Въведено за първи път в SQL Server 2017 Enterprise Edition, адаптивно присъединяване позволява преход по време на изпълнение от хеш присъединяване в пакетен режим към индексирано присъединяване (прилагане) на корелирани вложени цикли в редов режим. За краткост ще се позова на „корелирани вложени цикли, индексирано присъединяване“ като прилагане през останалата част от тази статия. Ако имате нужда от освежаване относно разликата между вложени цикли и прилагане, моля, вижте предишната ми статия.
Дали адаптивно обединение преминава от хеш присъединяване към прилагане по време на изпълнение зависи от стойност, означена с Редове за адаптивни прагови стойности на Адаптивно присъединяване оператор на план за изпълнение. Тази статия показва как работи адаптивното свързване, включва подробности за изчисляването на прага и обхваща последиците от някои от направените дизайнерски избори.
Въведение
Едно нещо, което искам да имате предвид в тази част, е адаптивното присъединяване винаги започва да се изпълнява като хеш присъединяване в пакетен режим. Това е вярно дори ако планът за изпълнение показва, че адаптивното присъединяване очаква да се изпълнява като се прилага режим на ред.
Подобно на всяко хеш присъединяване, адаптивното присъединяване чете всички редове, налични на входа му за изграждане, и копира необходимите данни в хеш таблица. Ароматът на пакетния режим на хеш присъединяване съхранява тези редове в оптимизиран формат и ги разделя с помощта на една или повече хеш функции. След като входът за компилиране бъде изразходван, хеш таблицата е напълно попълнена и разделена на дялове, готова за хеш присъединяването, за да започне да проверява редовете от страната на сондата за съвпадения.
Това е моментът, в който адаптивното присъединяване взема решението да продължи с хеш присъединяването в пакетен режим или да се приложи преход към режим на ред. Ако броят на редовете в хеш таблицата е по-малък от прага стойност, присъединяването превключва към приложение; в противен случай присъединяването продължава като хеш присъединяване, като започва да чете редове от входа на сондата.
Ако се случи преход към присъединяване за прилагане, планът за изпълнение не чете повторно редовете, използвани за попълване на хеш таблицата, за да управлява операцията по прилагане. Вместо това вътрешен компонент, известен като адаптивен буферен четец разширява редовете, които вече са съхранени в хеш таблицата, и ги прави достъпни при поискване за външния вход на оператора за прилагане. Има цена, свързана с адаптивния буферен четец, но е много по-ниска от цената за пълно пренавиване на входа за компилиране.
Избор на адаптивно присъединяване
Оптимизирането на заявката включва един или повече етапи на логическо изследване и физическо изпълнение на алтернативи. На всеки етап, когато оптимизаторът изследва физическите опции за логическа join, може да разгледа алтернативи за прилагане както на хеш присъединяване в пакетен режим, така и на редов режим.
Ако една от тези опции за физическо присъединяване е част от най-евтиното решение, намерено през текущия етап—и другият тип присъединяване може да предостави същите необходими логически свойства – оптимизаторът маркира групата за логическо присъединяване като потенциално подходящ за адаптивно присъединяване. Ако не, разглеждането на адаптивно присъединяване приключва тук (и не се задейства разширено събитие за адаптивно присъединяване).
Нормалната работа на оптимизатора означава, че най-евтиното намерено решение ще включва само една от опциите за физическо свързване - или хеширане, или прилагане, в зависимост от това, което е с най-ниската прогнозна цена. Следващото нещо, което прави оптимизаторът, е да изгради и струва нова реализация на типа присъединяване, което не беше избран като най-евтин.
Тъй като текущата фаза на оптимизация вече е приключила с намерено най-евтино решение, за адаптивното присъединяване се извършва специален кръг на проучване и внедряване на една група. Накрая оптимизаторът изчислява адаптивния праг .
Ако някоя от предходните работи е неуспешна, разширеното събитие adaptive_join_skipped се задейства с причина.
