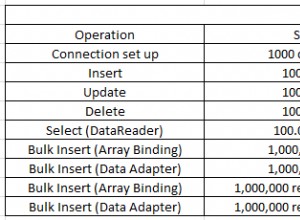
Unicode символите в диапазоните \u0000-\uD7FF и \uE000-\uFFFF ще имат 3 байта (или по-малко) кодиране в UTF8. Диапазонът \uD800-\uDFFF е за многобайтов UTF16. Не знам Python, но трябва да можете да настроите регулярен израз, който да съвпада извън тези диапазони.
pattern = re.compile("[\uD800-\uDFFF].", re.UNICODE)
pattern = re.compile("[^\u0000-\uFFFF]", re.UNICODE)
Редактирайте добавянето на Python от скрипта на Denilson Sá в тялото на въпроса:
re_pattern = re.compile(u'[^\u0000-\uD7FF\uE000-\uFFFF]', re.UNICODE)
filtered_string = re_pattern.sub(u'\uFFFD', unicode_string)