В тази статия продължавам да проучвам решения за съвпадение на търсенето и предлагането. Благодарим на Лука, Камил Косно, Даниел Браун, Брайън Уокър, Джо Обиш, Райнер Хофман, Пол Уайт, Чарли, Иън и Питър Ларсън за изпращането на вашите решения.
Миналия месец разгледах решения, базирани на преработен подход за интервални пресечки в сравнение с класическия. Най-бързото от тези решения комбинира идеи от Камил, Лука и Даниел. Той обединява две заявки с несвързани предикати, които могат да се сглобяват. Завършването на решението отне 1,34 секунди срещу вход от 400K реда. Това не е твърде изтъркано, като се има предвид, че решението, базирано на класическия подход за пресичане на интервали, отне 931 секунди за изпълнение срещу същия вход. Спомнете си също, че Джо излезе с брилянтно решение, което разчита на класическия подход за пресичане на интервали, но оптимизира логиката на съвпадение чрез разделяне на интервалите въз основа на най-голямата дължина на интервала. Със същия вход от 400K реда, решението на Джо отне 0,9 секунди, за да завърши. Трудната част за това решение е производителността му да се влошава с увеличаване на дължината на най-големия интервал.
Този месец изследвам завладяващи решения, които са по-бързи от решението за преработени кръстовища на Kamil/Luca/Daniel и са неутрални спрямо дължината на интервала. Решенията в тази статия са създадени от Брайън Уокър, Иън, Питър Ларсън, Пол Уайт и мен.
Тествах всички решения в тази статия спрямо входната таблица за търгове със 100K, 200K, 300K и 400K редове и със следните индекси:
-- Индекс за поддръжка на решение СЪЗДАЙТЕ УНИКАЛЕН НЕКЛУСТРИРАН ИНДЕКС idx_Code_ID_i_Quantity ON dbo.Auctions(Code, ID) INCLUDE(Quantity); -- Активиране на пакетен режим Window Aggregate CREATE NONCLUSTERED COLUMNSTORE INDEX idx_cs НА dbo.Auctions(ID) КЪДЕТО ID =-1 И ID =-2;
Когато описвам логиката зад решенията, ще приема, че таблицата за търгове е попълнена със следния малък набор от примерни данни:
ID код Количество----------- ---- ---------1 D 5.0000002 D 3.0000003 D 8.0000005 D 2.0000006 D 8.0000007 D 4.0000008 D 2.0000008 D 2.00000000.600 S00000000000000000000 2,0000004000 S 2,0000005000 S 4,0000006000 S 3,0000007000 S 2,000000
Следва желаният резултат за тези примерни данни:
DemandID SupplyID TradeQuantity----------- ----------- --------------1 1000 5.0000002 1000 3.0000003 2000 6.0000003 3000 2,0000005 4000 2,0000006 5000 4,0000006 6000 3,0000006 7000 1,0000007 7000 1,000000
Решението на Брайън Уокър
Външните съединения се използват доста често в решенията за SQL заявки, но далеч, когато ги използвате, използвате едностранни. Когато преподавам за външни присъединявания, често получавам въпроси, изискващи примери за практически случаи на използване на пълни външни съединения, а те не са толкова много. Решението на Брайън е красив пример за практична употреба на пълни външни съединения.
Ето пълния код на решението на Брайън:
ПУСНЕТЕ ТАБЛИЦА, АКО СЪЩЕСТВУВА #MyPairings; CREATE TABLE #MyPairings( DemandID INT NOT NULL, SupplyID INT NOT NULL, TradeQuantity DECIMAL(19,06) NOT NULL); С D AS( ИЗБЕРЕТЕ A.ID, SUM(A.Quantity) НАД (РАЗДЕЛЯНЕ ПО A.Code ПОРЪЧАЙТЕ ПО A.ID РЕДОВЕ НЕОГРАНИЧЕНИ ПРЕДШЕСТВАЩИ) КАТО Изпълнява се ОТ dbo.Auctions КАТО КЪДЕ A.Code ='D'),S AS( ИЗБЕРЕТЕ A.ID, SUM(A.Quantity) OVER (РАЗДЕЛЯНЕ ПО A.Code ПОРЪЧАЙТЕ ПО A.ID РЕДОВЕ, НЕОГРАНИЧЕНИ ПРЕДШЕСТВАЩИ) AS Изпълнява се ОТ dbo.Auctions КАТО КЪДЕ A.Code ='S'),W AS( ИЗБЕРЕТЕ D.ID КАТО DemandID, S.ID КАТО SupplyID, ISNULL(D.Running, S.Running) КАТО ИЗПЪЛНЕНИЕ ОТ D FULL JOIN S ON D.Running =S.Running),Z AS( ИЗБЕРЕТЕ СЛУЧАЙ, КОГАТО W.DemandID Е NOT NULL ТОГАВА W.DemandID ELSE MIN(W.DemandID) НАД (ПОРЪЧКА ОТ W.Running ROWS МЕЖДУ ТЕКУЩ РЕД И НЕОГРАНИЧЕН СЛЕДВАЩ) КРАЙ КАТО DemandID, СЛУЧАЙ, КОГАТО W.SupplyID НЕ Е NULL ТОГАВА W.SupplyID(W.ELSEupplyW. ) НАД (ПОРЪЧКА ОТ W.Изпълняващи се РЕДОВЕ МЕЖДУ ТЕКУЩИЯ РЕД И НЕОГРАНИЧЕНО СЛЕДВАНЕ) КРАЙ КАТО SupplyID, W.Running FROM W)INSERT #MyPair ings( DemandID, SupplyID, TradeQuantity) ИЗБЕРЕТЕ Z.DemandID, Z.SupplyID, Z.Running - ISNULL(LAG(Z.Running) OVER (ORDER BY Z.Running), 0.0) КАТО TradeQuantity ОТ Z, КЪДЕТО Z.DemandID НЕ Е НЕ Е. NULL И Z.SupplyID НЕ Е NULL;
Преразгледах първоначалното използване на Брайън на извлечени таблици с CTE за яснота.
