В последната си публикация („Пич, кой притежава тази таблица с #temp?“) предложих, че в SQL Server 2012 и по-нови версии можете да използвате разширени събития, за да наблюдавате създаването на #temp таблици. Това ще ви позволи да съпоставите конкретни обекти, заемащи много място в tempdb, със сесията, която ги е създала (например, за да определите дали сесията може да бъде убита, за да се опита да освободи пространството). Това, което не обсъдих, са допълнителните разходи за това проследяване – очакваме разширените събития да бъдат по-леки от проследяването, но нито едно наблюдение не е напълно безплатно.
Тъй като повечето хора оставят проследяването по подразбиране активирано, ние ще го оставим на място. Ще тестваме и двете купчини с помощта на SELECT INTO (която проследяването по подразбиране няма да събира) и клъстерирани индекси (които ще) и ние ще определим времето на пакета самостоятелно като базова линия, след което ще стартираме пакета отново с стартирана сесия на разширени събития. Ще тестваме и срещу SQL Server 2012 и SQL Server 2014. Самата партида е доста проста:
ЗАДАДЕТЕ NOCOUNT ON; SELECT SYSDATETIME();GO -- стартирайте тази част само за партидата на heap:SELECT TOP (100) [object_id] INTO #foo FROM sys.all_objects ORDER BY [object_id];DROP TABLE #foo; -- стартирайте тази част само за пакета CIX:CREATE TABLE #bar(id INT PRIMARY KEY);INSERT #bar(id) SELECT TOP (100) [object_id] FROM sys.all_objects ORDER BY [object_id];DROP TABLE #bar; GO 100000 ИЗБЕРЕТЕ SYSDATETIME();
