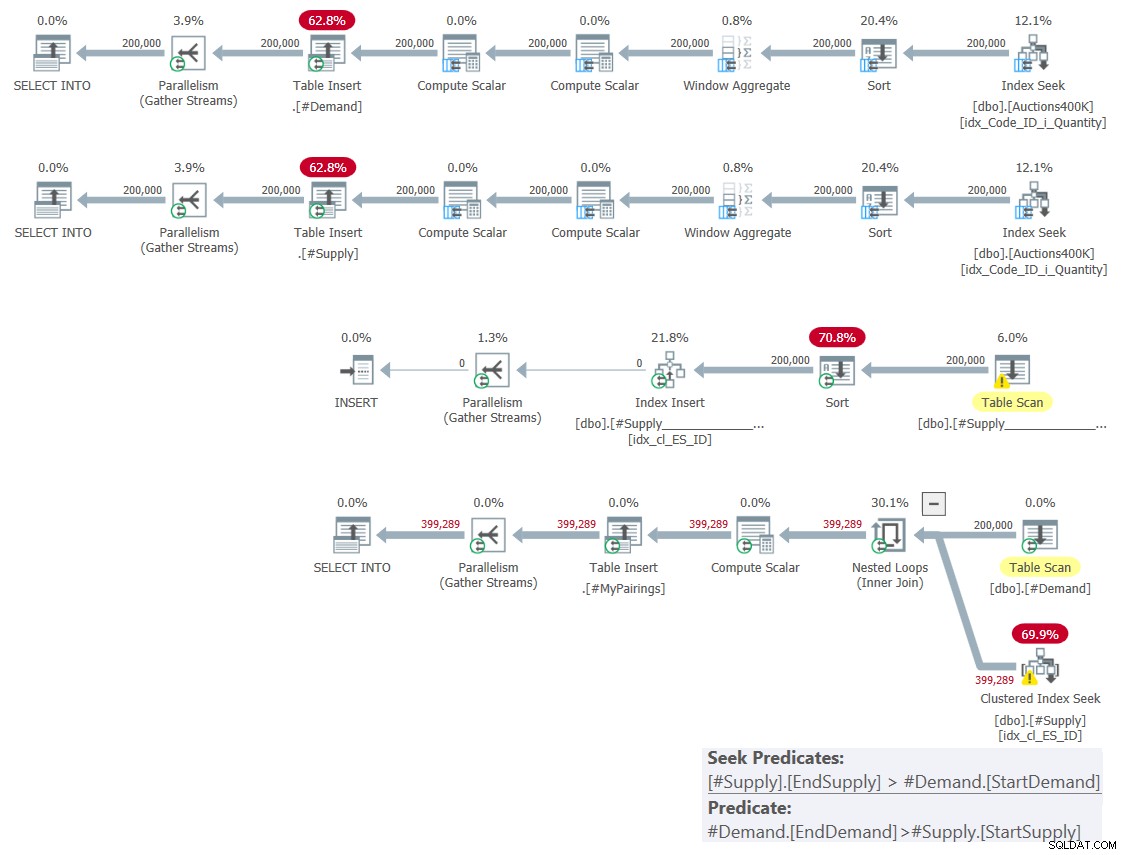 Фигура 1:План на заявка за решение въз основа на класически пресечки
Фигура 1:План на заявка за решение въз основа на класически пресечки
Както обясних миналия месец, сред двата включени предиката за диапазон, само единият може да се използва като предикат за търсене като част от операция за търсене на индекс, докато другият трябва да се прилага като остатъчен предикат. Можете ясно да видите това в плана за последната заявка на фигура 1. Ето защо си направих труда да създам само един индекс на една от таблиците. Също така принудих използването на търсене в индекса, който създадох с помощта на подсказката FORCESEEK. В противен случай оптимизаторът може да пренебрегне този индекс и да създаде свой собствен, използвайки оператор Index Spool.
Този план има квадратична сложност, тъй като на ред от едната страна—#Търсене в нашия случай—търсенето на индекса ще трябва да има достъп средно до половината от редовете от другата страна—#Доставка в нашия случай—на базата на предиката за търсене и да идентифицира окончателни съвпадения чрез прилагане на остатъчния предикат.
Ако все още не ви е ясно защо този план има квадратична сложност, може би визуално изобразяване на работата би могло да ви помогне, както е показано на фигура 2.