CTE D изчислява текущите количества на общото търсене в колона с резултати, наречена D.Running, а CTE S изчислява текущите общи количества за предлагане в колона с резултати, наречена S.Running. След това CTE W извършва пълно външно свързване между D и S, съпоставяйки D.Running с S.Running и връща първото не-NULL между D.Running и S.Running като W.Running. Ето резултата, който получавате, ако заявите всички редове от W, подредени от Running:
DemandID SupplyID Running---------- ----------- ----------1 NULL 5.0000002 1000 8.000000NULL 2000 14.0000003 3000 16.0000005 4000 18.00000 NULL 5000 22.000000NULL 6000 25.0000006 NULL 26.000000NULL 7000 27.0000007 NULL 30.0000008 NULL 32.000000Идеята да се използва пълно външно свързване, базирано на предикат, който сравнява текущите суми на търсенето и предлагането, е гениална! Повечето редове в този резултат – първите 9 в нашия случай – представляват сдвояване на резултати с липсващи малко допълнителни изчисления. Редове с крайни NULL ID от един от видовете представляват записи, които не могат да бъдат съпоставени. В нашия случай последните два реда представляват записи за търсене, които не могат да бъдат съпоставени с записи за предлагане. И така, това, което остава тук, е да се изчисли DemandID, SupplyID и TradeQuantity на двойките на резултатите и да се филтрират записи, които не могат да бъдат съпоставени.
Логиката, която изчислява резултата DemandID и SupplyID, се извършва в CTE Z, както следва (приемайки подреждане в W чрез Running):
- DemandID:ако DemandID не е NULL, тогава DemandID, в противен случай минималният DemandID, започващ с текущия ред
- SupplyID:ако SupplyID не е NULL, тогава SupplyID, в противен случай минималният SupplyID, започващ с текущия ред
Ето резултата, който получавате, ако заявите Z и подредите редовете чрез Изпълнение:
DemandID SupplyID Running---------- ----------- ----------1 1000 5,0000002 1000 8,0000003 2000 14,0000003 3000 16,0000005 4000 18,000 000 000 22.0000006 6000 25.0000006 7000 26.0000007 7000 27.0000007 NULL 30.0000008 NULL 32.000000
Външната заявка филтрира редове от Z, представляващи записи от един вид, които не могат да бъдат съпоставени с записи от друг вид, като гарантира, че както DemandID, така и SupplyID не са NULL. Търговското количество на резултатните сдвоения се изчислява като текущата текуща стойност минус предишната текуща стойност с помощта на LAG функция.
Ето какво се записва в таблицата #MyPairings, което е желаният резултат:
DemandID SupplyID TradeQuantity----------- ----------- --------------1 1000 5.0000002 1000 3.0000003 2000 6.0000003 3000 2,0000005 4000 2,0000006 5000 4,0000006 6000 3,0000006 7000 1,0000007 7000 1,000000
Планът за това решение е показан на Фигура 1.
