„Waitstats ни помага да идентифицираме броячи, свързани с производителността. Но информацията за изчакване сама по себе си не е достатъчна за точно диагностициране на проблеми с производителността. Компонентът на опашките на нашата методология идва от броячите на Performance Monitor, които предоставят поглед върху производителността на системата от гледна точка на ресурсите.Том Дейвидсън, Отваряне на кутията с инструменти за настройка на производителността на Microsoft
SQL Server Pro Magazine, декември 2003 г.
Waits and Queues се използва като методология за настройка на производителността на SQL Server, откакто Том Дейвидсън публикува горната статия, както и добре познатата бяла книга на SQL Server 2005 Waits and Queues през 2006 г. Когато се прилага в комбинация с показатели за ресурсите, изчакванията могат да бъдат ценни за оценка на определени характеристики на работното натоварване и помощ при усилията за настройка на кормилното управление. Данните Waits се появяват от много решения за мониторинг на производителността на SQL Server и аз съм привърженик на настройката с помощта на тази методология от самото начало. Подходът оказа влияние при проектирането на таблото за управление на производителността на SQL Sentry, което представя изчаквания, оградени от опашки (ключови показатели за ресурсите), за да предостави изчерпателен поглед върху производителността на сървъра.
Въпреки това, някои изглежда са пропуснали точката на Дейвидсън относно важността на ресурсите и разчитат почти изцяло на изчакване, за да представят картина на производителността на заявката и здравето на системата. Статистиката за изчакване идва директно от двигателя на SQL Server и е лесна за използване и категоризиране. Чакащите заявки означават чакащи приложения и потребители и никой не обича да чака! По-лесно е да се евангелизира настройката с изчакване като единственото решение за по-бързо правене на заявки и приложения, отколкото да се разкаже цялата история, която е по-ангажираща.
За съжаление подходът, фокусиран върху изчакването, за изключване на анализа на ресурсите може да подведе и в най-лошия случай да останете слепи. Членовете на екипа на SentryOne Кевин Клайн и Стив Райт по-рано засегнаха това тук и тук. В тази публикация ще се потопя по-задълбочено в някои скорошни изследвания, направени от Query Store, които хвърлиха нова светлина върху това колко недостатъчна може наистина да бъде настройката, включваща изключителни изчаквания.
Най-популярните заявки, които не бяха
Наскоро клиент на SentryOne се свърза с мен относно проблеми с производителността на тяхната база данни SentryOne. В основата на всяка среда за наблюдение на SentryOne има единна база данни на SQL Server и този клиент наблюдаваше около 600 сървъра с нашия софтуер. При този мащаб не е необичайно да видите проблем с производителността на заявките от време на време и да направите малка настройка, а някои предполагаемо нови заявки в работното натоварване бяха източникът на притесненията им.