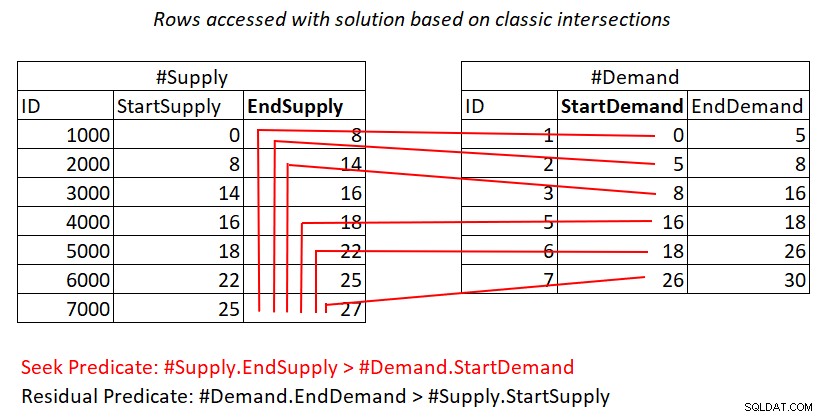 Фигура 2:Илюстрация на работа с решение, базирано на класически пресечки
Фигура 2:Илюстрация на работа с решение, базирано на класически пресечки
Тази илюстрация представя работата, извършена от присъединяването на вложените цикли в плана за последната заявка. Хемът #Demand е външният вход на присъединяването, а клъстерираният индекс на #Supply (с EndSupply като водещ ключ) е вътрешният вход. Червените линии представляват дейностите за търсене на индекс, извършени на ред в #Demand в индекса на #Supply и редовете, до които имат достъп като част от сканирането на диапазона в листа на индекса. Към изключително ниски стойности на StartDemand в #Demand, сканирането на диапазона трябва да има достъп близо до всички редове в #Supply. Към екстремно високи стойности на StartDemand в #Demand, сканирането на диапазона трябва да има достъп до близо до нула редове в #Supply. Средно сканирането на обхвата трябва да има достъп до около половината редове в #Supply на ред в търсенето. При D редове за търсене и S редове за доставка, броят на редовете, до които се осъществява достъп, е D + D*S/2. Това е в допълнение към цената на търсенията, които ви отвеждат до съвпадащите редове. Например, когато попълвате dbo.Auctions с 200 000 реда за търсене и 200 000 реда за доставки, това се превежда като присъединяване на вложени цикли, което осъществява достъп до 200 000 реда за търсене + 200 000*200 000/2 реда за предлагане, или 200,000 реда за предлагане, или 200,200, 200, 200, 200, 200 Тук се случват много повторно сканиране на редове за доставки!
Ако искате да се придържате към идеята за интервални пресечки, но да получите добра производителност, трябва да измислите начин да намалите количеството извършена работа.
В своето решение Джо Оббиш раздели интервалите въз основа на максималната дължина на интервала. По този начин той успя да намали броя на редовете, които трябва да обработят, и да разчита на пакетна обработка. Той използва класическия тест за пресичане на интервали като краен филтър. Решението на Джо работи добре, докато максималната дължина на интервала не е много голяма, но времето за изпълнение на решението се увеличава с увеличаване на максималната дължина на интервала.
И така, какво друго можете да направите...?
Ревизиран тест за пресичане
Лука, Камил и вероятно Даниел (имаше неясна част за публикуваното му решение поради форматирането на уебсайта, така че трябваше да предполагам) използваха преработен тест за пресичане на интервали, който позволява много по-добро използване на индексирането.
Техният тест за пресичане е дизюнкция на два предиката (предикати, разделени от оператор ИЛИ):
(D.StartDemand >= S.StartSupply AND D.StartDemand < S.EndSupply) OR (S.StartSupply >= D.StartDemand AND S.StartSupply < D.EndDemand)
На английски език или началният ограничител на търсенето се пресича с интервала на предлагане по включващ, изключителен начин (включително началото и с изключение на края); или началният ограничител на предлагането се пресича с интервала на търсенето по един включващ, изключителен начин. За да направите двата предиката разделени (без припокриващи се случаи), но все пак пълни за покриване на всички случаи, можете да запазите оператора =само в единия или другия, например:
(D.StartDemand >= S.StartSupply AND D.StartDemand < S.EndSupply) OR (S.StartSupply > D.StartDemand AND S.StartSupply < D.EndDemand)
Този преработен тест за пресичане на интервали е доста проницателен. Всеки от предикатите може потенциално ефективно да използва индекс. Помислете за предикат 1:
D.StartDemand >= S.StartSupply AND D.StartDemand < S.EndSupply ^^^^^^^^^^^^^ ^^^^^^^^^^^^^
Ако приемем, че създавате покриващ индекс на #Demand с StartDemand като водещ ключ, потенциално можете да получите присъединяване на вложени цикли, прилагайки работата, илюстрирана на фигура 3.
