По-рано публикувахме блог, обсъждащ Постигане на MySQL Failover &Failback на Google Cloud Platform (GCP) и в този блог ще разгледаме как неговият съперник, Amazon Relational Database Service (RDS), се справя с отказ. Ще разгледаме също така как можете да извършите възстановяване при отказ на предишния си главен възел, като го върнете към първоначалния му ред като главен.
Когато се сравняват публичните облаци от технологичен гигант, които поддържат управлявани услуги за релационни бази данни, Amazon е единствената, която предлага алтернативна опция (заедно с MySQL/MariaDB, PostgreSQL, Oracle и SQL Server) за предоставяне свой собствен вид управление на база данни, наречен Amazon Aurora. За тези, които не са запознати с Aurora, това е напълно управляван двигател за релационна база данни, който е съвместим с MySQL и PostgreSQL. Aurora е част от услугата за управлявана база данни Amazon RDS, уеб услуга, която улеснява настройването, работата и мащабирането на релационна база данни в облака.
Защо ще трябва да превключвате при отказ или отказ?
Проектирането на голяма система, която е устойчива на грешки, високодостъпна, без единична точка на отказ (SPOF), изисква правилно тестване, за да се определи как ще реагира, когато нещата се объркат.
Ако сте загрижени за това как би се представила вашата система, когато реагира на системата за откриване, изолиране и възстановяване (FDIR), тогава преодоляването при отказ и връщането при отказ трябва да са от голямо значение.
Отказ при отказ на база данни в Amazon RDS
Отказът става автоматично (тъй като ръчното превключване се нарича превключване). Както беше обсъдено в предишен блог, необходимостта от преодоляване на срив възниква, след като текущата ви главна база данни претърпи мрежова повреда или необичайно прекратяване на хост системата. Failover го превключва в стабилно състояние на резервиране или към резервен компютърен сървър, система, хардуерен компонент или мрежа.
В Amazon RDS не е необходимо да правите това, нито се изисква да го наблюдавате сами, тъй като RDS е услуга за управлявана база данни (което означава, че Amazon се справя с работата вместо вас). Тази услуга управлява неща като хардуерни проблеми, архивиране и възстановяване, актуализации на софтуера, надстройки за съхранение и дори софтуерни корекции. Ще говорим за това по-късно в този блог.
Отказ за възстановяване на база данни в Amazon RDS
В предишния блог също разгледахме защо ще трябва да върнете обратно. В типична репликирана среда главният трябва да е достатъчно мощен, за да носи огромен товар, особено когато изискването за работно натоварване е високо. Вашата основна настройка изисква адекватни хардуерни спецификации, за да гарантира, че може да обработва записи, да генерира събития за репликация, да обработва критични четения и т.н. по стабилен начин. Когато се изисква преодоляване на срив по време на възстановяване след бедствие (или за поддръжка), не е необичайно, че когато популяризирате нов главен, може да използвате по-нисък хардуер. Тази ситуация може временно да е наред, но в дългосрочен план определеният главен трябва да бъде върнат, за да ръководи репликацията, след като бъде счетена за здрава (или поддръжката е завършена).
Противно на превключването при отказ, операциите за възстановяване при отказ обикновено се извършват в контролирана среда чрез използване на превключване. Рядко се прави в режим на паника. Този подход предоставя на вашите инженери достатъчно време да планират внимателно и да репетират упражнението, за да осигурят плавен преход. Основната му цел е просто да върне добрия стар хозяин в най-новото състояние и да възстанови настройката за репликация до оригиналната й топология. Тъй като имаме работа с Amazon RDS, наистина няма нужда да се притеснявате прекалено много от този тип проблеми, тъй като това е управлявана услуга, като повечето задачи се обработват от Amazon.
Как Amazon RDS се справя с отказ на база данни?
Когато разгръщате вашите Amazon RDS възли, можете да настроите своя клъстер на база данни със зона за многократна наличност (AZ) или с една зона за достъпност. Нека проверим всеки един от тях за това как се обработва отказът.
Какво е настройка за няколко AZ?
