В Stack Overflow имаме някои таблици, използващи клъстерирани индекси на columnstore и те работят чудесно за по-голямата част от нашето работно натоварване. Но наскоро се натъкнахме на ситуация, при която „перфектни бури“ – множество процеси, които се опитват да изтрият от една и съща CCI – биха затрупали процесора, тъй като всички те вървяха широко паралелно и се бореха, за да завършат своята работа. Ето как изглеждаше в SolarWinds SQL Sentry:
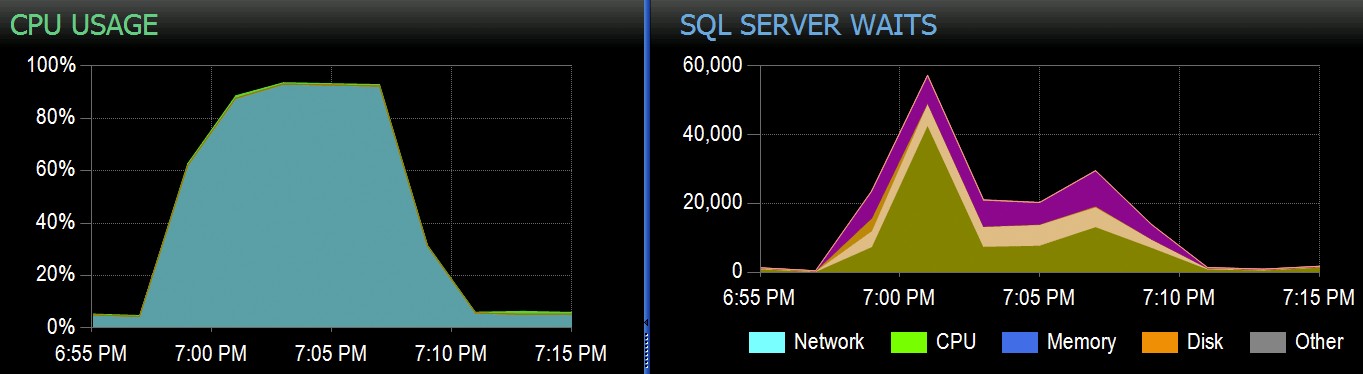
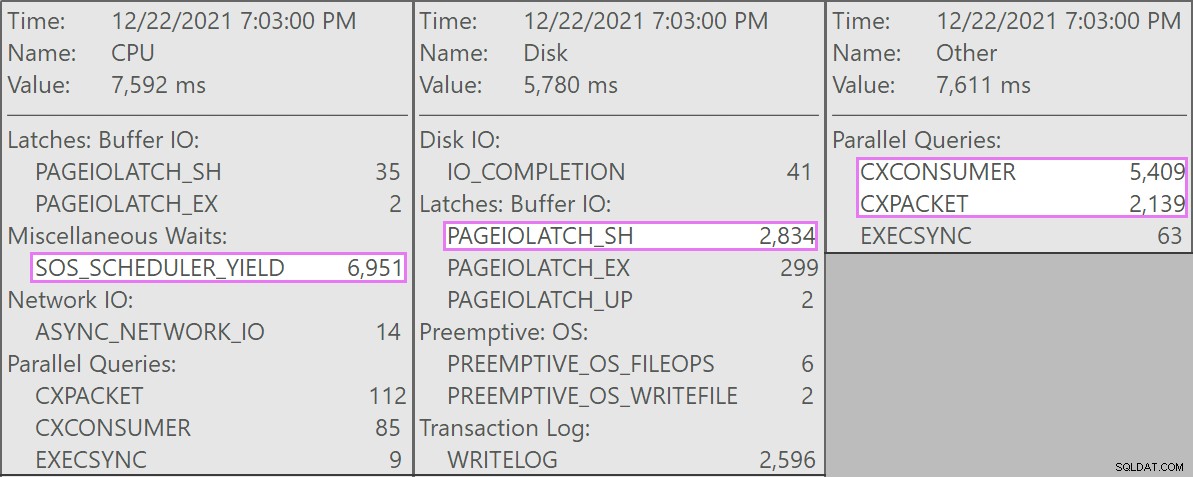
А ето и интересните изчаквания, свързани с тези заявки:
Всички конкуриращи се заявки бяха от тази форма:
ИЗТРИВАНЕ на dbo.LargeColumnstoreTable КЪДЕ col1 =@p1 И col2 =@p2;
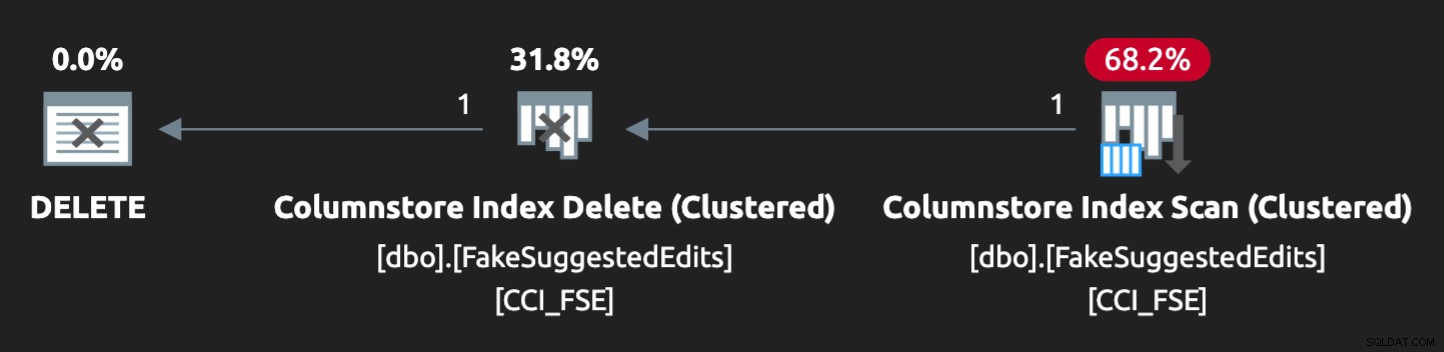
Планът изглеждаше така:

И предупреждението при сканирането ни посъветва за някои доста екстремни остатъчни I/O:

Таблицата има 1,9 милиарда реда, но е само 32 GB (благодаря, колонно хранилище!). Все пак тези изтривания на един ред биха отнели 10 – 15 секунди всяко, като по-голямата част от това време се изразходва за SOS_SCHEDULER_YIELD .
За щастие, тъй като в този сценарий операцията за изтриване може да бъде асинхронна, успяхме да решим проблема с две промени (въпреки че тук силно опростявам):
- Ограничихме
MAXDOPна ниво база данни, така че тези изтривания не могат да вървят толкова паралелно - Подобрихме сериализирането на процесите, идващи от приложението (по принцип изтривахме на опашка чрез един диспечер)
Като DBA, ние можем лесно да контролираме MAXDOP , освен ако не е отменен на ниво заявка (друга заешка дупка за друг ден). Не е задължително да контролираме приложението до такава степен, особено ако е разпространено или не е наше. Как можем да сериализираме записите в този случай, без драстично да променим логиката на приложението?
Фактна настройка
Няма да се опитвам да създам локално таблица с два милиарда реда — без значение точната таблица — но можем да приблизим нещо в по-малък мащаб и да се опитаме да възпроизведем същия проблем.