И двата екземпляра имат tempdb, конфигуриран с четири файла с данни и с активирани TF 1117 и TF 1118, във VM с четири процесора, 16 GB памет и само SSD. Умишлено създадох малки #temp таблици, за да засиля всяко наблюдавано въздействие върху самата партида (което ще се удави, ако създаването на #temp таблиците отне много време или предизвика прекомерни събития за автоматично нарастване).
Пуснах тези партиди във всеки сценарий и ето резултатите, измерени в продължителност на партидата в секунди:
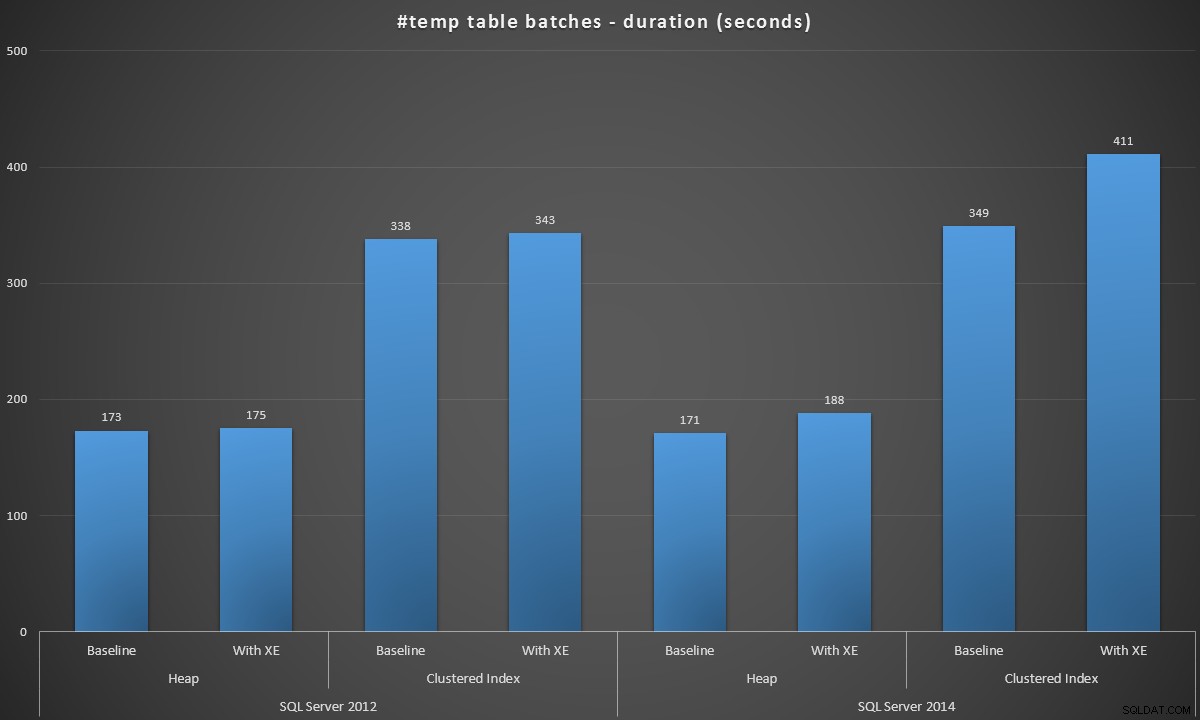
Продължителност на партидата, в секунди, за създаване на 100 000 #temp таблици
Изразявайки данните малко по-различно, ако разделим 100 000 на продължителността, можем да покажем броя #temp таблици, които можем да създадем за секунда във всеки сценарий (четете:пропускателна способност). Ето тези резултати:
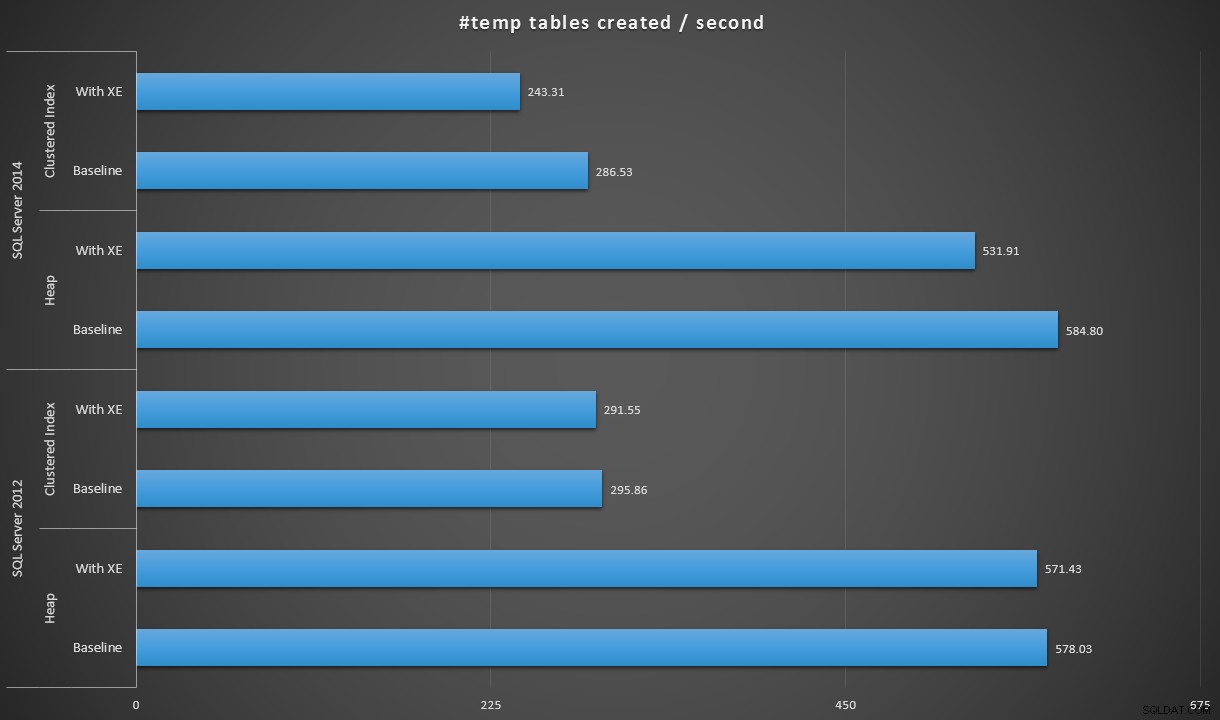
#temp таблици, създадени на секунда при всеки сценарий
Резултатите бяха малко изненадващи за мен – очаквах, че с подобренията на SQL Server 2014 в логиката на нетърпеливото писане, популацията на хепа най-малкото ще работи много по-бързо. Купчината през 2014 г. беше с две мизерни секунди по-бърза от 2012 г. при базовата конфигурация, но разширените събития увеличиха времето доста (приблизително 10% увеличение спрямо изходното ниво); докато времето на групирания индекс беше сравнимо с 2012 г. в изходното състояние, но се увеличи с близо 18% с активирани разширени събития. През 2012 г. делтите за купчини и клъстерирани индекси са много по-скромни – съответно 1,1% и 1,5%. (И за да бъде ясно, по време на нито един от тестовете не са настъпили събития за автоматично нарастване.)
