БЕЛЕЖКИ:
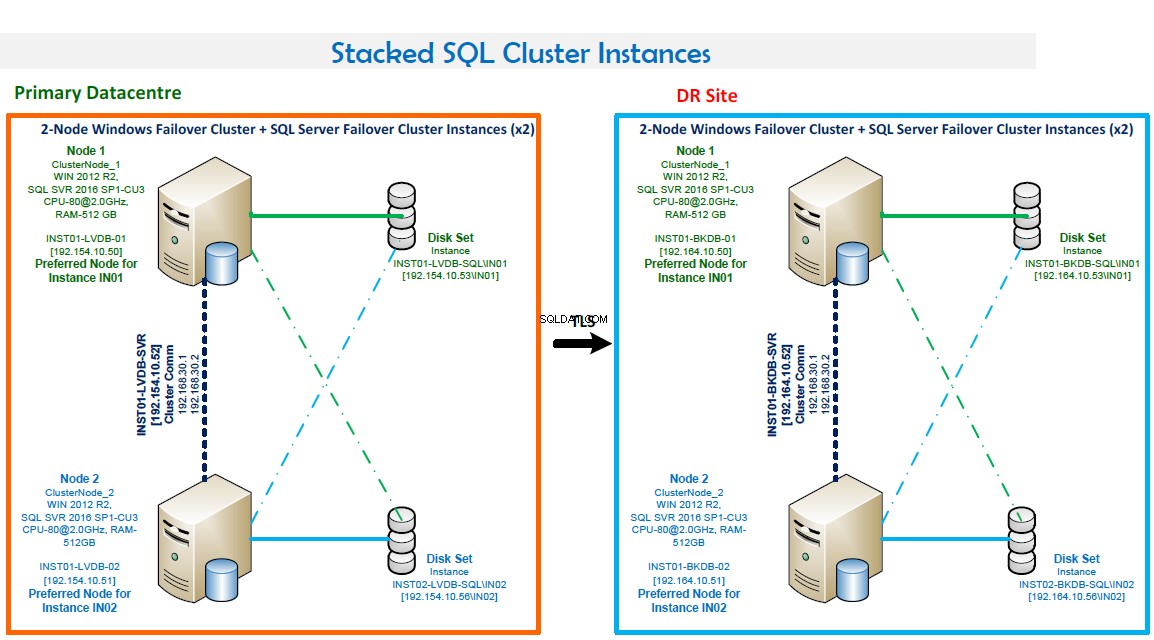
- Клъстер при отказ при отказ на Windows, включващ два възела.
- Два екземпляра на клъстер за отказване на SQL Server. Тази конфигурация оптимизира хардуера. IN01 е за предпочитане на Node1 и IN02 е за предпочитане на Node2.
- Номера на портове:IN01 слуша на порт 1435, а IN02 слуша на порт 1436.
- Висока наличност. И двата възела се копират един на друг. Отказът е автоматично в случай на повреда.
- Режимът на кворума е мнозинство на възел и диск.
- Резервно LAN на място и рутинно архивиране, конфигурирано с помощта на Veritas
Въведение
Не е необичайно разработчиците и ръководителите на проекти да изискват нов екземпляр на SQL Server за всяко ново приложение или услуга. Докато технологии като виртуализация и облак направиха въртенето на нови инстанции лесно, някои вековни техники, вградени в SQL Server, правят възможно постигането на ниски времена за изпълнение, когато има нужда от предоставяне на нова база данни за нова услуга или приложение. Това състояние на нещата може да бъде създадено от DBA, който може да проектира и разгърне голям SQL Server клъстер, способен да поддържа повечето бази данни на SQL Server, изисквани от организацията. Има допълнителни предимства към този вид консолидация, като по-ниски разходи за лицензи, по-добро управление и лекота на администриране. В статията ще подчертаем някои съображения, които сме имали възможността да изпитаме при използването на клъстериране и подреждане като средство за консолидиране на бази данни на SQL Server.
