Вероятно знаете как да вмъквате записи в таблица с помощта на единични или множество клаузи VALUES. Вие също знаете как да правите групови вмъквания с помощта на SQL INSERT INTO SELECT. Но все пак щракнахте върху статията. За работа с дубликати ли става въпрос?
Много статии обхващат SQL INSERT INTO SELECT. Google или Bing it и изберете заглавието, което ви харесва най-много – ще стане. Няма да разглеждам и основни примери за това как се прави. Вместо това ще видитепримери за това как да го използвате И да обработвате дубликати едновременно . Така че можете да направите това познато съобщение от вашите усилия INSERT:
Msg 2601, Level 14, State 1, Line 14
Cannot insert duplicate key row in object 'dbo.Table1' with unique index 'UIX_Table1_Key1'. The duplicate key value is (value1).
Но първо нещата.

[sendpulse-form id=”12989″]
Подгответе тестови данни за SQL INSERT INTO SELECT Code Samples
Този път мисля за паста. Така че ще използвам данни за ястия с паста. Намерих добър списък с ястия с паста в Wikipedia, които можем да използваме и извличаме в Power BI, използвайки уеб източник на данни. Въведох URL адреса на Wikipedia. След това посочих данните от 2 таблици от страницата. Почистих го малко и копирах данните в Excel.
Сега имаме данните – можете да ги изтеглите от тук. Това е сурово, защото ще направим 2 релационни таблици от него. Използването на INSERT INTO SELECT ще ни помогне да изпълним тази задача,
Импортирайте данните в SQL Server
Можете да използвате SQL Server Management Studio или dbForge Studio за SQL Server, за да импортирате 2 листа във файла на Excel.
Създайте празна база данни, преди да импортирате данните. Нарекох таблиците dbo.ItalianPastaDishes и dbo.NonItalianPastaDishes .
Създайте още 2 таблици
Нека дефинираме двете изходни таблици с командата SQL Server ALTER TABLE.
CREATE TABLE [dbo].[Origin](
[OriginID] [int] IDENTITY(1,1) NOT NULL,
[Origin] [varchar](50) NOT NULL,
[Modified] [datetime] NOT NULL,
CONSTRAINT [PK_Origin] PRIMARY KEY CLUSTERED
(
[OriginID] ASC
))
GO
ALTER TABLE [dbo].[Origin] ADD CONSTRAINT [DF_Origin_Modified] DEFAULT (getdate()) FOR [Modified]
GO
CREATE UNIQUE NONCLUSTERED INDEX [UIX_Origin] ON [dbo].[Origin]
(
[Origin] ASC
)
GO
CREATE TABLE [dbo].[PastaDishes](
[PastaDishID] [int] IDENTITY(1,1) NOT NULL,
[PastaDishName] [nvarchar](75) NOT NULL,
[OriginID] [int] NOT NULL,
[Description] [nvarchar](500) NOT NULL,
[Modified] [datetime] NOT NULL,
CONSTRAINT [PK_PastaDishes_1] PRIMARY KEY CLUSTERED
(
[PastaDishID] ASC
))
GO
ALTER TABLE [dbo].[PastaDishes] ADD CONSTRAINT [DF_PastaDishes_Modified_1] DEFAULT (getdate()) FOR [Modified]
GO
ALTER TABLE [dbo].[PastaDishes] WITH CHECK ADD CONSTRAINT [FK_PastaDishes_Origin] FOREIGN KEY([OriginID])
REFERENCES [dbo].[Origin] ([OriginID])
GO
ALTER TABLE [dbo].[PastaDishes] CHECK CONSTRAINT [FK_PastaDishes_Origin]
GO
CREATE UNIQUE NONCLUSTERED INDEX [UIX_PastaDishes_PastaDishName] ON [dbo].[PastaDishes]
(
[PastaDishName] ASC
)
GO
Забележка:Има уникални индекси, създадени в две таблици. Това ще ни попречи да вмъкнем дублиращи се записи по-късно. Ограниченията ще направят това пътуване малко по-трудно, но вълнуващо.
