[ Част 1 | Част 2 | Част 3 | Част 4 ]
Проблемът с Хелоуин може да има редица важни ефекти върху плановете за изпълнение. В тази последна част от поредицата разглеждаме триковете, които оптимизаторът може да използва, за да избегне проблема с Хелоуин, когато съставя планове за заявки, които добавят, променят или изтриват данни.
Фон
През годините бяха изпробвани редица подходи за избягване на проблема с Хелоуин. Една ранна техника беше просто да се избягва изграждането на каквито и да било планове за изпълнение, които включват четене от и записване на ключове от същия индекс. Това не беше много успешно от гледна точка на производителността, не на последно място защото често означаваше сканиране на основната таблица вместо използване на селективен неклъстериран индекс за намиране на редовете, които трябва да се променят.
Вторият подход беше да се разделят напълно фазите на четене и писане на заявка за актуализиране, като първо се локализират всички редове, които отговарят на изискванията за промяната, се съхраняват някъде и едва след това се започне да се извършват промените. В SQL Server това пълно фазово разделяне се постига чрез поставяне на вече познатия Eager Table Spool на входната страна на оператора за актуализиране:
Шпулата чете всички редове от своя вход и ги съхранява в скрит tempdb работна маса. Страниците на тази работна таблица може да останат в паметта или може да изискват физическо дисково пространство, ако наборът от редове е голям или ако сървърът е под напрежение в паметта.
Пълното разделяне на фазите може да бъде по-малко от идеално, защото обикновено искаме да изпълняваме възможно най-много от плана като конвейер, където всеки ред се обработва напълно, преди да преминем към следващия. Конвейерът има много предимства, включително избягване на необходимостта от временно съхранение и докосване на всеки ред само веднъж.
Оптимизаторът на SQL сървър
SQL Server отива много по-далеч от двете описани досега техники, въпреки че, разбира се, включва и двете като опции. Оптимизаторът на заявки на SQL Server открива заявки, които изискват Хелоуин защита, определя колко изисква се защита и използва базирана на разходите анализ за намиране на най-евтиния метод за осигуряване на тази защита.
Най-лесният начин да разберете този аспект на проблема за Хелоуин е да разгледате някои примери. В следващите раздели задачата е да добавите диапазон от числа към съществуваща таблица – но само числа, които все още не съществуват:
СЪЗДАВАЙТЕ ТАБЛИЦА dbo.Test( pk цяло число НЕ НУЛВО, ОГРАНИЧЕНИЕ PK_Test ПЪРВИЧЕН КЛУСТЕР (pk));
5 реда
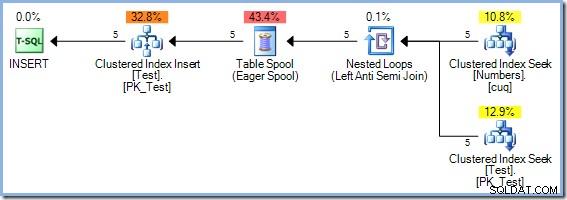
Първият пример обработва диапазон от числа от 1 до 5 включително:
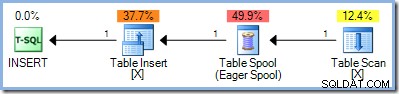
ВЪВЕТЕ /предварително>Тъй като тази заявка чете от и записва в ключовете на същия индекс в тестовата таблица, планът за изпълнение изисква защита за Хелоуин. В този случай оптимизаторът използва пълно фазово разделяне, използвайки Eager Table Spool:
50 реда
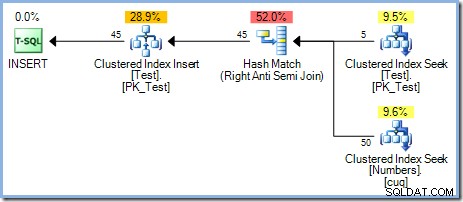
С пет реда вече в тестовата таблица, стартираме отново същата заявка, променяйки
WHEREклауза за обработка на числата от1 до 50 включително :
Този план осигурява правилна защита срещу проблема с Хелоуин, но не включва Eager Table Spool. Оптимизаторът разпознава, че операторът за присъединяване на Hash Match блокира своя вход за изграждане; всички редове се четат в хеш таблица, преди операторът да започне процеса на съвпадение, използвайки редове от входа на сондата. В резултат на това този план естествено осигурява разделяне на фазите (само за тестовата маса) без нужда от макара.