Присъединих се към сесия за споделяне на екрана, за да разгледам, и клиентът първо ми представи данни от друга система, която също наблюдаваше базата данни SentryOne. Системата използва подход на изчакване на ниво заявка и показва две съхранени процедури като отговорни за приблизително половината от изчакванията на сървъра на база данни SQL Sentry. Това беше необичайно, защото тези две процедури винаги се изпълняват много бързо и никога не са били показателни за реален проблем с производителността в нашата база данни. Озадачен, преминах към SQL Sentry, за да видя какво ще ни покаже, и бях изненадан да видя, че през същия интервал процедура №1 в другата система беше №6, №7 и №8 по отношение на общата продължителност, CPU и логически чете съответно:
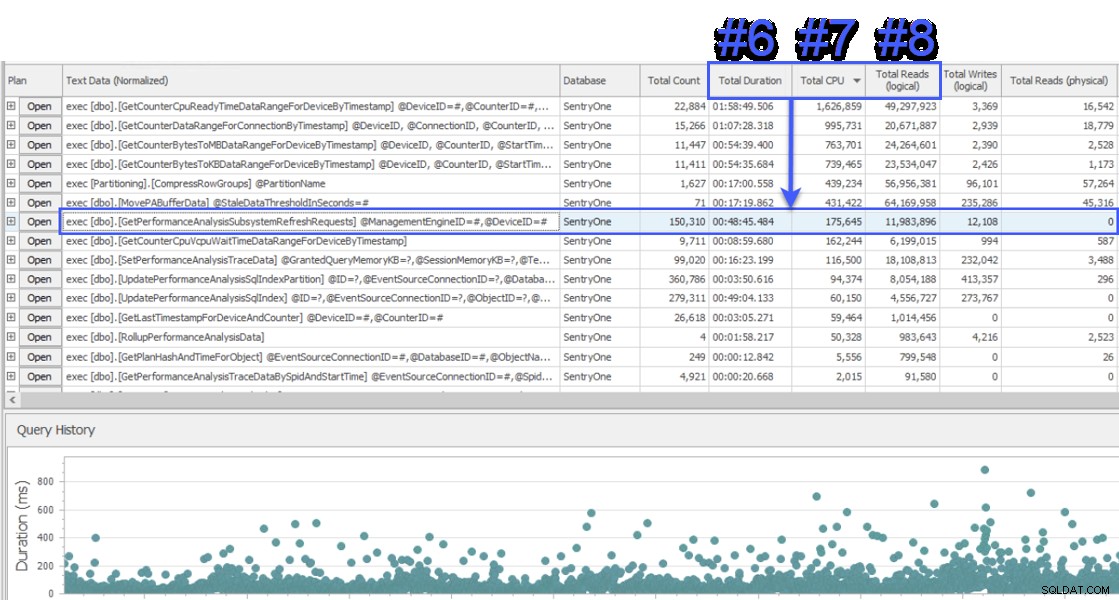 Изглед „Top SQL“ на SQL Sentry
Изглед „Top SQL“ на SQL Sentry
От гледна точка на потреблението на ресурси, това означаваше, че заявките над него представляват 75% от общата продължителност, 87% от общия процесор и 88% от логическите четения. Освен това процедурата №2 в другата система дори не беше в топ 30 в SQL Sentry, по всякаква мярка! Тези две заявки бяха далеч от първите 2, а заявките, които представляваха по-голямата част от действителните потреблението на системата беше силно недостатъчно представено.
Винаги съм предполагал, че има по-силна корелация между най-добрите сервитьори и най-добрите потребители на ресурси, но никога не съм правил директно сравнение на ниво заявка като това, така че тези резултати бяха меко казано изненадващи. Интересът ми възбуди, реших да проуча, за да определя дали тази ситуация е типична или аномална.
Query Store 2017 на помощ
В SQL Server 2017 и по-нови версии, Query Store улавя изчаквания на ниво заявка в допълнение към потреблението на ресурси за заявка. Ерин Стелато направи страхотна публикация в Query Store чака тук. Той е с по-ниски режийни разходи и е по-точен от заявките, изчакващи DMV всяка секунда, надявайки се да уловят заявки по време на полет, стандартният подход, използван от други инструменти, включително гореспоменатия.
SQL Sentry винаги е улавял изчаквания, но на ниво екземпляр на SQL Server, поради тези опасения относно режийните разходи и точността. Подробните изчаквания на заявка са достъпни при поискване чрез интегрирания Plan Explorer и ние оценяваме увеличаването на изчакванията на ниво екземпляр с данни на ниво заявка от Query Store, когато са налични.
За това начинание потърсих помощта на Консултативния съвет за продукти на SentryOne, група от клиенти, партньори и приятели на SentryOne в индустрията, които участват в частен канал на Slack. Споделих този скрипт, за да изхвърля предишните 8 часа данни от Query Store и получих обратно резултати за 11 производствени сървъра в множество вертикали, включително финансови услуги, публикуване на игри, проследяване на фитнес и застраховка.
Категориите на изчакване в магазина на заявки са документирани тук. Всички категории бяха включени в анализа с изключение на тези, които бяха премахнати поради цитираните причини:
- Паралелизъм – Може да увеличи времето на чакане на заявка доста над действителната й продължителност, тъй като множество нишки могат да изхвърлят свързаните изчаквания, объркваща корелация с продължителността и други показатели. Освен това, въпреки че разделянето CXPACKET/CXCONSUMER е полезно, CXPACKET все още означава само, че имате паралелизъм и не е непременно проблематично или приложимо.
