Екранна снимка №1 показва няколко точки за разграничаване между Merge Join transformation и Lookup transformation .
Относно търсенето:
Ако искате да намерите редове, съвпадащи в източник 2 въз основа на входния източник 1 и ако знаете, че ще има само едно съвпадение за всеки входен ред, тогава бих предложил да използвате операция Търсене. Пример за това е OrderDetails таблица и искате да намерите съответстващия Order Id и Customer Number , тогава търсенето е по-добър вариант.
Относно Merge Join:
Ако искате да извършвате обединения като извличане на всички адреси (домашен, работен, друг) от Address таблица за даден Клиент в Customer таблицата, тогава трябва да отидете с Merge Join, защото клиентът може да има 1 или повече адреса, свързани с тях.
Пример за сравнение:
Ето сценарий за демонстриране на разликите в производителността между Merge Join и Lookup . Използваните тук данни са едно към едно свързване, което е единственият общ сценарий между тях за сравняване.
-
Имам три таблици с име
dbo.ItemPriceInfo,dbo.ItemDiscountInfoиdbo.ItemAmount. Създаването на скриптове за тези таблици е предоставено в секцията SQL скриптове. -
Таблици
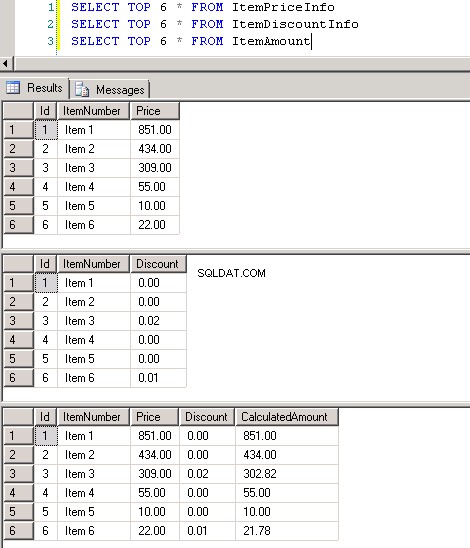
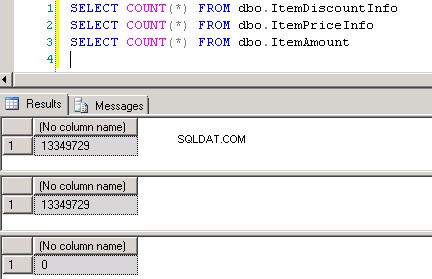
dbo.ItemPriceInfoиdbo.ItemDiscountInfoи двете имат 13 349 729 реда. И двете таблици имат ItemNumber като обща колона. ItemPriceInfo има информация за цената, а ItemDiscountInfo има информация за отстъпка. Екранна снимка №2 показва броя на редовете във всяка от тези таблици. Екранна снимка №3 показва първите 6 реда, за да даде представа за данните, присъстващи в таблиците. -
Създадох два пакета SSIS, за да сравня производителността на трансформациите за присъединяване и търсене. И двата пакета трябва да вземат информацията от таблици
dbo.ItemPriceInfoиdbo.ItemDiscountInfo, изчислете общата сума и я запишете в таблицатаdbo.ItemAmount. -
Първият пакет използва
Merge Joinтрансформация и вътре в нея използва INNER JOIN за комбиниране на данните. Екранни снимки №4 и #5 показва изпълнението на примерния пакет и продължителността на изпълнението. Отне05минути14секунди719милисекунди, за да изпълни пакета, базиран на трансформация Merge Join. -
Вторият пакет използва
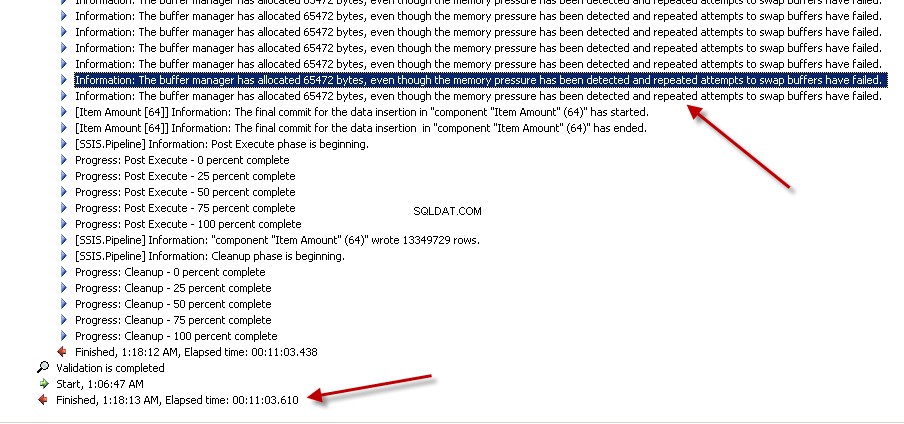
Lookupтрансформация с Пълен кеш (което е настройката по подразбиране). снимки на екрана №6 и #7 показва изпълнението на примерния пакет и продължителността на изпълнението. Отне11минути03секунди610милисекунди за изпълнение на пакета, базиран на трансформация Lookup. Може да срещнете предупредителното съобщение Информация:The buffer manager has allocated nnnnn bytes, even though the memory pressure has been detected and repeated attempts to swap buffers have failed.Ето и връзка който говори за това как да се изчисли размерът на кеша за търсене. По време на изпълнението на този пакет, въпреки че задачата за поток от данни е изпълнена по-бързо, почистването на конвейера отне много време. -
Товане означава, че трансформацията на търсене е лоша. Просто трябва да се използва разумно. Използвам това доста често в моите проекти, но отново не се занимавам с 10+ милиона реда за търсене всеки ден. Обикновено моите работни места обработват между 2 и 3 милиона реда и за това производителността е наистина добра. До 10 милиона реда, и двата се представят еднакво добре. През повечето време забелязах, че тесното място се оказва компонентът на местоназначението, а не трансформациите. Можете да преодолеете това, като имате няколко дестинации. Тук е пример, който показва изпълнението на множество дестинации.