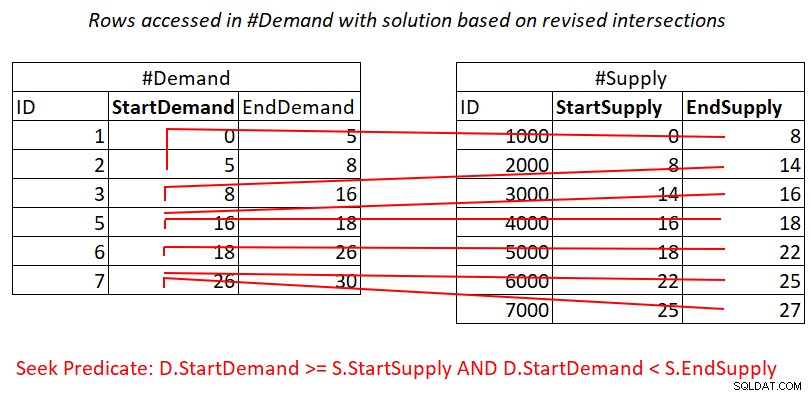
Фигура 3:Илюстрация на теоретичната работа, необходима за обработка на предикат 1
Да, вие все още плащате за търсене в индекса #Demand на ред в #Supply, но диапазонът сканира в достъпа до листовия на индекса почти непреходни подмножества от редове. Без повторно сканиране на редове!
Подобна е ситуацията и с предикат 2:
S.StartSupply > D.StartDemand AND S.StartSupply < D.EndDemand ^^^^^^^^^^^^^ ^^^^^^^^^^^^^
Ако приемем, че създавате покриващ индекс на #Supply със StartSupply като водещ ключ, потенциално можете да получите присъединяване с вложени цикли, прилагайки работата, илюстрирана на фигура 4.
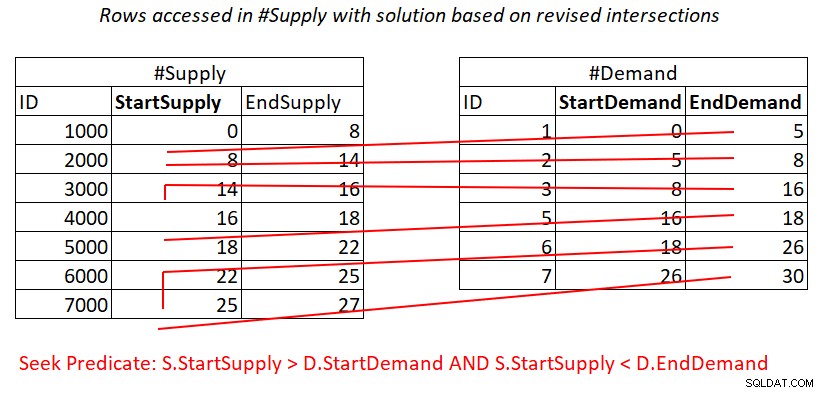
Фигура 4:Илюстрация на теоретичната работа, необходима за обработка на предикат 2
Освен това тук плащате за търсене в индекса #Supply на ред в #Demand, а след това диапазонът сканира в достъпа до листовия на индекса почти несъвместими подмножества от редове. Отново, без повторно сканиране на редове!
Ако приемем D редове за търсене и S редове за доставка, работата може да бъде описана като:
Number of index seek operations: D + S Number of rows accessed: 2D + 2S
Така че вероятно най-голямата част от разходите тук са разходите за I/O, свързани с търсенията. Но тази част от работата има линейно мащабиране в сравнение с квадратичното мащабиране на класическата заявка за пресичане на интервали.
Разбира се, трябва да вземете предвид предварителната цена на създаването на индекса във временните таблици, който има n log n мащабиране поради включеното сортиране, но вие плащате тази част като предварителна част и на двете решения.
