В тази статия ще разгледаме оператора „APPLY“ и неговите вариации – CROSS APPLY и OUTER APPLY заедно с примери за това как могат да се използват.
По-специално ще научим:
- разликата между CROSS APPLY и клаузата JOIN
- как да обедините изхода на SQL заявки с функции, оценени в таблица
- как да идентифицирате проблеми с производителността чрез запитване за динамични изгледи за управление и функции за динамично управление.
Какво е клаузата APPLY
Microsoft въведе оператора APPLY в SQL Server 2005. Операторът APPLY е подобен на клаузата T-SQL JOIN, тъй като също така ви позволява да обедините две таблици – например можете да присъедините външна таблица с вътрешна таблица. Операторът APPLY е добра опция, когато от една страна имаме оценен от таблица израз, който искаме да оценим за всеки ред от таблицата, която имаме от друга страна. И така, дясната таблица се обработва за всеки ред от лявата таблица. Първо се оценява лявата таблица, а след това дясната таблица се оценява спрямо всеки ред от лявата таблица, за да се генерира крайния набор от резултати. Крайният набор от резултати включва всички колони от двете таблици.
Операторът APPLY има два варианта:
- КРЪСТНО ПРИЛАГАНЕ
- ВЪНШНО ПРИЛАГАНЕ
КРЪСТНО ПРИЛАГАНЕ
CROSS APPLY е подобно на INNER JOIN, но може да се използва и за свързване на оценени от таблица функции със SQL таблици. Крайният изход на CROSS APPLY се състои от записи, съвпадащи между изхода на функция, оценена на таблица, и SQL таблица.
ВЪНШНО ПРИЛАГАНЕ
OUTER APPLY прилича на LEFT JOIN, но има възможност за свързване на оценени от таблица функции със SQL таблици. Крайният изход на OUTER APPLY съдържа всички записи от лявата таблица или функцията, оценена от таблицата, дори ако те не съвпадат със записите в дясната таблица или функцията с таблица.
Сега нека обясня и двата варианта с примери.
Примери за употреба
Подготовка на демонстрационната настройка
За да подготвите демонстрационна настройка, ще трябва да създадете таблици с имена „Служители“ и „Отдел“ в база данни, която ще наречем „DemoDatabase“. За да направите това, изпълнете следния код:
ИЗПОЛЗВАЙТЕ БАЗА ДЕМОДАННИ GO CREATE TABLE [DBO].[СЛУЖИТЕЛИ] ( [ИМЕ НА СЛУЖИТЕЛ] [VARCHAR](MAX) NULL, [ДАТА НА РОЖДЕНИЕ] [DATETIME] NULL, [JOBTITLE] [VARCHAR](150) NULL, [EMAILID] [ VARCHAR](100) NULL, [PHONENUMBER] [VARCHAR](20) NULL, [HIREDATE] [DATETIME] NULL, [DEPARTMENTID] [INT] NULL ) ОТМИНЕТЕ СЪЗДАЙТЕ ТАБЛИЦА [DBO].[ОТДЕЛ] ( [ОТДЕЛ] INT ИДЕНТИФИКАЦИЯ (1, 1), [DEPARTMENTNAME] [VARCHAR](MAX) NULL ) GO
След това поставете някои фиктивни данни в двете таблици. Следният скрипт ще вмъкне данни в „Служител с ” таблица:
[expand title =”ПЪЛНА ЗАЯВКА “]
ВЪВЕДЕТЕ [DBO].[СЛУЖИТЕЛИ] ([ИМЕ НА СЛУЖИТЕЛ], [ДАТА НА РОЖДЕНИЕ], [РАБОТА], [ИМЕЙЛ ИД], [ТЕЛЕФОНЕН НОМЕР], [НАЕМАНЕ], [ОТДЕЛ]) СТОЙНОСТИ (N'KEN J SÁNCHEZ', CAST) (N'1969-01-29T00:00:00.000' КАТО DATETIME), N'ГЛАВЕН ИЗПЪЛНИТЕЛЕН СЛУЖИТЕЛ', N'example@sqldat.com', N'697-555-0142', CAST(N'2009-01- 14T00:00:00.000' КАТО DATETIME), 1), (N'TERRI LEE DUFFY', CAST(N'1971-08-01T00:00:00.000' КАТО DATETIME), N'ВИДЕПРЕДСЕДАТЕЛ НА ИНЖЕНЕРИНГ, N'пример @sqldat.com', N'819-555-0175', CAST(N'2008-01-31T00:00:00.000' КАТО DATETIME), NULL), (N'ROBERTO TAMBURELLO', CAST(N'1974-11 -12T00:00:00.000' КАТО DATETIME), N'ENGINEERING MANAGER', N'example@sqldat.com', N'212-555-0187', CAST(N'2007-11-11T00:00:00.000' AS DATETIME), NULL), (N'ROB WALTERS', CAST(N'1974-12-23T00:00:00.000' КАТО DATETIME), N' СТАРШИ ИНСТРУМЕНТ ДИЗАЙНЕР', N'example@sqldat.com', N'612-555-0100', CAST(N'2007-12-05T00:00:00.000' КАТО DATETIME), NULL), (N'GAIL A ERICKSON ', CAST(N'1952-09-27T00:00:00.000' КАТО DATETIME), N'DESIGN ENGINEER', N'example@sqldat.com', N'849-555-0139', CAST(N'2008- 01-06T00:00:00.000' КАТО DATETIME), NULL), (N'JOSSEF H GOLDBERG', CAST(N'1959-03-11T00:00:00.000' КАТО DATETIME), N'DESIGN ENGINEER', N'example @sqldat.com', N'122-555-0189', CAST(N'2008-01-24T00:00:00.000' КАТО DATETIME), NULL), (N'DYLAN A MILLER', CAST(N'1987- 02-24T00:00:00.000' КАТО DATETIME), N'МЕНИДЖЪР ИЗСЛЕДВАНЕ И РАЗРАБОТКА', N'example@sqldat.com', N'181-555-0156', CAST(N'2009-02-08T00:00:00.000' КАТО DATETIME), 3), (N'DIANE L MARGHEIM', CAST(N'1986-06-05T00:00:00.000' КАТО DATETIME), N'ИНЖЕНЕР