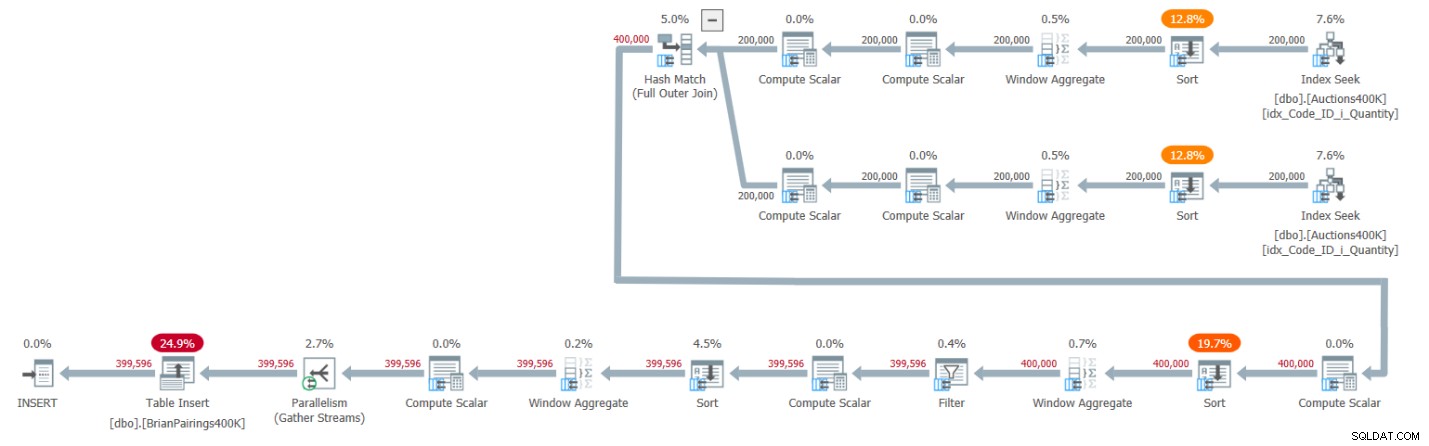 Фигура 1:План за заявка за решението на Брайън
Фигура 1:План за заявка за решението на Брайън
Горните два клона на плана изчисляват текущите суми за търсене и предлагане, използвайки оператор на пакетен режим Window Aggregate, всеки след извличане на съответните записи от поддържащия индекс. Както обясних в по-ранни статии от поредицата, тъй като индексът вече има редовете, подредени така, както трябва да бъдат операторите на Window Aggregate, бихте си помислили, че не трябва да се изискват изрични оператори за сортиране. Но SQL Server понастоящем не поддържа ефективна комбинация от паралелни операции с индекс за запазване на реда преди оператора Window Aggregate в паралелен пакетен режим, така че в резултат на това изричен паралелен оператор за сортиране предхожда всеки от паралелните оператори Window Aggregate.
Планът използва хеш присъединяване в пакетен режим за обработка на пълното външно присъединяване. Планът също така използва два допълнителни оператора Window Aggregate в пакетен режим, предшествани от изрични оператори за сортиране, за да се изчислят функциите на прозореца MIN и LAG.
Това е доста ефективен план!
Ето времето за изпълнение, което получих за това решение спрямо входни размери, вариращи от 100K до 400K редове, за секунди:
100K:0,368200K:0,845300K:1,255400K:1,315
Решението на Itzik
Следващото решение на предизвикателството е един от опитите ми да го реша. Ето пълния код на решението:
ПУСНЕТЕ ТАБЛИЦА, АКО СЪЩЕСТВУВА #MyPairings; С C1 AS( SELECT *, SUM(Quantity) OVER(PARTITION BY Код ПОРЪЧКА ПО ИД РЕДОВ НЕОГРАНИЧЕН ПРЕДИШНИ) КАТО SumQty ОТ dbo.Auctions),C2 AS( SELECT *, SUM(Quantity * CASE Code WHEN 'D' THEN -1 КОГАТО 'S' THEN 1 END) НАД (ПОРЪЧКА ПО SumQty, кодови РЕДОВЕ НЕОГРАНИЧЕНИ ПРЕДШЕСТВА) КАТО ниво на наличност, МИГА (SumQty, 1, 0.0) НАД (РЕД ПО SumQty, код) КАТО PrevSumQty, MAX(CASE, КОГАТО Код ='D' СЛЕД ИД КРАЙ) НАД (ПОРЪЧКА ПО SumQty, Код РЕДОВЕ НЕОГРАНИЧЕНИ ПРЕДИШНИ) КАТО PrevDemandID, MAX(СЛУЧАЙ, КОГАТО Код ='S' ТОГАВА ИД КРАЙ) НАД (ПОРЪЧКА ПО SumQty, Код РЕДОВЕ НЕОГРАНИЧЕНИ ПРЕДШЕСТВА) КАТО PrevSupplyID, WHMIN Code( ='D' THEN ID END) НАД (ПОРЕД ОТ SumQty, РЕДОВЕ КОДОВЕ МЕЖДУ ТЕКУЩ РЕД И НЕОГРАНИЧЕН СЛЕДВАЩ) КАТО NextDemandID, MIN(СЛУЧАЙ, КОГАТО Код ='S' ТОГАВА ИД КРАЙ) НАД (ПОРЕД ПО SumQty, РЕДОВЕ КОДОВЕ МЕЖДУ МЕЖДУ И НЕОГРАНИЧЕН СЛЕДВАЩ) КАТО NextSupplyID ОТ C1),C3 AS( SELECT *, CASE Code WHEN 'D ' THEN ID WHEN 'S' THEN CASE WHEN StockLevel> 0 THEN NextDemandID ELSE PrevDemandID END END КАТО DemandID, CASE Code WHEN 'S' THEN ID WHEN 'D' THEN CASE WHEN StockLevel <=0 THEN NextSupplyID END AS DemandID, CASE Code WHEN 'S' THEN ID WHEN 'D' THEN CASE WHEN StockLevel <=0 THEN NextSupplyID END AS ELSE PrevENDSu SumQty - PrevSumQty КАТО TradeQuantity ОТ C2)ИЗБЕРЕТЕ DemandID, SupplyID, TradeQuantityINTO #MyPairingsFROM C3WHERE TradeQuantity> 0.0 И DemandID НЕ Е NULL И SupplyID НЕ Е NULL;
CTE C1 отправя заявка към таблицата Auctions и използва прозоречна функция, за да изчисли текущото общо количество търсене и предлагане, като извиква колоната за резултат SumQty.