Групиране
Windows Server Failover Clustering е много добре известно решение за висока достъпност, което е оцеляло в много версии на Windows Server и което Microsoft възнамерява да продължи да инвестира и да го подобрява. Инстанциите на клъстер за отказ на SQL Server разчитат на WSFC. Както стандартното, така и корпоративното издание на SQL Server поддържат екземпляри на клъстер за отказ на SQL Server, но стандартното издание е ограничено само до два възела. Консолидирането на бази данни на един SQL Server FCI дава предимства като:
- HA по подразбиране — Всички бази данни, разположени на клъстерен екземпляр на SQL Server, са много достъпни по подразбиране! След като се създаде клъстерен екземпляр, новите внедрявания се полагат предварително по отношение на HA.
- Леснота на администриране – По-малко DBA могат да отделят време за конфигуриране, наблюдение и, когато е необходимо, за отстраняване на неизправности ЕДИН клъстериран екземпляр, поддържащ много приложения. Правилно, документирането на екземпляра също е много по-лесно, когато се работи с една голяма среда. Конфигурирането на Enterprise Backup решение за обработка на всички бази данни във вашата среда се улеснява от факта, че трябва да направите тази конфигурация само една, когато използвате консолидирани екземпляри.
- Съответствие – Такива ключови изисквания като корекция и дори втвърдяване могат да бъдат извършени веднъж с минимално време на престой на голям брой бази данни с едно административно усилие. В нашия магазин ние използвахме доставка на регистрационни файлове на транзакции между клъстерирани екземпляри в два центъра за данни, за да гарантираме, че базите данни са защитени от риска от бедствия.
- Стандартизация – Налагането на такива стандарти като конвенции за именуване, управление на достъпа, удостоверяване на Windows, одит и управление, базирано на политики, е много по-лесно, когато се работи само с една или две среди в зависимост от размера на вашия магазин
Обява 1: Извличане на информация за вашия екземпляр
-- Извличане на подробности за екземпляра-- Включва колона за проверка дали екземплярът е клъстеризиран SELECT SERVERPROPERTY('MachineName') КАТО [MachineName], SERVERPROPERTY('ServerName') КАТО [ServerName], SERVERPROPERTY('SERVERPROPERTY') AS [Име на машина] Инстанция], SERVERPROPERTY('IsClustered') КАТО [IsClustered], SERVERPROPERTY('ComputerNamePhysicalNetBIOS') КАТО [ComputerNamePhysicalNetBIOS] , SERVERPROPERTY('Edition') КАТО [Edition], SERVERPROPERTY('ProductLevelProperty') Le PROPERTY ProductVersion') КАТО [ProductVersion], SERVERPROPERTY('ProcessID') КАТО [ProcessID], SERVERPROPERTY('Collation') КАТО [Collation], SERVERPROPERTY('IsFullTextInstalled') КАТО [IsFullTextInstalled],'SERVERIOnsIntegrity AScurlyOnsIntegritySecurity ], SERVERPROPERTY('IsHadrEnabled') КАТО [IsHadrEnabled], SERVERPROPERTY('HadrManagerStatus') КАТО [HadrManagerStatus], SERVERPROPERTY('IsXTPSupported') КАТО [IsXTPSupported]; Подреждане
SQL Server поддържа до петдесет единични екземпляра на един сървър и до 25 екземпляра на отказоустойчив клъстер на отказен клъстер на Windows Server. Различни версии на SQL Server могат да бъдат подредени в една и съща среда, за да се осигури стабилна среда, която ще поддържа различни приложения. При такава конфигурация надграждането на бази данни може да приеме формата на простото им популяризиране от един екземпляр на SQL Server към следващата версия в същия клъстер до остаряването на хардуера. Едно ключово съображение, което трябва да имате предвид при подреждането на SQL Server, е, че трябва да разпределите памет за всеки екземпляр по такъв начин, че общото количество разпределена памет да не надвишава паметта, налична в операционната система. Другата точка в тази посока е да се гарантира, че акаунтът на услугата на SQL Server за всеки екземпляр трябва да има привилегии за заключване на страници в паметта. Присвояването на заключващи страници в паметта гарантира, че когато SQL Server придобие памет, операционната система не се опитва да възстанови такава памет, когато други процеси на сървъра се нуждаят от памет. Създаването на дефиниран акаунт за услуга на SQL Server, конфигурирането на MAX_SERVER_MEMORY и предоставянето на привилегия за заключване на страници в паметта са основно трио при подреждането на екземпляри на SQL Server.