ИЗСЛЕДВАНЕ И РАЗРАБОТКА, N'example@sqldat.com', N'815-555-0138', CAST(N'2008-12-29T00:00:00.000' КАТО DATETIME), 3), (N'GIGI N МАТЕЙ', CAST(N '1979-01-21T00:00:00.000' КАТО DATETIME), N'ИНЖЕНЕР ИЗСЛЕДВАНЕ И РАЗРАБОТКА', N'example@sqldat.com', N'185-555-0186', CAST(N'2009-01-16T00 :00:00.000' КАТО DATETIME), 3), (N'MICHAEL RAHEEM', CAST(N'1984-11-30T00:00:00.000' КАТО DATETIME), N'МЕНИДЖЪР ИЗСЛЕДВАНЕ И РАЗВИТИЕ', N'example@sqldat .com', N'330-555-2568', CAST(N'2009-05-03T00:00:00.000' КАТО DATETIME), 3)
[/expand]
За да добавите данни към нашия „Отдел ” изпълнете следния скрипт:
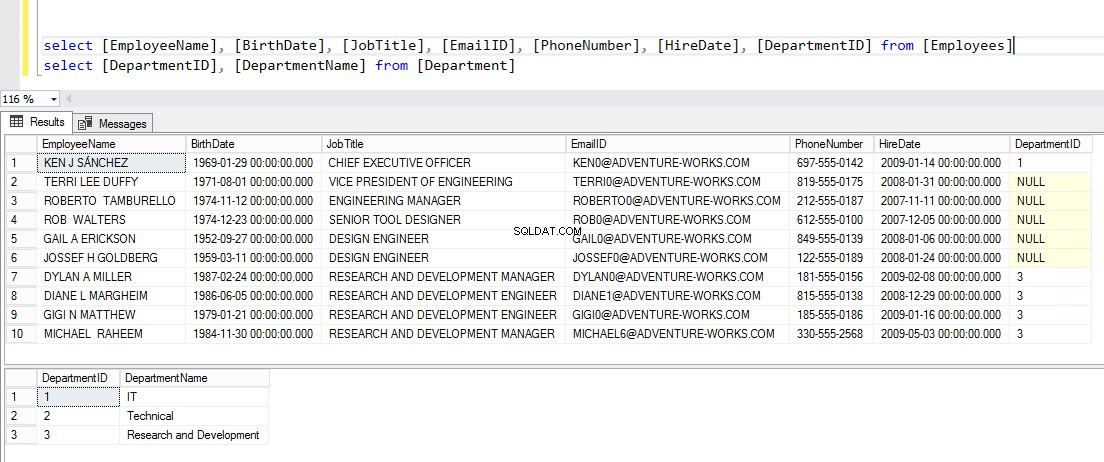
ВЪВЕТЕ [DBO].[ОТДЕЛ] ([DEPARTMENTID], [DEPARTMENTNAME]) СТОЙНОСТИ (1, N'IT'), (2, N'TECHNICAL'), (3, N'ИЗСЛЕДВАНЕ И РАЗРАБОТКА')Сега, за да проверите данните, изпълнете кода, който можете да видите по-долу:
ИЗБЕРЕТЕ [ИМЕ НА СЛУЖИТЕЛ], [ДАТА НА РОЖДЕНИЕ], [РАБОТА], [ИМЕЙЛ ИД], [ТЕЛЕФОНЕН НОМЕР], [НАЕМАНЕ], [ОТДЕЛ] ОТ [СЛУЖИТЕЛИ] ИЗБЕРЕТЕ [DEPARTMENTID], [DEPARTMENTNAME] ОТ [ОТДЕЛ] GOЕто желания изход:
Създаване и тестване на функция, оценена от таблица
Както вече споменах, „КРЪСТНО ПРИЛАГАНЕ ” и „ВЪНШНО ПРИЛОЖЕНИЕ ” се използват за свързване на SQL таблици с оценени от таблици функции. За да демонстрираме това, нека създадем оценена на таблица функция с име „getEmployeeData ” Тази функция ще използва стойност от DepartmentID колона като входен параметър и връща всички служители от кореспондентския отдел.
За да създадете функцията, изпълнете следния скрипт:
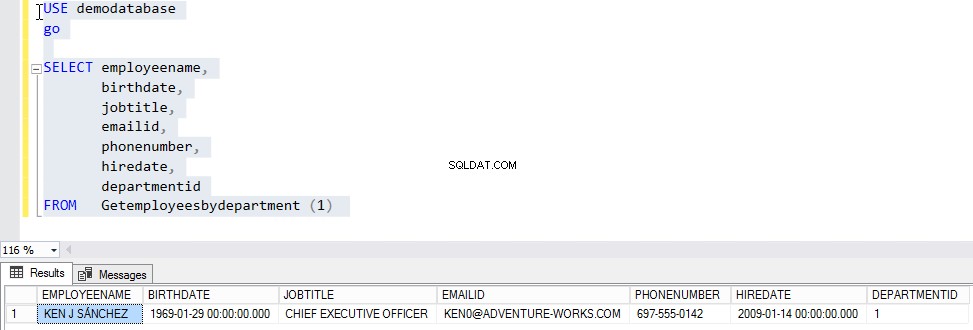
СЪЗДАВАНЕ НА ФУНКЦИЯ Gettemployeesbydepartment (@DEPARTMENTID INT) ВРЪЩА ТАБЛИЦА @EMPLOYEES (ИМЕ НА СЛУЖИТЕЛ VARCHAR (MAX), ДАТА НА РОЖДЕНИЕ, ДАТА НА РАБОТА, JOBTITLE VARCHAR(150), ИМЕЙЛ ИД VARCHAR(100), PHONE0NUMBER VARCHAR, DATE5TIME, VARCHAR 2 )) КАТО ЗАПОЧНЕТЕ ВЪВЕТЕ ВЪВ @EMPLOYEES ИЗБЕРЕТЕ A.EMPLOYEENAME, A.BIRTHDATE, A.JOBTITLE, A.EMAILID, A.PHONENUMBER, A.HIREDATE, A.DEPARTMENTID ОТ [СЛУЖИТЕЛИ] A КЪДЕ A.DEPARTMENTID =@DEPARTMENTID ВРЪЩАНЕ КРАЙСега, за да тестваме функцията, ще предадем „1 ” като „идентификатор на отдел ” към „Getemployeesbydepartment ” функция. За да направите това, изпълнете скрипта, предоставен по-долу:
ИЗПОЛЗВАЙТЕ DEMODATABASEGOSELECT EMPLOYEENAME, BIRTHDATE, JOBTITLE, EMAILID, PHONENUMBER, HIREDATE, DEPARTMENTIDFROM GETEMPLOYEESBYDEPARTMENT (1)Резултатът трябва да бъде както следва:
Присъединяване към таблица с функция, оценена от таблица, с помощта на CROSS APPLY
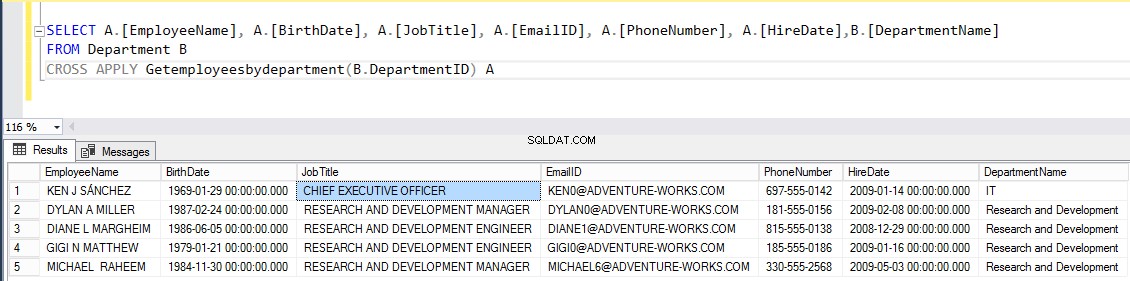
Сега нека се опитаме да се присъединим към таблицата на служителите с „Getemployeesbydepartment ” таблично оценена функция с помощта на КРЪСТНО ПРИЛАГАНЕ . Както споменах, КРЪСТНО ПРИЛАГАНЕ Операторът е подобен на клаузата за присъединяване. Той ще попълни всички записи от „Служител ” таблица, за която има съвпадащи редове в изхода на „Getemployeesbydepartment “.
Изпълнете следния скрипт:
ИЗБЕРЕТЕ A.[ИМЕ НА СЛУЖИТЕЛЯ], A.[ДАТА НА РОЖДЕНИЕ], A.[ЗАГЛАВА НА РАБОТА], A.[ИМЕЙЛ ИД], A.[ТЕЛЕФОНЕН НОМЕР], A.[ДАТА НА НАЕМАНЕ], B.[ИМЕ НА ОТДЕЛ] ОТ ОТДЕЛ B КРЪСТ ПРИЛОЖИТЕ ПРИЛОЖЕНИЕТО. GETEMPLOYEESBYDEPARTMENT(B.DEPARTMENTID) AРезултатът трябва да бъде както следва:
Присъединяване към таблица с функция, оценена от таблица, с помощта на OUTER APPLY
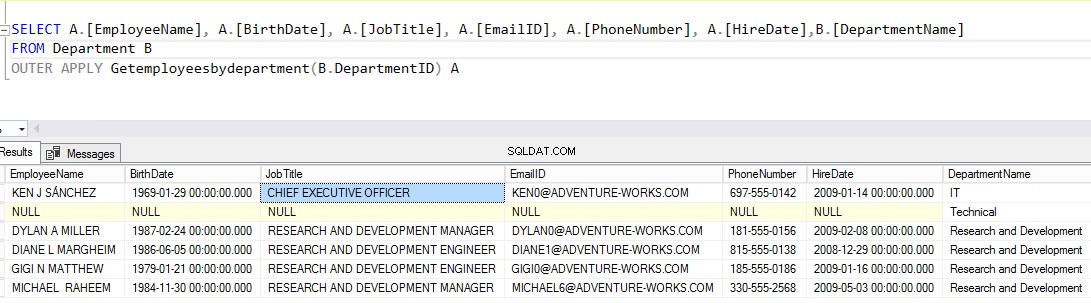
Сега, нека се опитаме да се присъединим към таблицата на служителите с „Getemployeesbydepartment ” таблично оценена функция с помощта на ВЪНШНО ПРИЛОЖЕНИЕ . Както споменах по-рано, ВЪНШНО ПРИЛАГАНЕ операторът прилича на „OUTER JOIN " клауза. Той попълва всички записи от „Служител ” таблица и изхода на „Getemployeesbydepartment ” функция.
Изпълнете следния скрипт:
ИЗБЕРЕТЕ A.[ИМЕ НА СЛУЖИТЕЛ], A.[ДАТА НА РОЖДЕНИЕ], A.[ЗАГЛАВА НА РАБОТА], A.[EMAILID], A.[ТЕЛЕФОНЕН НОМЕР], A.[ДАТА НА НАЕМАНЕ], B.[DEPARTMENTNAME] ОТ ОТДЕЛ B ВЪНШНО ПРИЛОЖЕНИЕ. GETEMPLOYEESBYDEPARTMENT(B.DEPARTMENTID) AЕто изхода, който трябва да видите като резултат:
Идентифициране на проблеми с производителността чрез използване на функции за динамично управление и изгледи
Нека ви покажа различен пример. Тук ще видим как да получим план за заявка и съответния текст на заявка чрез използване на функции за динамично управление и динамични изгледи за управление.