CTE C2 отправя заявка към C1 и изчислява редица атрибути, използвайки функции на прозореца въз основа на SumQty и подреждане на кода:
- Ниво на склад:Текущото ниво на склад след обработка на всеки запис. Това се изчислява чрез присвояване на отрицателен знак на количествата на търсенето и положителен знак на количествата на предлагане и сумиране на тези количества до и включително текущия запис.
- PrevSumQty:стойност SumQty на предишния ред.
- PrevDemandID:Последен идентификатор на търсене, който не е NULL.
- PrevSupplyID:Последен идентификатор на доставка, различен от NULL.
- NextDemandID:Следващ идентификатор на търсене, който не е NULL.
- NextSupplyID:Следващ идентификатор на доставка, който не е NULL.
Ето съдържанието на C2, подредено от SumQty и Code:
ID код Количество SumQty StockLevel PrevSumQty PrevDemandID PrevSupplyID NextDemandID Следващ идентификатор на доставка ---- ---- --------- ---------- --------- -- ----------- ------------ ------------ ------------ - ----------- 1 D 5.000000 5.000000 -5.000000 0.000000 1 NULL 1 10002 D 3.000000 8.000000 -8.000000 5.000000 2 NULL 2 10001000 S 8.000000 8.000000 0.000000 8.000000 2 1000 3 10002000 S 6.000000 14.000000 6.0000.000000 2 2000 3 20003 D 8.000000 16.000000 -2.000000 14.000000 3 2000 3 30003000 S 2.000000 16.000000 0.000000 16.000000 3 3000 5 30005 D 2.000000 18.000000 -2.000000 16.000000 5 3000 5 40004000 S 2.000000 18.000000 0.000000 18.000000 5 4000 6 40005000 S 4.000000 22.000000 4.000000 18.000000 5 5000 6 50006000 S 3.000000 25.000000 7.000000 22.000000 5 6000 6 60006 D 8.000000 26.000000 -1.000000 25.000000 6 6000 6 70007000 S 2.000000 27.000000 1.000000 26.000000 6 7000 7 70007 D 4.000000 30.000000 -3.000000 27.000000 7 7000 7 NULL8 D 2.000000 32,000000 -5,000000 30,000000 8 7000 8 NULL
CTE C3 отправя заявка към C2 и изчислява сдвояванията на резултата DemandID, SupplyID и TradeQuantity, преди да премахне някои излишни редове.
Резултатът колона C3.DemandID се изчислява така:
- Ако текущият запис е запис за търсене, върнете DemandID.
- Ако текущият запис е запис за доставка и текущото ниво на наличност е положително, върнете NextDemandID.
- Ако текущият запис е запис за доставка и текущото ниво на наличност не е положително, върнете PrevDemandID.
Резултатът колона C3.SupplyID се изчислява по следния начин:
- Ако текущият запис е запис за доставка, върнете SupplyID.
- Ако текущият запис е запис за търсене и текущото ниво на запасите не е положително, върнете NextSupplyID.
- Ако текущият запис е запис за търсене и текущото ниво на запасите е положително, върнете PrevSupplyID.
Резултатът TradeQuantity се изчислява като SumQty на текущия ред минус PrevSumQty.
Ето съдържанието на колоните, свързани с резултата от C3:
DemandID SupplyID TradeQuantity----------- ----------- --------------1 1000 5.0000002 1000 3.0000002 1000 0.0000003 2000 6.0000003 3000 2.0000003 3000 0.0000005 4000 2.0000005 4000 0.0000006 5000 4.0000006 6000 3.0000006 7000 1.0000007 7000 1.0000007 NULL 3.0000008 NULL 2.000000
Това, което остава на външната заявка, е да филтрира излишните редове от C3. Те включват два случая:
- Когато текущите суми и от двата вида са еднакви, записът за доставка има нулево търгуемо количество. Не забравяйте, че поръчката се основава на SumQty и Code, така че когато текущите суми са еднакви, записът за търсене се появява преди записа за предлагане.
- Завършващи записи от един вид, които не могат да бъдат съпоставени със записи от друг вид. Такива записи са представени от редове в C3, където или DemandID е NULL, или SupplyID е NULL.
Планът за това решение е показан на Фигура 2.