- CPU – Времето за изчакване на сигнала може да бъде полезно за установяване на тесни места на процесора чрез корелация с изчакване на ресурси, но магазинът на заявки понастоящем включва само SOS_SCHEDULER_YIELD в тази категория, което не е чакане в традиционния смисъл, както е описано тук. Той не се поддава на лесно сравнение или корелация, особено когато SQL Server е на VM, която живее на хост с прекомерно абонамент. Например, на един сървър Query Store изчакванията на CPU бяха 227% от общото време на процесора за всички заявки без паралелизъм, което не би трябвало да е възможно.
- Изчакайте потребителя иНеактивен – Тези категории се състоят изключително от изчакване на таймер и опашка и са изключени поради същата причина, поради която винаги трябва да се изключват тези типове – те са безобидни и създават само шум.
Като настрана, наскоро говорих с бащата на Query Store, Конър Кънингам, за вероятността от бъдещи промени в типовете и категориите изчакване на Query Store и той посочи, че със сигурност е възможно... така че ще трябва да следим го.
Резултати от анализа TL;DR
След задълбочен анализ потвърдих, че резултатите, наблюдавани в клиентската система, не са аномални, а по-скоро обичайни. Това означава, че ако сте зависими от фокусиран върху чакането инструмент за наблюдение и настройка на вашите работни натоварвания, има голяма вероятност да се съсредоточите върху грешните заявки и да пропуснете отговорните за повечето на продължителността на заявката и потреблението на ресурси в системата. Тъй като потреблението на CPU и IO се превежда директно в хардуера на сървъра и разходите в облак, това е значително.
Повечето заявки не чакат
Интересна и важна констатация, която ще разгледам първо, е, че повечето заявки изобщо не генерират изчакване. От общо 56 438 заявки на всички сървъри, само 9 781 (17%) са имали време за изчакване, а само 8 092 (14%) са имали време за изчакване от значими типове. Ако използвате само изчакване, за да определите кои заявки да оптимизирате, ще пропуснете повечето заявки в работното натоварване.
Корелиране на изчаквания и ресурси
