В последната си публикация започнах серия, която да обхваща проактивни проверки на здравето, които са жизненоважни за вашия SQL Server. Започнахме с дисково пространство и в тази публикация ще обсъдим задачите за поддръжка. Една от основните отговорности на DBA е да гарантира, че следните задачи за поддръжка се изпълняват редовно:
- Резервни копия
- Проверки на целостта
- Поддръжка на индекса
- Актуализации на статистиката
Обзалагам се, че вече имате работни места за управление на тези задачи. И бих се обзаложил, че имате конфигурирани известия да изпращат имейл до вас и вашия екип, ако дадена работа се провали. Ако и двете са верни, тогава вече сте проактивни по отношение на поддръжката. И ако не правите и двете, това е нещо, което трябва да поправите в момента – например, спрете да четете това, изтеглете скриптовете на Ola Hallengren, насрочете ги и се уверете, че сте настроили известия. (Друга алтернатива, специфична за поддръжката на индекси, която също препоръчваме на клиентите, е SQL Sentry Fragmentation Manager.)
Ако не знаете дали вашите работни места са настроени да ви изпращат имейл, ако не успеят, използвайте тази заявка:
SELECT [Name], [Description] FROM [dbo].[sysjobs] WHERE [enabled] = 1 AND [notify_level_email] NOT IN (2,3) ORDER BY [Name];
Въпреки това, проактивността по отношение на поддръжката отива още една стъпка по-далеч. Освен просто да се уверите, че вашите работни места работят, трябва да знаете колко време отнемат. Можете да използвате системните таблици в msdb, за да наблюдавате това:
SELECT
[j].[name] AS [JobName],
[h].[step_id] AS [StepID],
[h].[step_name] AS [StepName],
CONVERT(CHAR(10), CAST(STR([h].[run_date],8, 0) AS DATETIME), 121) AS [RunDate],
STUFF(STUFF(RIGHT('000000' + CAST ( [h].[run_time] AS VARCHAR(6 ) ) ,6),5,0,':'),3,0,':')
AS [RunTime],
(([run_duration]/10000*3600 + ([run_duration]/100)%100*60 + [run_duration]%100 + 31 ) / 60)
AS [RunDuration_Minutes],
CASE [h].[run_status]
WHEN 0 THEN 'Failed'
WHEN 1 THEN 'Succeeded'
WHEN 2 THEN 'Retry'
WHEN 3 THEN 'Cancelled'
WHEN 4 THEN 'In Progress'
END AS [ExecutionStatus],
[h].[message] AS [MessageGenerated]
FROM [msdb].[dbo].[sysjobhistory] [h]
INNER JOIN [msdb].[dbo].[sysjobs] [j]
ON [h].[job_id] = [j].[job_id]
WHERE [j].[name] = 'DatabaseBackup - SYSTEM_DATABASES – FULL'
AND [step_id] = 0
ORDER BY [RunDate]; Или, ако използвате скриптовете и информацията за регистриране на Ola, можете да потърсите неговата CommandLog таблица:
SELECT [DatabaseName], [CommandType], [StartTime], [EndTime], DATEDIFF(MINUTE, [StartTime], [EndTime]) AS [Duration_Minutes] FROM [master].[dbo].[CommandLog] WHERE [DatabaseName] = 'AdventureWorks2014' AND [Command] LIKE 'BACKUP DATABASE%' ORDER BY [StartTime];
Горният скрипт изброява продължителността на архивиране за всяко пълно архивиране на базата данни AdventureWorks2014. Можете да очаквате, че продължителността на задачите за поддръжка бавно ще се увеличава с течение на времето, тъй като базите данни нарастват. Като такива, вие търсите големи увеличения или неочаквани намаления на продължителността. Например, имах клиент със средна продължителност на архивиране по-малко от 30 минути. Изведнъж архивирането започва да отнема повече от час. Базата данни не се беше променила значително по размер, никакви настройки не се бяха променили за екземпляра или базата данни, нищо не се беше променило с хардуера или конфигурацията на диска. Няколко седмици по-късно продължителността на архивирането спадна до по-малко от половин час. Месец след това те отново се покачиха. В крайна сметка съпоставихме промяната в продължителността на архивирането с отказите между възлите на клъстера. На един възел архивирането отне по-малко от половин час. От друга страна, те отнеха повече от час. Малко проучване на конфигурацията на NIC и SAN тъканта и успяхме да определим проблема.