Ако адаптивната обработка на присъединяване е успешна, Concat операторът се добавя към вътрешния план над хеша и прилага алтернативи с адаптивния буферен четец и всички необходими адаптери за пакетен/редов режим. Не забравяйте, че само една от алтернативите за присъединяване ще се изпълнява по време на изпълнение, в зависимост от броя на действително срещаните редове в сравнение с адаптивния праг.
Конкат операторът и индивидуалните алтернативи за хеширане/прилагане обикновено не се показват в крайния план за изпълнение. Вместо това ни е представено едно Адаптивно присъединяване оператор. Това е просто решение за представяне — Concat и съединенията все още присъстват в кода, изпълняван от машината за изпълнение на SQL Server. Можете да намерите повече подробности за това в разделите Приложение и Свързано четене на тази статия.
Адаптивният праг
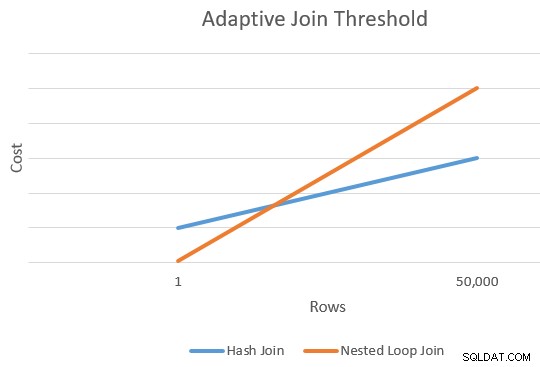
Приложението обикновено е по-евтино от хеш присъединяването за по-малък брой задвижващи редове. Хеш присъединяването има допълнителна начална цена за изграждане на своята хеш таблица, но по-ниска цена на ред, когато започне да търси съвпадения.
Обикновено има точка, в която прогнозната цена на прилагане и хеш присъединяване ще бъде еднаква. Тази идея беше добре илюстрирана от Joe Sack в неговата статия, Въвеждане на адаптивни присъединявания в пакетен режим:
Изчисляване на прага
В този момент оптимизаторът има една оценка за броя на редовете, влизащи във входа за изграждане на хеш присъединяването и прилагане на алтернативи. Той също така съдържа прогнозната цена на операторите за хеширане и прилагане като цяло.
Това ни дава една точка в крайния десен ръб на оранжевите и сините линии на диаграмата по-горе. Оптимизаторът се нуждае от друга отправна точка за всеки тип присъединяване, за да може да „начертае линиите“ и да намери пресечната точка (той не чертае буквално линии, но разбирате идеята).
За да намери втора точка за редовете, оптимизаторът иска от двете съединения да произведат нова оценка на разходите въз основа на различна (и хипотетична) мощност на входа. Ако първата оценка на мощността е била повече от 100 реда, тя изисква от присъединяванията да изчислят нови разходи за един ред. Ако първоначалната мощност е била по-малка или равна на 100 реда, втората точка се основава на входна мощност от 10 000 реда (така че има достатъчно приличен диапазон за екстраполиране).
Във всеки случай резултатът е две различни разходи и брой редове за всеки тип присъединяване, което позволява на редовете да бъдат „начертани“.
Формула на пресечната точка
Намирането на пресечната точка на две прави въз основа на две точки за всяка права е проблем с няколко добре известни решения. SQL Server използва такъв, базиран на детерминанти както описано в Wikipedia:
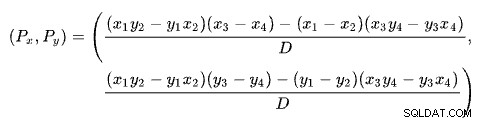
където:
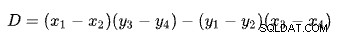
Първият ред е дефиниран от точките (x1 , y1 ) и (x2). , y2 ). Вторият ред е даден от точките (x3 , y3 ) и (x4). , y4 ). Пресечната точка е в (Px , Py ).
Нашата схема има броя на редовете по оста x и прогнозната цена по оста y. Интересуваме се от броя на редовете, където линиите се пресичат. Това се дава от формулата за Px . Ако искаме да знаем прогнозната цена на кръстовището, това би било Py .