Анализирах как изчакванията са свързани с потреблението на ресурси, като класирах всички заявки във всяка система по изчаквания и ресурси и използвах ранговете за изчисляване на корелацията на Spearman. Това, което в крайна сметка се опитваме да определим, е дали топ сервитьорите са склонни да бъдат водещите потребители. Както се оказва, не го правят.
Таблица 1 показва коефициентите на корелация с цветова скала за средно изчакване на заявка време спрямо други мерки – стойност от 1,00 (тъмно синьо) представлява данни, които са перфектно корелирани. Както можете да видите, корелацията с изчаквания и други мерки в повечето сървъри не е силна, а за един сървър има отрицателна корелация с повечето мерки.
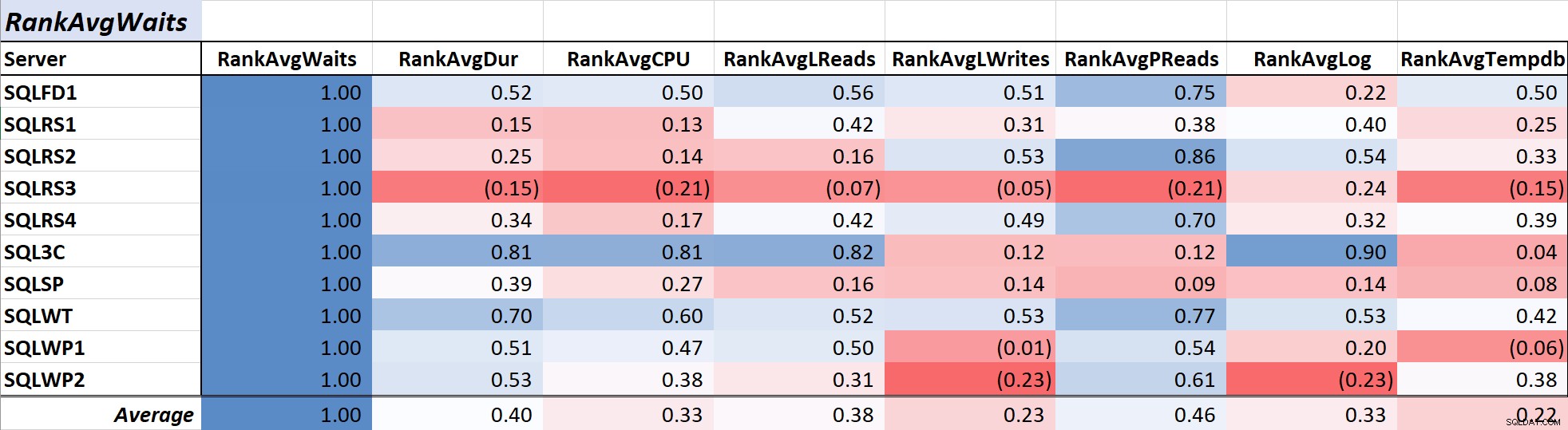 Таблица 1:Съотношение със Ср. време на изчакване на заявката (ms)
Таблица 1:Съотношение със Ср. време на изчакване на заявката (ms)
Продължителността на заявката често е основна грижа за администраторите на база данни и разработчиците, тъй като се превежда директно в потребителското изживяване и Таблица 2 показва корелацията между средната продължителност на заявката и другите мерки. Връзката с продължителността и двете основни мерки за ресурс, CPU и логическо четене, е доста силна при съответно 0,97 и 0,75.
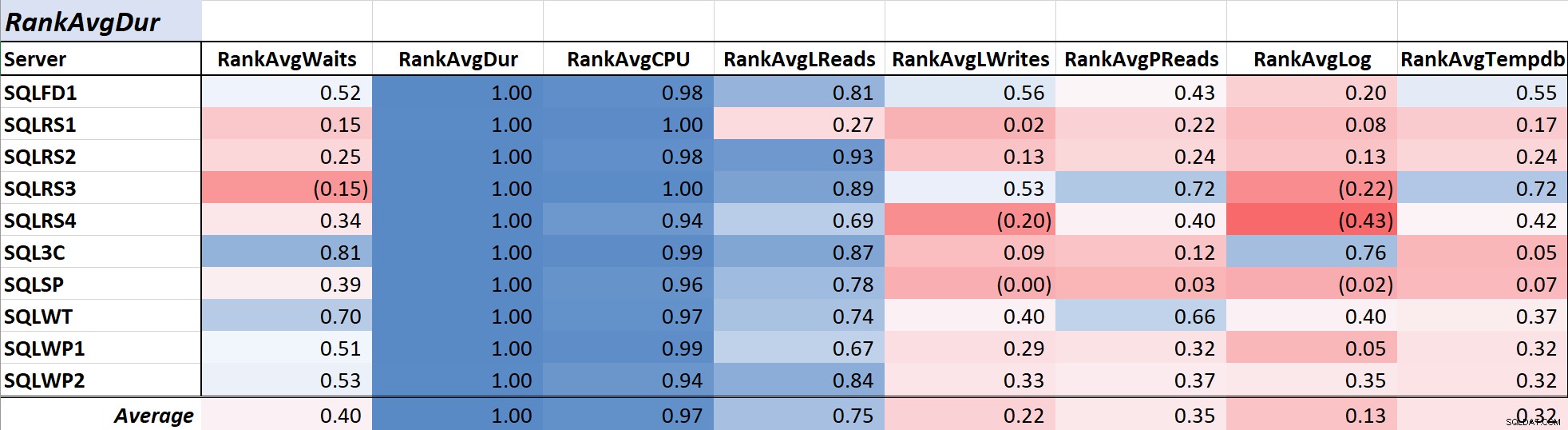 Таблица 2:Съотношение със средната продължителност на заявката (ms)
Таблица 2:Съотношение със средната продължителност на заявката (ms)
Тъй като логическите четения винаги използват CPU и, подобно на продължителността, CPU се измерва в милисекунди, тази връзка не е изненадваща. Резултатите са в съответствие с идеята, че ако искате вашите приложения за база данни да работят възможно най-бързо, фокусирането върху намаляването на процесора на заявка и логическите четения ще бъде по-ефективно за намаляване на продължителността, отколкото използването само на изчаквания. За щастие, да направите това чрез по-добър дизайн на заявка, индексиране и т.н. обикновено е по-просто предложение, отколкото директното намаляване на времето за изчакване на заявката. Колегата Аарон Бертран ефективно представя някои от предупрежденията при настройка с изчакване тук.