Когато настъпи катастрофа или бедствие, като например непланирани прекъсвания или природни бедствия, при които са засегнати екземпляри на вашата база данни, Amazon RDS автоматично превключва към резервна реплика в друга зона за достъпност. Този AZ обикновено се намира в друг клон на центъра за данни, често далеч от текущата зона на наличност, където се намират екземпляри. Тези AZ са високодостъпни, най-съвременни съоръжения, защитаващи вашите копия на база данни. Времената за отказ зависят от завършването на настройката, което често се основава на размера и активността на базата данни, както и на други условия, присъстващи в момента, в който първичният DB екземпляр е станал недостъпен.
Времената за отказ обикновено са 60-120 секунди. Те обаче могат да бъдат по-дълги, тъй като големите транзакции или дълъг процес на възстановяване могат да увеличат времето за преминаване при отказ. Когато преминаването при отказ приключи, може да отнеме допълнително време, докато RDS конзолата (UI), за да отрази новата зона за наличност.
Какво е настройка с единична AZ?
Настройките за единична AZ трябва да се използват за вашите екземпляри на база данни, ако вашите RTO (Цел за време за възстановяване) и RPO (Цел за точка на възстановяване) са достатъчно високи, за да го позволят. Съществуват рискове, свързани с използването на Single-AZ, като големи престои, които могат да нарушат бизнес операциите.
Общи сценарии за отказ на RDS
Размерът на престоя зависи от вида на повредата. Нека да разгледаме какво представляват и как се обработва възстановяването на екземпляра.
Неуспех на възстановимия екземпляр
Повреда на екземпляр на Amazon RDS възниква, когато основният EC2 екземпляр претърпи повреда. При възникване, AWS ще задейства известие за събитие и ще ви изпрати сигнал с помощта на Amazon RDS Event Notifications. Тази система използва AWS Simple Notification Service (SNS) като процесор за предупреждение.
RDS автоматично ще се опита да стартира нов екземпляр в същата зона за наличност, ще прикачи EBS тома и ще направи опит за възстановяване. В този сценарий RTO обикновено е под 30 минути. RPO е нула, тъй като обемът на EBS може да бъде възстановен. Обемът на EBS е в една зона на достъпност и този тип възстановяване се извършва в същата зона на наличност като оригиналния екземпляр.
Невъзстановими повреди на екземпляр или грешки на обема на EBS
За неуспешно възстановяване на RDS екземпляр (или ако основният обем на EBS претърпи повреда при загуба на данни) е необходимо възстановяване в момента (PITR). PITR не се обработва автоматично от Amazon, така че трябва или да създадете скрипт, за да го автоматизирате (с помощта на AWS Lambda), или да го направите ръчно.
Времето на RTO изисква стартиране на нов екземпляр на Amazon RDS, който ще има ново DNS име, след като бъде създаден, и след това прилагане на всички промени от последното архивиране.
Обикновено RPO е 5 минути, но можете да го намерите, като извикате RDS:describe-db-instances:LatestRestorableTime. Времето може да варира от 10 минути до часове в зависимост от броя на трупите, които трябва да бъдат приложени. Може да се определи само чрез тестване, тъй като зависи от размера на базата данни, броя на направените промени след последното архивиране и нивата на натоварване на базата данни. Тъй като архивите и регистрационните файлове на транзакциите се съхраняват в Amazon S3, това възстановяване може да се извърши във всяка поддържана зона за достъпност в региона.
След като новият екземпляр бъде създаден, ще трябва да актуализирате името на крайната точка на вашия клиент. Също така имате възможност да го преименувате на името на крайната точка на стария DB екземпляр (но това изисква да изтриете стария неуспешен екземпляр), но това прави определянето на основната причина за проблема невъзможно.
Нарушения на зоната за наличност
Нарушенията на зоната за достъпност могат да бъдат временни и са редки, но ако повредата на AZ е по-постоянна, екземплярът ще бъде настроен в неуспешно състояние. Възстановяването ще работи, както е описано по-горе и може да се създаде нов екземпляр в различен AZ, като се използва възстановяване в момента. Тази стъпка трябва да се направи ръчно или чрез скриптове. Стратегията за този тип сценарий за възстановяване трябва да бъде част от вашите по-големи планове за възстановяване след бедствие (DR).