И така, помислих си, какво ще стане, ако създам по-стройна, по-зла сесия за разширени събития? Със сигурност бих могъл да премахна някои от тези колони за действие – може би ми трябват само име за вход и spid и мога да игнорирам името на приложението, името на хоста и потенциално скъпия sql_text. Може би бих могъл да махна допълнителния филтър срещу комита (събирайки два пъти повече събития, но по-малко CPU изразходва за филтриране) и да разреша загуба на множество събития, за да намаля потенциалното въздействие върху работното натоварване. Тази по-лека сесия изглежда така:
СЪЗДАВАНЕ НА СЕСИЯ НА СЪБИТИЕ [TempTableCreation2014_LeanerMeaner] НА СЪРВЪР ДОБАВЯНЕ НА СЪБИТИЕ sqlserver.object_created( ACTION ( sqlserver.server_principal_name, sqlserver.session_id ) WHERE ( sqlserver.session_id ) WHERE ( sqlserver.session_id ) WHERE ( sqlserver.session_id ) WHERE ( sqlserver.session_id ) WHERE ( sqlserver.session_id ) WHERE ( sqlserver.session_id ) WHERE ( sqlserver.session_id ) WHERE ( sqlserver.session_id ) WHERE ( sqlserver.session_id) (Задаване на fileName ='C:\ temp \ temptableCreation2014_leanermeaner.xel', max_file_size =32768, max_rollover_files =10) с (event_retention_mode =relege_multiple_event_loss); сесия на вратата [temptablecreation2014_leanermeaner] on server stain =starge =stair;Уви, не, същите резултати. Малко над три минути за купчината и малко под седем минути за клъстерирания индекс. За да разровя по-дълбоко къде се изразходва допълнителното време, гледах екземпляра от 2014 г. с SQL Sentry и пуснах само групирания индекс без конфигурирани сесии за разширени събития. След това стартирах пакета отново, този път с конфигурирана по-лека XE сесия. Времената на партидата бяха 5:47 (347 секунди) и 6:55 (415 секунди) – толкова много в съответствие с предишната партида (с радост видях, че нашето наблюдение не допринесе повече за продължителността :-)) . Потвърдих, че няма отпаднали събития и отново, че не са възникнали събития за автоматично нарастване.