% от общото време на изчакване
След това разгледах дали заявките с най-голямо време на изчакване са склонни да отчитат най-голяма консумация на ресурси. Искаме да определим дали това, което видяхме в клиентската система, е нетипично, където първите 2 чакащи заявки представляват относително малък процент от общото потребление на ресурси.
Диаграма 1 по-долу показва % от общия процесор и логически четения за всеки сървър, отчетени от заявките, представляващи 75% от общото време за изчакване. Само един сървър имаше ресурс над 75% - чете на SQLRS3. За останалата част заявките, отговорни за 75% от времето за изчакване, изразходваха по-малко от 75% от ресурсите – често много по-малко. Това отразява това, което видяхме в клиентската система и е в съответствие с анализа на корелацията.
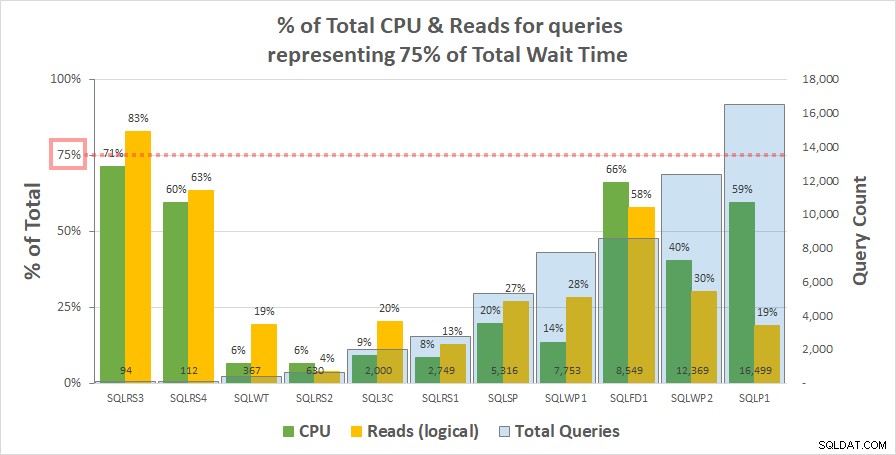 Диаграма 1
Диаграма 1
Имайте предвид, че изглежда има връзка с общия брой заявки в работното натоварване. Това е представено от светлосиня колонна серия на вторичната ос y и диаграмата е сортирана възходящо по тази серия. Двата сървъра с най-високи мерки за ресурс при 75% изчаквания също са имали най-малко заявки (SQLRS3 и SQLRS4). Колкото по-малко е зададеното работно натоварване, толкова по-голямо е потенциалното влияние на малък брой заявки и със сигурност и на двата сървъра само две заявки представляват по-голямата част от чаканията и ресурсите. Един от начините да погледнете това е, че изчакването помага на повечето, за да идентифицирате най-тежките ви заявки, когато най-малко имате нужда от него.