Ако повредата на зоната за достъпност е временна, базата данни ще не работи, но ще остане в налично състояние. Вие носите отговорност за наблюдението на ниво приложение (с помощта на инструменти на Amazon или на трети страни), за да откриете този тип сценарий. Ако това се случи, можете да изчакате възстановяването на зоната за наличност или да изберете да възстановите екземпляра в друга зона за наличност с възстановяване в даден момент.
RTO ще бъде времето, необходимо за стартиране на нов екземпляр на RDS и след това прилагане на всички промени от последното архивиране. RPO може да е по-дълъг до момента, в който възникне грешка в зоната за достъпност.
Тестване на отказ и отказ на Amazon RDS
Създадохме и настроихме Amazon RDS Aurora, използвайки db.r4.large с внедряване в няколко AZ (което ще създаде реплика/четец на Aurora в различен AZ), който е достъпен само през EC2. Ще трябва да изберете тази опция при създаването, ако възнамерявате да имате Amazon RDS като механизъм за преодоляване на срив.
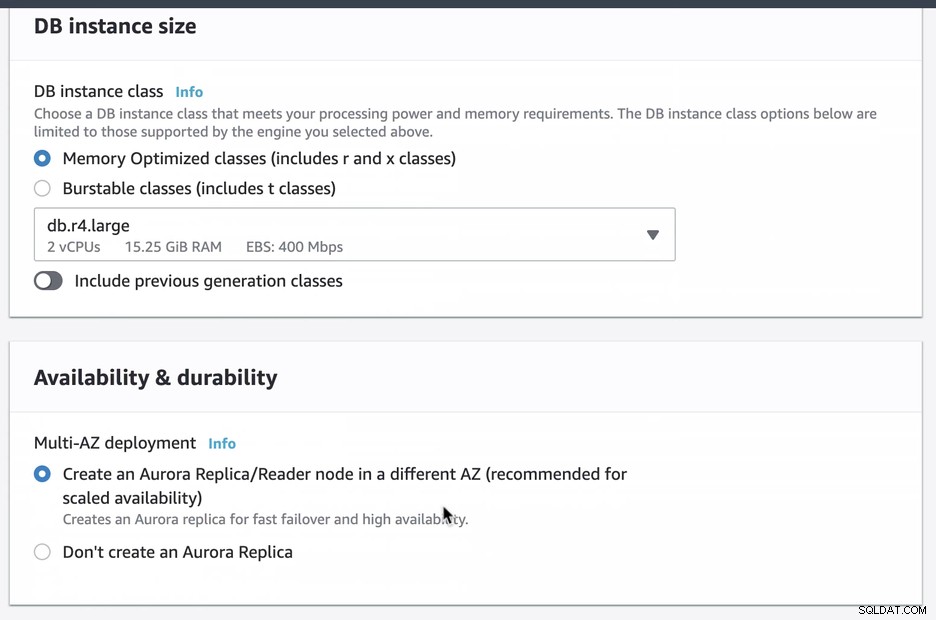
По време на предоставянето на нашия RDS екземпляр отне около ~11 минути преди екземплярите станаха достъпни и достъпни. По-долу е екранна снимка на възлите, налични в RDS след създаването:
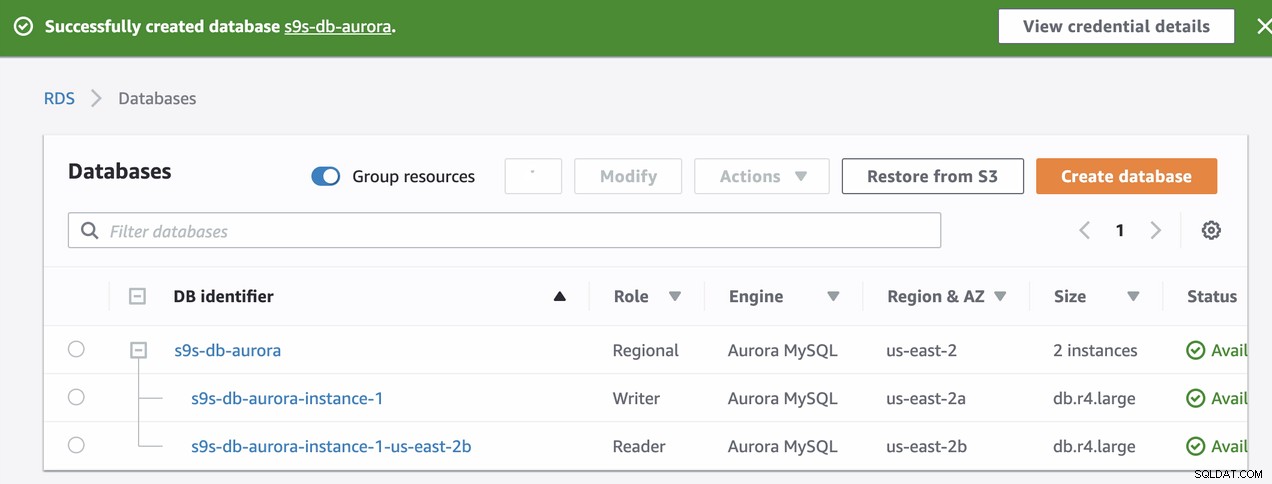
Тези два възела ще имат свои собствени определени имена на крайни точки, които ние ще използвайте за свързване от гледна точка на клиента. Проверете го първо и проверете основното име на хост за всеки от тези възли. За да проверите, можете да изпълните тази bash команда по-долу и просто да замените съответно имената на хостове/крайни точки:
example@sqldat.com:~# host=('s9s-db-aurora.cluster-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' 's9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com'); for h in "${host[@]}"; do mysql -h $h -e "select @@hostname; select @@global.innodb_read_only"; done;
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+Резултатът се изяснява, както следва,
s9s-db-aurora-instance-1 = s9s-db-aurora.cluster-cmu8qdlvkepg.us-east-2.rds.amazonaws.com = ip-10-20-0-94 (read-write)
s9s-db-aurora-instance-1-us-east-2b = s9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com = ip-10-20-1-139 (read-only)Симулиране на отказ на Amazon RDS