За Px редове, прогнозните разходи за решенията за прилагане и хеш присъединяване ще бъдат равни. Това е адаптивният праг, от който се нуждаем.
Сработен пример
Ето пример за използване на примерната база данни AdventureWorks2017 и следния трик за индексиране от Ицик Бен-Ган за да получите безусловно разглеждане на изпълнението на пакетен режим:
-- Трикът на Ицик СЪЗДАВАТЕ НЕКЛУСТРИРАН ИНДЕКС НА COLUMNSTORE BatchModeON Sales.SalesOrderHeader (SalesOrderID)WHERE SalesOrderID =-1AND SalesOrderID =-2; -- Тестване на заявкаSELECT SOH.SubTotalFROM Sales.SalesOrderHeader КАТО SOHJOIN Sales.SalesOrderDetail КАТО SOD ON SOD.SalesOrderID =SOH.SalesOrderIDWHERE SOH.SalesOrderID <=75123;
Планът за изпълнение показва адаптивно присъединяване с праг от 1502.07 редове:
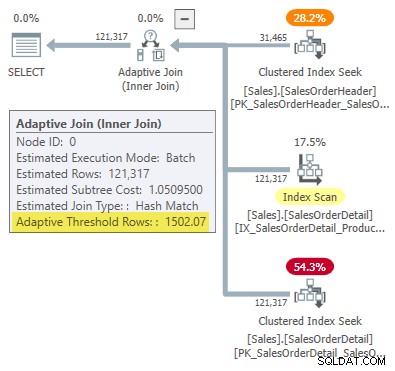
Прогнозният брой редове, управляващи адаптивното присъединяване, е 31 465 .
Разходи за присъединяване
В този опростен случай можем да намерим приблизителни разходи за поддърво за хеша и да приложим алтернативи за присъединяване с помощта на подсказки:
-- HashSELECT SOH.SubTotalFROM Sales.SalesOrderHeader КАТО SOHJOIN Sales.SalesOrderDetail КАТО SOD ON SOD.SalesOrderID =SOH.SalesOrderIDWHERE SOH.SalesOrderID <=75123OPTION (MAXpreDOP JOIN, MAXpreDOP JOIN);
-- ApplySELECT SOH.SubTotalFROM Sales.SalesOrderHeader КАТО SOHJOIN Sales.SalesOrderDetail КАТО SOD ON SOD.SalesOrderID =SOH.SalesOrderIDWHERE SOH.SalesOrderID <=75123OPTION> (MAXpreDOP JOIN, LOOP JOIN);
Това ни дава една точка на линията за всеки тип присъединяване:

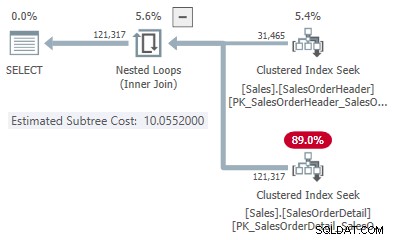
- 31 465 реда
- Хеш цена 1,05083
- Приложете цена 10,0552
Втората точка на линията
Тъй като приблизителният брой редове е повече от 100, вторите референтни точки идват от специални вътрешни оценки, базирани на един въведен ред за присъединяване. За съжаление, няма лесен начин да получите точните стойности на разходите за това вътрешно изчисление (ще говоря повече за това скоро).
Засега просто ще ви покажа числата на разходите (използвайки пълната вътрешна прецизност, а не шестте значими цифри, представени в плановете за изпълнение):
- Един ред (вътрешно изчисление)
- Хеш цена 0,999027422729
- Приложете цена 0,547927305023
- 31 465 реда
- Хеш цена 1,05082787359
- Приложете цена 10,0552890166
Както се очаква, присъединяването за прилагане е по-евтино от хеша за малка входна мощност, но много по-скъпо за очакваната мощност от 31 465 реда.