Нека се опитаме да приложим тази теория на практика. Нека започнем с попълването на временните таблици #Demand и #supply с интервалите на търсене и предлагане (същите като при класическите интервални пресечки) и създаване на поддържащи индекси:
-- Drop temp tables if exist
SET NOCOUNT ON;
DROP TABLE IF EXISTS #MyPairings, #Demand, #Supply;
GO
WITH D0 AS
-- D0 computes running demand as EndDemand
(
SELECT ID, Quantity,
SUM(Quantity) OVER(ORDER BY ID ROWS UNBOUNDED PRECEDING) AS EndDemand
FROM dbo.Auctions
WHERE Code = 'D'
),
-- D extracts prev EndDemand as StartDemand, expressing start-end demand as an interval
D AS
(
SELECT ID, Quantity, EndDemand - Quantity AS StartDemand, EndDemand
FROM D0
)
SELECT ID,
CAST(ISNULL(StartDemand, 0.0) AS DECIMAL(19, 6)) AS StartDemand,
CAST(ISNULL(EndDemand, 0.0) AS DECIMAL(19, 6)) AS EndDemand
INTO #Demand
FROM D;
WITH S0 AS
-- S0 computes running supply as EndSupply
(
SELECT ID, Quantity,
SUM(Quantity) OVER(ORDER BY ID ROWS UNBOUNDED PRECEDING) AS EndSupply
FROM dbo.Auctions
WHERE Code = 'S'
),
-- S extracts prev EndSupply as StartSupply, expressing start-end supply as an interval
S AS
(
SELECT ID, Quantity, EndSupply - Quantity AS StartSupply, EndSupply
FROM S0
)
SELECT ID,
CAST(ISNULL(StartSupply, 0.0) AS DECIMAL(19, 6)) AS StartSupply,
CAST(ISNULL(EndSupply, 0.0) AS DECIMAL(19, 6)) AS EndSupply
INTO #Supply
FROM S;
-- Indexing
CREATE UNIQUE CLUSTERED INDEX idx_cl_SD_ID ON #Demand(StartDemand, ID);
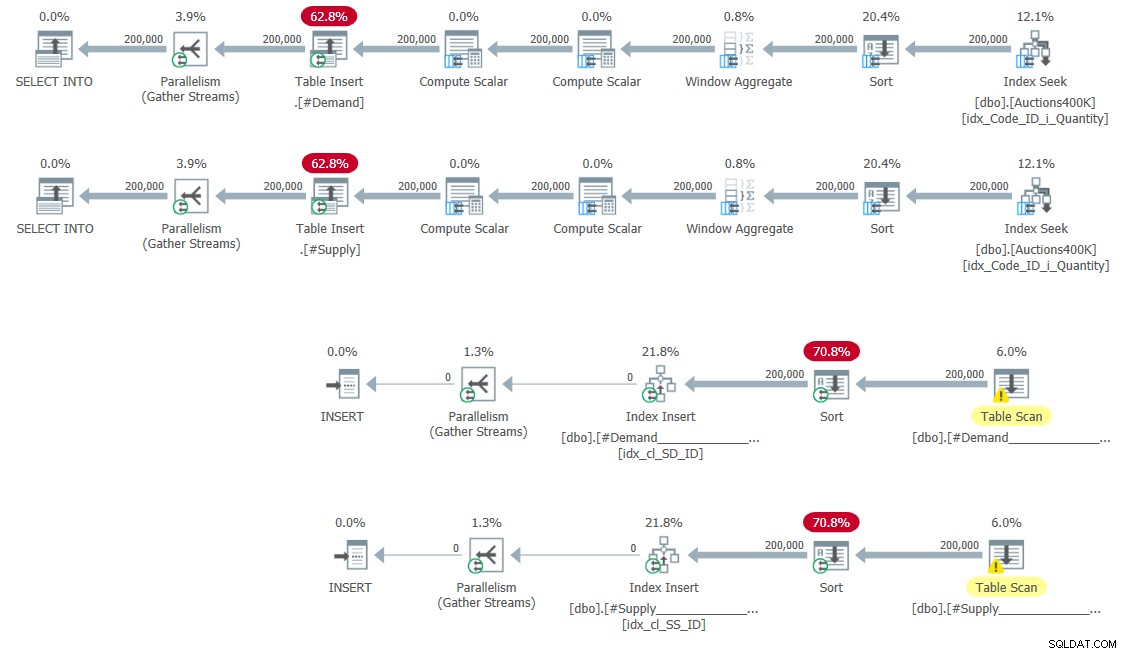
CREATE UNIQUE CLUSTERED INDEX idx_cl_SS_ID ON #Supply(StartSupply, ID); Плановете за попълване на временните таблици и създаване на индекси са показани на фигура 5.
Фигура 5:Планове за заявки за попълване на временни таблици и създаване индекси
Тук няма изненади.
Сега към последната заявка. Може да се изкушите да използвате една заявка с гореспоменатото разделяне на два предиката, като така:
SELECT
D.ID AS DemandID, S.ID AS SupplyID,
CASE WHEN EndDemand < EndSupply THEN EndDemand ELSE EndSupply END - CASE WHEN StartDemand > StartSupply THEN StartDemand ELSE StartSupply END
AS TradeQuantity
INTO #MyPairings
FROM #Demand AS D
INNER JOIN #Supply AS S
ON (D.StartDemand >= S.StartSupply AND D.StartDemand < S.EndSupply) OR (S.StartSupply > D.StartDemand AND S.StartSupply < D.EndDemand); Планът за тази заявка е показан на фигура 6.