Microsoft таксува няколко хиляди долара за чифт процесорни ядра. Подреждането на екземпляри на SQL Server ви позволява да използвате този модел на лицензиране, като екземплярите споделят един и същ набор от процесори (изпотяване на актива). Вече споменахме, че можете да подреждате различни версии на SQL Server, като по този начин се грижите за наследени приложения, които все още работят с версии, по-стари от SQL Server 2016 например. Когато използвате различни издания на SQL Server, може да искате да обмислите използването на Processor Affinity, както е описано от Glen Berry в тази статия. Афинитетът на процесора може също да се използва за контрол на това как ресурсите на процесора се споделят между инстанция, точно както вие контролирате паметта. Подреждането също така адресира проблемите със сигурността за приложения, които трябва да използват акаунта на SA например или проблемите с конфигурацията за приложения, които изискват специален екземпляр, или такива опции са специфично съпоставяне. Загрижеността относно производителността на споделената TempDB е друга причина, поради която може да искате да стекате, а не да обедините всички бази данни в един клъстериран екземпляр.
Струва си да се отбележи, че стойността на клъстерирането, както беше подчертано по-рано, се простира още повече с подреждането. Например, когато закърпвате екземпляр на SQL Server с няколко FCI, всички FCI могат да бъдат закърпени наведнъж.
Точки към бележка
Когато се използва клъстериране, определени конвенции ще направят администрирането и управлението на средата малко по-лесно и ще потят активите по-добре. Ще се спрем накратко на някои от тях:
- Текущи клиентски инструменти — Може да откриете, че получавате необичайни грешки, когато се опитвате да управлявате екземпляр на SQL Server 2016 с помощта на SQL Server Management Studio 2012. Грешките не ви казват конкретно, че проблемът е версията на клиентския инструмент. Обикновено имаме SQL Server Management Studio 17.3 екземпляр на клиента, който искаме да използваме, за да се свържем с нашите екземпляри.
- Конвенции за именуване — Конвенцията за именуване ви улеснява да сте сигурни в кой екземпляр работите във всеки един момент. Използвайки псевдоними, можете допълнително да намалите тежестта от запомняне на дълго име на екземпляр за крайните потребители, които се нуждаят от достъп до базата данни.
- Предпочитан възел – Задаването на предпочитан възел за всяка роля на SQL Server в Failover Cluster Manager е добра идея, добър начин да се уверите, че процесорната мощност на всичките ви възли на клъстер се използва. В нашия магазин, след като настроихме предпочитани възли, ние конфигурирахме ролята да се откаже обратно между 0500 HRS и 0600 HRS в случай, че има неволно преминаване при отказ.
- Изпращане на регистрационни файлове на транзакциите – Когато конфигурирате възстановяване след бедствие за FCI, има смисъл да се идентифицират всички UNC пътища с помощта на виртуални имена, а не имената или IP адреса на възлите на клъстера. Това гарантира, че нещата продължават да функционират правилно, ако възникне отказ. Също така е много важно да се гарантира, че акаунтите на агент на SQL Server и на двата сайта имат пълен контрол върху тези пътища.