Нека се преструваме, че това е SuggestedEdits маса (в действителност не е така). Но това е лесен пример за използване, защото можем да изтеглим схемата от Stack Exchange Data Explorer. Използвайки това като основа, можем да създадем еквивалентна таблица (с няколко незначителни промени, за да улесним попълването) и да хвърлим клъстериран индекс на columnstore върху нея:
СЪЗДАВАНЕ НА ТАБЛИЦА dbo.FakeSuggestedEdits( Id int IDENTITY(1,1), PostId int NOT NULL DEFAULT CONVERT(int, ABS(КОНТРОЛНА СУМА(NEWID()))) % 200, CreationDate datetime2 NOT NULL DEFAULT sysrovalDate(), datetime2 NOT NULL DEFAULT sysdatetime(), RejectionDate datetime2 NULL, OwnerUserId int NOT NULL DEFAULT 7, Comment nvarchar (800) NOT NULL DEFAULT NEWID(), Text nvarchar (max) NOT NULL DEFAULT(NOT Ti2char NEW0n) DEFAULT NEWID(), Етикети nvarchar (250) NOT NULL DEFAULT NEWID(), RevisionGUID uniqueidentifier NOT NULL DEFAULT NEWSEQUENTIALID(), INDEX CCI_FSE CLUSTERED COLUMNSTORE);
За да го попълним със 100 милиона реда, можем да кръстосваме join sys.all_objects и sys.all_columns пет пъти (в моята система това ще произвежда 2,68 милиона реда всеки път, но YMMV):
-- 2680350 * 5 ~ 3 минути INSERT dbo.FakeSuggestedEdits(CreationDate) SELECT TOP (10) /*(2000000) */ modify_date ОТ sys.all_objects КАТО o CROSS JOIN sys.columns ASpre c;>След това можем да проверим мястото:
EXEC sys.sp_spaceused @objname =N'dbo.FakeSuggestedEdits';Това е само 1,3 GB, но това трябва да е достатъчно:
Имитиране на нашето клъстерно изтриване на Columnstore
Ето една проста заявка, която приблизително съответства на това, което нашето приложение правеше с таблицата:
ДЕКЛАРИРАНЕ @p1 int =ABS(КОНТРОЛНА СУМА(НОВИД())) % 10000000, @p2 int =7;ИЗТРИВАНЕ на dbo.FakeSuggestedEdits WHERE Id =@p1 И OwnerUserId =@p2;Планът обаче не е съвсем идеален:
За да го накарам да върви паралелно и да предизвика подобно спорове на моя оскъден лаптоп, трябваше да принудя малко оптимизатора с този намек:
ОПЦИЯ (QUERYTRACEON 8649);Сега изглежда правилно:
Възпроизвеждане на проблема
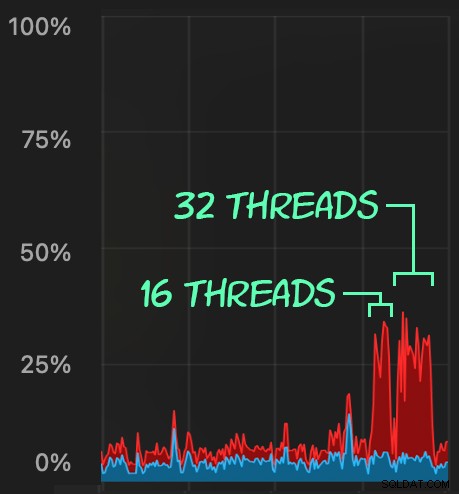
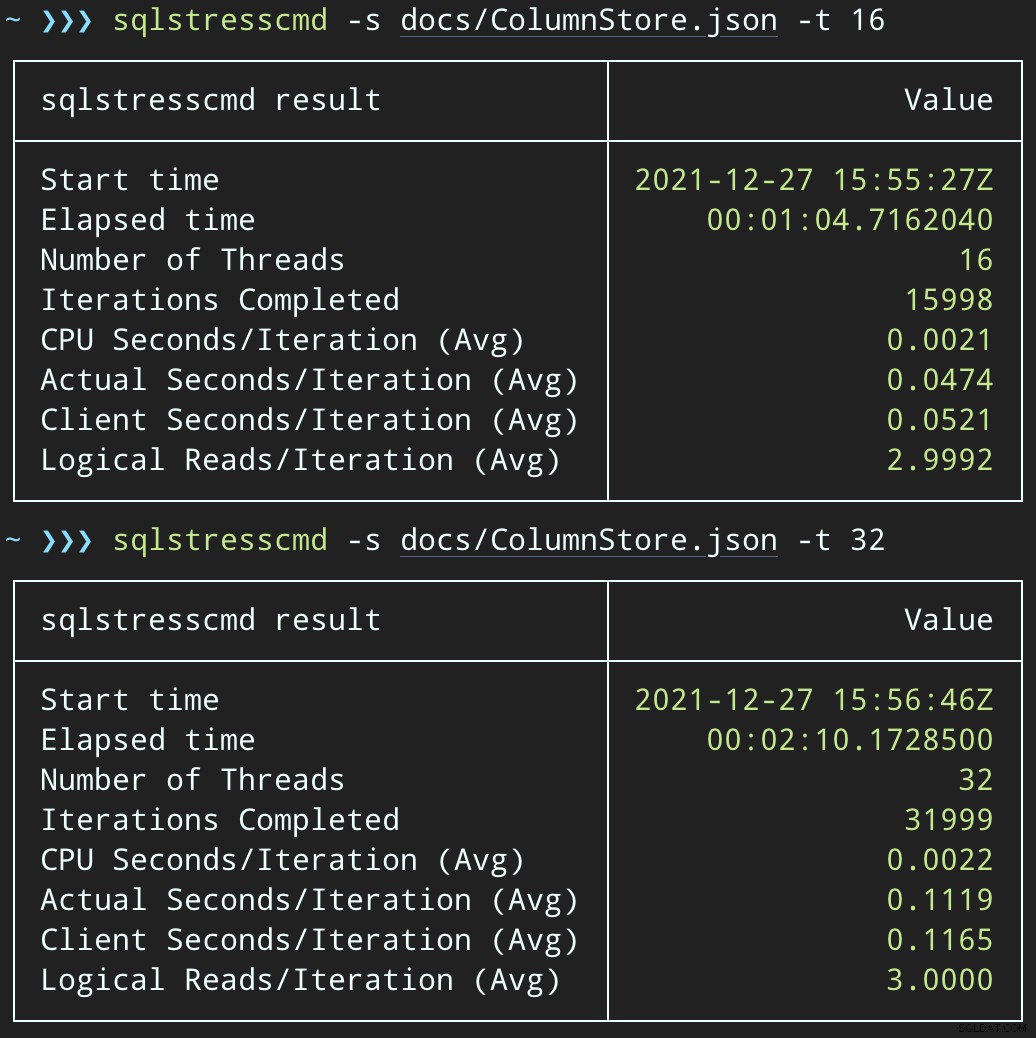
След това можем да създадем вълна от едновременна активност за изтриване, използвайки SqlStressCmd, за да изтрием 1000 произволни реда, използвайки 16 и 32 нишки:
sqlstresscmd -s docs/ColumnStore.json -t 16sqlstresscmd -s docs/ColumnStore.json -t 32Можем да наблюдаваме напрежението, което това поставя върху процесора:
Натоварването на процесора продължава през целия период от около 64 и 130 секунди, съответно:
Забележка:Резултатът от SQLQueryStress понякога е малко по-различен от итерациите, но потвърдих, че работата, която искате да свърши, е свършена точно.
