Фон
Едно от първите неща, които гледам, когато отстранявам проблем с производителността, е статистиката за чакане чрез sys.dm_os_wait_stats DMV. За да видя какво чака SQL Server, използвам заявката от текущия набор от диагностични заявки на Glenn Berry. В зависимост от изхода започвам да ровя в конкретни области в SQL Server.
Като пример, ако видя високо изчакване на CXPACKET, проверявам броя на ядрата на сървъра, броя на NUMA възлите и стойностите за максимална степен на паралелизъм и праг на разходите за паралелизъм. Това е основна информация, която използвам, за да разбера конфигурацията. Преди дори да обмисля да направя някакви промени, събирам още количествени данни, тъй като система с CXPACKET изчакване не е задължително да има неправилна настройка за максимална степен на паралелизъм.
По същия начин, система, която има голямо изчакване за свързани с I/O типове изчакване, като PAGEIOLATCH_XX, WRITELOG и IO_COMPLETION, не е задължително да има по-ниска подсистема за съхранение. Когато видя типове изчаквания, свързани с I/O, като горното чакане, веднага искам да разбера повече за основното хранилище. Това директно свързано съхранение ли е или SAN? Какво е нивото на RAID, колко диска съществуват в масива и каква е скоростта на дисковете? Също така искам да знам дали други файлове или бази данни споделят хранилището. И макар да е важно да разберете конфигурацията, логична следваща стъпка е да разгледате статистиката на виртуалните файлове чрез sys.dm_io_virtual_file_stats DMV.
Въведен в SQL Server 2005, този DMV е заместител на функцията fn_virtualfilestats, която тези от вас, които са работили на SQL Server 2000 и по-рано, вероятно познават и обичат. DMV съдържа кумулативна I/O информация за всеки файл на базата данни, но данните се нулират при рестартиране на екземпляра, когато базата данни е затворена, изведена офлайн, отделена и повторно прикачена и т.н. Важно е да се разбере, че данните за статистика на виртуалния файл не са представителни за текущите производителност – това е моментна снимка, която е съвкупност от I/O данни от последното изчистване от едно от гореспоменатите събития. Въпреки че данните не са моментни, те все още могат да бъдат полезни. Ако най-високите изчаквания за даден екземпляр са свързани с I/O, но средното време на изчакване е по-малко от 10 ms, съхранението вероятно не е проблем – но корелирането на изхода с това, което виждате в sys.dm_io_virtual_stats, все още си струва да се потвърди ниско латентности. Освен това, дори ако видите големи латентности в sys.dm_io_virtual_stats, все още не сте доказали, че съхранението е проблем.
Настройката
За да разгледам статистиката на виртуалните файлове, настроих две копия на базата данни AdventureWorks2012, които можете да изтеглите от Codeplex. За първото копие, известно по-нататък като EX_AdventureWorks2012, стартирах скрипта на Джонатан Кехайяс, за да разширя таблиците Sales.SalesOrderHeader и Sales.SalesOrderDetail съответно до 1,2 милиона и 4,9 милиона реда. За втората база данни, BIG_AdventureWorks2012, използвах скрипта от предишната си публикация за разделяне, за да създам копие на таблицата Sales.SalesOrderHeader със 123 милиона реда. И двете бази данни бяха съхранени на външно USB устройство (Seagate Slim 500GB), с tempdb на моя локален диск (SSD).
Преди тестването създадох четири персонализирани съхранени процедури във всяка база данни (Create_Custom_SPs.zip), които ще ми служат като "нормално" работно натоварване. Моят процес на тестване беше следният за всяка база данни:
- Рестартирайте екземпляра.
- Заснемане на статистически данни за виртуални файлове.
- Изпълнете „нормалното“ натоварване за две минути (процедури, извиквани многократно чрез скрипт на PowerShell).
- Заснемане на статистически данни за виртуални файлове.
- Повторно изграждане на всички индекси за подходящата(ите) таблица(и) на SalesOrder.
- Заснемане на статистически данни за виртуални файлове.