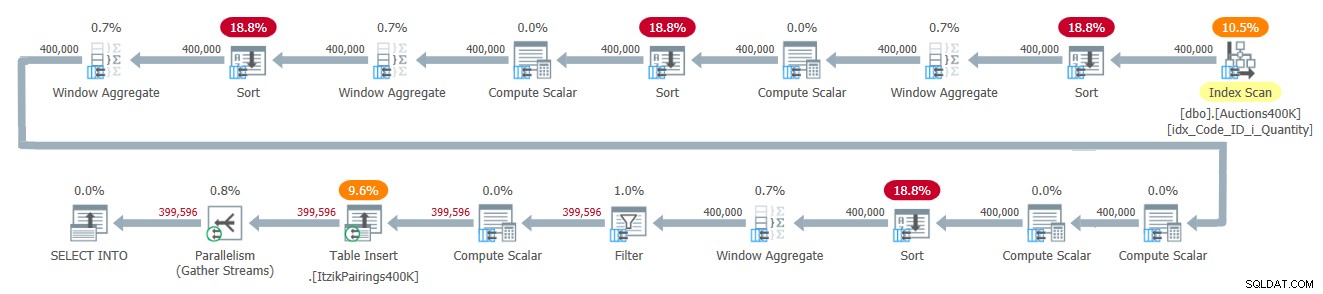 Фигура 2:План на заявка за решението на Itzik
Фигура 2:План на заявка за решението на Itzik
Планът прилага едно преминаване върху входните данни и използва четири оператора Window Aggregate в пакетен режим за обработка на различните прозоречни изчисления. Всички оператори Window Aggregate са предшествани от изрични оператори за сортиране, въпреки че само два от тях са неизбежни тук. Другите две са свързани с текущата реализация на оператора Window Aggregate в паралелен пакетен режим, който не може да разчита на паралелен вход, запазващ реда. Прост начин да видите кои оператори за сортиране се дължат на тази причина е да наложите сериен план и да видите кои оператори за сортиране изчезват. Когато принудя сериен план с това решение, първият и третият оператор за сортиране изчезват.
Ето времето за изпълнение в секунди, което получих за това решение:
100K:0,246200K:0,427300K:0,616400K:0,841>
Решението на Иън
Решението на Иън е кратко и ефективно. Ето пълния код на решението:
ПУСНЕТЕ ТАБЛИЦА, АКО СЪЩЕСТВУВА #MyPairings; С A AS ( ИЗБЕРЕТЕ *, СУМА(Количество) НАД (РАЗДЕЛЯНЕ ПО код ПОРЪЧКА ПО ИД РЕДОВЕ НЕОГРАНИЧЕНИ ПРЕДШЕСТВА) КАТО Кумулативно количество ОТ dbo.Auctions), B AS ( ИЗБЕРЕТЕ Кумулативно количество, Кумулативно количество - LAG(CumulativeQuantity, SOVER 0), OVER BY CumulativeQuantity) AS TradeQuantity, MAX(CASE WHEN Code ='D' THEN ID END) AS DemandID, MAX(CASE WHEN Code ='S' THEN ID END) КАТО SupplyID ОТ ГРУПА ПО Кумулативно количество, ID/ID -- фалшиво групиране за подобряване на оценката на редовете -- (брой редове на търгове вместо 2 реда)), C AS ( -- попълнете NULL със следващото предлагане/търсене -- FIRST_VALUE(ID) ИГНОРИРАНЕ НА НУЛИ НАД... -- би било по-добре, но това ще работи, защото идентификаторите са в кумулативно количество. ИЗБЕРЕТЕ MIN(DemandID) НАД (РЕД ПО КУМУЛАТИВНО КОЛИЧЕСТВО РЕДОВЕ МЕЖДУ ТЕКУЩ РЕД И НЕОГРАНИЧЕН СЛЕДВАЩ) КАТО DemandID, MIN(SupplyID) НАД (ПОРЪЧКА ПО Кумулативна Q uantity РЕДОВЕ МЕЖДУ ТЕКУЩ РЕД И НЕОГРАНИЧЕН СЛЕДВАЩ) КАТО SupplyID, TradeQuantity ОТ B)ИЗБЕРЕТЕ DemandID, SupplyID, TradeQuantityINTO #MyPairingsFROM CWHERE SupplyID НЕ Е NULL -- изрежете неизпълнените изисквания IS И NOT; -- отрежете неизползваните консумативи
Кодът в CTE A отправя заявка към таблицата на търговете и изчислява текущите количества на общото търсене и предлагане с помощта на прозоречна функция, именувайки колоната за резултат Кумулативно количество.
Кодът в CTE B отправя заявка към CTE A и групира редовете по CumulativeQuantity. Това групиране постига подобен ефект на външното присъединяване на Брайън въз основа на текущите суми на търсенето и предлагането. Иън също добави фиктивния израз ID/ID към набора за групиране, за да подобри първоначалната мощност на групирането под оценка. На моята машина това също доведе до използване на паралелен план вместо сериен.
В списъка SELECT кодът изчислява DemandID и SupplyID, като извлича идентификатора на съответния тип запис в групата, използвайки MAX агрегата и CASE израз. Ако идентификационният номер не присъства в групата, резултатът е NULL. Кодът също така изчислява колона за резултат, наречена TradeQuantity като текущото кумулативно количество минус предишното, извлечено с помощта на функцията на прозореца LAG.