Потенциално решение:Опашка за изтриване
Първоначално мислех за въвеждане на таблица на опашката в базата данни, която бихме могли да използваме за разтоварване на активността за изтриване:
СЪЗДАВАНЕ НА ТАБЛИЦА dbo.SuggestedEditDeleteQueue( QueueID int IDENTITY(1,1) ПЪРВИЧЕН КЛЮЧ, EnqueuedDate datetime2 NOT NULL DEFAULT sysdatetime(), ProcessedDate datetime2 NULL, Id int NOT NOT NULL, Owtner);Всичко, от което се нуждаем, е ВМЕСТО тригер, за да прихване тези измамни изтривания, идващи от приложението, и да ги постави на опашката за фонова обработка. За съжаление, не можете да създадете задействане в таблица с клъстериран индекс на columnstore:
Съобщение 35358, ниво 16, състояние 1
СЪЗДАВАНЕ НА TRIGGER в таблица 'dbo.FakeSuggestedEdits' не бе успешно, защото не можете да създадете задействане в таблица с клъстериран индекс на columnstore. Помислете за налагане на логиката на тригера по някакъв друг начин или ако трябва да използвате тригер, вместо това използвайте хеп или индекс на B-дърво.Ще ни трябва минимална промяна в кода на приложението, така че да извика съхранена процедура за обработка на изтриването:
СЪЗДАВАНЕ НА ПРОЦЕДУРА dbo.DeleteSuggestedEdit @Id int, @OwnerUserId intASBEGIN SET NOCOUNT ON; ИЗТРИВАТЕ dbo.FakeSuggestedEdits КЪДЕТО Id =@Id И OwnerUserId =@OwnerUserId;ENDТова не е постоянно състояние; това е само за да запазим поведението същото, докато променяме само едно нещо в приложението. След като приложението бъде променено и успешно извиква тази съхранена процедура, вместо да изпраща ad hoc заявки за изтриване, съхранената процедура може да се промени:
СЪЗДАВАНЕ НА ПРОЦЕДУРА dbo.DeleteSuggestedEdit @Id int, @OwnerUserId intASBEGIN SET NOCOUNT ON; INSERT dbo.SuggestedEditDeleteQueue(Id, OwnerUserId) ИЗБЕРЕТЕ @Id, @OwnerUserId;ENDТестване на въздействието на опашката
