Напоследък имах много разговори за видовете натоварвания – по-специално разбирането дали едно работно натоварване е параметризирано, adhoc или смесено. Това е едно от нещата, които разглеждаме по време на одит на здравето и Кимбърли има страхотна заявка от своя кеш на плановете и публикация за оптимизиране за adhoc работни натоварвания, която е част от нашия инструментариум. Копирах заявката по-долу и ако никога досега не сте я изпълнявали срещу някоя от вашите производствени среди, определено намерете време да го направите.
SELECT objtype AS [CacheType],
COUNT_BIG(*) AS [Total Plans],
SUM(CAST(size_in_bytes AS DECIMAL(18, 2))) / 1024 / 1024 AS [Total MBs],
AVG(usecounts) AS [Avg Use Count],
SUM(CAST((CASE WHEN usecounts = 1 THEN size_in_bytes
ELSE 0
END) AS DECIMAL(18, 2))) / 1024 / 1024 AS [Total MBs – USE Count 1],
SUM(CASE WHEN usecounts = 1 THEN 1
ELSE 0
END) AS [Total Plans – USE Count 1]
FROM sys.dm_exec_cached_plans
GROUP BY objtype
ORDER BY [Total MBs – USE Count 1] DESC; Ако изпълня тази заявка срещу производствена среда, може да получим изход като следния:
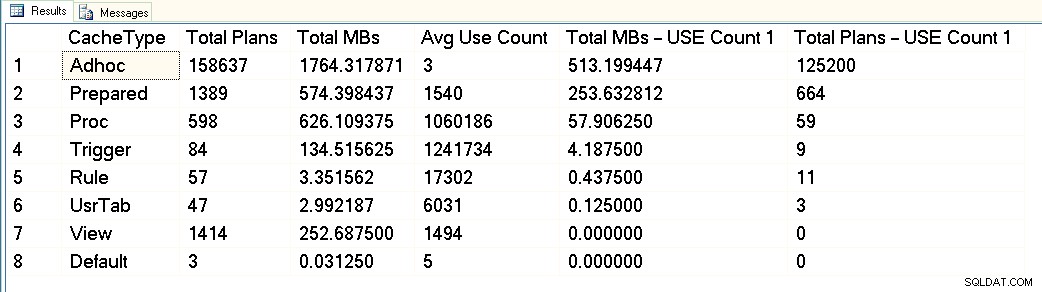
От тази екранна снимка можете да видите, че имаме около 3GB общо, посветени на кеша на плана, като от тях 1,7GB са за плановете на над 158 000 adhoc заявки. От тези 1,7 GB приблизително 500 MB се използват за 125 000 плана, които изпълняват ЕДИН само време. Около 1 GB от кеша на плана е за подготвени и процедурни планове и те заемат само около 300 MB пространство. Но имайте предвид средния брой на употреба – доста над 1 милион за процедури. Разглеждайки този изход, бих категоризирал това работно натоварване като смесено – някои параметризирани заявки, някои adhoc.
Публикацията в блога на Кимбърли обсъжда опциите за управление на кеш на планове, изпълнен с много adhoc заявки. Раздуването на кеша на плановете е само един проблем, с който трябва да се справите, когато имате adhoc работно натоварване и в тази публикация искам да проуча ефекта, който може да има върху CPU в резултат на всички компилации, които трябва да се случат. Когато заявка се изпълнява в SQL Server, тя преминава през компилация и оптимизация и има допълнителни разходи, свързани с този процес, което често се проявява като цена на процесора. След като планът за заявка е в кеша, той може да бъде използван повторно. Параметризираните заявки могат да доведат до повторно използване на план, който вече е в кеша, тъй като текстът на заявката е абсолютно същият. Когато една adhoc заявка се изпълни, тя ще използва повторно плана в кеша само ако има точното същия текст и стойност(и) за въвеждане .
Настройка
За нашето тестване ще генерираме произволен низ в TSQL и ще го конкатенираме към заявка, така че всяко изпълнение да има различна буквална стойност. Обвих това в съхранена процедура, която извиква заявката с помощта на динамично изпълнение на низ (EXEC @QueryString), така че тя се държи като adhoc изявление. Извикването му от съхранена процедура означава, че можем да го изпълним известен брой пъти.