Списък 2: Конфигуриране на наблюдение за изпращане на дневник на транзакциите с помощта на имейл
-- Създаване на таблица за съхраняване на регистрационни данни за доставка Създаване на таблица msdb dbo log_shipping_report (бит за състояние, is_primary bit, server sysname, database_name sysname, time_since_last_backup int, last_backup_file nvarchar (500), backup_threshold int, is_enstsiableco bit_alert, is_enstsablecop_alert ), time_since_last_restore int, last_restored_file nvarchar(500), last_restored_latency int, restore_threshold int, is_restore_alert_enabled bit); go-- Създайте задание на SQL агент със следния скрипт-- Това ще изпрати имейл на интервали, определени от графика на заданието-- Работата трябва да бъде създадена във вторичен клъстеризиран екземпляр за доставка на журнали-- Тази работа изисква пощата на базата данни да е разрешена съкращаване таблица msdb dbo log_shipping_report goinsert в msdb dbo log_shipping_report EXEC sp_help_log_shipping_monitor; go/*select [сървър], database_name [database], time_since_last_copy [Last Copy Time], last_copied_file [Last Copied File], time_since_last_restore [Last Restore Time], last_restored_file [Last Restored timeresold], [Restored Thresold], Restoreh Restoreh Restoreh Restoreh Restoreh_thres [Restore Latency] от msdb.dbo.log_shipping_report; отидете */DECLARE @tableHTML NVARCHAR(MAX);DECLARE @SecServer SYSNAME;SET @SecServer =@@SERVERNAMESET @tableHTML =N'Състояние на регистрационните данни на транзакциите от вторичен сървър ' + @SecServer + N'
' +N'Моля, намерете състоянието по-долу на вторични бази данни:
' +N'
| Вторичен сървър | Вторична база данни | Последно копие | ' +N'Последно копиран файл | Последно време за възстановяване | ' +N'Последно възстановен файл | Праг за възстановяване | Възстановяване на забавяне | ' +CAST ( ( SELECT td =lsr.server, '',td =lsr [име_на_база_данни], td =lsr time_since_last_copy '',td =lsr last_copied_file td =si lsr lsr time_re , td =lsr last_restored_file, '',td =lsr restore_threshold '',td =casewhen lsr restore_thresholdlsr time_since_last_restore <0 then + '' + 'CRITICAL' + ' | 'когато lsr restore_thresholdlsr time_since_last_restore <20 и lsr restore_thresholdlsr time_since_last_restore> 0 след това + '#FFBB3color">' + 'WARNING' + ' | 'когато lsr restore_thresholdlsr time_since_last_restore> 20, след това + '' + 'OK' + ' | 'end , ''ОТ msdb dbo log_shipping_report as lsr ORDER BY lsr .[database_name]ЗА XML PATH('tr'), TYPE ) КАТО NVARCHAR(MAX) ) +N'
|---|
Дискови устройства
Един страничен ефект от подреждането на екземпляр на SQL Server и осигуряването на няколко бази данни е тенденцията да се изчерпват буквите на устройствата. Заобиколихме този проблем, като конфигурирахме точките за монтиране на обема. Всеки диск, присвоен на роля на клъстер, е конфигуриран като точка за монтиране с буква на устройството, необходима само за едно или две устройства на екземпляр. Важен момент, който трябва да се отбележи, когато използвате точки за монтиране на обем в клъстер, е, че в бъдеще, когато трябва да добавите повече точки за монтиране, за да изпълнявате подобни задачи по поддръжката, ще е необходимо да поставите И ДВЕ основното устройство, което притежава буквата на устройството, и монтирането точка в режим на поддръжка на клъстера.
В нашия случай открихме името на всяка точка за монтиране на тома въз основа на ролята на клъстера, към която беше присвоена. С толкова много дискове, с които трябва да се справите, определено ще трябва да измислите начин както вие, така и администраторът на хранилището да идентифицирате уникален диск, така че поддържането на дисковете на ниво съхранение, например, да не представлява голяма караница.
Списък 3: Наблюдавайте използването на дисково пространство при използване на точки за монтиране на обем
-- Следният скрипт ще покаже използването на дисково пространство от SQL Server - Той е особено полезен при използване на точки за монтиране на тома-- Използването на пространство на точката за монтиране на тома може също да се наблюдава от управление на компютъра (ниво на ОС)SELECT DISTINCT срещу volume_mount_point , спрямо file_system_type , срещу logical_volume_name, CONVERT(DECIMAL!18 2 срещу total_bytes 1073741824.0) AS [Общ размер (GB)], CONVERT(DECIMAL(18 2 срещу налични_байта 1073744) 1073744182 AS (CASTvaGB) available_bytes AS FLOAT)/ CAST(vs total_bytes AS FLOAT) КАТО DECIMAL (18,2)) * 100 AS [Свободно място %]FROM sys.master_files AS f С (NOLOCK)CROSS APPLY sys.dm_os_volume_stats f database_id, f i AS срещу OPTION (РЕКОМПИЛИРАНЕ);
Разгръщане на база данни
В нашия случай нашата стратегия беше да гарантираме, че новите бази данни следват нашия стандарт. По-старите бази данни се обработваха с малко повече внимание, тъй като консолидирахме и надграждахме едновременно. Помощникът за миграция на бази данни ни помогна да ни каже кои бази данни определено няма да са съвместими с нашия свещен екземпляр на SQL Server 2016 и ги оставихме на спокойствие (някои с нива на съвместимост са до 100). Всяка разгърната база данни трябва да има свои собствени обеми за данни и регистрационни файлове в зависимост от нейния размер. Използването на отделни томове за всяка база данни е още една стъпка към наличието на много добре организирана среда, което е важно като се има предвид потенциалната сложност на тази консолидирана среда. Последното твърдение също така предполага, че когато разрешите на приложение да създава свои собствени бази данни, вие като DBA трябва да преместите файловете с данни, след като разполагането приключи, тъй като приложението ще използва същите файлови местоположения, използвани от базата данни на модела.