Изчисляване на пресечната точка
Включването на тези числа за мощност и цена във формулата за пресичане на линии ви дава следното:
- Хеш точки (x =кардиналност; y =цена) ДЕКЛАРИРАНЕ @x1 float =1, @y1 float =0,999027422729, @x2 float =31465, @y2 float =1,05082787359; -- Приложете точки (x =кардиналност; y =цена) ДЕКЛАРИРАНЕ @x3 float =1, @y3 float =0,547927305023, @x4 float =31465, @y4 float =10,0552890166; -- Формула:ИЗБЕРЕТЕ праг =( (@x1 * @y2 - @y1 * @x2) * (@x3 - @x4) - (@x1 - @x2) * (@x3 * @y4 - @y3 * @x4 ) ) / ( (@x1 - @x2) * (@y3 - @y4) - (@y1 - @y2) * (@x3 - @x4) ); -- Връща 1502.06521571273
Закръглен до шест значими цифри, този резултат съответства на 1502.07 редове, показани в плана за изпълнение на адаптивното присъединяване:
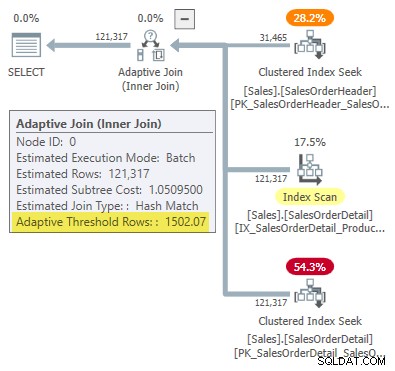
Дефект или дизайн?
Не забравяйте, че SQL Server се нуждае от четири точки, за да „начертае“ броя на редовете спрямо разходните линии, за да намери прага за адаптивно присъединяване. В настоящия случай това означава намиране на оценки на разходите за мощностите на един ред и 31 465 реда както за прилагане, така и за хеш присъединяване.
Оптимизаторът извиква рутина с име sqllang!CuNewJoinEstimate за изчисляване на тези четири разходи за адаптивно присъединяване. За съжаление няма флагове за проследяване или разширени събития, които да предоставят удобен преглед на тази дейност. Нормалните флагове за проследяване, използвани за изследване на поведението на оптимизатора и разходите за показване, не функционират тук (вижте приложението, ако се интересувате от повече подробности).
Единственият начин да получите прогнозите за разходите в един ред е да прикачите програма за отстраняване на грешки и да зададете точка на прекъсване след четвъртото извикване на CuNewJoinEstimate в кода за sqllang!CardSolveForSwitch . Използвах WinDbg, за да получа този стек от повиквания на SQL Server 2019 CU12:

В този момент в кода разходите с плаваща запетая с двойна точност се съхраняват в четири места в паметта, посочени от адреси в rsp+b0 , rsp+d0 , rsp+30 и rsp+28 (където rsp е регистър на процесора и изместванията са в шестнадесетична форма):

Показаните номера на разходите в поддървото на оператора съвпадат с тези, използвани във формулата за изчисляване на прага за адаптивно присъединяване.
Относно тези едноредови оценки на разходите
Може да сте забелязали, че приблизителните разходи за поддървото за съединенията от един ред изглеждат доста високи за количеството работа, свързана с присъединяването на един ред:
- Един ред
- Хеш цена 0,999027422729
- Приложете цена 0,547927305023
Ако се опитате да създадете планове за изпълнение на едноредово въвеждане за хеш присъединяването и да приложите примери, ще видите много по-ниски прогнозни разходи за поддървото при присъединяването от тези, показани по-горе. По същия начин, изпълнението на оригиналната заявка с цел за ред от единица (или броя на изходните редове за присъединяване, очакван за вход от един ред) също ще доведе до прогнозна цена начин по-ниско от показаното.
Причината е CuNewJoinEstimate рутинната оценка на един ред случай по начин, който мисля, че повечето хора не биха намерили интуитивен.