Оптимизаторът избра план за присъединяване на Hash Match пред присъединяването с вложени цикли, което се вижда в 5-редовия план по причини, базирани на разходите. Планът Hash Match с 50 реда има обща прогнозна цена от 0,0347345 единици. Можем да принудим плана за вложени цикли, използван преди, с намек, за да видим защо оптимизаторът не е избрал вложени цикли:
Този план има приблизителна цена от 0,0379063 единици, включително макарата, малко повече от плана Hash Match.
500 реда
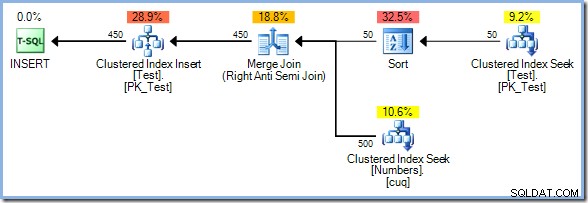
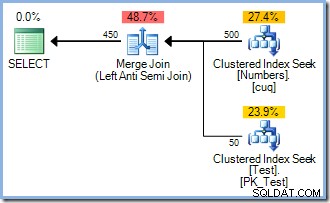
С 50 реда вече в тестовата таблица, ние допълнително увеличаваме диапазона от числа до 500 :
Този път оптимизаторът избира Merge Join и отново няма Eager Table Spool. Операторът за сортиране осигурява необходимото разделяне на фазите в този план. Той консумира напълно своя вход, преди да върне първия ред (сортирането не може да знае кой ред се сортира първи, докато не бъдат видени всички редове). Оптимизаторът реши, че сортирането е 50 редове от таблицата за тестове биха били по-евтини от нетърпеливото спулиране 450 редове точно преди оператора за актуализиране.
Планът Sort plus Merge Join има приблизителна цена от 0,0362708 единици. Алтернативите на плана Hash Match и Nested Loops излизат на 0,0385677 единици и0.112433 единици съответно.
Нещо странно в сортирането
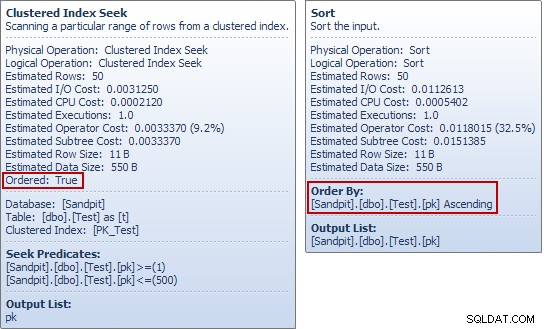
Ако сте използвали тези примери за себе си, може би сте забелязали нещо странно в последния пример, особено ако разгледате съветите за инструмента Plan Explorer за тестовата таблица Търсене и сортиране:
Търсенето произвежда подредено поток от pk стойности, така че какъв е смисълът от сортирането на същата колона веднага след това? За да отговорим на този (много разумен) въпрос, започваме с разглеждане само на
SELECTчаст отINSERTзаявка:ИЗБЕРЕТЕ Num.n ОТ dbo.Numbers КАТО NumWHERE Num.n МЕЖДУ 1 И 500 И НЕ СЪЩЕСТВУВА ( ИЗБЕРЕТЕ 1 ОТ dbo.Test AS t WHERE t.pk =Num.n )ПОРЪЧАЙТЕ ПО Num.n;Тази заявка произвежда плана за изпълнение по-долу (със или без
ORDER BYДобавих, за да отговоря на някои технически възражения, които може да имате):
Забележете липсата на оператор за сортиране. И така, защо
INSERTпланът включва сортиране? Просто за да избегнете проблема с Хелоуин. Оптимизаторът смята, че извършва излишно сортиране (с вграденото си разделяне на фазите) беше най-евтиният начин за изпълнение на заявката и гарантиране на правилни резултати. Умен.Нива на защита и свойства за Хелоуин
Оптимизаторът на SQL Server има специфични функции, които му позволяват да разсъждава за нивото на защита на Хелоуин (HP), което се изисква във всяка точка от плана на заявката, и за подробния ефект, който всеки оператор има. Тези допълнителни функции са включени в същата рамка на свойствата, която оптимизаторът използва, за да следи стотици други важни битове информация по време на своите дейности по търсене.