Данните
За да заснема статистически данни за виртуални файлове, създадох таблица за съхраняване на историческа информация и след това използвах вариация на заявката на Джими Мей от неговия DMV All-Stars скрипт за моментната снимка:
USE [msdb];
GO
CREATE TABLE [dbo].[SQLskills_FileLatency]
(
[RowID] [INT] IDENTITY(1,1) NOT NULL,
[CaptureID] [INT] NOT NULL,
[CaptureDate] [DATETIME2](7) NULL,
[ReadLatency] [BIGINT] NULL,
[WriteLatency] [BIGINT] NULL,
[Latency] [BIGINT] NULL,
[AvgBPerRead] [BIGINT] NULL,
[AvgBPerWrite] [BIGINT] NULL,
[AvgBPerTransfer] [BIGINT] NULL,
[Drive] [NVARCHAR](2) NULL,
[DB] [NVARCHAR](128) NULL,
[database_id] [SMALLINT] NOT NULL,
[file_id] [SMALLINT] NOT NULL,
[sample_ms] [INT] NOT NULL,
[num_of_reads] [BIGINT] NOT NULL,
[num_of_bytes_read] [BIGINT] NOT NULL,
[io_stall_read_ms] [BIGINT] NOT NULL,
[num_of_writes] [BIGINT] NOT NULL,
[num_of_bytes_written] [BIGINT] NOT NULL,
[io_stall_write_ms] [BIGINT] NOT NULL,
[io_stall] [BIGINT] NOT NULL,
[size_on_disk_MB] [NUMERIC](25, 6) NULL,
[file_handle] [VARBINARY](8) NOT NULL,
[physical_name] [NVARCHAR](260) NOT NULL
) ON [PRIMARY];
GO
CREATE CLUSTERED INDEX CI_SQLskills_FileLatency ON [dbo].[SQLskills_FileLatency] ([CaptureDate], [RowID]);
CREATE NONCLUSTERED INDEX NCI_SQLskills_FileLatency ON [dbo].[SQLskills_FileLatency] ([CaptureID]);
DECLARE @CaptureID INT;
SELECT @CaptureID = MAX(CaptureID) FROM [msdb].[dbo].[SQLskills_FileLatency];
PRINT (@CaptureID);
IF @CaptureID IS NULL
BEGIN
SET @CaptureID = 1;
END
ELSE
BEGIN
SET @CaptureID = @CaptureID + 1;
END
INSERT INTO [msdb].[dbo].[SQLskills_FileLatency]
(
[CaptureID],
[CaptureDate],
[ReadLatency],
[WriteLatency],
[Latency],
[AvgBPerRead],
[AvgBPerWrite],
[AvgBPerTransfer],
[Drive],
[DB],
[database_id],
[file_id],
[sample_ms],
[num_of_reads],
[num_of_bytes_read],
[io_stall_read_ms],
[num_of_writes],
[num_of_bytes_written],
[io_stall_write_ms],
[io_stall],
[size_on_disk_MB],
[file_handle],
[physical_name]
)
SELECT
--virtual file latency
@CaptureID,
GETDATE(),
CASE
WHEN [num_of_reads] = 0
THEN 0
ELSE ([io_stall_read_ms]/[num_of_reads])
END [ReadLatency],
CASE
WHEN [io_stall_write_ms] = 0
THEN 0
ELSE ([io_stall_write_ms]/[num_of_writes])
END [WriteLatency],
CASE
WHEN ([num_of_reads] = 0 AND [num_of_writes] = 0)
THEN 0
ELSE ([io_stall]/([num_of_reads] + [num_of_writes]))
END [Latency],
--avg bytes per IOP
CASE
WHEN [num_of_reads] = 0
THEN 0
ELSE ([num_of_bytes_read]/[num_of_reads])
END [AvgBPerRead],
CASE
WHEN [io_stall_write_ms] = 0
THEN 0
ELSE ([num_of_bytes_written]/[num_of_writes])
END [AvgBPerWrite],
CASE
WHEN ([num_of_reads] = 0 AND [num_of_writes] = 0)
THEN 0
ELSE (([num_of_bytes_read] + [num_of_bytes_written])/([num_of_reads] + [num_of_writes]))
END [AvgBPerTransfer],
LEFT([mf].[physical_name],2) [Drive],
DB_NAME([vfs].[database_id]) [DB],
[vfs].[database_id],
[vfs].[file_id],
[vfs].[sample_ms],
[vfs].[num_of_reads],
[vfs].[num_of_bytes_read],
[vfs].[io_stall_read_ms],
[vfs].[num_of_writes],
[vfs].[num_of_bytes_written],
[vfs].[io_stall_write_ms],