Сега, когато сме готови, нека се потопим.
5 лесни начина за справяне с дубликати с помощта на SQL INSERT INTO SELECT
Най-лесният начин да се справите с дубликатите е да премахнете уникалните ограничения, нали?
Грешно!
С изчезналите уникални ограничения е лесно да направите грешка и да вмъкнете данните два пъти или повече. Ние не искаме това. И какво ще стане, ако имаме потребителски интерфейс с падащ списък за избор на произхода на ястието с паста? Ще направят ли дубликатите вашите потребители щастливи?
Следователно премахването на уникалните ограничения не е един от петте начина за обработка или изтриване на дублиращи се записи в SQL. Имаме по-добри опции.
1. Използване на INSERT INTO SELECT DISTINCT
Първата опция за това как да идентифицирате SQL записи в SQL е да използвате DISTINCT във вашия SELECT. За да проучим случая, ще попълним Произход маса. Но първо, нека използваме грешен метод:
-- This is wrong and will trigger duplicate key errors
INSERT INTO Origin
(Origin)
SELECT origin FROM NonItalianPastaDishes
GO
INSERT INTO Origin
(Origin)
SELECT ItalianRegion + ', ' + 'Italy'
FROM ItalianPastaDishes
GO
Това ще задейства следните дублиращи се грешки:
Msg 2601, Level 14, State 1, Line 2
Cannot insert a duplicate key row in object 'dbo.Origin' with unique index 'UIX_Origin'. The duplicate key value is (United States).
The statement has been terminated.
Msg 2601, Level 14, State 1, Line 6
Cannot insert duplicate key row in object 'dbo.Origin' with unique index 'UIX_Origin'. The duplicate key value is (Lombardy, Italy).
Има проблем, когато се опитате да изберете дублиращи се редове в SQL. За да стартирам SQL проверката за дубликати, които са съществували преди, изпълних частта SELECT от оператора INSERT INTO SELECT:
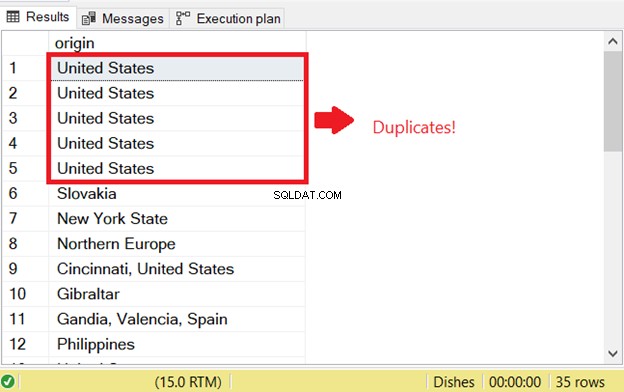
Това е причината за първата грешка при дублиране на SQL. За да го предотвратите, добавете ключовата дума DISTINCT, за да направите набора от резултати уникален. Ето правилния код:
-- The correct way to INSERT
INSERT INTO Origin
(Origin)
SELECT DISTINCT origin FROM NonItalianPastaDishes
INSERT INTO Origin
(Origin)
SELECT DISTINCT ItalianRegion + ', ' + 'Italy'
FROM ItalianPastaDishes
Вмъква записите успешно. И ние приключихме с Произход таблица.
Използването на DISTINCT ще направи уникални записи от оператора SELECT. Това обаче не гарантира, че дубликати не съществуват в целевата таблица. Добре е, когато сте сигурни, че целевата таблица няма стойностите, които искате да вмъкнете.
Така че, не изпълнявайте тези изрази повече от веднъж.