За демонстрационни цели създадох таблица с име „SmokeTestResults ” в „Демобаза данни“. Той съдържа резултати от тест за дим от приложението. Нека си представим, че по погрешка разработчик изпълнява SQL заявка, за да попълни данните от „SmokeTestResults ” без добавяне на филтър, което значително намалява производителността на базата данни.
Като DBA, ние трябва да идентифицираме заявката, натоварена с ресурси. За да направим това, ще използваме „sys.dm_exec_requests ” изглед и „sys.dm_exec_sql_text ” функция.
“Sys.dm_exec_requests ” е динамичен изглед за управление, който предоставя следните важни подробности, които можем да използваме, за да идентифицираме заявката, която консумира ресурси:
- Идентификатор на сесията
- Време на процесора
- Тип на изчакване
- Идентификатор на базата данни
- Чете (физически)
- Записва (физически)
- Логически четения
- SQL манипулатор
- Управление на плана
- Състояние на заявката
- Команда
- Идентификатор на транзакцията
“sys.dm_exec_sql_text ” е функция за динамично управление, която приема SQL манипулатор като входен параметър и предоставя следните подробности:
- Идентификатор на базата данни
- Идентификатор на обект
- Шифровано е
- Текст на SQL заявка
Сега нека изпълним следната заявка, за да генерираме малко напрежение върху базата данни ASAP. Изпълнете следната заявка:
ИЗПОЛЗВАЙТЕ ASAP GO SELECT TSID, USERID, EXECUTIONID, EX_RESULTFILE, EX_TESTDATAFILE, EX_ZIPFILE, EX_STARTTIME, EX_ENDTIME, EX_REMARKS FROM [ASAP].[DBO].[SMOKETESTRESULTS]SQL Server разпределя идентификатор на сесия „66“ и започва изпълнението на заявката. Вижте следното изображение:
Сега, за да отстраним проблема, се нуждаем от ID на базата данни, логически четения, SQL Запитване, команда, идентификатор на сесия, тип на изчакване и SQL манипулатор . Както споменах, можем да получим ID на базата данни, логически четения, команда, идентификатор на сесия, тип чакане и SQL манипулатор от „sys.dm_exec_requests.“ За да получите SQL заявката , трябва да използваме „sys.dm_exec_sql_text. ” Това е функция за динамично управление, така че ще трябва да се присъедините към „sys.dm_exec_requests ” с „sys.dm_exec_sql_text ” с помощта на КРЪСТНО ПРИЛАГАНЕ.
В прозореца на нов редактор на заявки изпълнете следната заявка:
ИЗБЕРЕТЕ B.TEXT, A.WAIT_TYPE, A.LAST_WAIT_TYPE, A.COMMAND, A.SESSION_ID, CPU_TIME, A.BLOCKING_SESSION_ID, A.LOGICAL_READS ОТ SYS.DM_EXEC_REQUESTS A CROSS APPLEC_SYS.DDMLE /предварително>Той трябва да произведе следния изход:
Както можете да видите на горната екранна снимка, заявката върна цялата информация, необходима за идентифициране на проблема с производителността.
Сега, в допълнение към текста на заявката, искаме да получим плана за изпълнение, който е бил използван за изпълнение на въпросната заявка. За да направим това, ще използваме „sys.dm_exec_query_plan“ функция.