Крайната цена се състои от три основни компонента:
- Цената на входното поддърво за изграждане
- Местната цена на присъединяването
- Цената на входното поддърво на сондата
Елементи 2 и 3 зависят от вида на присъединяването. За хеш присъединяване те отчитат разходите за четене на всички редове от входа на сондата, съпоставянето им (или не) с единия ред в хеш таблицата и предаването на резултатите на следващия оператор. За кандидатстване разходите покриват едно търсене на по-ниския вход към обединението, вътрешната цена на самото обединение и връщането на съвпадащите редове на родителския оператор.
Нищо от това не е необичайно или изненадващо.
Разходната изненада
Изненадата идва от страна на строежа на присъединяването (точка 1 от списъка). Може да се очаква от оптимизатора да направи някакво фантастично изчисление, за да намали вече изчислената цена на поддървото за 31 465 реда до един среден ред или нещо подобно.
Всъщност, както хеширането, така и прилагането на прогнозите за свързване в един ред просто използват цялата цена на поддървото за оригинал оценка на кардиналитета от 31 465 реда. В нашия пример за изпълнение това „поддърво“ е 0.54456 цена на груповото търсене на индекс в пакетния режим в заглавната таблица:
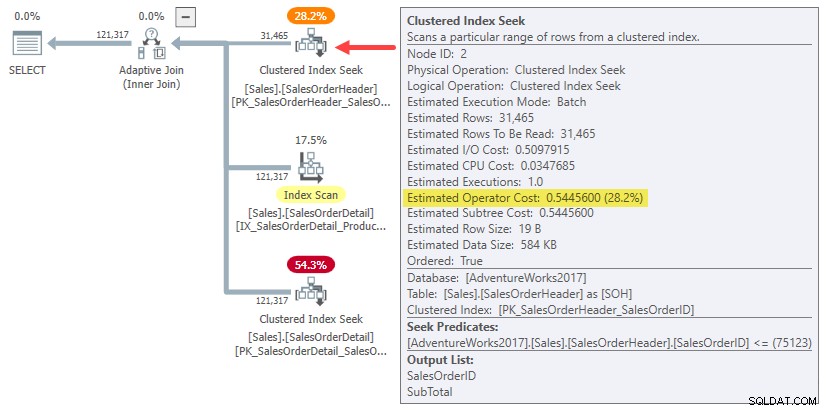
За да бъде ясно:прогнозните разходи от страна на изграждане за алтернативите за свързване с един ред използват входна цена, изчислена за 31 465 реда. Това би трябвало да ви се стори малко странно.
Като напомняне, разходите за един ред са изчислени от CuNewJoinEstimate бяха както следва:
- Един ред
- Хеш цена 0,999027422729
- Приложете цена 0,547927305023
Можете да видите, че общата цена за прилагане (~0,54793) е доминирана от 0,54456 Разходите на поддървото от страна на изграждане, с малка допълнителна сума за едно търсене от вътрешната страна, обработване на малкия брой резултантни редове в обединението и предаването им на оператора родител.
Прогнозната цена за хеш присъединяване на един ред е по-висока, тъй като пробната страна на плана се състои от пълно сканиране на индекс, където всички получени редове трябва да преминат през обединението. Общата цена на едноредовото хеш присъединяване е малко по-ниска от първоначалната цена от 1,05095 за примера с 31 465 реда, защото сега има само един ред в хеш таблицата.
Последствия
Човек би очаквал оценката за едноредово присъединяване да се основава отчасти на разходите за доставка на един ред към входния вход за свързване. Както видяхме, това не важи за адаптивно присъединяване:алтернативите за прилагане и хеширане са обременени с пълната прогнозна цена за 31 465 реда. Останалата част от присъединяването струва доста скъпо, както може да се очаква за въвеждане на едноредово изграждане.
Тази интуитивно странна подредба е причината да е трудно (може би невъзможно) да се покаже план за изпълнение, отразяващ изчислените разходи. Ще трябва да изградим план, доставящ 31 465 реда към горния вход за присъединяване, но струващ самото присъединяване и неговия вътрешен вход, сякаш присъства само един ред. Трудно питане.