Сега нека симулираме срив, за да симулираме отказ за екземпляр за запис на Amazon RDS Aurora, който е s9s-db-aurora-instance-1 с крайна точка s9s-db-aurora.cluster-cmu8qdlvkepg.us -east-2.rds.amazonaws.com.
За да направите това, свържете се с вашия екземпляр за запис, като използвате командния ред на mysql клиент и след това издайте синтаксиса по-долу:
ALTER SYSTEM SIMULATE percentage_of_failure PERCENT DISK FAILURE [ IN DISK index | NODE index ]
FOR INTERVAL quantity [ YEAR | QUARTER | MONTH | WEEK| DAY | HOUR | MINUTE | SECOND ];Издаването на тази команда има откриване за възстановяване на Amazon RDS и действа доста бързо. Въпреки че заявката е с цел тестване, тя може да се различава, когато това се случи във фактическо събитие. Може да ви е интересно да научите повече за тестването на срив на екземпляр в тяхната документация. Вижте как се озоваваме по-долу:
mysql> ALTER SYSTEM SIMULATE 100 PERCENT DISK FAILURE FOR INTERVAL 3 MINUTE;
Query OK, 0 rows affected (0.01 sec)Изпълнението на SQL командата по-горе означава, че тя трябва да симулира повреда на диска за поне 3 минути. Наблюдавах момента във времето за започване на симулацията и отне около 18 секунди, преди да започне превключването при отказ.
Вижте по-долу как RDS се справя с неуспеха на симулацията и превключването,
Tue Sep 24 10:06:29 UTC 2019
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
….
…..
………..
Tue Sep 24 10:06:44 UTC 2019
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
ERROR 2003 (HY000): Can't connect to MySQL server on 's9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' (111)
….
……..
………..
Tue Sep 24 10:06:51 UTC 2019
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
….
………..
…………………
Tue Sep 24 10:07:13 UTC 2019
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+Резултатите от тази симулация са доста интересни. Нека вземем това едно по едно.
- Около 10:06:29 започнах да изпълнявам заявката за симулация, както е посочено по-горе.
- Около 10:06:44 показва, че крайната точка s9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com с присвоено име на хост ip-10-20-1- 139, където всъщност това е екземпляр само за четене, остана недостъпен, въпреки че командата за симулация беше изпълнена под екземпляра за четене-запис.