Списък 4: Преместване на потребителски бази данни
-- 1. Задайте базата данни офлайн-- Не забравяйте да замените DB_NAME с действителното име на базата данниALTER DATABASE DB_NAME SET OFFLINE-- 2. Преместете файла или файловете на новото място.-- Това означава действително копиране на файловете с данни на Ниво на ОС-- Може също да се наложи да предоставите на акаунта на SQL Server Service пълни разрешения за файла с данни-- 3. За всеки преместен файл изпълнете следното изявление. ALTER DATABASE DB_NAME MODIFY FILE ( NAME =logical_name FILENAME ='new_path\os_file_name' )-- 4. Върнете базата данни онлайн ALTER DATABASE име на базата данни SET ONLINE -- 5. Проверете промяната на файла:SELECT име, физическо_име КАТО CurrentLocation, state_descFROM sys.master_filesWHERE database_id =DB_ID(N'DB_NAME');
Управление на достъпа
Ще се съгласите, че в нашата консолидирана среда бихме могли да имаме много дълъг списък от обекти на ниво сървър, като например влизания. Използването на Windows Groups ще помогне да се съкрати този списък и да се опрости управлението на достъпа на всеки клъстериран екземпляр. Обикновено ще ви трябват групи, създадени в Active Directory за администратори на приложения, които се нуждаят от достъп, акаунти за услуги на приложения, бизнес потребители, които трябва да изтеглят отчети и разбира се администратори на база данни. Едно от ключовите предимства на използването на Windows Groups е, че достъпът може да бъде предоставен или отменен просто чрез управление на членството в тези групи направо в Active Directory.
Вероятно вече е очевидно, че това предимство в областта на управлението на достъпа е възможно само с удостоверяване на Windows. Входовете в SQL Server не могат да се управляват в групи.
Списък 5: Инстанции за влизане, потребители на база данни и техните роли
създайте таблица #userlist ([Име на сървър] varchar(20),[Име на база данни] varchar(50),[Потребител на база данни] varchar(50), [Роля в базата данни] varchar(50), [Вход в инстанция] varchar( 50), [Състояние] varchar(15))goinsert into #userlistexec sp_MSforeachdb @command1 ='ИЗПОЛЗВАНЕ [?]АКО ''?'' НЕ В ("tempdb","model"J"msdb"J"master")BEGINselect @@име на сървър като име_на_екземпляр, ''?'' като име_на_база, rp.name като потребител на база данни, mp.name като роля_на_база_данни, sp.name като потребителско_вход, case, когато sp.is_disabled =1, след това ''Disabled'', когато sp.is_disabled =0 след това ''Enabled'' end[login_status]от sys.database_principals rpleft външно присъединяване sys.database_role_members drm on (drm.member_principal_id =rp.principal_id)left outer join sys.database_principals mple on (principal_principals out) mple_. присъединете се към sys.server_principals sp на (rp.sid=sp.sid), където rp.type_desc в (''WINDOWS_GROUP'',''WINDOWS_USER'',''SQL_USER'')END' goselect * от #userlist godrop таблица #userlist Заключение
Проучихме на много високо ниво ползите, които могат да бъдат получени чрез клъстериране и подреждане на екземпляри на SQL Server като средство за постигане на консолидация, оптимизиране на разходите и лекота на управление. Ако откриете, че можете да закупите голям хардуер, можете да разгледате тази опция и да се възползвате от предимствата, които описахме по-горе.