Всеки оператор имазадължителен Собственост на HP и вдоставка HP собственост. Зазадължителното свойството показва нивото на HP, необходимо в тази точка в дървото за правилни резултати. Доставната свойството отразява HP, предоставено от текущия оператор и кумулативно HP ефекти, предоставени от неговото поддърво.
Оптимизаторът съдържа логика, за да определи как всеки физически оператор (например Compute Scalar) влияе върху нивото на HP. Чрез проучване на широк спектър от алтернативи на планове и отхвърляне на планове, при които доставеното HP е по-малко от изискваното HP при оператора за актуализиране, оптимизаторът разполага с гъвкав начин да намери правилни, ефективни планове, които не винаги изискват Eager Table Spool.
Промени в плана за защита на Хелоуин
Видяхме как оптимизаторът добавя излишно сортиране за Хелоуин защита в предишния пример за присъединяване към сливане. Как можем да сме сигурни, че това е по-ефективно от обикновена Eager Table Spool? И как можем да разберем кои функции на план за актуализация са налице само за защитата на Хелоуин?
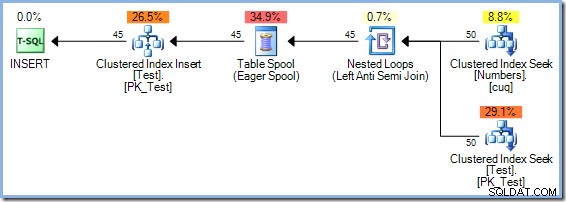
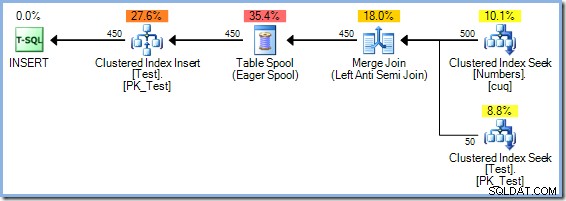
И на двата въпроса може да се отговори (естествено в тестова среда) с помощта на недокументиран флаг за проследяване 8692 , което принуждава оптимизатора да използва Eager Table Spool за защита на Хелоуин. Припомнете си, че планът Merge Join с излишно сортиране имаше приблизителна цена от 0,0362708 магически модули за оптимизиране. Можем да сравним това с алтернативата Eager Table Spool, като прекомпилираме заявката с активиран флаг за проследяване 8692:
INSERT dbo.Test (pk)ИЗБЕРЕТЕ Num.n ОТ dbo.Numbers КАТО NumWHERE Num.n МЕЖДУ 1 И 500 И НЕ СЪЩЕСТВУВА (ИЗБЕРЕТЕ 1 ОТ dbo.Test AS t КЪДЕ t.pk =Num.n) ОПЦИЯ ( QUERYTRACEON 8692);
Планът Eager Spool има приблизителна цена от 0,0378719 единици (от0,0362708 с излишния сорт). Разликите в разходите, показани тук, не са много значителни поради тривиалния характер на задачата и малкия размер на редовете. Заявките за актуализиране в реалния свят със сложни дървета и по-голям брой редове често създават планове, които са много по-ефективни благодарение на способността на оптимизатора на SQL Server да мисли задълбочено за защитата на Хелоуин.