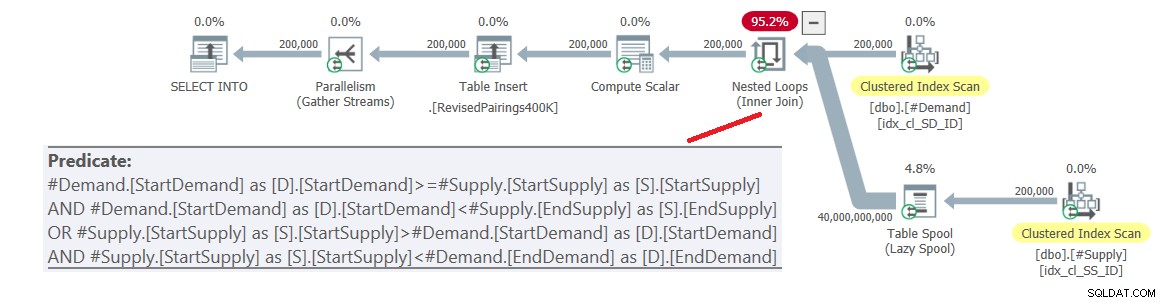
Фигура 6:План на заявка за окончателна заявка с помощта на ревизирано пресичане тест, опитайте 1
Проблемът е, че оптимизаторът не знае как да раздели тази логика на две отделни дейности, всяка от които обработва различен предикат и използва ефективно съответния индекс. Така че завършва с пълно декартово произведение на двете страни, прилагайки всички предикати като остатъчни предикати. С 200 000 реда за търсене и 200 000 реда за доставка, присъединяването обработва 40 000 000 000 реда.
Проницателният трик, използван от Лука, Камил и вероятно Даниел, беше да разбият логиката на две заявки, обединявайки резултатите си. Ето къде използването на два несвързани предиката става важно! Можете да използвате оператор UNION ALL вместо UNION, като избягвате ненужните разходи за търсене на дубликати. Ето заявката, която прилага този подход:
SELECT
D.ID AS DemandID, S.ID AS SupplyID,
CASE WHEN EndDemand < EndSupply THEN EndDemand ELSE EndSupply END - CASE WHEN StartDemand > StartSupply THEN StartDemand ELSE StartSupply END
AS TradeQuantity
INTO #MyPairings
FROM #Demand AS D
INNER JOIN #Supply AS S
ON D.StartDemand >= S.StartSupply AND D.StartDemand < S.EndSupply
UNION ALL
SELECT
D.ID AS DemandID, S.ID AS SupplyID,
CASE WHEN EndDemand < EndSupply THEN EndDemand ELSE EndSupply END - CASE WHEN StartDemand > StartSupply THEN StartDemand ELSE StartSupply END
AS TradeQuantity
FROM #Demand AS D
INNER JOIN #Supply AS S
ON S.StartSupply > D.StartDemand AND S.StartSupply < D.EndDemand; Планът за тази заявка е показан на Фигура 7.
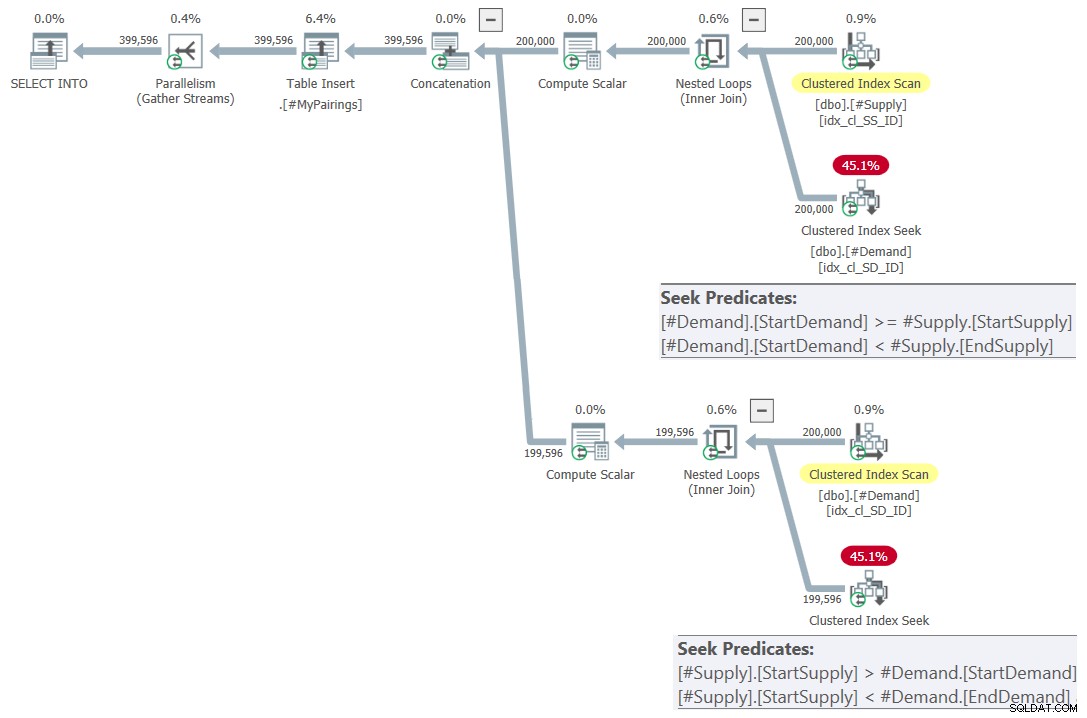
Фигура 7:План на заявка за окончателна заявка с помощта на ревизирано пресичане тест, опитайте 2
Това е просто красиво! не е ли така? И тъй като е толкова красиво, ето цялото решение от нулата, включително създаването на временни таблици, индексиране и окончателната заявка:
-- Drop temp tables if exist
SET NOCOUNT ON;
DROP TABLE IF EXISTS #MyPairings, #Demand, #Supply;