“sys.dm_exec_query_plan ” е функция за динамично управление, която приема ръководител на план като входен параметър и предоставя следните подробности:
- Идентификатор на базата данни
- Идентификатор на обект
- Шифровано е
- SQL план за заявка в XML формат
За да попълним плана за изпълнение на заявката, трябва да използваме CROSS APPLY, за да се присъединим към „sys.dm_exec_requests ” и „sys.dm_exec_query_plan. ”
Отворете прозореца на редактора на нови заявки и изпълнете следната заявка:
ИЗБЕРЕТЕ B.TEXT, A.WAIT_TYPE, A.LAST_WAIT_TYPE, A.COMMAND, A.SESSION_ID, CPU_TIME, A.BLOCKING_SESSION_ID, A.LOGICAL_READS, C.QUERY_PLAN ОТ SYS.DM_EXEC_REQUESTS_REQUESTS_DEQUESTSQUESTSQUESTSQUESTSQUESTSQUESTSQ. SQL_HANDLE) B КРЪСНО ПРИЛАГАНЕ SYS.DM_EXEC_QUERY_PLAN (A.PLAN_HANDLE) CРезултатът трябва да бъде както следва:
Сега, както можете да видите, планът на заявката се генерира в XML формат по подразбиране. За да го отворите като графично представяне, щракнете върху XML изхода в план_заявка колона, както е показано на горното изображение. След като щракнете върху XML изхода, планът за изпълнение ще се отвори в нов прозорец, както е показано на следното изображение:
Получаване на списък с таблици със силно фрагментирани индекси чрез използване на динамични изгледи и функции за управление
Нека видим още един пример. Искам да получа списък с таблици с индекси, които имат 50% или повече фрагментация в дадена база данни. За да извлечем тези таблици, ще трябва да използваме „sys.dm_db_index_physical_stats ” изглед и „sys.tables ” функция.
“Системни таблици ” е динамичен изглед за управление, който попълва списък с таблици в конкретната база данни.
“sys.dm_db_index_physical_stats ” е функция за динамично управление, която приема следните входни параметри:
- Идентификатор на базата данни
- Идентификатор на обект
- Идентификационен номер на индекса
- Номер на дял
- Режим
Връща подробна информация за физическото състояние на посочения индекс.
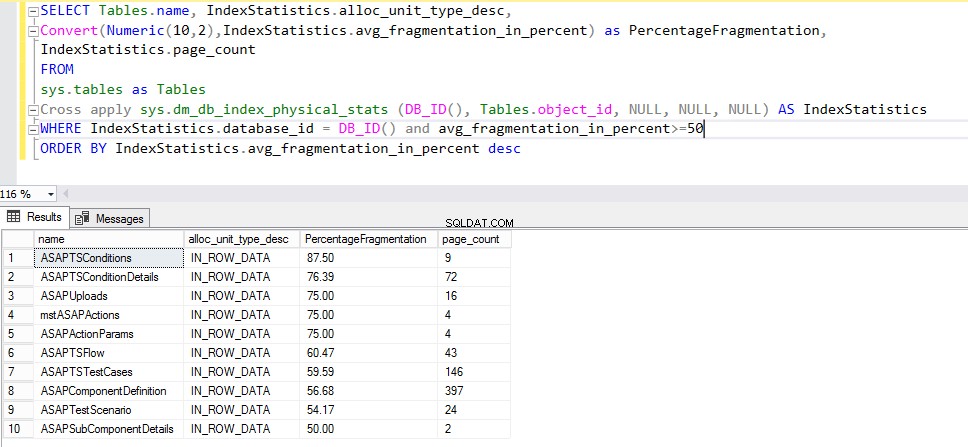
Сега, за да попълним списъка с фрагментирани индекси, трябва да се присъединим към „sys.dm_db_index_physical_stats ” и „sys.tables ” с помощта на КРЪСТО ПРИЛАГАНЕ. Изпълнете следната заявка:
ИЗБЕРЕТЕ TABLES.NAME, INDEXSTATISTICS.ALLOC_UNIT_TYPE_DESC, CONVERT(NUMERIC(10, 2), INDEXSTATISTICS.AVG_FRAGMENTATION_IN_PERCENT) КАТО PERCENTAGEFRAGMENTATION, INDEXSTATISTICS.PAGE_COUNT FROM COMPANY SYSTEM SYSTEM SYSTEM. , NULL, NULL, NULL) КАТО INDEXSTATISTICS, КЪДЕТО INDEXSTATISTICS.DATABASE_ID =DB_ID() И AVG_FRAGMENTATION_IN_PERCENT>=50 ПОРЪЧАЙТЕ ПО INDEXSTATISTICS.AVG_FRAGMENTATION_IN_PERCENT DESCЗаявката трябва да даде следния изход:
Резюме
В тази статия разгледахме оператора APPLY, неговите вариации – CROSS APPLY и OUTER APPLY и как работите. Видяхме също как можете да ги използвате, за да идентифицирате проблеми с производителността на SQL, като използвате изгледи за динамично управление и функции за динамично управление.