2. Използване на WHERE NOT IN
След това попълваме PastaDishes маса. За това първо трябва да вмъкнем записи от ItalianPastaDishes маса. Ето кода:
INSERT INTO [dbo].[PastaDishes]
(PastaDishName,OriginID, Description)
SELECT
a.DishName
,b.OriginID
,a.Description
FROM ItalianPastaDishes a
INNER JOIN Origin b ON a.ItalianRegion + ', ' + 'Italy' = b.Origin
WHERE a.DishName NOT IN (SELECT PastaDishName FROM PastaDishes)
Тъй като Italian PastaDishes съдържа необработени данни, трябва да се присъединим към Origin текст вместо OriginID . Сега опитайте да стартирате един и същ код два пъти. Вторият път, когато се стартира, няма да има вмъкнати записи. Това се случва заради клаузата WHERE с оператора NOT IN. Той филтрира записи, които вече съществуват в целевата таблица.
След това трябва да попълним PastaDishes таблица от Неиталиански ястия от паста маса. Тъй като сме едва във втората точка от тази публикация, няма да вмъкваме всичко.
Избрахме тестени изделия от Съединените щати и Филипините. Ето го:
-- Insert pasta dishes from the United States (22) and the Philippines (15) using NOT IN
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE a.PastaDishName NOT IN (SELECT PastaDishName FROM PastaDishes)
AND b.OriginID IN (15,22)
Има 9 записа, вмъкнати от това изявление – вижте фигура 2 по-долу:
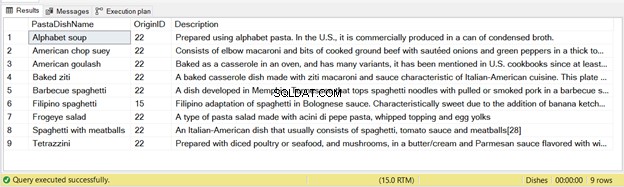
Отново, ако стартирате кода по-горе два пъти, второто изпълнение няма да има вмъкнати записи.
3. Използване на WHERE NOT EXISTS
Друг начин да намерите дубликати в SQL е да използвате NOT EXISTS в клаузата WHERE. Нека го опитаме със същите условия от предишния раздел:
-- Insert pasta dishes from the United States (22) and the Philippines (15) using WHERE NOT EXISTS
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE NOT EXISTS(SELECT PastaDishName FROM PastaDishes pd
WHERE pd.OriginID IN (15,22))
AND b.OriginID IN (15,22)
Кодът по-горе ще вмъкне същите 9 записа, които видяхте на фигура 2. Ще избегне вмъкването на едни и същи записи повече от веднъж.
4. Използване на IF NOT EXISTS
Понякога може да се наложи да разположите таблица в базата данни и е необходимо да проверите дали вече съществува таблица със същото име, за да избегнете дублиране. В този случай командата SQL DROP TABLE IF EXISTS може да бъде от голяма помощ. Друг начин да гарантирате, че няма да вмъквате дубликати, е да използвате IF NOT EXISTS. Отново ще използваме същите условия от предишния раздел:
-- Insert pasta dishes from the United States (22) and the Philippines (15) using IF NOT EXISTS
IF NOT EXISTS(SELECT PastaDishName FROM PastaDishes pd
WHERE pd.OriginID IN (15,22))
BEGIN
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE b.OriginID IN (15,22)
END
Горният код първо ще провери за съществуването на 9 записа. Ако върне истината, INSERT ще продължи.
5. Използване на COUNT(*) =0
И накрая, използването на COUNT(*) в клаузата WHERE също може да гарантира, че няма да вмъквате дубликати. Ето един пример:
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE b.OriginID IN (15,22)
AND (SELECT COUNT(*) FROM PastaDishes pd
WHERE pd.OriginID IN (15,22)) = 0
За да избегнете дублиране, COUNT или записите, върнати от подзаявката по-горе, трябва да са нула.
Забележка :Можете да проектирате всяка заявка визуално в диаграма, като използвате функцията Query Builder на dbForge Studio за SQL Server.
Сравняване на различни начини за обработка на дубликати с SQL INSERT INTO SELECT
4 секции използваха същия изход, но различни подходи за вмъкване на групови записи с оператор SELECT. Може да се чудите дали разликата е само на повърхността. Можем да проверим техните логически показания от STATISTICS IO, за да видим колко различни са те.