GO
WITH D0 AS
-- D0 computes running demand as EndDemand
(
SELECT ID, Quantity,
SUM(Quantity) OVER(ORDER BY ID ROWS UNBOUNDED PRECEDING) AS EndDemand
FROM dbo.Auctions
WHERE Code = 'D'
),
-- D extracts prev EndDemand as StartDemand, expressing start-end demand as an interval
D AS
(
SELECT ID, Quantity, EndDemand - Quantity AS StartDemand, EndDemand
FROM D0
)
SELECT ID,
CAST(ISNULL(StartDemand, 0.0) AS DECIMAL(19, 6)) AS StartDemand,
CAST(ISNULL(EndDemand, 0.0) AS DECIMAL(19, 6)) AS EndDemand
INTO #Demand
FROM D;
WITH S0 AS
-- S0 computes running supply as EndSupply
(
SELECT ID, Quantity,
SUM(Quantity) OVER(ORDER BY ID ROWS UNBOUNDED PRECEDING) AS EndSupply
FROM dbo.Auctions
WHERE Code = 'S'
),
-- S extracts prev EndSupply as StartSupply, expressing start-end supply as an interval
S AS
(
SELECT ID, Quantity, EndSupply - Quantity AS StartSupply, EndSupply
FROM S0
)
SELECT ID,
CAST(ISNULL(StartSupply, 0.0) AS DECIMAL(19, 6)) AS StartSupply,
CAST(ISNULL(EndSupply, 0.0) AS DECIMAL(19, 6)) AS EndSupply
INTO #Supply
FROM S;
-- Indexing
CREATE UNIQUE CLUSTERED INDEX idx_cl_SD_ID ON #Demand(StartDemand, ID);
CREATE UNIQUE CLUSTERED INDEX idx_cl_SS_ID ON #Supply(StartSupply, ID);
-- Trades are the overlapping segments of the intersecting intervals
SELECT
D.ID AS DemandID, S.ID AS SupplyID,
CASE WHEN EndDemand < EndSupply THEN EndDemand ELSE EndSupply END - CASE WHEN StartDemand > StartSupply THEN StartDemand ELSE StartSupply END
AS TradeQuantity
INTO #MyPairings
FROM #Demand AS D
INNER JOIN #Supply AS S
ON D.StartDemand >= S.StartSupply AND D.StartDemand < S.EndSupply
UNION ALL
SELECT
D.ID AS DemandID, S.ID AS SupplyID,
CASE WHEN EndDemand < EndSupply THEN EndDemand ELSE EndSupply END - CASE WHEN StartDemand > StartSupply THEN StartDemand ELSE StartSupply END
AS TradeQuantity
FROM #Demand AS D
INNER JOIN #Supply AS S
ON S.StartSupply > D.StartDemand AND S.StartSupply < D.EndDemand; Както споменахме по-рано, ще наричам това решение ревизирани кръстовища .
