Наскоро участвах в разработването на функционалността, която изисква бързо и често прехвърляне на големи обеми данни на диск. Освен това тези данни трябваше да се четат от диска от време на време. Затова ми беше писано да разбера мястото, начина и средствата за съхранение на тези данни. В тази статия ще прегледам накратко задачата, както и ще проуча и сравня решенията за изпълнение на тази задача.
Контекст на задачата :Работя в екип, който разработва инструменти за относителна разработка на бази данни (SQL Server, MySQL, Oracle). Гамата от инструменти включва както самостоятелни инструменти, така и добавки за MS SSMS.
Задача :Възстановяване на документи, които са били отворени в момента на затваряне на IDE при следващото стартиране на IDE.
Usecase :За да затворите бързо IDE, преди да напуснете офиса, без да мислите кои документи са запазени и кои не. При следващото стартиране на IDE трябва да получим същата среда, която е била в момента на затваряне и да продължим работата. Всички резултати от работата трябва да бъдат запазени в момента на безпорядъчното затваряне, напр. по време на срив на програма или операционна система или по време на изключване.
Анализ на задача :Подобна функция присъства в уеб браузърите. Въпреки това, браузърите съхраняват само URL адреси, които се състоят от приблизително 100 символа. В нашия случай трябва да съхраняваме цялото съдържание на документа. Следователно имаме нужда от място за записване и съхранение на документите на потребителя. Нещо повече, понякога потребителите работят със SQL по различен начин, отколкото с други езици. Например, ако напиша C# клас с повече от 1000 реда, едва ли ще бъде приемливо. Докато във вселената на SQL, наред с 10-20-редови заявки, съществуват чудовищни изхвърляния на база данни. Такива дъмпове трудно могат да се редактират, което означава, че потребителите биха предпочели да пазят редакциите си в безопасност.
Изисквания към съхранение:
- Трябва да е леко вградено решение.
- Трябва да има висока скорост на писане.
- Трябва да има опция за многопроцесорен достъп. Това изискване не е критично, тъй като можем да осигурим достъп с помощта на обектите за синхронизация, но все пак би било хубаво да имаме тази опция.
Кандидати
Първият кандидат е доста тромав, тоест да съхранява всичко в папка, някъде в AppData.
Вторият кандидат е очевиден – SQLite, стандарт за вградени бази данни. Много солиден и популярен кандидат.
Третият кандидат е базата данни LiteDB. Това е първият резултат за заявката „вградена база данни за .net“ в Google.
Първи поглед
Файлова система. Файловете са файлове, изискват поддръжка и правилно именуване. Освен съдържанието на файла, ще трябва да съхраняваме малък набор от свойства (оригинален път на диска, низ за връзка, версия на IDE, в която е отворен). Това означава, че ще трябва или да създадем два файла за един документ, или да измислим формат, който разделя свойствата от съдържанието.
SQLite е класическа релационна база данни. Базата данни е представена от един файл на диск. Този файл се обвързва със схемата на базата данни, след което трябва да взаимодействаме с него с помощта на SQL средствата. Ще можем да създадем 2 таблици, едната за свойства, а другата за съдържание – в случай че ще трябва да използваме свойства или съдържание отделно.
LiteDB е нерелационна база данни. Подобно на SQLite, базата данни е представена от един файл. Написано е изцяло на С#. Той има завладяваща простота на използване:просто трябва да дадем обект на библиотеката, докато сериализацията ще се извърши по собствени средства.
Тест за ефективност
Преди да предоставя код, бих искал да обясня общата концепция и да предоставя резултати за сравнение.
Общата концепция е сравняване на скоростта на записване на голямо количество малки файлове в база данни, средно количество средни файлове и малко количество големи файлове. Случаят със средни файлове е предимно близък до реалния случай, докато случаите с малки и големи файлове са гранични случаи, което също трябва да се вземе предвид.
Записвах съдържание във файл с помощта на FileStream със стандартния размер на буфера.
Имаше един нюанс в SQLite, който бих искал да спомена. Не успяхме да поставим цялото съдържание на документа (както споменах по-горе, те могат да бъдат наистина големи) в една клетка на базата данни. Работата е там, че за целите на оптимизация съхраняваме текст на документа ред по ред. Това означава, че за да поставим текст в една клетка, трябва да поставим целия документ в един ред, което би удвоило количеството на използваната оперативна памет. Другата страна на проблема ще се разкрие по време на четене на данни от базата данни. Ето защо в SQLite имаше отделна таблица, където данните се съхраняваха ред по ред и данните се свързваха с помощта на външен ключ с таблицата, съдържаща само свойства на файла. Освен това успях да ускоря базата данни с пакетно вмъкване на данни (няколко хиляди реда наведнъж) в режим на ИЗКЛЮЧЕНО синхронизиране без регистриране и в рамките на една транзакция.
LiteDB получи обект със списък сред свойствата и библиотеката го запази на диск самостоятелно.
По време на разработването на тестовото приложение разбрах, че предпочитам LiteDB. Работата е там, че тестовият код за SQLite заема повече от 120 реда, докато кодът, който решава същия проблем в LiteDb, заема само 20 реда.