[vfs].[io_stall],
[vfs].[size_on_disk_bytes]/1024/1024. [size_on_disk_MB],
[vfs].[file_handle],
[mf].[physical_name]
FROM [sys].[dm_io_virtual_file_stats](NULL,NULL) AS vfs
JOIN [sys].[master_files] [mf]
ON [vfs].[database_id] = [mf].[database_id]
AND [vfs].[file_id] = [mf].[file_id]
ORDER BY [Latency] DESC; Рестартирах екземпляра и след това веднага заснех статистически данни за файла. Когато филтрирах изхода, за да преглеждам само файловете на базата данни EX_AdventureWorks2012 и tempdb, бяха уловени само tempdb данни, тъй като не бяха поискани данни от базата данни EX_AdventureWorks2012:

Изход от първоначалното заснемане на sys.dm_os_virtual_file_stats
След това стартирах "нормалното" натоварване за две минути (броят на изпълненията на всяка съхранена процедура леко варираше) и след като завърши отново заснетите статистически данни за файла:

Изход от sys.dm_os_virtual_file_stats след нормално натоварване
Виждаме латентност от 57 мс за файла с данни EX_AdventureWorks2012. Не е идеално, но с течение на времето с нормалното ми натоварване това вероятно ще се изравни. Има минимално забавяне за tempdb, което се очаква, тъй като работното натоварване, което изпълнявах, не генерира много tempdb активност. След това възстанових всички индекси за таблиците Sales.SalesOrderHeaderEnlarged и Sales.SalesOrderDetailEnlarged:
USE [EX_AdventureWorks2012]; GO ALTER INDEX ALL ON Sales.SalesOrderHeaderEnlarged REBUILD; ALTER INDEX ALL ON Sales.SalesOrderDetailEnlarged REBUILD;
Преструктурирането отне по-малко от минута и забележете скока в латентността при четене за файла с данни EX_AdventureWorks2012 и скокове в забавянето на запис за данните EX_AdventureWorks2012 и регистрационни файлове:

Изход от sys.dm_os_virtual_file_stats след възстановяване на индекса
Според тази моментна снимка на статистическите данни за файловете, латентността е ужасна; над 600 мс за запис! Ако видя тази стойност за производствена система, би било лесно веднага да заподозря проблеми със съхранението. Въпреки това, също така си струва да се отбележи, че AvgBPerWrite също се увеличи, а записите на по-големи блокове отнемат повече време за завършване. Очаква се увеличението на AvgBPerWrite за задачата за възстановяване на индекса.
Разберете, че докато гледате тези данни, не получавате пълна картина. По-добър начин да разгледате латентностите с помощта на статистически данни за виртуални файлове е да направите моментни снимки и след това да изчислите латентността за изминалия период от време. Например, скриптът по-долу използва две моментни снимки (текущи и предишни) и след това изчислява броя на четенията и записите през този период от време, разликата в стойностите на io_stall_read_ms и io_stall_write_ms и след това разделя io_stall_read_ms делта на броя четения и io_stall_read_ms bywrite_ms брой записи. С този метод изчисляваме времето, през което SQL Server е чакал I/O за четене или запис, и след това го разделяме на броя четения или записвания, за да определим латентността.