Разтворът на Камил
Между решенията на Лука, Камил и Даниел, Камил беше най-бързият. Ето цялостното решение на Kamil:
SET NOCOUNT ON;
DROP TABLE IF EXISTS #supply, #demand;
GO
CREATE TABLE #demand
(
DemandID INT NOT NULL,
DemandQuantity DECIMAL(19, 6) NOT NULL,
QuantityFromDemand DECIMAL(19, 6) NOT NULL,
QuantityToDemand DECIMAL(19, 6) NOT NULL
);
CREATE TABLE #supply
(
SupplyID INT NOT NULL,
QuantityFromSupply DECIMAL(19, 6) NOT NULL,
QuantityToSupply DECIMAL(19,6) NOT NULL
);
WITH demand AS
(
SELECT
a.ID AS DemandID,
a.Quantity AS DemandQuantity,
SUM(a.Quantity) OVER(ORDER BY ID ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
- a.Quantity AS QuantityFromDemand,
SUM(a.Quantity) OVER(ORDER BY ID ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
AS QuantityToDemand
FROM dbo.Auctions AS a WHERE Code = 'D'
)
INSERT INTO #demand
(
DemandID,
DemandQuantity,
QuantityFromDemand,
QuantityToDemand
)
SELECT
d.DemandID,
d.DemandQuantity,
d.QuantityFromDemand,
d.QuantityToDemand
FROM demand AS d;
WITH supply AS
(
SELECT
a.ID AS SupplyID,
SUM(a.Quantity) OVER(ORDER BY ID ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
- a.Quantity AS QuantityFromSupply,
SUM(a.Quantity) OVER(ORDER BY ID ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
AS QuantityToSupply
FROM dbo.Auctions AS a WHERE Code = 'S'
)
INSERT INTO #supply
(
SupplyID,
QuantityFromSupply,
QuantityToSupply
)
SELECT
s.SupplyID,
s.QuantityFromSupply,
s.QuantityToSupply
FROM supply AS s;
CREATE UNIQUE INDEX ix_1 ON #demand(QuantityFromDemand)
INCLUDE(DemandID, DemandQuantity, QuantityToDemand);
CREATE UNIQUE INDEX ix_1 ON #supply(QuantityFromSupply)
INCLUDE(SupplyID, QuantityToSupply);
CREATE NONCLUSTERED COLUMNSTORE INDEX nci ON #demand(DemandID)
WHERE DemandID is null;
DROP TABLE IF EXISTS #myPairings;
CREATE TABLE #myPairings
(
DemandID INT NOT NULL,
SupplyID INT NOT NULL,
TradeQuantity DECIMAL(19, 6) NOT NULL
);
INSERT INTO #myPairings(DemandID, SupplyID, TradeQuantity)
SELECT
d.DemandID,
s.SupplyID,
d.DemandQuantity
- CASE WHEN d.QuantityFromDemand < s.QuantityFromSupply
THEN s.QuantityFromSupply - d.QuantityFromDemand ELSE 0 end
- CASE WHEN s.QuantityToSupply < d.QuantityToDemand
THEN d.QuantityToDemand - s.QuantityToSupply ELSE 0 END AS TradeQuantity
FROM #demand AS d
INNER JOIN #supply AS s
ON (d.QuantityFromDemand < s.QuantityToSupply
AND s.QuantityFromSupply <= d.QuantityFromDemand)
UNION ALL
SELECT
d.DemandID,
s.SupplyID,
d.DemandQuantity
- CASE WHEN d.QuantityFromDemand < s.QuantityFromSupply
THEN s.QuantityFromSupply - d.QuantityFromDemand ELSE 0 END
- CASE WHEN s.QuantityToSupply < d.QuantityToDemand
THEN d.QuantityToDemand - s.QuantityToSupply ELSE 0 END AS TradeQuantity
FROM #supply AS s
INNER JOIN #demand AS d
ON (s.QuantityFromSupply < d.QuantityToDemand
AND d.QuantityFromDemand < s.QuantityFromSupply); Както можете да видите, това е много близо до ревизираното решение за кръстовища, което разгледах.
Планът за окончателната заявка в решението на Kamil е показан на фигура 8.
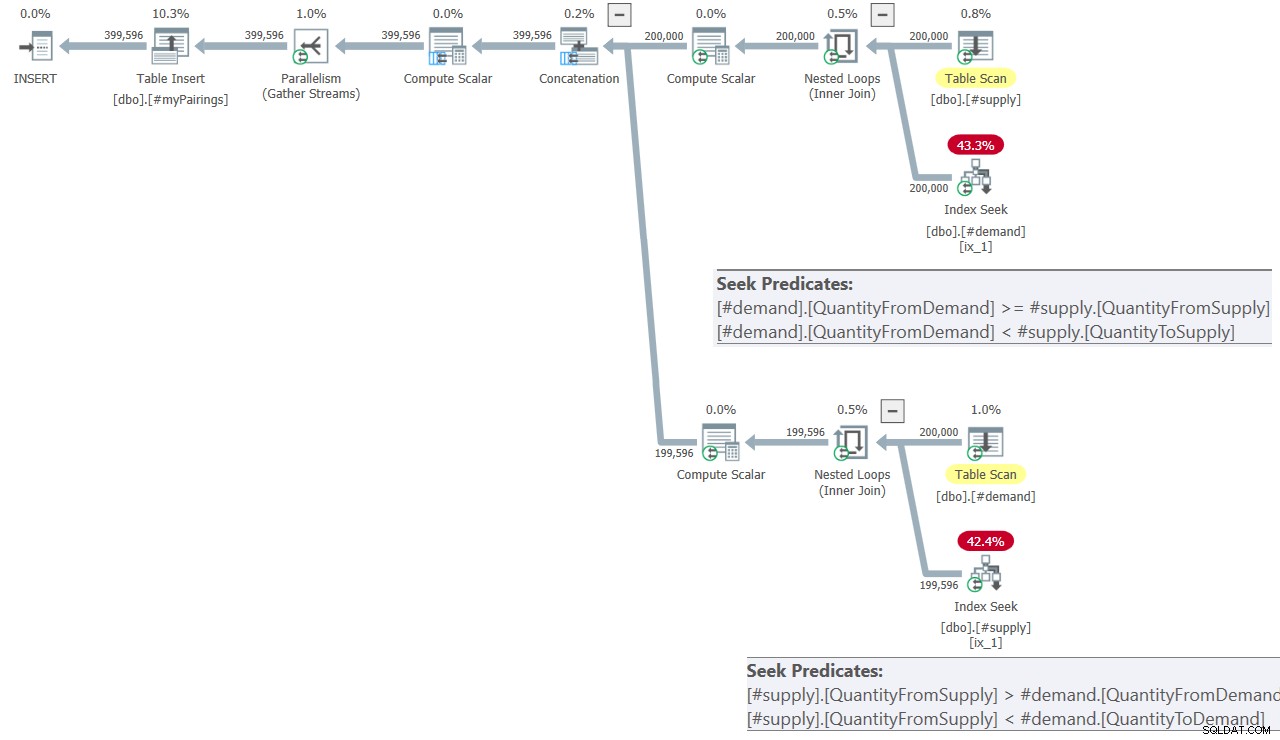
Фигура 8:План на заявка за окончателна заявка в решението на Kamil
Планът изглежда доста подобен на този, показан по-рано на Фигура 7.