Ефектът от всичко това е да повдигнем най-лявата точка на нашата диаграма с пресичащи се линии нагоре по оста y. Това се отразява на наклона на линията и следователно на пресечната точка.
Друг практически ефект е, че изчисленият праг на адаптивно присъединяване сега зависи от първоначалната оценка на мощността при входа за изграждане на хеш, както отбеляза Джо Оббиш в публикацията си в блога от 2017 г. Например, ако променим WHERE клауза в тестовата заявка до SOH.SalesOrderID <= 55000 , адаптивният праг намалява от 1502.07 на 1259.8 без промяна на хеша на плана на заявката. Същият план, различен праг.
Това възниква, тъй като, както видяхме, вътрешната едноредова оценка на разходите зависи от входната цена за изграждане за първоначалната оценка на мощността. Това означава, че различните първоначални оценки от страна на изграждане ще дадат различен „тласък“ по оста y на оценката от един ред. От своя страна линията ще има различен наклон и различна пресечна точка.
Интуицията предполага, че оценката за един ред за едно и също съединение трябва винаги да дава една и съща стойност, независимо от другата оценка на мощността на реда (като се има предвид точно същото съединение със същите свойства и размери на редовете има близка до линейна връзка между движението редове и цена). Това не е така за адаптивно присъединяване.
По проект?
Мога да ви кажа с известна увереност каквоправи SQL Server при изчисляване на прага за адаптивно присъединяване. Нямам никаква специална представа за защо прави го по този начин.
Все пак има някои причини да смятаме, че това споразумение е умишлено и е възникнало след надлежно разглеждане и обратна връзка от тестването. Останалата част от този раздел обхваща някои от моите мисли по този аспект.
Адаптивното присъединяване не е пряк избор между нормално прилагане и хеш присъединяване в пакетен режим. Адаптивното присъединяване винаги започва с пълно попълване на хеш таблицата. Само след като тази работа приключи, се взема решението да се премине към прилагане на прилагане или не.
По това време вече сме направили потенциално значителни разходи чрез попълване и разделяне на хеш присъединяването в паметта. Това може да няма голямо значение за едноредовия случай, но става все по-важно с увеличаване на мощността. Неочакваното „ускоряване“ може да бъде начин за включване на тези реалности в изчислението, като същевременно се запази разумна цена на изчисленията.
Моделът на разходите на SQL Server отдавна е малко предубеден спрямо присъединяването на вложени цикли, вероятно с известна обосновка. Дори идеалният индексиран случай на приложение може да бъде бавен на практика, ако необходимите данни вече не са в паметта и I/O подсистемата не е флаш, особено с донякъде модел на произволен достъп. Ограничените количества памет и бавният I/O няма да са напълно непознати за потребителите на облачни бази данни от по-нисък клас, например.
Възможно е практическото тестване в такива среди да разкрие, че адаптивното присъединяване с интуитивна цена е било твърде бързо за преминаване към приложение. Теорията понякога е страхотна само на теория.
Все пак настоящата ситуация не е идеална; кеширането на план, базиран на необичайно ниска оценка на мощността, ще доведе до адаптивно присъединяване, много по-неохотно да премине към приложение, отколкото би било при по-голяма първоначална оценка. Това е разновидност на проблема с чувствителността на параметрите, но ще бъде ново разглеждане от този тип за много от нас.
Сега също е възможно използването на пълния входен поддърво за изграждане за най-лявата точка на пресичащите се разходни линии е просто некоригирана грешка или пропуск. Чувството ми е, че настоящата реализация вероятно е умишлен практически компромис, но ще ви трябва някой с достъп до проектните документи и изходния код, за да знаете със сигурност.
Резюме
Адаптивното присъединяване позволява на SQL Server да премине от хеш присъединяване в пакетен режим към приложение, след като хеш таблицата е напълно попълнена. Той взема това решение, като сравнява броя на редовете в хеш таблицата с предварително изчислен адаптивен праг.
Прагът се изчислява чрез прогнозиране къде разходите за прилагане и хеш присъединяване са равни. За да открие тази точка, SQL Server произвежда втора оценка на разходите за вътрешно присъединяване за различна мощност на входа за изграждане — обикновено един ред.