Време на изчакване и продължителност на заявката
Накрая оцених процента от общото време на изчакване към общата продължителност на заявката за всяка система. Таблица 3 има колони за:
- Обща продължителност на заявката в ms
- Общо време на изчакване ms – необработено
- Общо време на изчакване ms – без паралелизъм, неактивен режим и изчакване на потребител (Rev1)
- Общо време на изчакване ms – без паралелизъм, празен ход, изчакване на потребителя и CPU (Rev2)
- Процентът на продължителността на 3-те колони за време на изчакване с ленти с данни
- Общ брой уникални заявки с ленти с данни
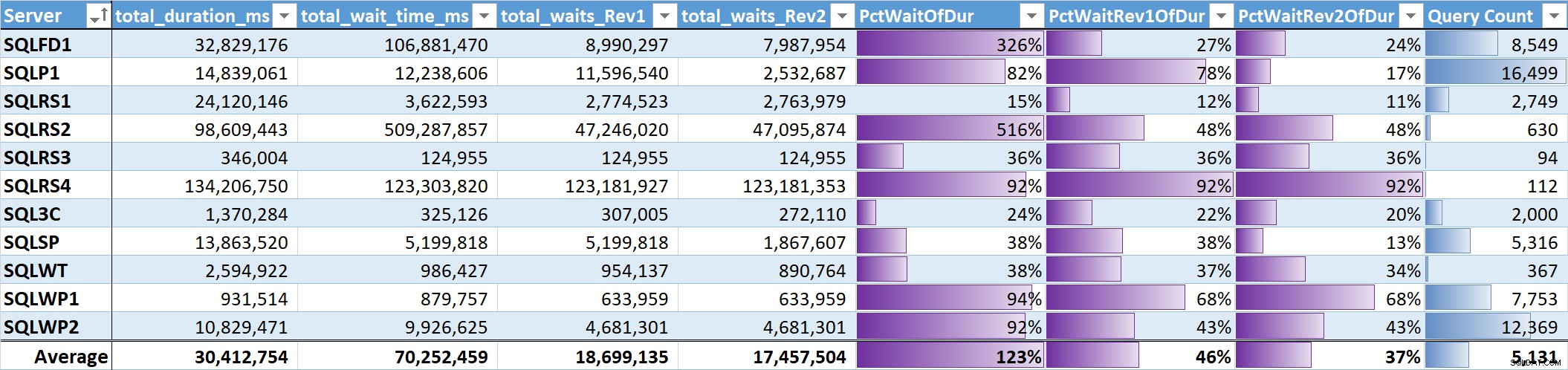 Таблица 3
Таблица 3
Непретеглената средна стойност за смислените изчаквания (Rev2) във всички системи е 37% от общата продължителност на заявката. При пет от системите е по-малко от 25%, а само при две системи е над 50%. В системата с 92% време за изчакване (SQLRS4), една с най-малко заявки, две заявки представляват 99% от чаканията, 97% от продължителността, 84% от процесора и 86% от четенията.
Въпреки че времето за изчакване може да представлява значителна част от времето за изпълнение на заявката в определени системи и изглежда интуитивно, че ако намалите времето за изчакване, продължителността на заявката също ще намалее, видяхме, че времето за изчакване и продължителността са слабо свързани. Малко вероятно е да е толкова просто и моят собствен опит го потвърждава. Тук са необходими повече изследвания.
Изчерпателна настройка с Plan Explorer и SQL Sentry
Както често подсказва тази отлична бяла книга за SQLskills, коренът на голямото чакане често са неоптимизирани заявки и индекси. Безплатният SentryOne Plan Explorer е специално създаден за намаляване на потреблението на ресурси чрез ефективна настройка на заявки, използвайки своя модул за анализ на индекси и много други иновативни функции. SQL Sentry интегрира Plan Explorer директно в модулите Top SQL, Blocking и Deadlocks, така че можете автоматично да улавяте и настройвате проблемни заявки на едно място. Можете лесно да изберете диапазон от интерес в историческите диаграми на изчаквания, CPU или IO на таблото за управление на SQL Sentry и да преминете към изгледа Top SQL, за да намерите най-изходните заявки през това време. След това с едно щракване можете да отворите заявка в Plan Explorer и да получите подробни изчаквания на ниво заявка и ресурси при поискване, когато е необходимо. Не мисля, че има по-добро въплъщение на пълната методология за настройка на изчаквания и опашки от това.
 Диаграма „Чака“ на таблото за управление на SQL Sentry
Диаграма „Чака“ на таблото за управление на SQL Sentry
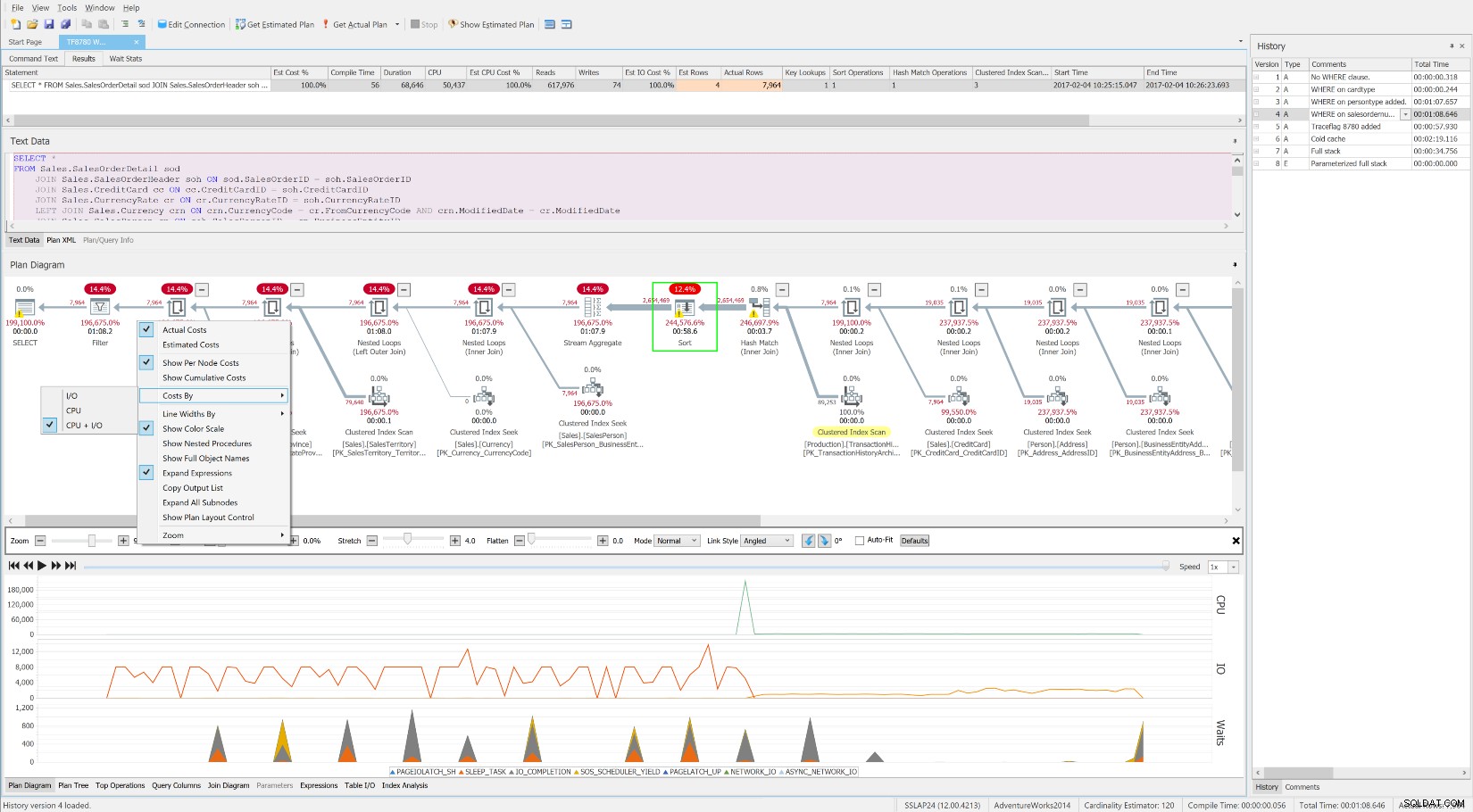 Безплатният SentryOne Plan Explorer показва изчаквания с течение на времето, заедно с ниво на операция разходи и ресурси
Безплатният SentryOne Plan Explorer показва изчаквания с течение на времето, заедно с ниво на операция разходи и ресурси
Заключение
Настройката с изчаквания и опашки е също толкова приложима за производителността на SQL Server днес, както беше през 2006 г. Въпреки това, фокусирането върху изчаквания с изключване на ресурси е опасна работа, тъй като от данните е ясно, че това ще доведе до като цяло неоптимизирани и рентабилни системи. Когато става въпрос за хардуерни ресурси и разходи в облака, вие в крайна сметка плащате за изчислителни и IO ресурси, а не за времето за изчакване, така че е целесъобразно да оптимизирате директно за потребление. Според моя опит, тъй като потреблението на ресурси и свързаните с тях спорове намаляват, естествено ще последва намалено време за изчакване.
Потвърждение
Исках да благодаря на Фред Фрост, водещ специалист по данни в SentryOne, за неговия ценен принос и критичен преглед на този анализ.