Тест за производителност
Припомнете си, че завършването на класическото решение за кръстовища отне 931 секунди спрямо вход с 400 000 реда. Това са 15 минути! Това е много, много по-лошо от решението на курсора, което отне около 12 секунди, за да завърши срещу същия вход. Фигура 9 показва числата за производителност, включително новите решения, обсъждани в тази статия.
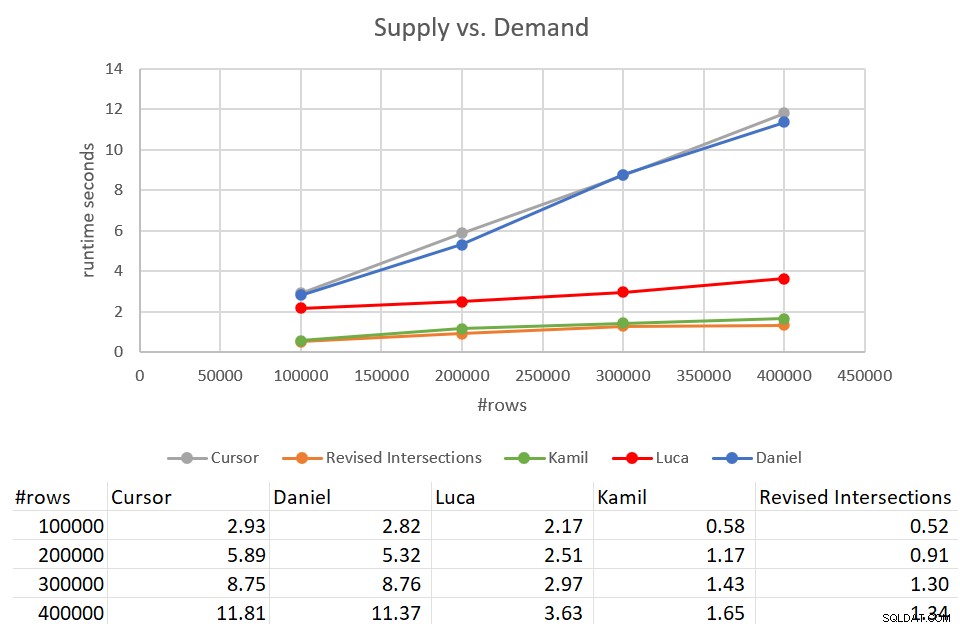
Фигура 9:Тест за ефективност
Както можете да видите, решението на Kamil и подобното ревизирано решение за кръстовища отне около 1,5 секунди за завършване спрямо входа от 400K реда. Това е доста прилично подобрение в сравнение с оригиналното базирано на курсора решение. Основният недостатък на тези решения е цената на I/O. С търсене на ред, за вход от 400K ред, тези решения извършват излишък от 1,35M четения. Но също така може да се счита за напълно приемлива цена, като се има предвид доброто време за изпълнение и мащабиране, което получавате.
Какво следва?
Първият ни опит за решаване на предизвикателството за съответствие между предлагането и търсенето разчиташе на класическия тест за пресичане на интервали и получихме лошо представящ се план с квадратично мащабиране. Много по-лошо от решението, базирано на курсора. Въз основа на прозрения от Лука, Камил и Даниел, използвайки ревизиран тест за пресичане на интервали, вторият ни опит беше значително подобрение, което използва ефективно индексирането и работи по-добре от базираното на курсора решение. Това решение обаче включва значителни разходи за I/O. Следващия месец ще продължа да проучвам допълнителни решения.
[ Прескочи към:Оригинално предизвикателство | Решения:Част 1 | Част 2 | част 3]