Ето съдържанието на B:
CumulativeQuantity TradeQuantity DemandId SupplyId------------------------ -------------- --------- - -------- 5.000000 5.000000 1 NULL 8.000000 3.000000 2 100014.000000 6.000000 NULL 200016.000000 2.000000 3 300018.000000 2.000000 5 400022.000000 4.000000 NULL 500025.000000 3.000000 NULL 600026.000000 1.000000 6 NULL27.000000 1.000000 NULL 700030.000000 3.000000 7 NULL32.000000 2.000000 8 NULL
След това кодът в CTE C отправя заявка към CTE B и попълва NULL идентификатори на търсене и предлагане със следващите идентификатори на търсене и предлагане, които не са NULL, като използва функцията на прозореца MIN с рамката РЕДОВЕ МЕЖДУ ТЕКУЩ РЕД И НЕОБГРАНИЧЕН СЛЕД.
Ето съдържанието на C:
DemandID SupplyID TradeQuantity --------- --------- --------------1 1000 5,000000 2 1000 3,000000 3 2000 6,000000 3 3000 2,000000 5 4000 2.000000 6 5000 4.000000 6 6000 3.000000 6 7000 1.000000 7 7000 1.000000 7 NULL 3.000000 8 NULL 3.000000 8 0 0Последната стъпка, обработвана от външната заявка срещу C, е да се премахнат записи от един вид, които не могат да бъдат съпоставени с записи от друг вид. Това се прави чрез филтриране на редове, където SupplyID е NULL или DemandID е NULL.
Планът за това решение е показан на Фигура 3.
Фигура 3:План за заявка за решението на Иън
Този план извършва едно сканиране на входните данни и използва три паралелни оператора за агрегатен прозорец в пакетен режим за изчисляване на различните функции на прозореца, всички предшествани от паралелни оператори за сортиране. Две от тях са неизбежни, както можете да проверите, като наложите сериен план. Планът също така използва оператор Hash Aggregate за обработка на групирането и агрегирането в CTE B.
Ето времето за изпълнение в секунди, което получих за това решение:
100K:0,214200K:0,363300K:0,546400K:0,701
Решението на Питър Ларсон
Решението на Питър Ларсън е невероятно кратко, сладко и високоефективно. Ето пълния код на решението на Питър:
ПУСНЕТЕ ТАБЛИЦА, АКО СЪЩЕСТВУВА #MyPairings; С cteSource(ID, Code, RunningQuantity)AS( SELECT ID, Code, SUM(Quantity) OVER (PARTITION BY Code ORDER BY ID) КАТО RunningQuantity ОТ dbo.Auctions)ИЗБЕРЕТЕ DemandID, SupplyID, TradeQuantityINTO #MyPairingsFROM (ИЗБИРАНЕ НА КОЛИЧЕСТВО Код ='D' THEN ID ELSE 2147483648 END) НАД (ПОРЕД ОТ RunningQuantity, Код РЕДОВ МЕЖДУ ТЕКУЩ РЕД И НЕОГРАНИЧЕН СЛЕДВАЩ) КАТО DemandID, MIN(СЛУЧАЙ, КОГАТО Код ='S' THEN ID ELSE ELSE 21478, Running Кодови РЕДОВЕ МЕЖДУ ТЕКУЩ РЕД И НЕОБГРАНИЧЕН СЛЕД) КАТО идентификатор на доставка, текущо количество - КОАЛЕСЦИРАНЕ(ЗАСТАВКА(Текущо количество) НАД (ПОРЕД ОТ текущо количество, код), 0.0) КАТО търговско количество ОТ cteSource ID ) КАТО идентификатор на доставката ) КАТО идентификационен номер на източника ) КАТО идентификатор на търсенето на cteSource ) 4AND2308 TRADLY 4AND2308CTE cteSource отправя заявка към таблицата Auctions и използва прозоречна функция, за да изчисли текущото общо количество търсене и предлагане, като извиква колоната за резултат RunningQuantity.
Кодът, дефиниращ извлечената таблица d, отправя заявка към cteSource и изчислява DemandID, SupplyID и TradeQuantity на сдвоените резултати, преди да премахне някои излишни редове. Всички функции на прозореца, използвани в тези изчисления, се основават на RunningQuantity и подреждане на кода.
Резултатната колона d.DemandID се изчислява като минимален идентификатор на търсенето, започвайки с текущия или 2147483648, ако не е намерен такъв.
Резултатната колона d.SupplyID се изчислява като минимален идентификатор на доставка, започващ с текущия или 2147483648, ако не е намерен такъв.
Резултатът TradeQuantity се изчислява като стойност RunningQuantity на текущия ред минус стойността RunningQuantity на предишния ред.
Ето съдържанието на d:
DemandID SupplyID TradeQuantity--------------- ----------- --------------1 1000 5.0000002 1000 3.0000003 1000 0.0000003 2000 6.0000003 3000 2.0000005 3000 0.0000005 4000 2.0000006 4000 0.0000006 5000 4.0000006 6000 3.0000006 7000 1.0000007 7000 1.0000007 2147483648 3.0000008 2147483648 2.000000Това, което остава на външната заявка, е да филтрира излишните редове от d. Това са случаи, когато търгуваното количество е нула или записи от един вид, които не могат да бъдат съпоставени с записи от другия вид (с идентификационен номер 2147483648).