Изненадващо, прогнозната цена за оценката за един ред включва пълната цена на поддървото от страната на изграждане за първоначалната оценка на мощността (не е мащабирана до един ред). Това означава, че праговата стойност зависи от първоначалната оценка на мощността на входа за изграждане.
Следователно, адаптивното присъединяване може да има неочаквано ниска прагова стойност, което означава, че адаптивното присъединяване е много по-малко вероятно да премине от хеш присъединяване. Не е ясно дали това поведение е проектирано.
Свързано четене
- Представяме адаптивни присъединявания в пакетен режим от Джо Сак
- Разбиране на адаптивните присъединявания в документацията на продукта
- Adaptive Join Internals от Dima Pilugin
- Как работят адаптивните присъединявания в пакетен режим? на Stack Exchange на администратори на бази данни от Ерик Дарлинг
- Адаптивна регресия на присъединяване от Джо Оббиш
- Ако искате адаптивни присъединявания, имате нужда от по-широки индекси и по-голям ли е по-добър? от Ерик Дарлинг
- Подушване на параметри:Адаптивни присъединявания от Брент Озар
- Въпроси и отговори за интелигентна обработка на заявки от Джо Сак
Приложение
Този раздел обхваща няколко аспекта на адаптивно присъединяване, които беше трудно да се включат в основния текст по естествен начин.
Разширеният адаптивен план
Можете да опитате да разгледате визуално представяне на вътрешния план, като използвате недокументиран флаг за проследяване 9415, както е предоставено от Дима Пилугин в неговата отлична статия за адаптивно присъединяване, свързана по-горе. С активен този флаг, адаптивният план за присъединяване за нашия пример за изпълнение става следният:
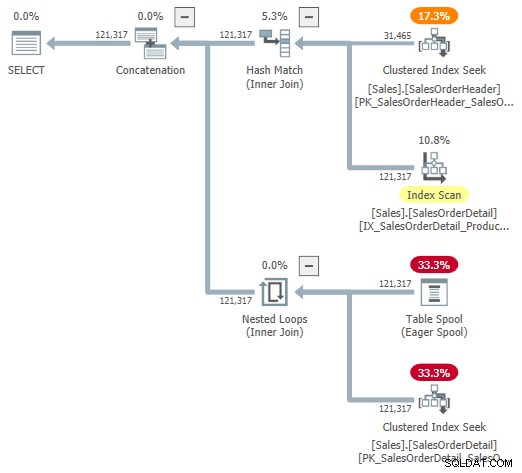
Това е полезно представяне за подпомагане на разбирането, но не е напълно точно, пълно или последователно. Например, Table Spool не съществува – това е представяне по подразбиране за адаптивния четец на буфери четене на редове директно от хеш таблицата в пакетния режим.
Свойствата на оператора и оценките за мощността също са малко навсякъде. Изходът от адаптивния буферен четец („шпула“) трябва да бъде 31 465 реда, а не 121 317. Цената на поддървото на приложението е неправилно ограничена от цената на родителския оператор. Това е нормално за showplan, но няма смисъл в контекста на адаптивно присъединяване.
Има и други несъответствия — твърде много, за да се изброят полезно — но това може да се случи с недокументирани флагове за проследяване. Разширеният план, показан по-горе, не е предназначен за използване от крайни потребители, така че може би не е напълно изненадващо. Посланието тук е да не разчитате твърде много на числата и свойствата, показани в този недокументиран формуляр.
Трябва също така да спомена мимоходом, че готовият стандартен оператор на адаптивен план за присъединяване не е напълно без собствени проблеми с последователността. Те произтичат до голяма степен изключително от скритите детайли.
Например, показаните свойства за адаптивно свързване идват от смес от основните Concat , Присъединяване към хеш и Прилагане оператори. Можете да видите изпълнение на пакетен режим за отчитане на адаптивно присъединяване за присъединяване на вложени цикли (което е невъзможно) и показаното изминало време всъщност се копира от скрития Concat , а не конкретното присъединяване, което се изпълнява по време на изпълнение.