USE [WideWorldImporters];
GO
DROP PROCEDURE IF EXISTS dbo.[RandomSelects];
GO
CREATE PROCEDURE dbo.[RandomSelects]
@NumRows INT
AS
DECLARE @ConcatString NVARCHAR(200);
DECLARE @QueryString NVARCHAR(1000);
DECLARE @RowLoop INT = 0;
WHILE (@RowLoop < @NumRows)
BEGIN
SET @ConcatString = CAST((CONVERT (INT, RAND () * 2500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1000) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1500) + 1) AS NVARCHAR(50));
SELECT @QueryString = N'SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = ''' + @ConcatString + ''';';
EXEC (@QueryString);
SELECT @RowLoop = @RowLoop + 1;
END
GO
DBCC FREEPROCCACHE;
GO
EXEC dbo.[RandomSelects] @NumRows = 10;
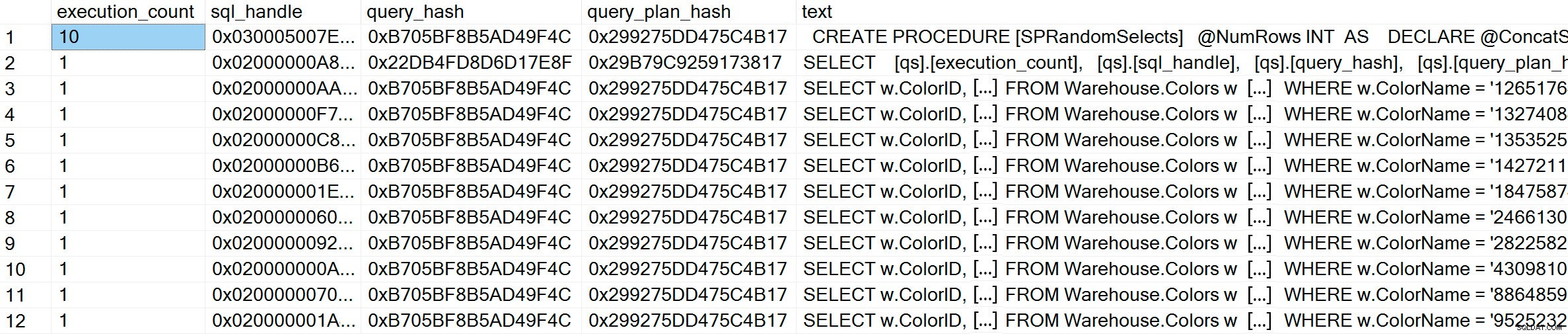
GO След изпълнение, ако проверим кеша на плана, можем да видим, че имаме 10 уникални записа, всеки с execution_count от 1 (увеличете изображението, ако е необходимо, за да видите уникалните стойности за предиката):
SELECT [qs].[execution_count], [qs].[sql_handle], [qs].[query_hash], [qs].[query_plan_hash], [st].[text] FROM sys.dm_exec_query_stats AS [qs] CROSS APPLY sys.dm_exec_sql_text ([qs].[sql_handle]) AS [st] CROSS APPLY sys.dm_exec_query_plan ([qs].[plan_handle]) AS [qp] WHERE [st].[text] LIKE '%Warehouse%' ORDER BY [st].[text], [qs].[execution_count] DESC; GO

Сега създаваме почти идентична съхранена процедура, която изпълнява същата заявка, но параметризирана:
USE [WideWorldImporters];
GO
DROP PROCEDURE IF EXISTS dbo.[SPRandomSelects];
GO
CREATE PROCEDURE dbo.[SPRandomSelects]
@NumRows INT
AS
DECLARE @ConcatString NVARCHAR(200);
DECLARE @QueryString NVARCHAR(1000);
DECLARE @RowLoop INT = 0;
WHILE (@RowLoop < @NumRows)
BEGIN
SET @ConcatString = CAST((CONVERT (INT, RAND () * 2500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1000) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1500) + 1) AS NVARCHAR(50))
SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = @ConcatString;
SELECT @RowLoop = @RowLoop + 1;
END
GO
EXEC dbo.[SPRandomSelects] @NumRows = 10;
GO В кеша на плана, в допълнение към 10-те adhoc заявки, виждаме един запис за параметризираната заявка, която е била изпълнена 10 пъти. Тъй като входът е параметризиран, дори ако в параметъра са предадени много различни низове, текстът на заявката е абсолютно същият:
Тестване
Сега, когато разбираме какво се случва в кеша на плана, нека създадем повече натоварване. Ще използваме файл от командния ред, който извиква един и същ .sql файл в 10 различни нишки, като всеки файл извиква съхранената процедура 10 000 пъти. Ще изчистим кеша на плана, преди да започнем, и ще уловим общия CPU% и SQL компилации/сек с PerfMon, докато скриптовете се изпълняват.