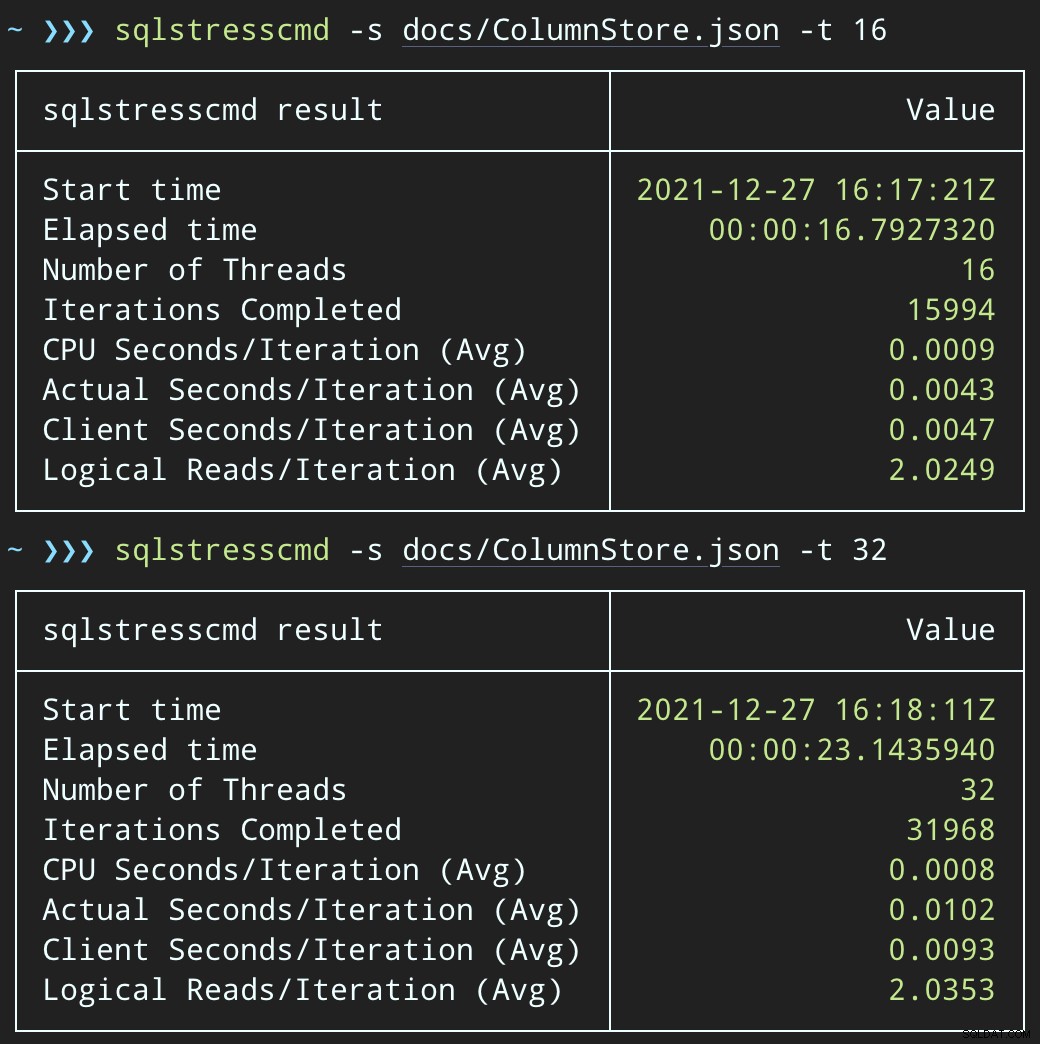
Сега, ако променим SqlQueryStress да извика съхранената процедура вместо това:
ДЕКЛАРИРАНЕ @p1 int =ABS(КОНТРОЛНА СУМА(НОВИД())) % 10000000, @p2 int =7;EXEC dbo.DeleteSuggestedEdit @Id =@p1, @OwnerUserId =@p2;И изпратете подобни партиди (поставяне на 16K или 32K реда на опашката):
ДЕКЛАРИРАНЕ @p1 int =ABS(КОНТРОЛНА СУМА(НОВИД())) % 10000000, @p2 int =7;EXEC dbo.@Id =@p1 И OwnerUserId =@p2;Въздействието на процесора е малко по-високо:
Но работните натоварвания завършват много по-бързо — съответно 16 и 23 секунди:
Това е значително намаляване на болката, която приложенията ще почувстват, когато попаднат в периоди на висока едновременност.
Все пак трябва да извършим изтриването
Все още трябва да обработваме тези изтривания на заден план, но вече можем да въведем групиране и да имаме пълен контрол върху скоростта и всяко забавяне, което искаме да инжектираме между операциите. Ето най-основната структура на съхранена процедура за обработка на опашката (признано без пълен контрол върху транзакциите, обработка на грешки или почистване на таблицата на опашката):
СЪЗДАВАНЕ НА ПРОЦЕДУРА dbo.ProcessSuggestedEditQueue @JobSize int =10000, @BatchSize int =100, @DelayInSeconds int =2 -- трябва да бъде между 1 и 59ASBEGIN SET NOCOUNT ON; DECLARE @d TABLE(Id int, OwnerUserId int); ДЕКЛАРИРАНЕ @rc int =1, @jc int =0, @wf nvarchar(100) =N'WAITFOR DELAY ' + CHAR(39) + '00:00:' + RIGHT('0' + CONVERT(varchar(2)) , @DelayInSeconds), 2) + CHAR(39); ДОКАТО @rc> 0 И @jc <@JobSize ЗАПОЧНЕТЕ ИЗТРИВАНЕ @d; UPDATE TOP (@BatchSize) q SET ProcessedDate =sysdatetime() ИЗХОД вмъкнат.Id, inserted.OwnerUserId В @d ОТ dbo.SuggestedEditDeleteQueue КАТО q С (UPDLOCK, READPAST) КЪДЕТО Е ProcessedDate; SET @rc =@@ROWCOUNT; АКО @rc =0 BREAK; ИЗТРИВАНЕ fse ОТ dbo.FakeSuggestedEdits