DECLARE @CurrentID INT, @PreviousID INT; SET @CurrentID = 3; SET @PreviousID = @CurrentID - 1; WITH [p] AS ( SELECT [CaptureDate], [database_id], [file_id], [ReadLatency], [WriteLatency], [num_of_reads], [io_stall_read_ms], [num_of_writes], [io_stall_write_ms] FROM [msdb].[dbo].[SQLskills_FileLatency] WHERE [CaptureID] = @PreviousID ) SELECT [c].[CaptureDate] [CurrentCaptureDate], [p].[CaptureDate] [PreviousCaptureDate], DATEDIFF(MINUTE, [p].[CaptureDate], [c].[CaptureDate]) [MinBetweenCaptures], [c].[DB], [c].[physical_name], [c].[ReadLatency] [CurrentReadLatency], [p].[ReadLatency] [PreviousReadLatency], [c].[WriteLatency] [CurrentWriteLatency], [p].[WriteLatency] [PreviousWriteLatency], [c].[io_stall_read_ms]- [p].[io_stall_read_ms] [delta_io_stall_read], [c].[num_of_reads] - [p].[num_of_reads] [delta_num_of_reads], [c].[io_stall_write_ms] - [p].[io_stall_write_ms] [delta_io_stall_write], [c].[num_of_writes] - [p].[num_of_writes] [delta_num_of_writes], CASE WHEN ([c].[num_of_reads] - [p].[num_of_reads]) = 0 THEN NULL ELSE ([c].[io_stall_read_ms] - [p].[io_stall_read_ms])/([c].[num_of_reads] - [p].[num_of_reads]) END [IntervalReadLatency], CASE WHEN ([c].[num_of_writes] - [p].[num_of_writes]) = 0 THEN NULL ELSE ([c].[io_stall_write_ms] - [p].[io_stall_write_ms])/([c].[num_of_writes] - [p].[num_of_writes]) END [IntervalWriteLatency] FROM [msdb].[dbo].[SQLskills_FileLatency] [c] JOIN [p] ON [c].[database_id] = [p].[database_id] AND [c].[file_id] = [p].[file_id] WHERE [c].[CaptureID] = @CurrentID AND [c].[database_id] IN (2, 11);
Когато изпълним това, за да изчислим латентността по време на възстановяването на индекса, получаваме следното:

Закъснението, изчислено от sys.dm_io_virtual_file_stats по време на възстановяване на индекса 0 Adventure1 за WEX_EX em>
Сега можем да видим, че действителната латентност през това време е била висока – което бихме очаквали. И ако след това се върнем към нормалното си работно натоварване и го изпълним за няколко часа, средните стойности, изчислени от статистиката на виртуалните файлове, ще намалеят с времето. Всъщност, ако погледнем данните на PerfMon, които са били заснети по време на теста (и след това обработени чрез PAL), виждаме значителни скокове в Ср. Disk sec/Read и Avg. Disk sec/Write, което корелира с времето, през което се изпълняваше възстановяването на индекса. Но в други случаи стойностите на латентността са доста под приемливите стойности:
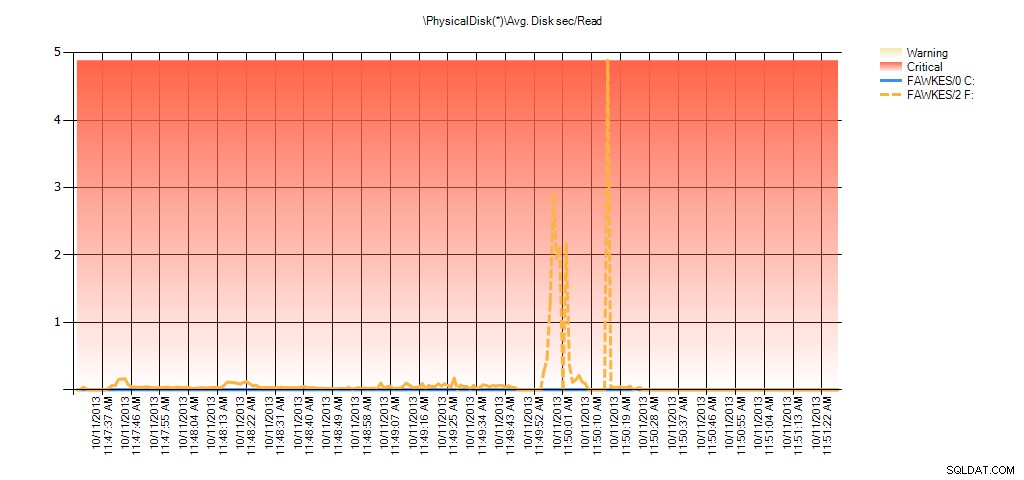
Резюме на средната дискова секунда/четене от PAL за EX_AdventureWorks2012 по време на тестване
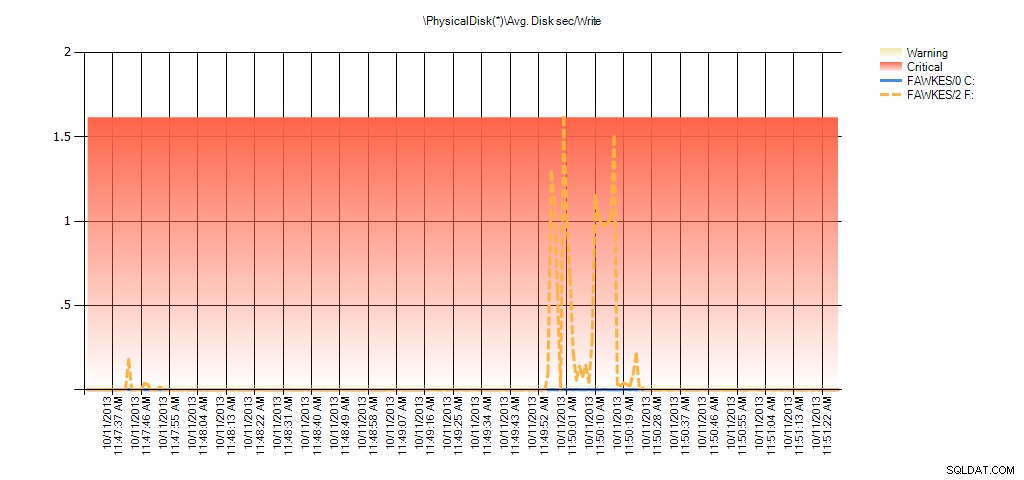
Резюме на средната дискова секунда/запис от PAL за EX_AdventureWorks2012 по време на тестване
Можете да видите същото поведение за базата данни BIG_AdventureWorks 2012. Ето информацията за закъснението въз основа на моментната снимка на статистиката на виртуалния файл преди възстановяването на индекса и след това:

Закъснението, изчислено от sys.dm_io_virtual_file_stats по време на възстановяване на индекса 0 Adventure2 за BIG em>
И данните от монитора на производителността показват същите пикове по време на повторното изграждане:
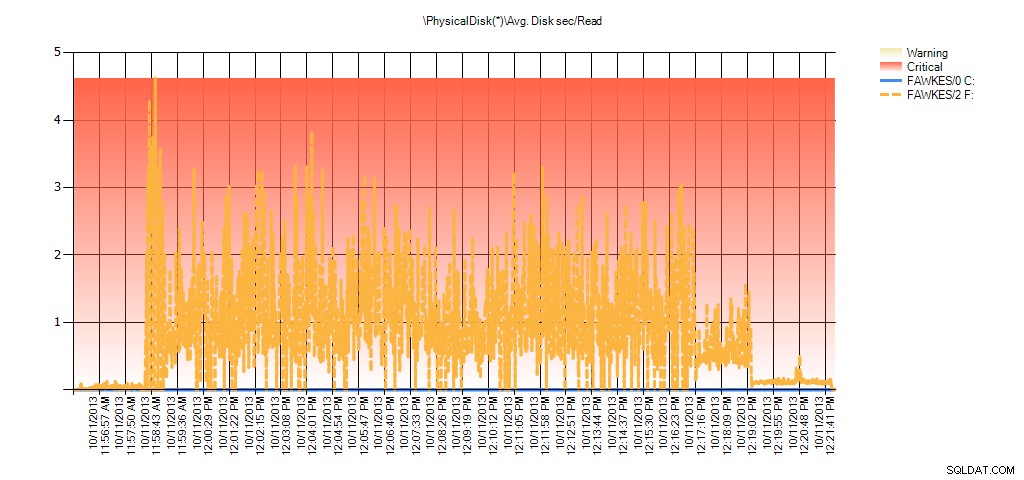
Резюме на средната дискова секунда/четене от PAL за BIG_AdventureWorks2012 по време на тестване
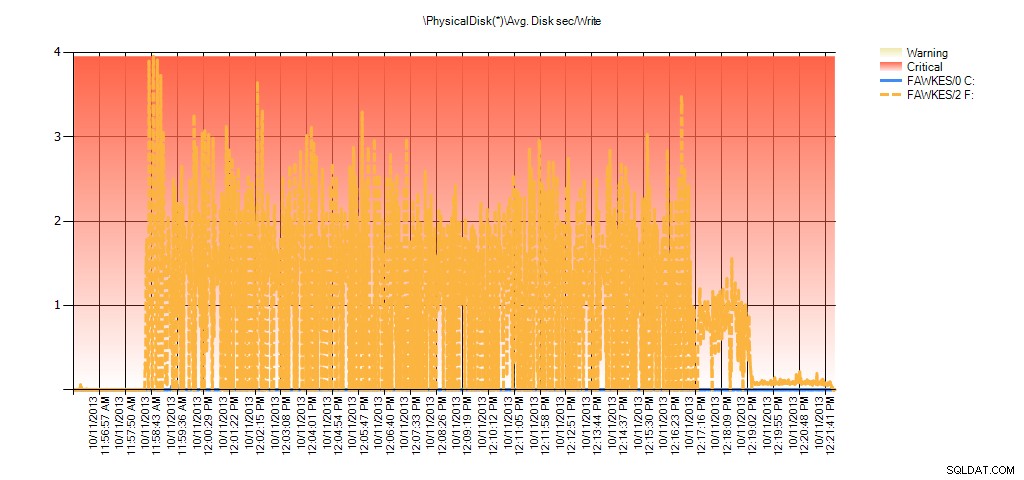
Резюме на средната дискова секунда/запис от PAL за BIG_AdventureWorks2012 по време на тестване
Заключение
Статистическите данни за виртуалните файлове са чудесна отправна точка, когато искате да разберете I/O производителността за екземпляр на SQL Server. Ако виждате изчаквания, свързани с I/O, когато разглеждате статистически данни за чакане, разглеждането на sys.dm_io_virtual_file_stats е логична следваща стъпка. Имайте предвид обаче, че данните, които преглеждате, са обобщени тъй като статистиката последно е изчистена от едно от свързаните събития (рестартиране на екземпляра, офлайн на базата данни и т.н.). Ако видите ниски латентности, тогава I/O подсистемата поддържа натоварването на производителността. Въпреки това, ако видите големи латентности, не е предрешено, че съхранението е проблем. За да разберете наистина какво се случва, можете да започнете да правите статистически данни за файла със моментни снимки, както е показано тук, или можете просто да използвате Performance Monitor, за да разгледате латентността в реално време. Много е лесно да създадете набор за събиране на данни в PerfMon, който улавя броячите на физическия диск Avg. Disk Sec/Read и Avg. Disk Sec/Read за всички дискове, които хостват файлове с база данни. Планирайте редовното стартиране и спиране на Data Collector и пробвайте всеки n секунди (напр. 15) и след като заснемете PerfMon данни за подходящо време, пуснете ги през PAL, за да проверите забавянето във времето.