Разбирането на средното време на изпълнение на операциите CHECKDB също е важно. Това е нещо, за което Пол говори в нашето събитие за потапяне с висока достъпност и възстановяване при бедствия:трябва да знаете колко време обикновено отнема на CHECKDB, така че ако откриете повреда и изпълните проверка на цялата база данни, да знаете колко време трябва вземете за завършване на CHECKDB. Когато шефът ви попита:„Колко още, докато разберем степента на проблема?“ ще можете да предоставите количествен отговор за минималния период от време, което ще трябва да изчакате. Ако CHECKDB отнема повече време от обикновено, тогава знаете, че е намерено нещо (което може да не е непременно повреда; винаги трябва да оставяте проверката да завърши).
Сега, ако управлявате стотици бази данни, не искате да изпълнявате горната заявка за всяка база данни или всяка работа. Вместо това може просто да искате да намерите работни места, които са извън средната продължителност с определен процент, който можете да получите с помощта на тази заявка:
SELECT
[j].[name] AS [JobName],
[h].[step_id] AS [StepID],
[h].[step_name] AS [StepName],
CONVERT(CHAR(10), CAST(STR([h].[run_date],8, 0) AS DATETIME), 121) AS [RunDate],
STUFF(STUFF(RIGHT('000000' + CAST ( [h].[run_time] AS VARCHAR(6 ) ) ,6),5,0,':'),3,0,':')
AS [RunTime],
(([run_duration]/10000*3600 + ([run_duration]/100)%100*60 + [run_duration]%100 + 31 ) / 60)
AS [RunDuration_Minutes],
[avdur].[Avg_RunDuration_Minutes]
FROM [dbo].[sysjobhistory] [h]
INNER JOIN [dbo].[sysjobs] [j]
ON [h].[job_id] = [j].[job_id]
INNER JOIN
(
SELECT
[j].[name] AS [JobName],
AVG((([run_duration]/10000*3600 + ([run_duration]/100)%100*60 + [run_duration]%100 + 31 ) / 60))
AS [Avg_RunDuration_Minutes]
FROM [dbo].[sysjobhistory] [h]
INNER JOIN [dbo].[sysjobs] [j]
ON [h].[job_id] = [j].[job_id]
WHERE [step_id] = 0
AND CONVERT(DATE, RTRIM(h.run_date)) >= DATEADD(DAY, -60, GETDATE())
GROUP BY [j].[name]
) AS [avdur]
ON [avdur].[JobName] = [j].[name]
WHERE [step_id] = 0
AND (([run_duration]/10000*3600 + ([run_duration]/100)%100*60 + [run_duration]%100 + 31 ) / 60)
> ([avdur].[Avg_RunDuration_Minutes] + ([avdur].[Avg_RunDuration_Minutes] * .25))
ORDER BY [j].[name], [RunDate]; Тази заявка изброява работни места, които са отнели 25% повече от средното. Заявката ще изисква известна настройка, за да предостави конкретната информация, която искате – някои задачи с малка продължителност (например по-малко от 5 минути) ще се покажат, ако отнемат само няколко допълнителни минути – това може да не е проблем. Независимо от това, тази заявка е добро начало и осъзнайте, че има много начини за намиране на отклонения – можете също да сравните всяко изпълнение с предишното и да потърсите работни места, които са отнели определен процент по-дълго от предишното.
Очевидно продължителността на заданието е най-логичният идентификатор, който да се използва за потенциални проблеми – независимо дали става дума за резервно копие, проверка на целостта или задачата, която премахва фрагментацията и актуализира статистическите данни. Открих, че най-голямата вариация в продължителността обикновено е в задачите за премахване на фрагментация и актуализиране на статистически данни. В зависимост от вашите прагове за reorg срещу rebuild и променливостта на вашите данни, може да прекарате дни с предимно reorgs, след което изведнъж ще стартирате няколко възстановяване на индекси за големи таблици, където тези реконструкции напълно променят средната продължителност. Може да искате да промените праговете си за някои индекси или да коригирате фактора на запълване, така че повторното изграждане да се извършва по-често или по-рядко – в зависимост от индекса и нивото на фрагментация. За да направите тези корекции, трябва да погледнете колко често всеки индекс се преизгражда или реорганизира, което можете да направите само ако използвате скриптовете на Ola и регистрирате в таблицата CommandLog, или ако сте разработили свое собствено решение и регистрирате всяка реорганизация или реконструкция. За да разгледате това с помощта на таблицата CommandLog, можете да започнете, като проверите кои индекси се променят най-често:
SELECT [DatabaseName], [ObjectName], [IndexName], COUNT(*) FROM [master].[dbo].[CommandLog] [c] WHERE [DatabaseName] = 'AdventureWorks2014' AND [Command] LIKE 'ALTER INDEX%' GROUP BY [DatabaseName], [ObjectName], [IndexName] ORDER BY COUNT(*) DESC;
От този изход можете да започнете да виждате кои таблици (и следователно индекси) имат най-голяма нестабилност и след това да определите дали прагът за reorg или rebuild трябва да се коригира, или коефициентът на запълване трябва да бъде модифициран.