Планът за това решение е показан на Фигура 4.
Фигура 4:План на заявка за решението на Питър
Подобно на плана на Иън, планът на Питър разчита на едно сканиране на входните данни и използва три паралелни прозоречни агрегати в пакетен режим за изчисляване на различните функции на прозореца, всички предшествани от паралелни оператори за сортиране. Две от тях са неизбежни, както можете да проверите, като наложите сериен план. В плана на Питър няма нужда от групиран агрегатен оператор, както в плана на Иън.
Критичното прозрение на Питър, което позволи такова кратко решение, е осъзнаването, че за съответен запис от който и да е от видовете, съответстващият идентификатор от другия вид винаги ще се появява по-късно (въз основа на RunningQuantity и подреждане на кода). След като видях решението на Питър, определено имах чувството, че преусложних нещата в моето!
Ето времето за изпълнение в секунди, което получих за това решение:
100K:0,197200K:0,412300K:0,558400K:0,696
Решението на Пол Уайт
Последното ни решение е създадено от Пол Уайт. Ето пълния код на решението:
ПУСНЕТЕ ТАБЛИЦА, АКО СЪЩЕСТВУВА #MyPairings; CREATE TABLE #MyPairings( DemandID integer NOT NULL, SupplyID integer NOT NULL, TradeQuantity decimal(19, 6) NOT NULL);GO INSERT #MyPairings WITH (TABLOCK)(DemandID, SupplyID, TradeQuantity,DemandSQuantly)SELECT Q3. Q3.TradeQuantityFROM ( SELECT Q2.DemandID, Q2.SupplyID, TradeQuantity =-- Интервално припокриване CASE WHEN Q2.Code ='S' THEN CASE WHEN Q2.CumDemand>=Q2.IntEnd THEN Q2.IntLength WHEN Q2.Cum. IntStart THEN Q2.CumDemand - Q2.IntStart ELSE 0.0 END WHEN Q2.Code ='D' THEN CASE WHEN Q2.CumSupply>=Q2.IntEnd THEN Q2.IntLength КОГАТО Q2.CumSupply> Q2.CumSupply> Q2.Intly. IntStart ELSE 0.0 КРАЙ КРАЙ ОТ ( SELECT Q1.Code, Q1.IntStart, Q1.IntEnd, Q1.IntLength, DemandID =MAX(IIF(Q1.Code ='D', Q1.ID, 0)) НАД ( ПОРЪДКА ПО Q1.IntStart, Q1.ID РЕДОВЕ НЕОГРАНИЧЕНИ PRECEDING), SupplyID =MAX(IIF(Q1.Code ='S', Q1.ID, 0)) НАД ( ПОРЪДКА ПО Q1.IntStart, Q1.ID РЕДОВЕ НЕОГРАНИЧЕНИ ПРЕДШЕСТВАЩА), CumSupply =SUM(IIF(Q1.Code ='S', Q1.IntLength, 0)) НАД (ПОРЕД ОТ Q1.IntStart, Q1.ID РЕДОВЕ НЕОГРАНИЧЕНИ ПРЕДШЕСТВАЩ), CumDemand =SUM(IIF(Q1.Code ='D', Q1.IntLength, 0)) НАД ( ПОРЪЧАЙТЕ ПО Q1.IntStart, Q1.ID РЕДОВЕ НЕОГРАНИЧЕНИ ПРЕДШЕСТВАЩО) ОТ ( -- Интервали на търсенето ИЗБЕРЕТЕ A.ID, A.Code, IntStart =SUM(A.Quantity) НАД ( ПОРЪЧАЙТЕ ПО РЕДОВЕ ЗА A.ID НЕОГРАНИЧЕНИ ПРЕДШЕСТВА) - A. количество, IntEnd =SUM(A.Quantity) НАД (ПОРЪЧКА ПО A.ID РЕДОВЕ НЕОГРАНИЧЕНИ ПРЕДШЕСТВАЩИ), IntLength =A.Quantity ОТ dbo.Auctions КАТО A.Code ='D' UNION ALL -- Интервали на доставка ИЗБЕРЕТЕ A.ID, A.Code, IntStart =SUM(A.Quantity) НАД ( ПОРЪДКА ОТ A.ID РЕДОВЕ НЕОГРАНИЧЕНИ ПРЕДШЕСТВА) - A.Quantity, IntEnd =SUM(A.Quantity) НАД ( ПОРЪДКА ПО A.ID РЕДОВЕ НЕОГРАНИЧЕНИ ПРЕДШЕСТВА), IntLength =A.Quantity FROM dbo.Auctions AS A WHERE A.Code ='S') AS Q1) AS Q2) AS Q3WHERE Q3.TradeQuantity> 0;Кодът, дефиниращ извлечената таблица Q1, използва две отделни заявки за изчисляване на интервалите на търсене и предлагане въз основа на текущи суми и обединява двете. За всеки интервал кодът изчислява неговото начало (IntStart), край (IntEnd) и дължина (IntLength). Ето съдържанието на Q1, подредено от IntStart и ID:
ID Code IntStart IntEnd IntLength----- ---- ---------- ---------- ----------1 D 0.000000 5.000000 5.0000001000 S 0.000000 8.000000 8.0000002 D 5.000000 8.000000 3.0000003 D 8.000000 16.000000 8.0000002000 S 8.000000 14.000000 6.0000003000 S 14.000000 16.000000 2.0000005 D 16.000000 18.000000 2.0000004000 S 16.000000 18.000000 2.0000006 D 18.000000 26.000000 8.0000005000 S 18.000000 22.000000 4.0000006000 S 22.000000 25.000000 3.0000007000 S 25.000000 27.000000 2.0000007 D 26.000000 30.000000 4.0000008 D 30,000000 32,000000 2,000000Кодът, дефиниращ извлечената таблица Q2, отправя заявки към Q1 и изчислява колони с резултати, наречени DemandID, SupplyID, CumSupply и CumDemand. Всички функции на прозореца, използвани от този код, се основават на подреждането на IntStart и ID и на рамката ROWS UNBOUNDED PRECEDING (всички редове до текущата).