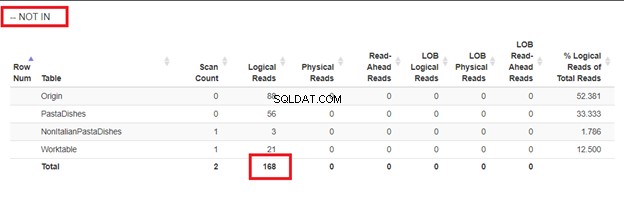
Използване на WHERE NOT IN:
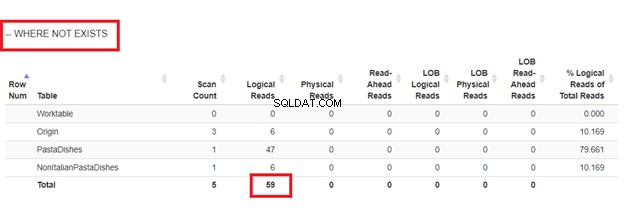
Използване на NOT EXISTS:
Използване на IF NOT EXISTS:
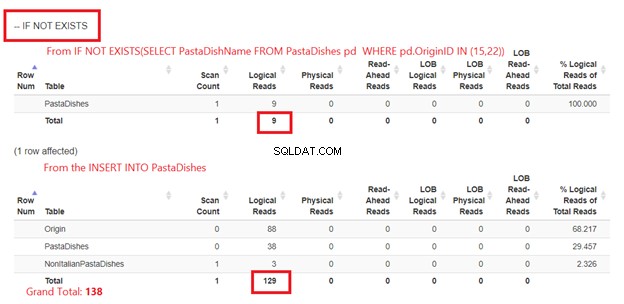
Фигура 5 е малко по-различна. Появяват се 2 логически показания за PastaDishes маса. Първият е от IF NOT EXISTS(SELECT PastaDishName от PastaDishes WHERE OriginID IN (15,22)). Вторият е от оператора INSERT.
И накрая, използвайки COUNT(*) =0
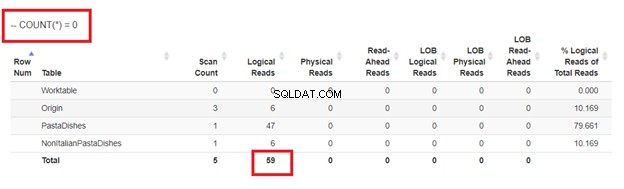
От логическите показания на 4 подхода, които имахме, най-добрият избор е WHERE NOT EXISTS или COUNT(*) =0. Когато проверяваме техните планове за изпълнение, виждаме, че имат същия QueryHashPlan . Следователно те имат подобни планове. Междувременно най-малко ефективната е използването на NOT IN.
Означава ли това, че КЪДЕТО НЕ СЪЩЕСТВУВА винаги е по-добре от НЕ В? Изобщо не.
Винаги проверявайте логическите показания и плана за изпълнение на вашите заявки!
Но преди да приключим, трябва да завършим поставената задача. След това ще вмъкнем останалите записи и ще проверим резултатите.
-- Insert the rest of the records
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE a.PastaDishName NOT IN (SELECT PastaDishName FROM PastaDishes)
GO
-- View the output
SELECT
a.PastaDishID
,a.PastaDishName
,b.Origin
,a.Description
,a.Modified
FROM PastaDishes a
INNER JOIN Origin b ON a.OriginID = b.OriginID
ORDER BY b.Origin, a.PastaDishName
Прелистването от списъка със 179 ястия с паста от Азия до Европа ме кара да огладнявам. Вижте част от списъка от Италия, Русия и други отдолу:

Заключение
В крайна сметка избягването на дубликати в SQL INSERT INTO SELECT не е толкова трудно. Имате под ръка оператори и функции, които да ви отведат до това ниво. Също така е добър навик да проверите плана за изпълнение и логическите показания, за да сравните кое е по-добро.
Ако смятате, че някой друг ще се възползва от тази публикация, моля, споделете я в любимите си социални медийни платформи. И ако имате нещо да добавите, което сме забравили, уведомете ни в секцията за коментари по-долу.