Улесняване на живота
Сега има по-лесно решение от това да пишете свои собствени заявки, стига да използвате SQL Sentry Event Manager (EM). Инструментът следи всички задания на агент, настроени на екземпляр, и с помощта на изгледа на календара можете бързо да видите кои задачи са неуспешни, анулирани или изпълнявани по-дълго от обикновено:
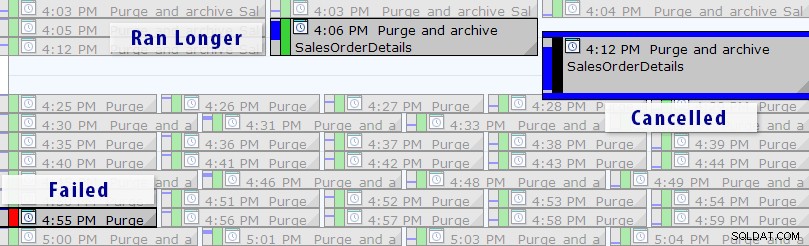 Календарен изглед на SQL Sentry Event Manager (с етикети, добавени във Photoshop)
Календарен изглед на SQL Sentry Event Manager (с етикети, добавени във Photoshop)
Можете също така да разгледате отделни изпълнения, за да видите колко повече време е отнело изпълнението на дадена задача, а също така има удобни графики по време на изпълнение, които ви позволяват бързо да визуализирате всякакви модели в аномалии на продължителност или условия на отказ. В този случай виждам, че на всеки 15 минути продължителността на изпълнение за тази конкретна работа скочи с почти 400%:
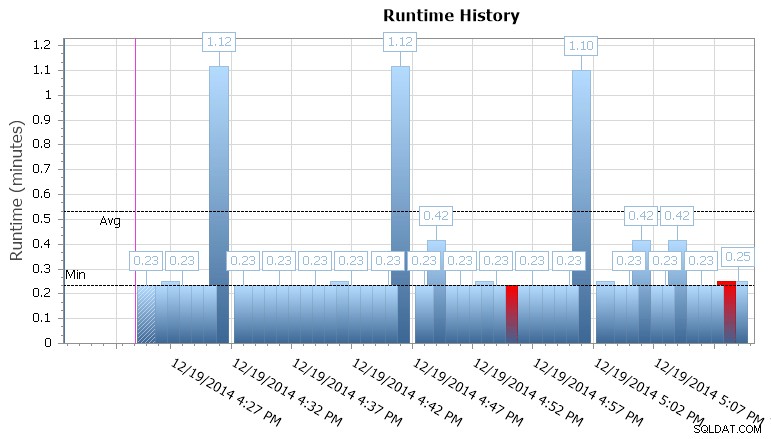 SQL Sentry Event Manager графика за изпълнение на мениджъра
SQL Sentry Event Manager графика за изпълнение на мениджъра
Това ми дава представа, че трябва да разгледам други планирани работни места, които може да причиняват някои проблеми с едновременността тук. Бих могъл да намаля календара отново, за да видя какви други задачи се изпълняват по едно и също време, или може дори да не трябва да гледам, за да разпозная, че това е някаква задача за отчитане или архивиране, която се изпълнява срещу тази база данни.
Резюме
Бих се обзаложил, че повечето от вас вече имат необходимите задачи за поддръжка и че също така имате настроени известия за неуспехи на работа. Ако не сте запознати със средната продължителност на работата си, това е следващата ви стъпка в проактивността. Забележка:може също да се наложи да проверите колко дълго запазвате хронологията на работата. Когато търся отклонения в продължителността на работата, предпочитам да гледам данни за няколко месеца, а не за няколко седмици. Не е нужно да запаметявате тези времена на изпълнение, но след като се уверите, че съхранявате достатъчно данни, за да имате хронологията, която да използвате за изследвания, тогава започнете да търсите вариации редовно. В идеалния сценарий увеличеното време на изпълнение може да ви предупреди за потенциален проблем, което ви позволява да го решите, преди да възникне проблем във вашата производствена среда.