Обикновените заподозрени
Ние можем получите полезна информация от видовете недокументирани флагове за проследяване, които обикновено се използват за разглеждане на изхода на оптимизатора. Например:
ИЗБЕРЕТЕ SOH.SubTotalFROM Sales.SalesOrderHeader КАТО SOHJOIN Sales.SalesOrderDetail КАТО SOD ON SOD.SalesOrderID =SOH.SalesOrderIDWHERE SOH.SalesOrderID <=75123OPTION, (QUERYTRACEON, QUERY80TRA>QUERYTRACEON 360TRA)Изход (силно редактиран за четливост):
*** Изходно дърво:***
PhyOp_ExecutionModeAdapter(BatchToRow) Card=121317 Cost=1,05095
- PhyOp_Concat (партидна) Card=121317 Cost=1,05325
- PhyOp_HashJoinx_jtInner (партида) Card=121317 Cost=1,05083
- PhyOp_Range Sales.SalesOrderHeader Card=31465 Cost=0,54456
- PhyOp_Filter(партидна) карта=121317 Цена=0,397185
- PhyOp_Range Sales.SalesOrderDetail Card=121317 Cost=0,338953
- PhyOp_ExecutionModeAdapter(RowToBatch) Card=121317 Цена=10,0798
- PhyOp_Apply Card=121317 Cost=10,0553
- PhyOp_ExecutionModeAdapter(BatchToRow) Card=31465 Цена=0,544623
- PhyOp_Range Sales.SalesOrderHeader Card=31465 Cost=0,54456 [** 3 **]
- PhyOp_Filter Card=3,85562 Цена=9,00356
- PhyOp_Range Sales.SalesOrderDetail Card=3,85562 Cost=8,94533
- PhyOp_ExecutionModeAdapter(BatchToRow) Card=31465 Цена=0,544623
- PhyOp_Apply Card=121317 Cost=10,0553
Това дава известна представа за приблизителните разходи за случая с пълна кардиналност с хеш и алтернативи за прилагане без писане на отделни заявки и използване на подсказки. Както е споменато в основния текст, тези флагове за проследяване не са ефективни в рамките на CuNewJoinEstimate , така че не можем директно да видим повторните изчисления за случая с 31 465 реда или някоя от подробностите за прогнозите за един ред по този начин.
Обединяване при сливане и хеширане в режим на ред
Адаптивните обединявания предлагат само преход от пакетен режим на хеш присъединяване към приложим режим на ред. За причините, поради които хеш присъединяването в режим на ред не се поддържа, вижте Въпроси и отговори за интелигентна обработка на заявки в раздела Свързано четене. Накратко, смята се, че хеш обединяванията в редовия режим биха били твърде склонни към регресия на производителността.
Превключването към обединяване на редов режим би било друга опция, но в момента оптимизаторът не обмисля това. Доколкото разбирам, е малко вероятно той да бъде разширен в тази посока в бъдеще.
Някои от съображенията са същите като за хеш присъединяване в редов режим. Освен това плановете за обединяване за сливане обикновено са по-малко лесно заменяеми с хеш присъединяване, дори ако се ограничим до индексирано обединяване с обединяване (без изрично сортиране).
Освен това има много по-голяма разлика между хеширане и прилагане, отколкото между хеширане и сливане. Както хеширането, така и обединяването са подходящи за по-големи входове, а приложението е по-подходящо за по-малък вход. Обединяването при сливане не се паралелизира толкова лесно, колкото хеш присъединяването и не се мащабира толкова добре с увеличаване на броя на нишките.
Като се има предвид мотивацията за адаптивни присъединявания е да се справят по-добре с значително различни входни размери — и само хеш обединяването поддържа обработка в пакетен режим — изборът на пакетно хеширане спрямо прилагане на ред е по-естественият. И накрая, наличието на три варианта за адаптивно свързване би усложнило значително изчисляването на прага за потенциално малка печалба.