Други опции без шпула
Оптималното позициониране на блокиращ оператор в план не е единствената стратегия, отворена за оптимизатора за минимизиране на разходите за осигуряване на защита срещу проблема на Хелоуин. Той може също да разсъждава за диапазона от стойности, които се обработват, както показва следният пример:
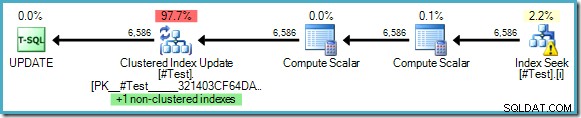
СЪЗДАВАНЕ НА ТАБЛИЦА #Test( pk цяло число ИДЕНТИФИКАЦИЯ ПЪРВИЧЕН КЛЮЧ, някаква_стойност цяло число); СЪЗДАВАЙТЕ ИНДЕКС i ON #Test (някаква_стойност); -- Представете си, че таблицата има много данни в нея АКТУАЛИЗИРАНЕ НА СТАТИСТИКАТА #TestWITH ROWCOUNT =123456, PAGECOUNT =1234; АКТУАЛИЗИРАНЕ #TestSET some_value =10WHERE some_value =5;Планът за изпълнение не показва нужда от защита за Хелоуин, въпреки факта, че четем и актуализираме ключовете на общ индекс:
Оптимизаторът може да види, че промяната на ‘some_value’ от 5 на 10 никога не би могла да доведе до това, че актуализиран ред бъде видян втори път от търсенето на индекс (което търси само редове, където some_value е 5). Това разсъждение е възможно само когато в заявката се използват буквални стойности или когато заявката посочва
OPTION (RECOMPILE), което позволява на оптимизатора да подуши стойностите на параметрите за еднократен план за изпълнение.Дори и с буквални стойности в заявката, оптимизаторът може да бъде възпрепятстван да приложи тази логика, ако опцията на базата данни
FORCED PARAMETERIZATIONеON. В този случай литералните стойности в заявката се заменят с параметри и оптимизаторът вече не може да е сигурен, че защитата на Хелоуин не се изисква (или няма да се изисква, когато планът се използва повторно с различни стойности на параметрите):
В случай, че се чудите какво ще стане, ако
FORCED PARAMETERIZATIONе активиран и заявката посочваOPTION (RECOMPILE), отговорът е, че оптимизаторът компилира план за подушените стойности и така може да приложи оптимизацията. Както винаги сOPTION (RECOMPILE), планът за заявка със специфична стойност не се кешира за повторна употреба.Отгоре
Този последен пример показва как
Topоператорът може да премахне необходимостта от защита за Хелоуин:АКТУАЛИЗИРАНЕ НА ВЪРХУ (1) tSET some_value +=1FROM #Test AS tWHERE some_value <=10;
Не се изисква защита, защото актуализираме само един ред. Актуализираната стойност не може да бъде открита от търсенето на индекс, тъй като конвейерът за обработка спира веднага щом се актуализира първият ред. Отново, тази оптимизация може да се приложи само ако се използва константна литерална стойност в
TOPили ако променлива, връщаща стойността '1', се подуши с помощта наOPTION (RECOMPILE).Ако променим
TOP (1)в заявката къмTOP (2), оптимизаторът избира групирано сканиране на индекс вместо търсенето на индекс:
Ние не актуализираме ключовете на клъстерирания индекс, така че този план не изисква защита за Хелоуин. Принудително използване на неклъстерирания индекс с намек в
TOP (2)заявка прави цената на защитата очевидна:
Оптимизаторът изчисли, че Clustered Index Scan ще бъде по-евтино от този план (с неговата допълнителна защита за Хелоуин).
Коефициенти и краища
Има няколко други точки, които искам да направя за защитата на Хелоуин, които досега не са намерили естествено място в поредицата. Първият е въпросът за защитата на Хелоуин, когато се използва ниво на изолация с версии на ред.
Версиониране на редове
SQL Server предоставя две нива на изолация,
READ COMMITTED SNAPSHOTиSNAPSHOT ISOLATIONкоито използват съхранение на версии в tempdb за осигуряване на последователен изглед на базата данни на ниво изявление или транзакция. SQL Server може напълно да избегне защитата на Хелоуин при тези нива на изолация, тъй като хранилището на версиите може да предостави данни, незасегнати от промените, които изпълняващият се израз може да е направил досега. Тази идея понастоящем не се прилага в пусната версия на SQL Server, въпреки че Microsoft е подал патент, описващ как ще работи това, така че може би една бъдеща версия ще включва тази технология.Накопи и препратени записи
Ако сте запознати с вътрешните елементи на структурите на heap, може да се чудите дали може да възникне конкретен проблем за Хелоуин, когато препратените записи се генерират в таблица на heap. В случай, че това е ново за вас, запис на купчина ще бъде препратен, ако съществуващ ред бъде актуализиран така, че вече не се вписва в оригиналната страница с данни. Двигателят оставя след себе си препращане и премества разширения запис на друга страница.