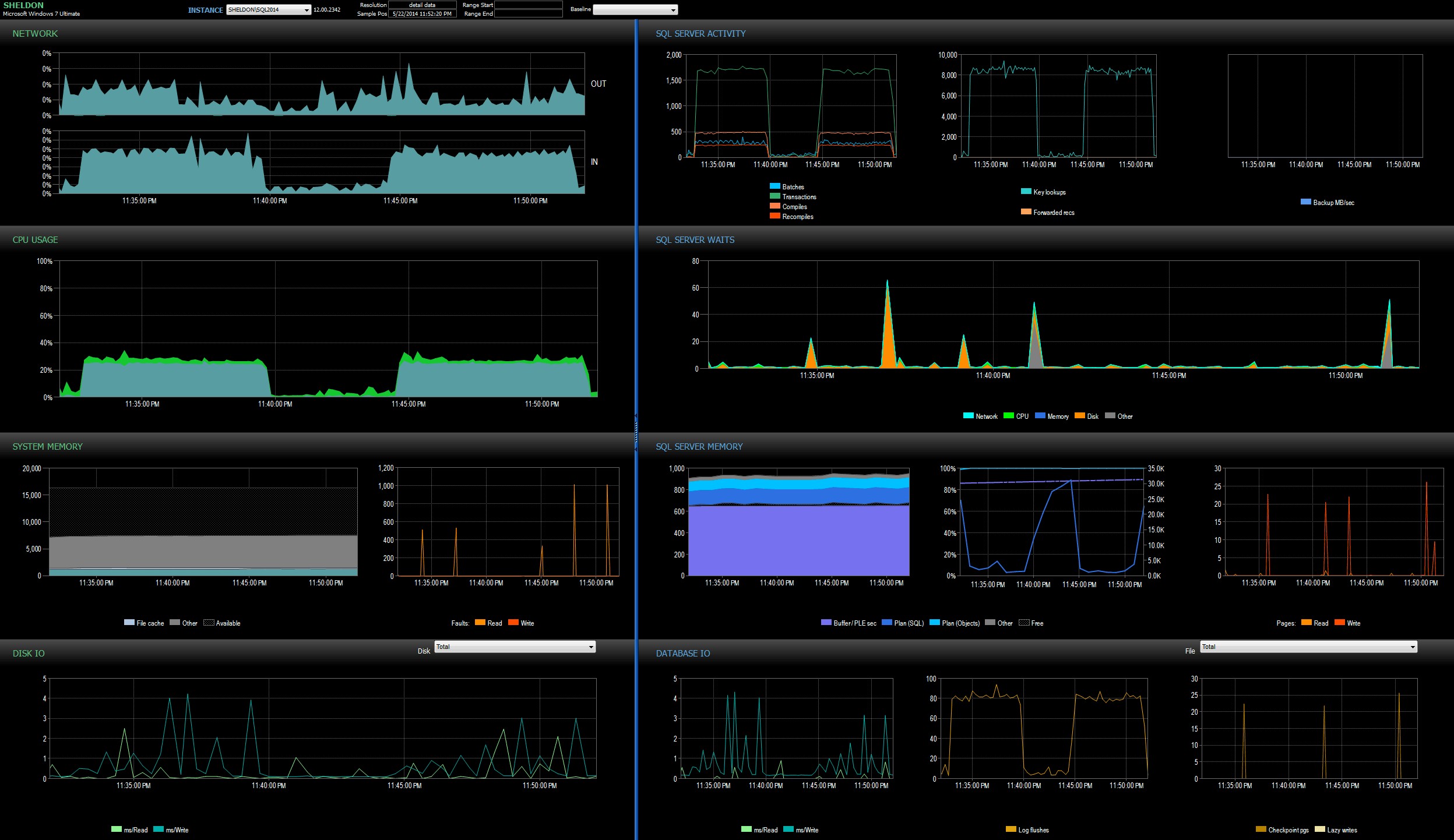
Погледнах таблото за управление на SQL Sentry в режим на история, което ми позволи бързо да видя показателите за производителност на двете партиди една до друга:
Табло за управление на SQL Sentry, в режим на история, показващо и двете партидиИ двете партиди бяха практически идентични по отношение на мрежа, процесор, транзакции, компилиране, търсене на ключове и т.н. Има малка разлика в изчакванията – пиковете по време на първата партида бяха изключително WRITELOG, докато имаше някои незначителни чакания на CXPACKET, открити в втора партида. Моята работна теория доста след полунощ е, че може би голяма част от наблюдаваното закъснение се дължи на превключване на контекста, причинено от процеса на разширени събития. Тъй като нямаме никаква видимост за това какво точно прави XE под завивките, нито знаем каква основна механика се е променила в XE между 2012 и 2014 г., това е историята, с която ще се придържам засега, докато не стана по-удобно с xperf и/или WinDbg.
Заключение
Във всеки случай е ясно, че проследяването на създаването на #temp таблица не е безплатно и цената може да варира в зависимост от типа на #temp таблици, които създавате, количеството информация, което събирате във вашите XE сесии и дори версията на SQL Server, който използвате. Така че можете да проведете тестове, подобни на това, което направих тук, и да решите колко ценно е събирането на тази информация във вашата среда.