-
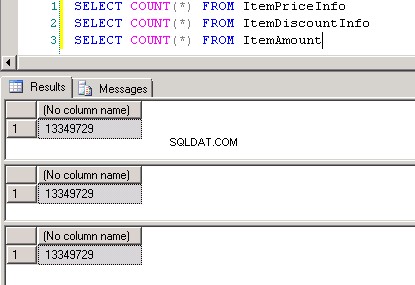
Екранна снимка №8 показва броя на записите и в трите таблици. Екранна снимка №9 показва първите 6 записа във всяка от таблиците.
Надявам се това да помогне.
SQL скриптове:
CREATE TABLE [dbo].[ItemAmount](
[Id] [int] IDENTITY(1,1) NOT NULL,
[ItemNumber] [nvarchar](30) NOT NULL,
[Price] [numeric](18, 2) NOT NULL,
[Discount] [numeric](18, 2) NOT NULL,
[CalculatedAmount] [numeric](18, 2) NOT NULL,
CONSTRAINT [PK_ItemAmount] PRIMARY KEY CLUSTERED ([Id] ASC)) ON [PRIMARY]
GO
CREATE TABLE [dbo].[ItemDiscountInfo](
[Id] [int] IDENTITY(1,1) NOT NULL,
[ItemNumber] [nvarchar](30) NOT NULL,
[Discount] [numeric](18, 2) NOT NULL,
CONSTRAINT [PK_ItemDiscountInfo] PRIMARY KEY CLUSTERED ([Id] ASC)) ON [PRIMARY]
GO
CREATE TABLE [dbo].[ItemPriceInfo](
[Id] [int] IDENTITY(1,1) NOT NULL,
[ItemNumber] [nvarchar](30) NOT NULL,
[Price] [numeric](18, 2) NOT NULL,
CONSTRAINT [PK_ItemPriceInfo] PRIMARY KEY CLUSTERED ([Id] ASC)) ON [PRIMARY]
GO
Екранна снимка №1:

Екранна снимка №2:
Екранна снимка №3:
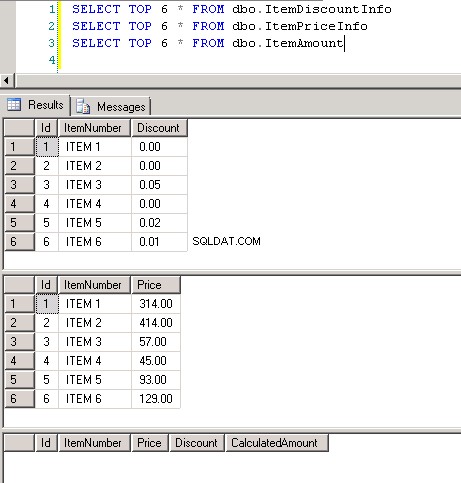
Екранна снимка №4:
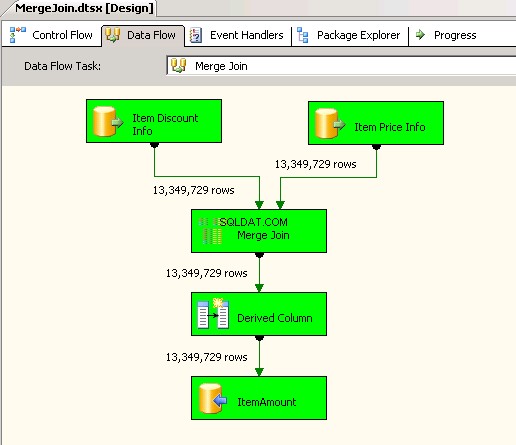
Екранна снимка №5:

Екранна снимка №6:
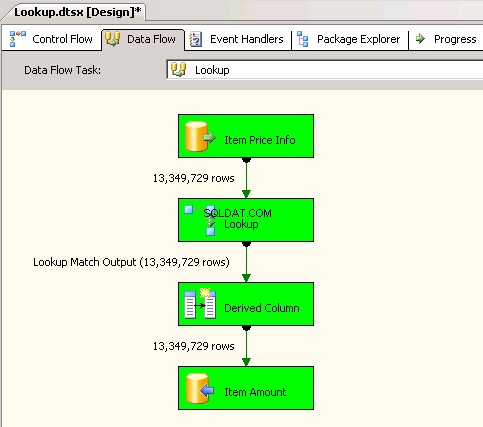
Екранна снимка №7:
Екранна снимка №8:
Екранна снимка №9: