Въведение
Изпращането на дневник на транзакциите е много добре позната технология, използвана в SQL Server за поддържане на копие на живата база данни в сайта за възстановяване при бедствия. Технологията зависи от три ключови задачи:задание за архивиране, задание за копиране и задание за възстановяване. Докато заданието за архивиране се изпълнява на първичния сървър, заданията за копиране и възстановяване се изпълняват на вторичния сървър. По същество процесът включва периодично архивиране на регистрационния файл на транзакциите в споделен ресурс, от който заданието за копиране се премества същото към вторичния сървър; впоследствие заданието за възстановяване прилага резервните копия на журнала към вторичния сървър. Преди всичко това да започне, вторичната база данни трябва да бъде инициализирана с пълно архивиране от основния сървър, възстановено с опция NORECOVERY.
Microsoft предоставя набор от съхранени процедури, които могат да се използват за конфигуриране на доставка на дневници от край до край, както и еквиваленти на GUI, започвайки от елемента на свойствата на всяка база данни, за която може да искате да конфигурирате доставка на дневници. Струва си да се отбележи, че вторичната база данни може да бъде конфигурирана в режим NORECOVERY или в режим STANDBY. В режим NORECOVERY базата данни никога не е достъпна за заявки, но в режим STANDBY, вторичната база данни може да бъде запитана, когато не е в ход операция за възстановяване на регистрационния файл на транзакциите.
Настройка на средата
За да накараме топката да се движи, създаваме две инстанции на SQL Server на AWS с идентично изображение на Amazon EC2. Този екземпляр на Amazon EC2 работи с SQL Server 2017 RTM-CU5 на Windows Server 2016. След това възстановяваме копие на базата данни WideWorldImporters, използвайки резервен набор, придобит от GitHub, до първия екземпляр, нашия първичен екземпляр. Използваме един и същ резервен набор, за да създадем две идентични бази данни, наречени BranchDB и CorporateDB.
Фиг. 1 версия на SQL Server
Фиг. 2 BranchDB и CorporateDB на първичен инстанция (вторична празна инстанция)
Списък 1:Възстановяване на примерна база данни на WideWorldImporters
възстановяване на filelistonly от disk='WideWorldImporters-Full.bak'restore база данни CorporateDB от disk='WideWorldImporters-Full.bak' със stats=10, възстановяване, преместване на 'WWI_Primary' в 'M:\MSSQL_Primary\W. mdf' , преместете 'WWI_UserData' в 'M:\MSSQL\Data\WWI_UserData.ndf' , преместете 'WWI_Log' към 'N:\MSSQL\Log\WWI_Log.ldf', преместете 'WWI_InMemory_Data\S'QLM_1\' в Data\WWI_InMemory_Data_1.ndf'restore база данни BranchDB от disk='WideWorldImporters-Full.bak' със stats=10, възстановяване, преместете 'WWI_Primary' в 'M:\MSSQL\Data\WWI_Primary1.mdf' в 'WI'Da преместете в'User M:\MSSQL\Data\WWI_UserData1.ndf' , преместете 'WWI_Log' в 'N:\MSSQL\Log\WWI_Log1.ldf', преместете 'WWI_InMemory_Data_1' в 'M:\MSSQL\Data\WWI_InMemory>.Вече имаме два екземпляра, първичният екземпляр, който хоства двете първични бази данни (BranchDB и CorporateDB и вторичният екземпляр без потребителски бази данни. Продължаваме с конфигурирането на доставка на регистрационни файлове на транзакциите и в двете бази данни, но ги разграничаваме, като прилагаме забавяне към конфигурацията за възстановяване на първата база данни. Припомнете си, че базите данни всъщност са идентични по отношение на данните, които съдържат. Следващите графики показват ключовите опции, избрани в конфигурацията за доставка на дневници.
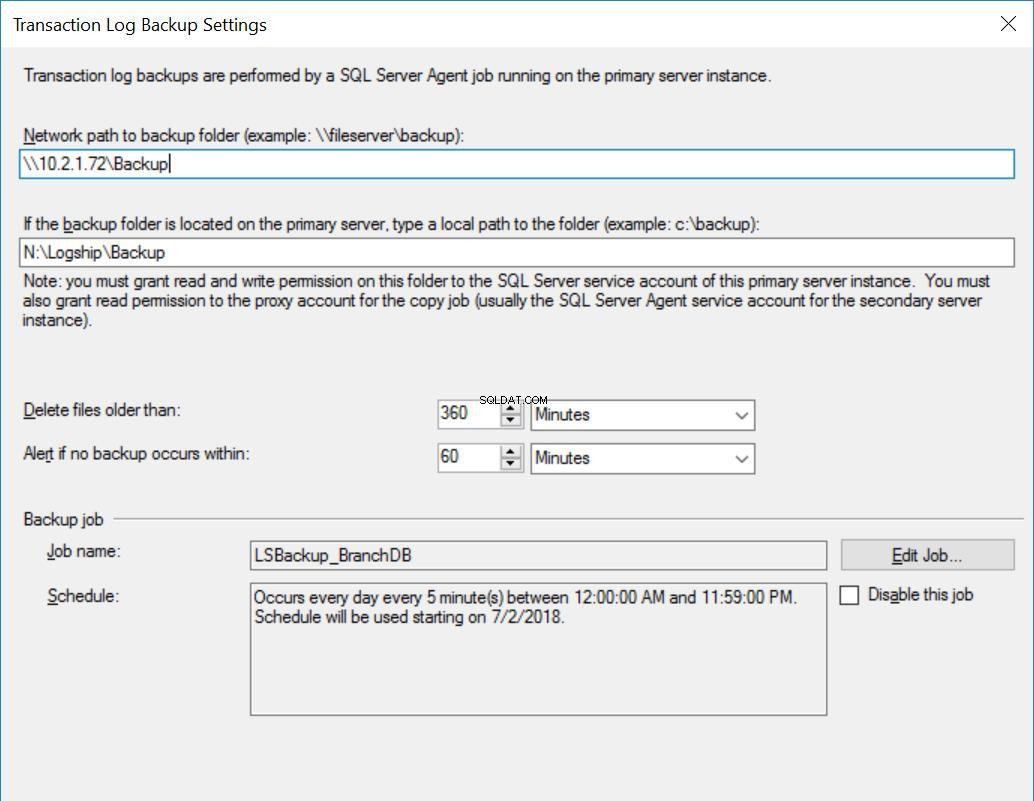
Фиг. 3 Настройки за архивиране за BranchDB
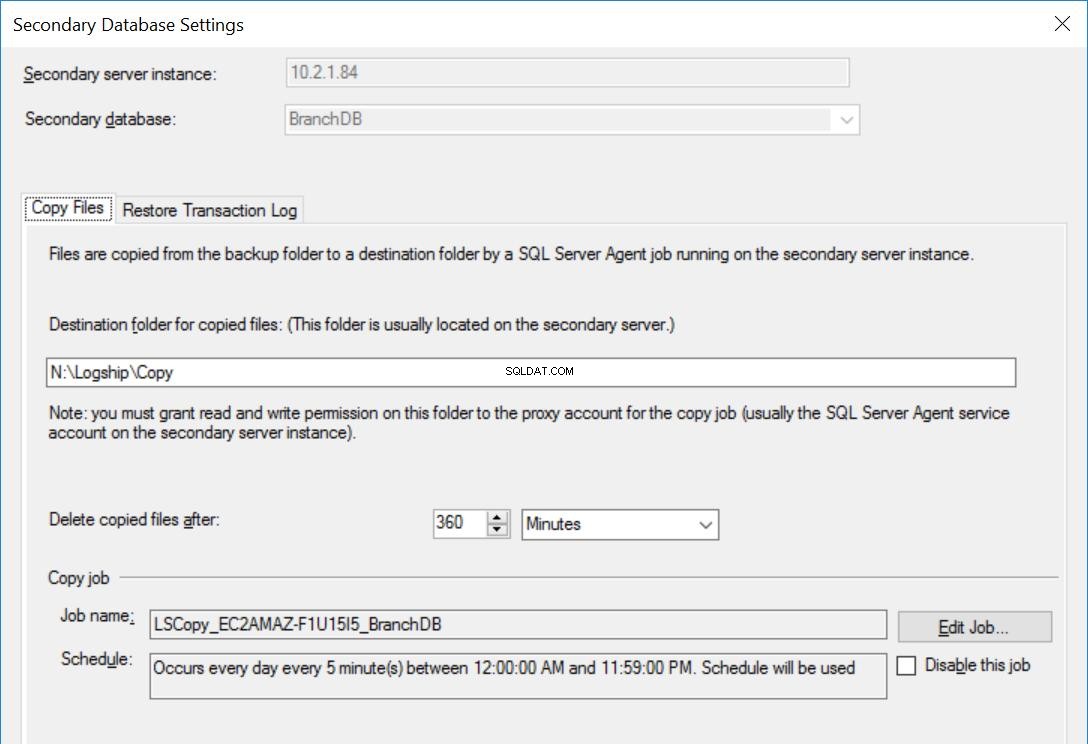
Фиг. 4 Настройки за копиране за BranchDB
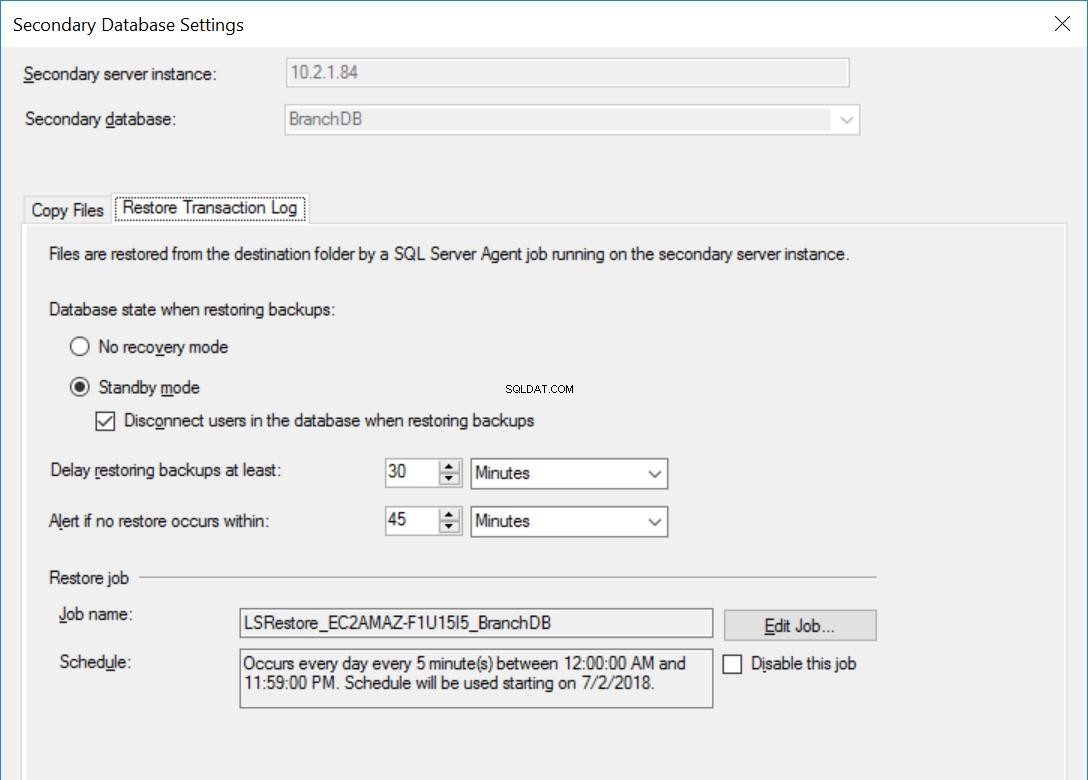
Фиг. 5 Възстановяване на настройките за BranchDB
Всяко задание за доставка на журнали е конфигурирано да се изпълнява на всеки пет минути. За да обработим „Забавяне на възстановяването на архиви“, трябва да използваме режима за възстановяване в режим на готовност в конфигурацията за доставка на журнал. Това е логично, тъй като има вторичната база данни в режим на готовност и показва, че можем да правим запитвания към вторичната база данни, когато възстановяването на регистрационния файл на транзакциите не е в ход. Стойността, която посочваме в тази опция (30 минути в този случай), ни дава добър прозорец, през който можем да стартираме отчети от вторичната база данни, освен основното изискване на тази статия, което е в състояние да се възстанови от грешка на потребителя.
Също така трябва да споменем, че възстановяването на резервните копия на регистрационните файлове на транзакциите всъщност се забавя. Неговото времево клеймо е по-късно от стойността на закъснението. Това означава, че всички резервни копия на регистрационните файлове на транзакциите ще бъдат копирани на вторичния сървър, който се основава на графика и е посочен в заданието за копиране. Всъщност заданието за възстановяване ще продължи да работи по график, но архивите на регистрационните файлове на транзакциите (които не са на възраст до 30 минути) няма да бъдат възстановени. По същество резервната база данни на BranchDB е на 30 минути зад основната база данни на BranchDB. За да демонстрираме това изоставане, в следващия раздел ще създадем таблица в двете бази данни и ще създадем задание, което вмъква запис всяка минута. Ще разгледаме тази таблица във Вторичните бази данни.
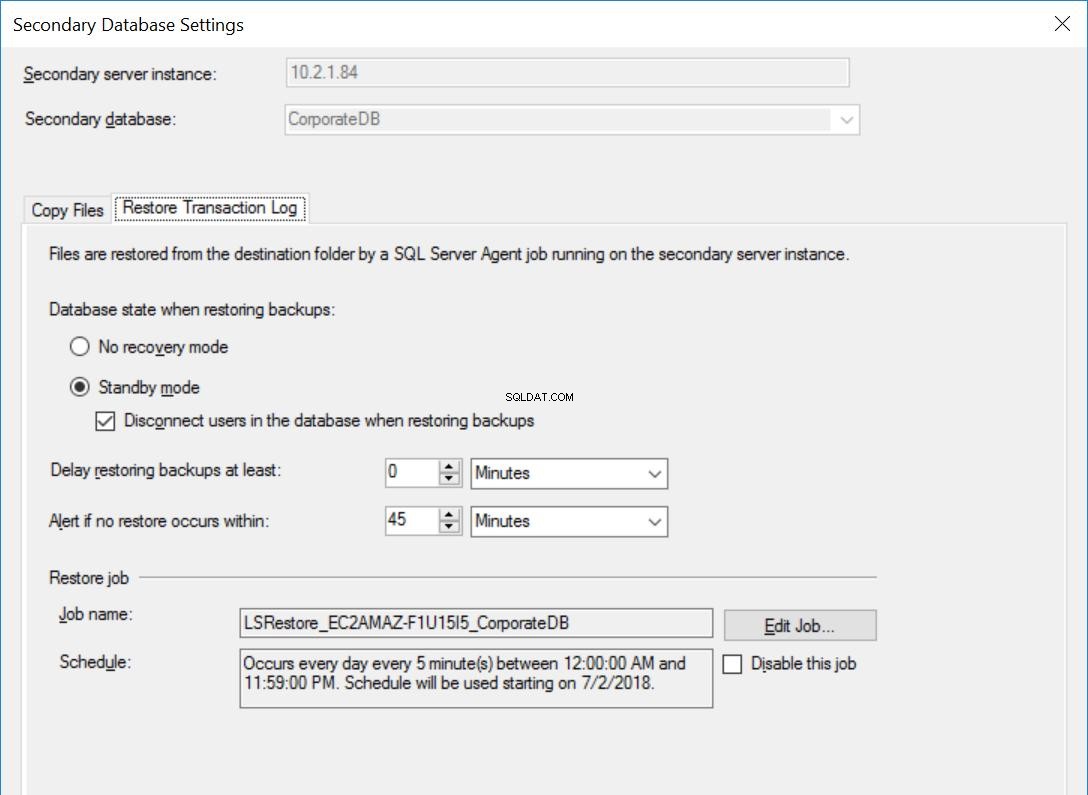
Настройките за базата данни CorporateDB са същите като на фиг. 3 до 5, с изключение на заданието за възстановяване, което НЕ е настроено да забавя архивирането на регистрационните файлове на транзакциите.
Фиг. 6 Възстановяване на настройките за CorporateDB
Проверка на конфигурацията
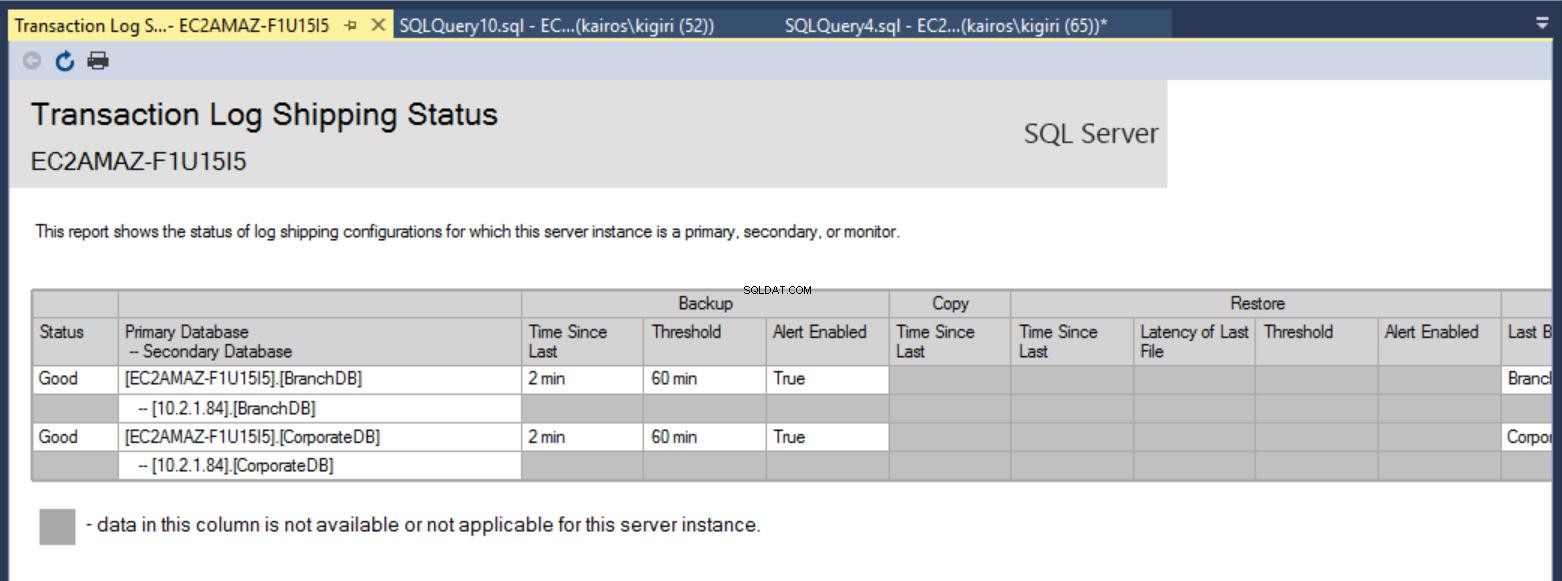
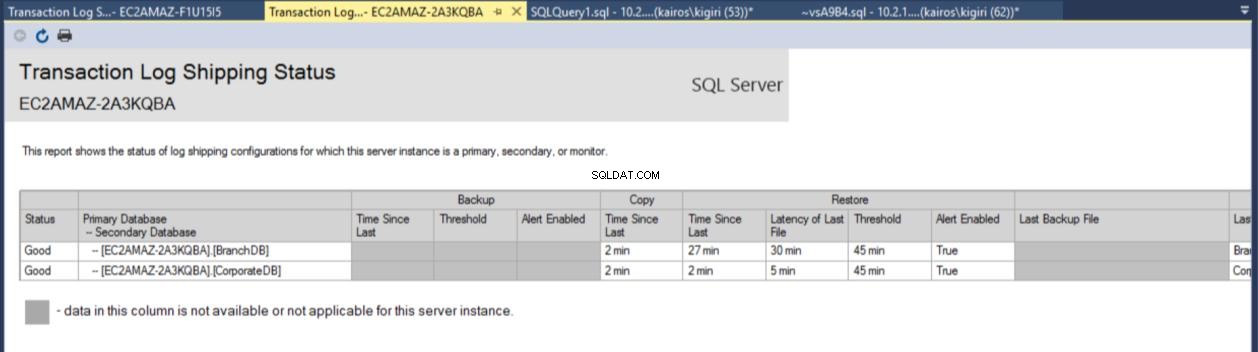
След като конфигурацията приключи, можем да проверим дали конфигурацията е наред и да започнем с наблюдение на нейната работа. Отчетът за доставка на дневника на транзакциите ни показва, че клоновата база данни наистина изостава от CorporateDB по отношение на възстановяването:
Фиг. 7a Доклад за доставка на дневника на транзакциите на първичния сървър
Фиг. 7b Доклад за доставка на дневника на транзакциите на вторичен сървър
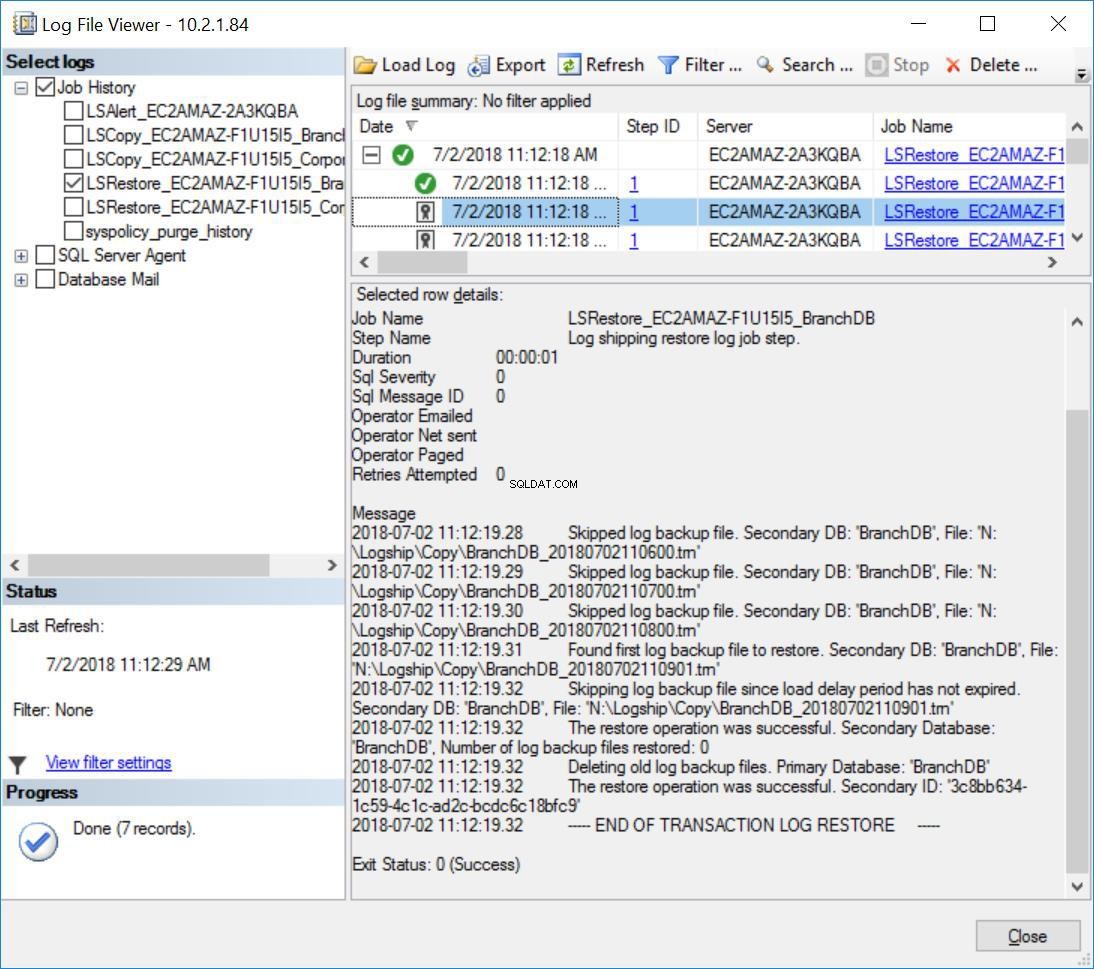
Освен това ще забележите съобщението по-долу в хронологията за възстановяване на заданията за BranchDB:
Фиг. 8 Възстановява дневника на пропуснатите транзакции на вторичен сървър
Можем да отидем по-далеч с тази проверка, като създадем таблица и използваме задание за попълване на тази таблица с редове всяка минута. Работата е прост начин за симулиране на това, което приложението може да прави с потребителска таблица. Това може да ни покаже, че това изоставане определено се показва в потребителските данни.
Списък 2 – Създаване на таблица за проследяване на журнали
използвайте BranchDBgocreate таблица log_ship_tracker( ID int identity (100,1), Database_Name sysname default db_name(),RecordTime datetime default getdate(),ServerName sysname default @@servername)използвайте CorporateDBgocreate таблица log_ship_tracker (ID int, identity ),Име на базата данни sysname по подразбиране db_name(),RecordTime datetime default getdate(),ServerName sysname default @@servername)Списък 3 – Създаване на работа за попълване на таблица за проследяване на регистрационни файлове
/* ==Параметри на скриптове==Версия на изходния сървър :SQL Server 2017 (14.0.3023) Издание на изходната база данни:Microsoft SQL Server Стандартно издание Тип на изворната база данни:Самостоятелен SQL Server Версия на целевия сървър:SQL Server 2017 Target Database Engine Edition:Microsoft SQL Server Standard EditionTarget Database Engine Тип:Самостоятелен SQL Server*/USE [msdb]GO/****** Обект:Работа [InsertRecords] Дата на скрипта:02.07.2018 15:32:00 **** **/BEGIN TRANSACTIONDECLARE @ReturnCode INTSELECT @ReturnCode =0/****** Обект:JobCategory [[Uncategorized (Local)]] Дата на скрипта:7/2/2018 15:32:00 PM ****** /АКО НЕ СЪЩЕСТВУВА (ИЗБЕРЕТЕ име ОТ msdb.dbo.syscategories WHERE name=N'[Uncategorized (Local)]' И category_class=1)BEGINEXEC @ReturnCode =msdb.dbo.sp_add_category @class=N'JOB', @type=N'LOCAL', @name=N'[Uncategorized (Local)]'IF (@@ERROR <> 0 ИЛИ @ReturnCode <> 0) ОТИДИТЕ QuitWithRollbackENDDECLARE @jobId BINARY(16)EXEC @ReturnCode =msdb.dbo.sp_add_jo job_name=N'InsertRecords', @enabled=1 ,@notify_level_eventlog=0,@notify_level_email=0,@notify_level_netsend=0,@notify_level_page=0,@delete_level=0,@description=N'Няма налично описание.',@category_name=N'[Uncategorized',Local)] @owner_login_name=N'kairos\kigiri', @job_id =@jobId OUTPUTIF (@@ERROR <> 0 ИЛИ @ReturnCode <> 0) ОТИДИТЕ QuitWithRollback/****** Обект:Стъпка [InsertRecords] Дата на скрипта:7/ 2/2018 15:32:00 ******/EXEC @ReturnCode =msdb.dbo.sp_add_jobstep @example@sqldat.com,@step_name=N'InsertRecords',@step_id=1,@cmdexec_success_code=0, @on_success_action=1,@on_success_step_id=0,@on_fail_action=2,@on_fail_step_id=0,@retry_attempts=0,@retry_interval=0,@os_run_priority=0, @subsystem=N'TSQL',@command=go DB intolog_ship_trackervalues(db_name(),getdate(),@@име на сървър)използвайте CorporateDBgoinsert intolog_ship_trackervalues(db_name(),getdate(),@@име на сървър)GO',@database_name=N'master',@flags=0IF (@@ERROR <> 0 ИЛИ @ReturnCode <> 0) ОТИДЕТЕ QuitWithRollbackEXEC @ReturnCode =msdb.dbo.sp_update_job @job_id =@jobId, @start_step_id =1 IF (@@ERROR <> 0 ИЛИ @ReturnCode <> 0) ОТИДЕТЕ QuitWithRollbackEXEC @ReturnCode =msdb.dbo.sp_add_jobschedule @example@sqldat.com, @name=N'Schedule=1, @en freq_type=4,@freq_interval=1,@freq_subday_type=4,@freq_subday_interval=1,@freq_relative_interval=0,@freq_recurrence_factor=0,@active_start_date=20180702,@active_end_date20180702,@active_end_date2,active_end9_star@,599_end_date20,599 schedule_uid=N'03e5f1b2-2e0b-4b30-8d60-3643c84aa08d' IF (@@ERROR <> 0 ИЛИ @ReturnCode <> 0) ОТПРАВИТЕ НА QuitWithRollbackEXEC @ReturnCode =msdb.dbo_name_server_, @jo_serverb_server' (local)'IF (@@ERROR <> 0 ИЛИ @ReturnCode <> 0) ОТИДИТЕ QuitWithRollbackCOMMIT TRANSACTIONGOTO EndSaveQuitWithRollback:IF (@@TRANCOUNT> 0) ROLLBACK TRANSACTIONEndSave:GO
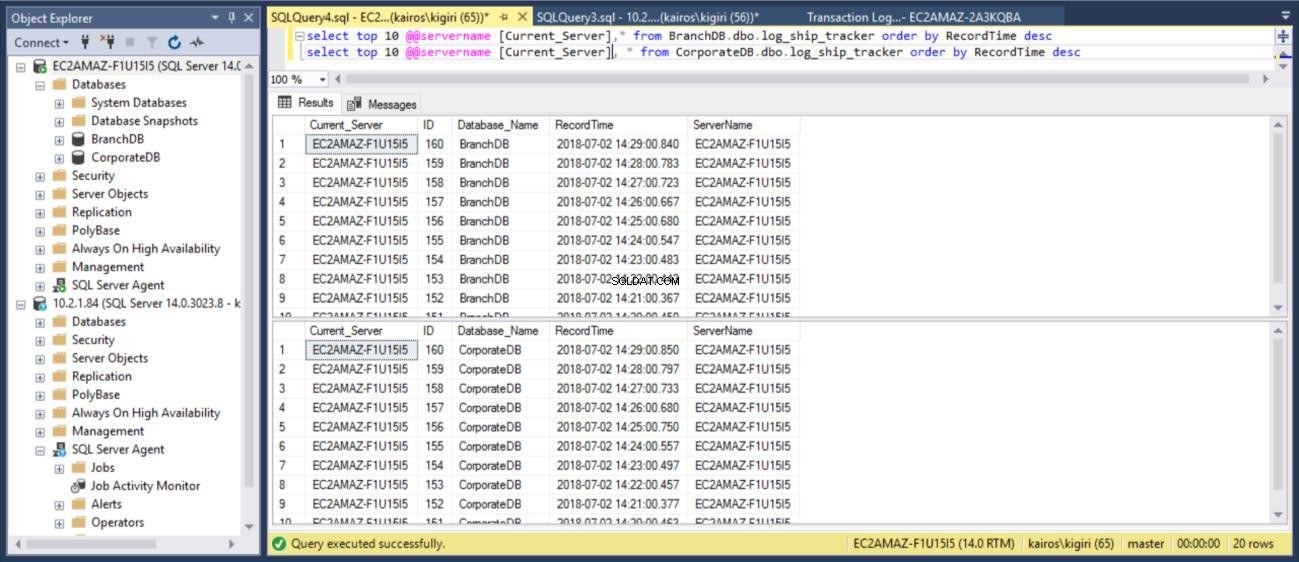
Когато правим заявка към таблицата съответно в Основните бази данни, можем да потвърдим (чрез използване на колоната RecordTime), че редовете съвпадат в BranchDB и CorporateDB. Когато разгледаме таблицата във вторичните бази данни, по същия начин виждаме ясно, че имаме 30-минутна разлика между BranchDB и CorporateDB.
Списък 4 – Запитване на таблицата на Log Tracker
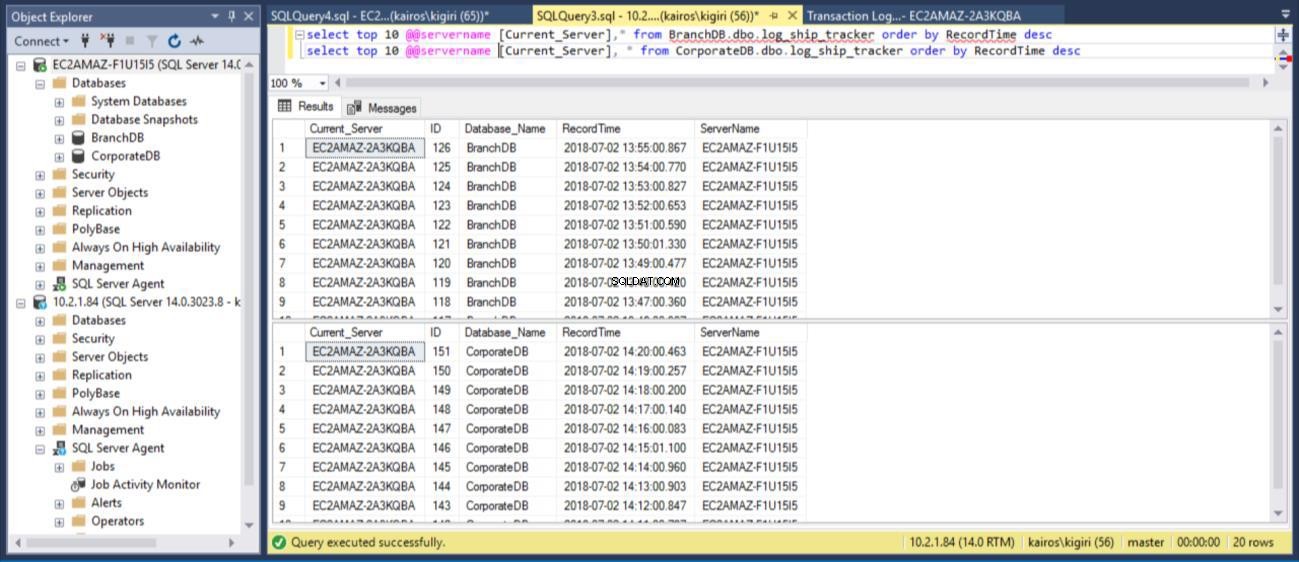
изберете топ 10 @@servername [Current_Server],* от BranchDB.dbo.log_ship_tracker поръчка от RecordTime descsизберете топ 10 @@servername [Current_Server], * от CorporateDB.dbo.log_ship_tracker поръчка по RecordTime desc
Фиг. 9 таблици за проследяване на регистрационни файлове съвпадат в първични бази данни
Фиг. 10 таблици за проследяване на журнали имат интервал от ~30 минути във вторични бази данни
Възстановяване от потребителска грешка
Сега нека поговорим за ключовата полза от това забавяне. В сценария, при който потребител по невнимание изпуска таблица, можем бързо да възстановим данните от вторичната база данни, стига периодът на забавяне да не е изтекъл. В този пример пускаме таблицата Sales.Orderlines в ДВЕТЕ бази данни и проверяваме, че таблицата вече не съществува в ДВЕТЕ бази данни.
Списък 5 – Отпадане на таблицата с линии за поръчки
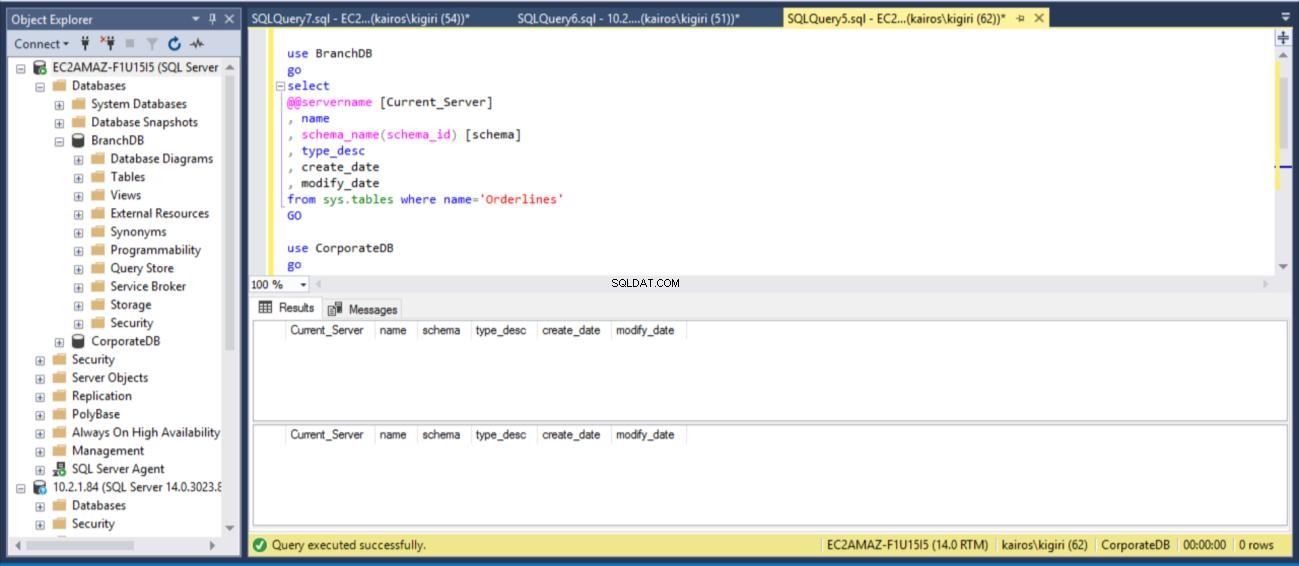
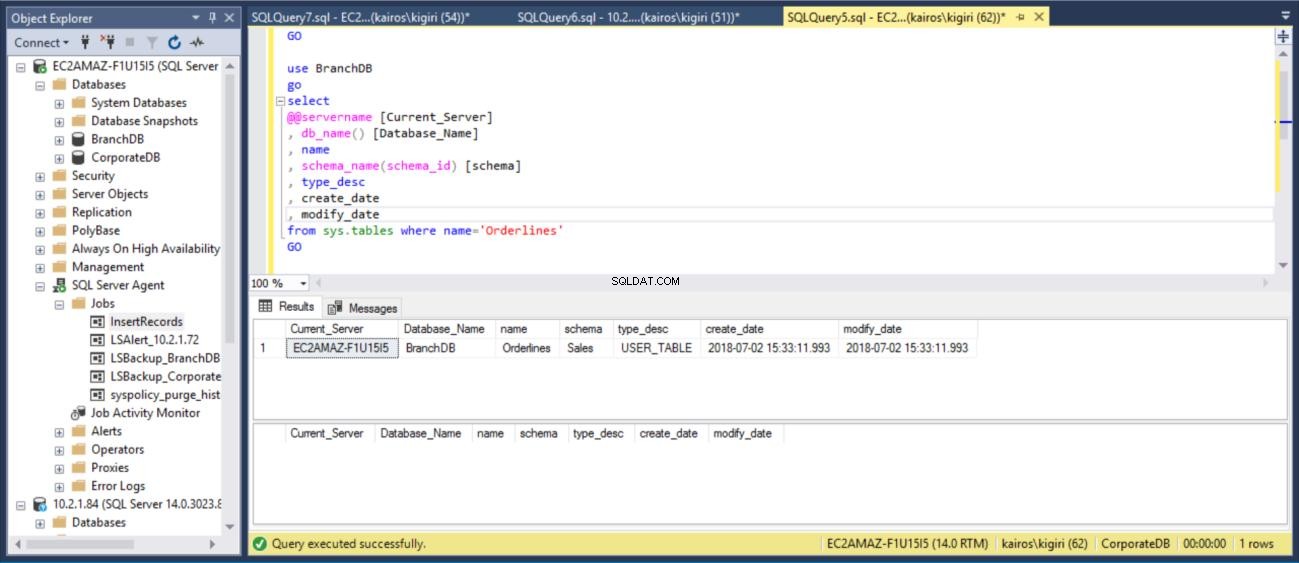
отпуснете таблицата BranchDB.Sales.Orderlinesdrop table CorporateDB.Sales.OrderlinesGOuse BranchDBgoselect@@servername [Current_Server], db_name() [Име_на_база от данни], име, schema_name(schema_id) [schema], type_datable, s modify name='Orderlines'GOuse CorporateDBgoselect@@servername [Current_Server], db_name() [Име на базата от данни], име, schema_name(schema_id) [schema], type_desc, create_date, modify_datefrom sys.tables, където name='GO
Фиг. 11 Отпадане на таблица Sales.Orderlines
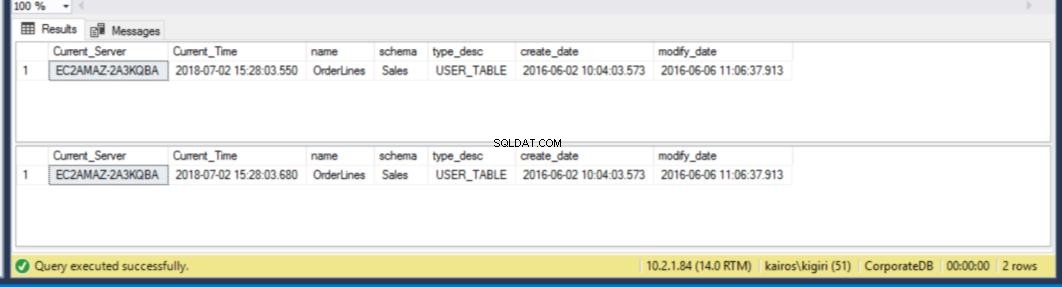
Когато търсим таблицата на вторичния сървър, откриваме, че таблицата все още е налична в ДВЕТЕ бази данни. По този начин за CorporateDB имаме по-малко от пет минути за възстановяване на данните. (фиг. 12). Но след като следващото възстановяване Cycle се изпълни, ние губим таблицата в базата данни на Corporate DB. За да възстановим тази таблица, трябва да направим възстановяване в момента, използвайки пълно архивиране в отделна среда и след това да извлечем тази конкретна таблица. Ще се съгласите, че ще отнеме известно време. За таблицата BranchDB Orderlines имаме малко повече време и можем да възстановим таблицата с един SQL оператор през свързан сървър (вижте листинг 6).
Фиг. 12 Петминутно обратно броене:таблица съществува и в двете вторични бази данни
Фиг. 13 Допълнителни 25 минути за възстановяване на таблицата на BranchDB
Списък 6 – Таблица за възстановяване на поръчки
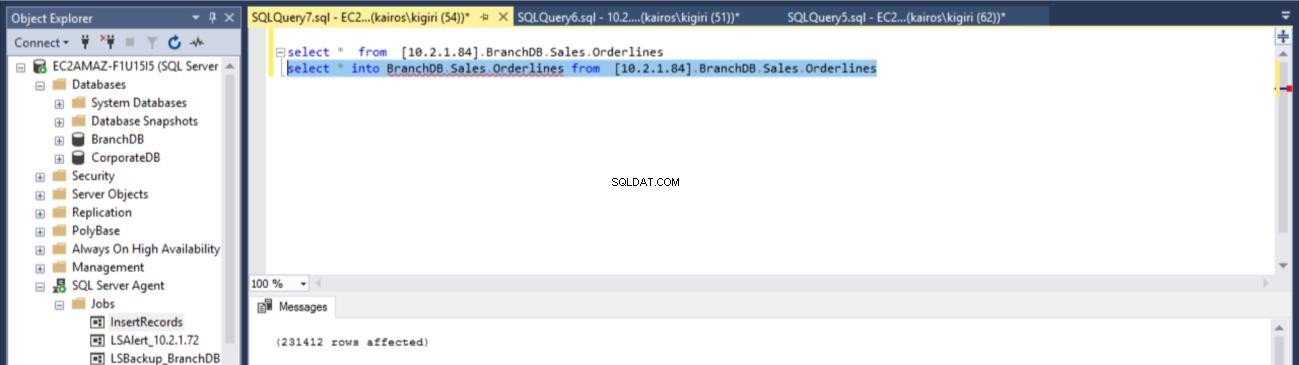
ИЗПОЛЗВАЙТЕ [master]GO/****** Обект:LinkedServer [10.2.1.84] Дата на скрипта:02.07.2018 16:14:59 ******/EXEC master.dbo.sp_addlinkedserver @server =N'10.2.1.84', @srvproduct=N'SQL Server'/* От съображения за сигурност паролата за отдалечено влизане в свързания сървър се променя с ######## */EXEC master.dbo.sp_addlinkedsrvlogin@rmtsrvname =N'10.2.1.84',@useself=N'True',@locallogin=NULL,@rmtuser=NULL,@rmtpasswo rd=NULLGOselect * в BranchDB.Sales.Orderlines от [10.2.1.84].BranchDB.Sales.Orderlines.
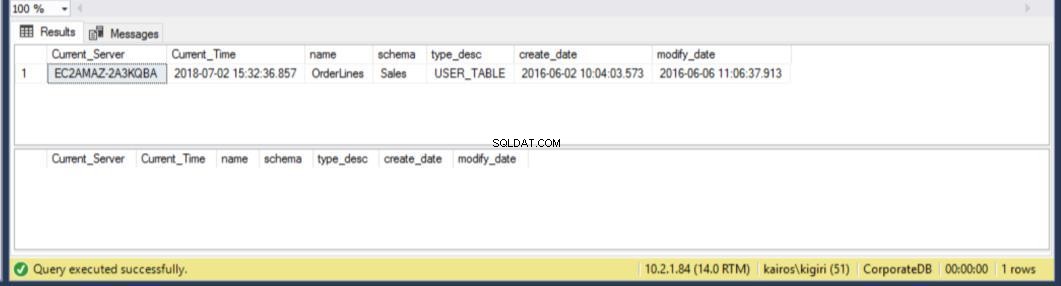
Фиг. 14 Възстановете таблицата на BranchDB Sales.Orderlines
След това проверяваме основния сървър (BranchDB Database), че таблицата е възстановена.
Фиг. 15 Възстановете таблицата на BranchDB Sales.Orderlines
Заключение
SQL Server предоставя редица начини за възстановяване от загуба на данни от различни основни причини – повреда на диска, повреда, потребителска грешка и т.н. Възстановяването в момента от архивни копия е може би най-известният от тези методи. За някои прости случаи на потребителска грешка или подобен случай, когато един или два обекта са загубени, използването на доставка на регистрационни файлове на транзакции с отложено възстановяване е добър подход, който трябва да се разгледа. Въпреки това, трябва да се отбележи, че вторична база данни, която е конфигурирана стриктно за нуждите на DR, трябва да бъде избрана за по-ниски RPO.