КАТО fse INNER JOIN @d AS d ON fse.Id =d.Id И fse.OwnerUserId =d.OwnerUserId; SET @jc +=@rc; IF @jc> @JobSize BREAK; EXEC sys.sp_executesql @wf; END RAISERROR('Изтрити %d реда.', 0, 1, @jc) WITH NOWAIT;ENDСега изтриването на редове ще отнеме повече време - средната стойност за 10 000 реда е 223 секунди, ~100 от които са умишлено забавяне. Но никой потребител не чака, така че на кого му пука? Профилът на процесора е почти нулев и приложението може да продължи да добавя елементи на опашката толкова много едновременно, колкото иска, с почти нулев конфликт с фоновата работа. Докато обработвах 10 000 реда, добавих още 16 000 реда към опашката и той използва същия процесор като преди – отнема само секунда повече, отколкото когато заданието не се изпълняваше:
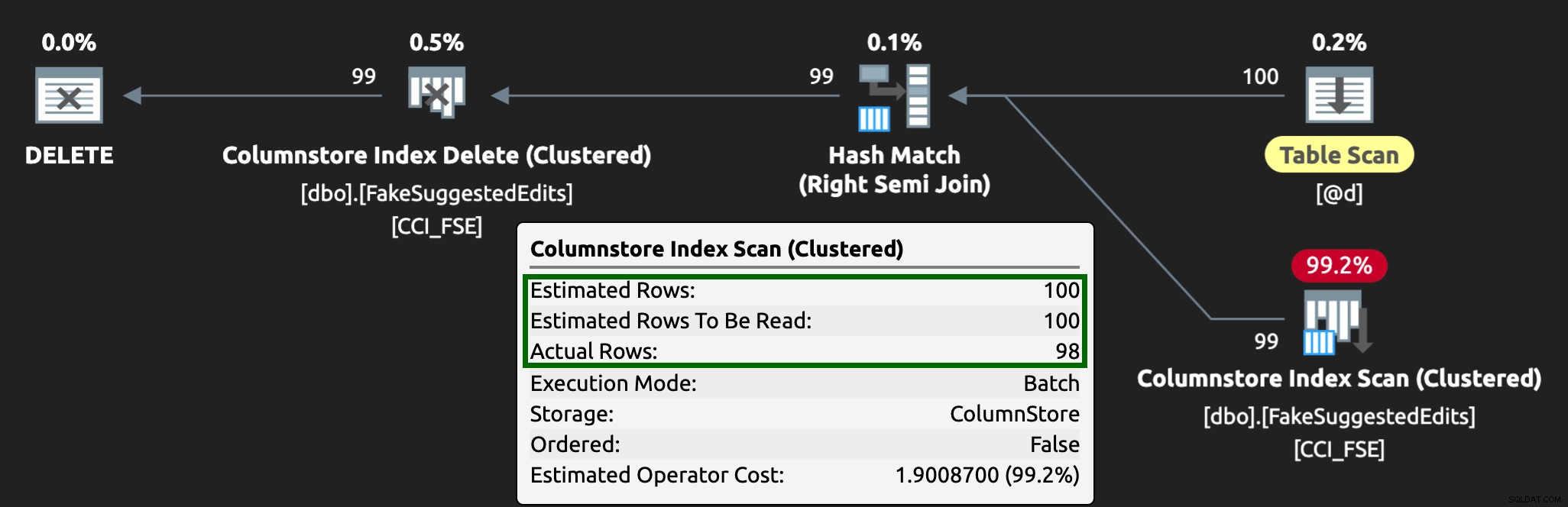
И сега планът изглежда така, с много по-добри прогнозни/действителни редове:
Виждам, че този подход на таблицата на опашките е ефективен начин за справяне с висок DML едновременност, но изисква поне малко гъвкавост с приложенията, изпращащи DML - това е една от причините, поради които наистина харесвам приложенията да извикват съхранени процедури, тъй като те ни даде много повече контрол по-близо до данните.
Други опции
Ако нямате възможност да промените заявките за изтриване, идващи от приложението – или ако не можете да отложите изтриванията във фонов процес – можете да помислите за други опции за намаляване на въздействието на изтриванията:


- Неклъстериран индекс на предикатните колони за поддръжка на търсене на точки (можем да направим това изолирано, без да променяме приложението)
- Използване само на меки изтривания (все пак изисква промени в приложението)
Ще бъде интересно да се види дали тези опции предлагат подобни предимства, но ще ги запазя за бъдеща публикация.