Може да възникне проблем, ако план, съдържащ сканиране на купчина, актуализира запис, така че да бъде препратен. Сканирането на купчина може да срещне реда отново, когато позицията на сканиране достигне страницата с препратения запис. В SQL Server този проблем се избягва, тъй като Storage Engine гарантира, че винаги следва незабавно указателите за препращане. Ако сканирането срещне запис, който е бил препратен, то го игнорира. С тази предпазна мярка оптимизаторът на заявки не трябва да се тревожи за този сценарий.
SCEMABINDING и T-SQL скаларни функции
Има много малко случаи, когато използването на скаларна функция на T-SQL е добра идея, но ако трябва да използвате такава, трябва да сте наясно с важен ефект, който може да има по отношение на защитата на Хелоуин. Освен ако скаларна функция не е декларирана с
SCHEMABINDINGопция, SQL Server приема, че функцията осъществява достъп до таблици. За да илюстрирате, разгледайте простата T-SQL скаларна функция по-долу:СЪЗДАВАНЕ НА ФУНКЦИЯ dbo.ReturnInput( @value integer)ВРЪЩА цяло числоASBEGIN RETURN @value;END;Тази функция няма достъп до никакви таблици; всъщност той не прави нищо, освен да връща предадената му стойност на параметъра. Сега вижте следния
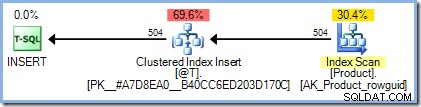
INSERTзаявка:ДЕКЛАРИРАНЕ @T КАТО ТАБЛИЦА (ПРАВИЛЕН КЛЮЧ, цяло число на продукта); INSERT @T (ProductID)SELECT p.ProductIDFROM AdventureWorks2012.Production.Product AS p;Планът за изпълнение е точно такъв, какъвто бихме очаквали, без да е необходима защита за Хелоуин:
Добавянето на нашата функция за нищо не прави обаче има драматичен ефект:
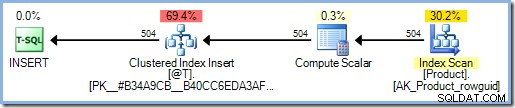
ДЕКЛАРИРАНЕ @T КАТО ТАБЛИЦА (ПРАВИЛЕН КЛЮЧ, цяло число на продукта); INSERT @T (ProductID)SELECT dbo.ReturnInput(p.ProductID)FROM AdventureWorks2012.Production.Product AS p;
Планът за изпълнение вече включва Eager Table Spool за защита на Хелоуин. SQL Server приема, че функцията осъществява достъп до данни, което може да включва отново четене от таблицата с продукти. Както може би си спомняте,
INSERTплан, който съдържа препратка към целевата таблица от страната за четене на плана, изисква пълна защита за Хелоуин и доколкото оптимизаторът знае, това може да е случаят тук.Добавяне на
SCHEMABINDINGопция за дефиницията на функцията означава, че SQL Server разглежда тялото на функцията, за да определи до кои таблици има достъп. Той не намира такъв достъп и затова не добавя никаква защита за Хелоуин:ALTER FUNCTION dbo.ReturnInput( @value integer)ВРЪЩА цяло число С SCHEMABINDINGASBEGIN RETURN @value;END;GODECLARE @T КАТО ТАБЛИЦА (ИД на продукта int ПРАВИЛЕН КЛЮЧ); INSERT @T (ProductID)SELECT p.ProductIDFROM AdventureWorks2012.Production.Product AS p;
Този проблем със скаларните функции на T-SQL засяга всички заявки за актуализиране –
INSERT,UPDATE,DELETEиMERGE. Познаването кога се сблъсквате с този проблем се затруднява, тъй като ненужната защита за Хелоуин не винаги ще се показва като допълнителна Eager Table Spool, а извикванията на скаларни функции могат да бъдат скрити в изгледи или изчислени дефиниции на колони, например.[ Част 1 | Част 2 | Част 3 | Част 4 ]