Съдържание на файла Adhoc.sql:
EXEC [WideWorldImporters].dbo.[RandomSelects] @NumRows = 10000;
Съдържание на Parameterized.sql файл:
EXEC [WideWorldImporters].dbo.[SPRandomSelects] @NumRows = 10000;
Примерен команден файл (виждан в Notepad), който извиква .sql файла:
Примерен команден файл (виждан в Notepad), който създава 10 нишки, като всяка извиква файла Run_Adhoc.cmd:
След като изпълним всеки набор от заявки общо 100 000 пъти, ако погледнем кеша на плана, виждаме следното:

В кеша на плановете има повече от 10 000 adhoc плана. Може да се чудите защо няма план за всички 100 000 изпълнени adhoc заявки и това е свързано с това как работи кешът на плана (размерът му се основава на наличната памет, когато неизползваните планове са остарели и т.н.). Важното е, че така съществуват много adhoc планове, в сравнение с това, което виждаме за останалите типове кеш.
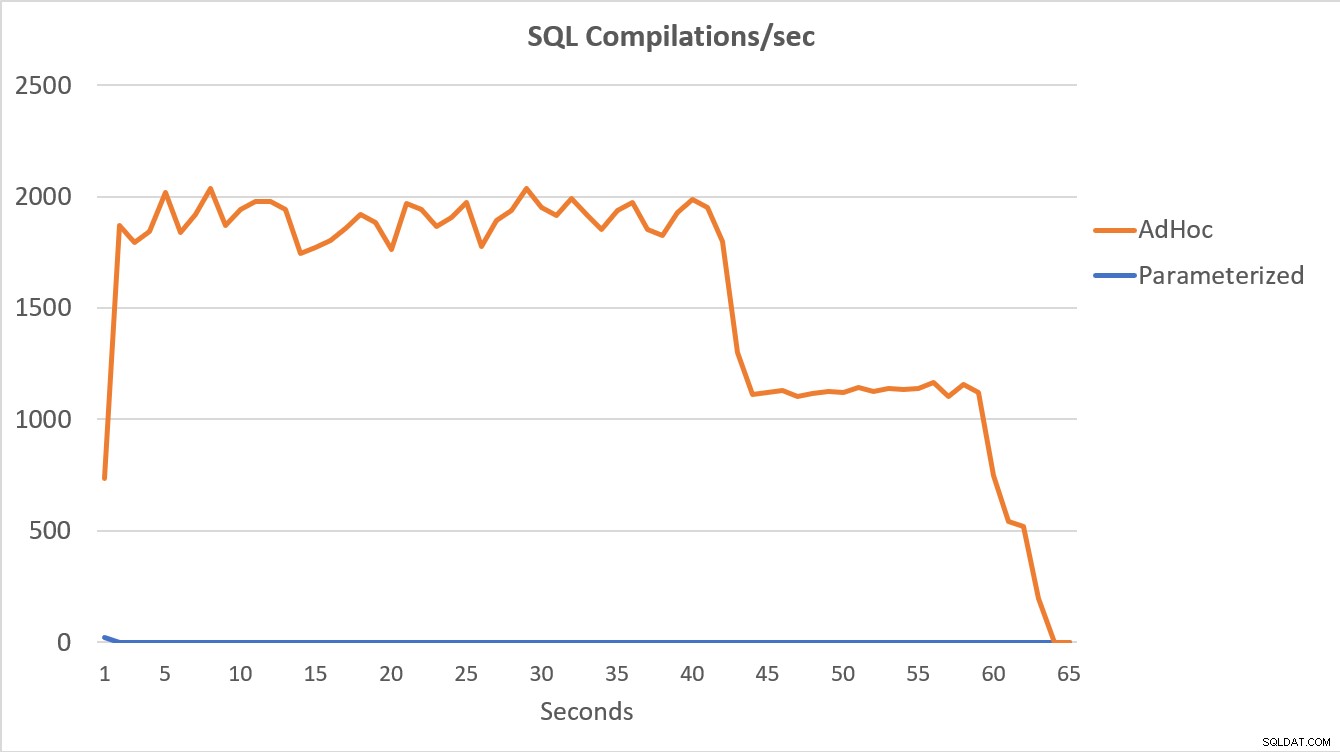
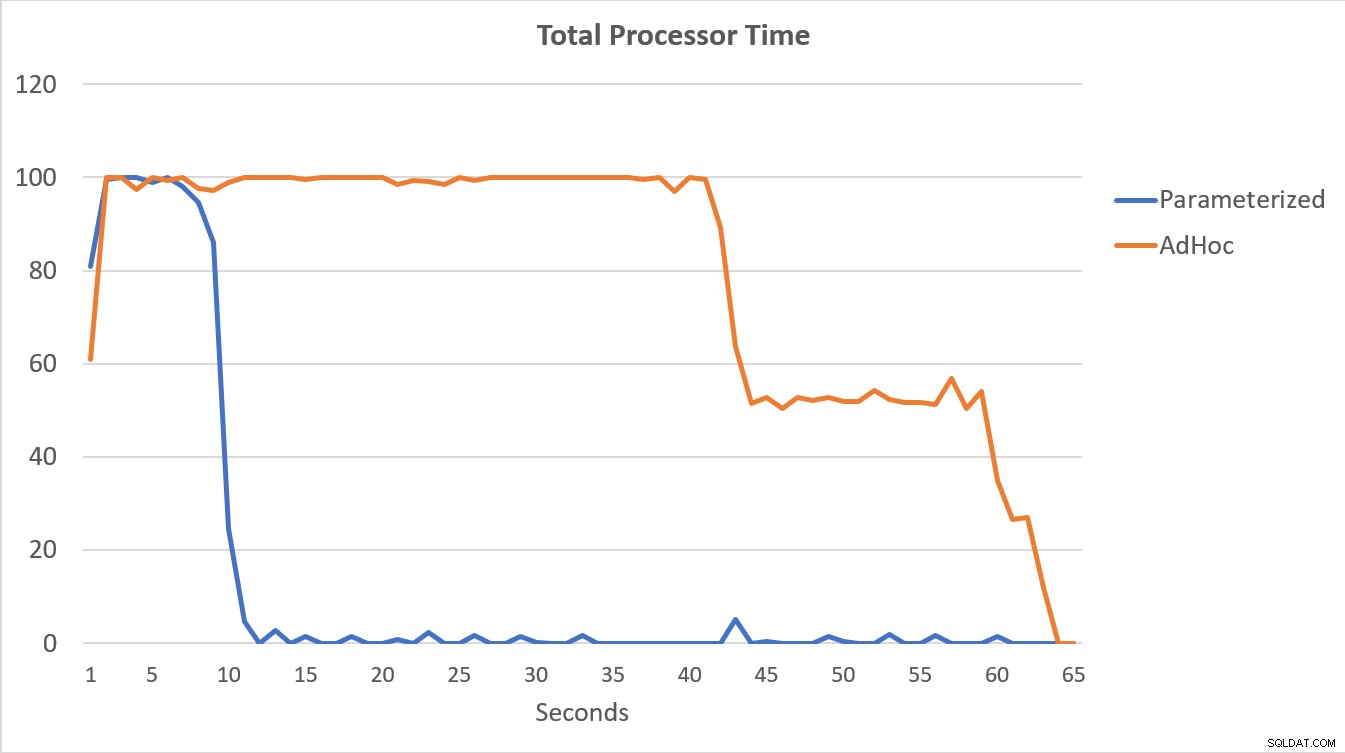
Данните на PerfMon, показани по-долу, са най-показателни. Изпълнението на 100 000 параметризирани заявки завърши за по-малко от 15 секунди и имаше малък скок в компилации/сек в началото, който едва се забелязва на графиката. Същият брой adhoc изпълнения отне малко над 60 секунди, като компилациите/сек скочат близо до 2000, преди да спаднат близо до 1000 около 45-те секунди, с CPU близо или на 100% през по-голямата част от времето.
Резюме
Нашият тест беше изключително прост, тъй като изпратихме варианти само за един adhoc заявка, докато в производствена среда бихме могли да имаме стотици или хиляди различни вариации за стотици или хиляди на различни adhoc запитвания. Въздействието върху производителността на тези adhoc заявки не е само раздуването на кеша на плана, което се случва, въпреки че погледнете кеша на плана е чудесно място да започнете, ако не сте запознати с вида на натоварването, което имате. Големият обем adhoc заявки може да доведе до компилации и следователно на CPU, който понякога може да бъде маскиран чрез добавяне на повече хардуер, но абсолютно може да дойде момент, в който CPU наистина се превърне в пречка. Ако смятате, че това може да е проблем или потенциален проблем във вашата среда, тогава потърсете да идентифицирате кои adhoc заявки се изпълняват най-често и вижте какви опции имате за параметризирането им. Не ме разбирайте погрешно – има потенциални проблеми с параметризирани заявки (например стабилност на плана поради изкривяване на данните) и това е друг проблем, който може да трябва да преодолеете. Независимо от вашето работно натоварване, важно е да разберете, че рядко има метод „задайте го и го забрави“ за кодиране, конфигуриране, поддръжка и т.н. Решенията на SQL Server са живи, дишащи същества, които винаги се променят и полагат непрекъснати грижи и захранване за изпълняват надеждно. Една от задачите на DBA е да остане на върха на тази промяна и да управлява производителността възможно най-добре – независимо дали е свързана с adhoc или параметризирани предизвикателства в производителността.