Генериране на тестови данни
FileStrings.cs
вътрешен клас FileStrings { private static readonly Random random =new Random(); публичен списък низове { get; комплект; } =нов списък(); public int SomeInfo { get; комплект; } public FileStrings() { } public FileStrings(int id, int minLines, decimal lineIncrement) { SomeInfo =id; int линии =minLines + (int)(id * lineIncrement); for (int i =0; i new FileStrings(f, MIN_NUM_LINES, (MAX_NUM_LINES - MIN_NUM_LINES) / (десетични)NUM_FILES)) .ToList();
SQLite
private static void SaveToDb(списъчни файлове) { using (var connection =new SQLiteConnection()) { connection.ConnectionString =@"Data Source=data\database.db;FailIfMissing=False;"; връзка.Отвори(); команда var =connection.CreateCommand(); command.CommandText =@"СЪЗДАВАНЕ на TABLE файлове (ID INTEGER PRIMARY KEY, file_name TEXT);CREATE TABLE strings(id INTEGER PRIMARY KEY, низ TEXT, file_id INTEGER, line_number INTEGER);CREATE UNIQUE INDEX strings_number_file_id_line_line_file_id); PRAGMA synchronous =OFF;PRAGMA journal_mode =OFF"; команда.ИзпълнениеNonQuery(); var insertFilecommand =connection.CreateCommand(); insertFilecommand.CommandText ="INSERT INTO files(file_name) VALUES(?); SELECT last_insert_rowid();"; insertFilecommand.Parameters.Add(insertFilecommand.CreateParameter()); insertFilecommand.Prepare(); var insertLineCommand =connection.CreateCommand(); insertLineCommand.CommandText ="ВМЕСЕТЕ В низове (низ, идентификатор на_файла, номер_на_ред) СТОЙНОСТИ(?, ?, ?);"; insertLineCommand.Parameters.Add(insertLineCommand.CreateParameter()); insertLineCommand.Parameters.Add(insertLineCommand.CreateParameter()); insertLineCommand.Parameters.Add(insertLineCommand.CreateParameter()); insertLineCommand.Prepare(); foreach (var item във файлове) { using (var tr =connection.BeginTransaction()) { SaveToDb(item, insertFilecommand, insertLineCommand); tr.Commit(); } } } } private static void SaveToDb(FileStrings item, SQLiteCommand insertFileCommand, SQLiteCommand insertLinesCommand) { string fileName =Path.Combine("data", item.SomeInfo + ".sql"); insertFileCommand.Parameters[0].Value =FileName; var fileId =insertFileCommand.ExecuteScalar(); int lineIndex =0; foreach (var line в item.Strings) { insertLinesCommand.Parameters[0].Value =line; insertLinesCommand.Parameters[1].Value =fileId; insertLinesCommand.Parameters[2].Value =lineIndex++; insertLinesCommand.ExecuteNonQuery(); } }
LiteDB
private static void SaveToNoSql(List item) { using (var db =new LiteDatabase("data\\litedb.db")) { var data =db.GetCollection("files"); data.EnsureIndex(f => f.SomeInfo); данни. Вмъкване(елемент); } }
Следващата таблица показва средните резултати за няколко пуска на тестовия код. По време на модификациите статистическото отклонение беше доста незабележимо.
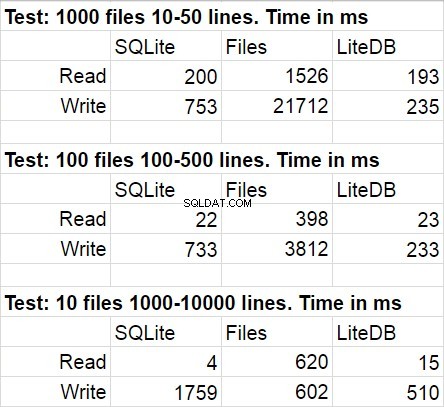
Не бях изненадан, че LiteDB спечели в това сравнение. Въпреки това бях шокиран от победата на LiteDB над файловете. След кратко проучване на библиотечното хранилище установих, че е много щателно приложено записване на страници на диск, но съм сигурен, че това е само един от многото трикове за ефективност, използвани там. Още нещо, което бих искал да отбележа, е бързата скорост на намаляване на достъпа до файловата система, когато количеството файлове в папката стане наистина голямо.
Избрахме LiteDB за разработването на нашата функция и почти не съжаляваме за този избор. Работата е там, че библиотеката е написана на роден за всички C# и ако нещо не беше съвсем ясно, винаги можем да се обърнем към изходния код.
Против
Освен гореспоменатите плюсове на LiteDB в сравнение с неговите претенденти, започнахме да забелязваме минуси по време на разработката. Повечето от тези недостатъци могат да бъдат обяснени с „младостта“ на библиотеката. След като започнахме да използваме библиотеката малко извън границите на „стандартния“ сценарий, открихме няколко проблема (#419, #420, #483, #496). Авторът на библиотеката отговаряше на въпроси доста бързо и повечето от проблемите бяха бързо разрешени. Сега е останала само една задача (не се бъркайте с нейния статус затворен). Това е въпрос на конкурентния достъп. Изглежда, че много гадно състояние на състезанието се крие някъде дълбоко в библиотеката. Подминахме този бъг по доста оригинален начин (възнамерявам да напиша отделна статия по тази тема).
Бих искал да спомена и липсата на изряден редактор и зрител. Има LiteDBShell, но е само за истински фенове на конзолите.
Резюме
Изградихме голяма и важна функционалност върху LiteDB и сега работим върху друга голяма функция, където ще използваме и тази библиотека. За тези, които търсят база данни в процес, предлагам да обърнат внимание на LiteDB и на начина, по който той ще се докаже в контекста на вашата задача, тъй като, както знаете, ако нещо се е получило за една задача, не е задължително работете за друга задача.