DemandID е максималният идентификатор на търсенето до текущия ред или 0, ако такъв не съществува.
SupplyID е максималният идентификатор на доставките до текущия ред или 0, ако такъв не съществува.
CumSupply е кумулативните количества на доставките (дължини на интервала на доставка) до текущия ред.
CumDemand е кумулативните количества на търсенето (дължини на интервала на търсене) до текущия ред.
Ето съдържанието на Q2:
Code IntStart IntEnd IntLength DemandID SupplyID CumSupply CumDemand---- ---------- ---------- ---------- ----- ---- --------- ---------- ----------D 0,000000 5,000000 5,000000 1 0 0,000000 5,000000S 0,000000 8,000000 8,000000 1 10000000000000000 5.000000 8.000000 3.000000 2 1000 8.000000 8.000000D 8.000000 16.000000 8.000000 3 1000 8.000000 16.000000S 8.000000 14.000000 6.000000 3 2000 14.000000 16.000000S 14.000000 16.000000 2.000000 3 3000 16.000000 16.000000D 16.000000 18.000000 2.000000 5 3000 16.000000 18.000000S 16.000000 18.000000 2.000000 5 4000 18.000000 18.000000D 18.000000 26.000000 8.000000 6 4000 18.000000 26.000000S 18.000000 22.000000 4.000000 6 5000 22.000000 26.000000 26.000000S 000000000 00 00 00 00 00 00 00 00 00 00 00. 25.000000 26.000000S 25.000000 27.000000 2.000000 6 7000 27.000000 26.000000D 26.000000 30.000000 4.000000 7 7000 27.000000 30.000000D 30.000000 32.000000 2.000000 8 7000 27.000000 32.000000Q2 already has the final result pairings’ correct DemandID and SupplyID values. The code defining the derived table Q3 queries Q2 and computes the result pairings’ TradeQuantity values as the overlapping segments of the demand and supply intervals. Finally, the outer query against Q3 filters only the relevant pairings where TradeQuantity is positive.
The plan for this solution is shown in Figure 5.
Figure 5:Query plan for Paul’s solution
The top two branches of the plan are responsible for computing the demand and supply intervals. Both rely on Index Seek operators to get the relevant rows based on index order, and then use parallel batch-mode Window Aggregate operators, preceded by Sort operators that theoretically could have been avoided. The plan concatenates the two inputs, sorts the rows by IntStart and ID to support the subsequent remaining Window Aggregate operator. Only this Sort operator is unavoidable in this plan. The rest of the plan handles the needed scalar computations and the final filter. That’s a very efficient plan!
Here are the run times in seconds I got for this solution:
100K:0.187200K:0.331300K:0.369400K:0.425These numbers are pretty impressive!
Performance Comparison
Figure 6 has a performance comparison between all solutions covered in this article.
Figure 6:Performance comparison
At this point, we can add the fastest solutions I covered in previous articles. Those are Joe’s and Kamil/Luca/Daniel’s solutions. The complete comparison is shown in Figure 7.
Figure 7:Performance comparison including earlier solutions
These are all impressively fast solutions, with the fastest being Paul’s and Peter’s.
Заключение
When I originally introduced Peter’s puzzle, I showed a straightforward cursor-based solution that took 11.81 seconds to complete against a 400K-row input. The challenge was to come up with an efficient set-based solution. It’s so inspiring to see all the solutions people sent. I always learn so much from such puzzles both from my own attempts and by analyzing others’ solutions. It’s impressive to see several sub-second solutions, with Paul’s being less than half a second!
It's great to have multiple efficient techniques to handle such a classic need of matching supply with demand. Well done everyone!
[ Jump to:Original challenge | Solutions:Part 1 | Part 2 | Part 3 ]