Ако откриете, че I/O латентността възниква по време на нормалното ви работно натоварване, а не само по време на задачи по поддръжка, които задвижват I/O, вие все още не може да посочи съхранението като основен проблем. Закъснението при съхранение може да съществува по различни причини, като например:
- SQL сървърът трябва да чете твърде много данни в резултат на неефективни планове за заявки или липсващи индекси
- На екземпляра е разпределена твърде малко памет и едни и същи данни се четат от диск отново и отново, защото не могат да останат в паметта
- Неявните преобразувания причиняват сканиране на индекси или таблици
- Заявките изпълняват SELECT *, когато не са задължителни всички колони
- Проблемите с препратените записи в купчини причиняват допълнителен вход/изход
- Ниската плътност на страниците от фрагментация на индекс, разделяне на страници или неправилни настройки на фактора за запълване причиняват допълнителен вход/изход.
Каквато и да е основната причина, това, което е важно да разберете за производителността – особено що се отнася до I/O – е, че рядко има една точка от данни, която можете да използвате, за да определите проблема. Намирането на истинския проблем изисква множество факти, които, когато са събрани заедно, ви помагат да разкриете проблема.
И накрая, имайте предвид, че в някои случаи латентността при съхранение може да е напълно приемлива. Преди да поискате по-бързо съхранение или промени в кода, прегледайте моделите на работно натоварване и Споразумението за ниво на обслужване (SLA) за базата данни. В случай на хранилище за данни, което обслужва отчети на потребителите, SLA за заявки вероятно не е същите стойности под секунда, които бихте очаквали за OLTP система с голям обем. В DW решението I/O латентности, по-големи от една секунда, може да са напълно приемливи и очаквани. Разберете очакванията на бизнеса и неговите потребители и след това определете какво действие, ако има такова, да предприемете. И ако са необходими промени, съберете количествените данни, от които се нуждаете, за да подкрепите аргумента си, а именно статистически данни за изчакване, статистика за виртуални файлове и закъснения от Performance Monitor.