- Около 10:06:51 часа показва, че крайната точка s9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com с присвоено име на хост на ip-10-20-1- 139 е нагоре, но има маркировка като състояние за четене и запис. Обърнете внимание, че променливата innodb_read_only, за управлявани от Aurora MySQL екземпляри, това е неговият идентификатор, за да се определи дали хостът е възел за четене-запис или само за четене и Aurora също работи само на InnoDB машина за съхранение за MySQL съвместими инстанции.
- Около 10:07:13 ч. редът се промени. Това означава, че преминаването при отказ е извършено и екземплярите са присвоени на определените му крайни точки.
Вижте резултата по-долу, който се показва в RDS конзолата:
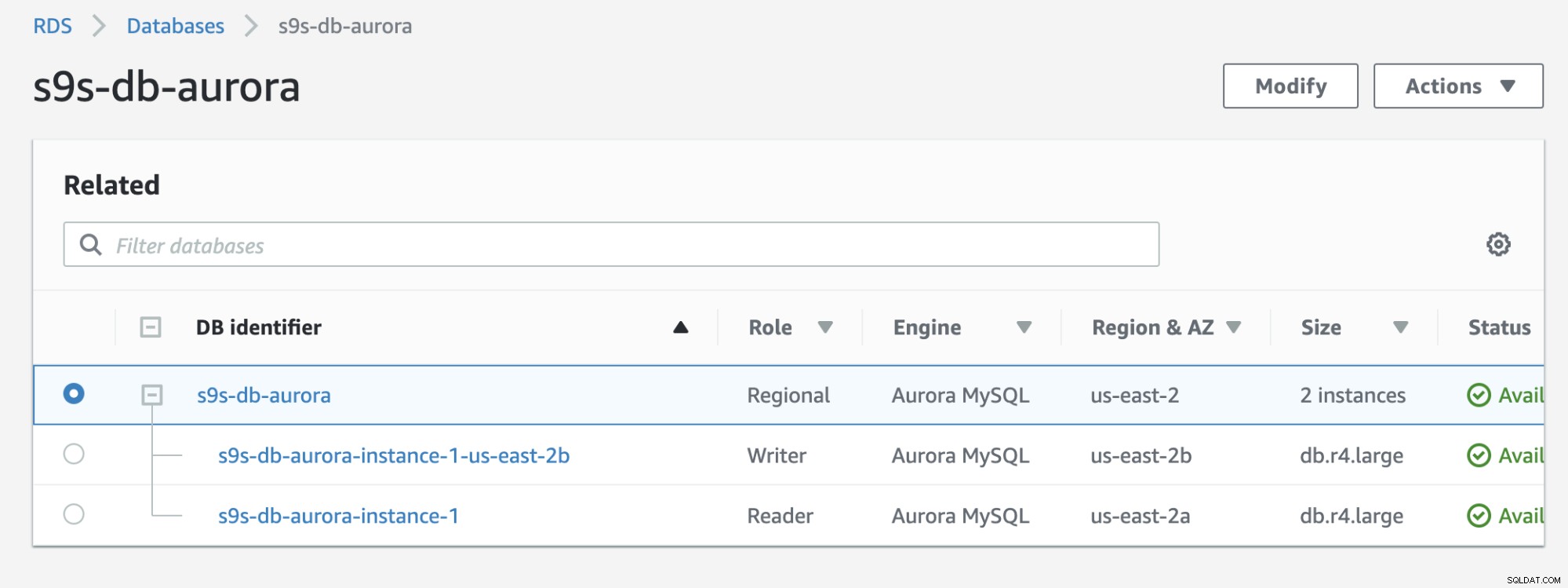
Ако сравните с по-ранния, s9s-db-aurora- instance-1 беше четец, но след това беше повишен като писател след отказ. Процесът, включващ теста, отне около 44 секунди, за да завърши задачата, но преминаването при отказ показва, че е завършено за почти 30 секунди. Това е впечатляващо и бързо за отказ, особено като се има предвид, че това е база данни за управлявани услуги; което означава, че не е нужно да се притеснявате за проблеми с хардуера или поддръжката.
Извършване на отказ в Amazon RDS
Отказът в Amazon RDS е доста лесен. Преди да преминем през него, нека добавим нова реплика на четец. Нуждаем се от опция за тестване и идентифициране на кой възел AWS RDS би избрал, когато се опита да се върне към желания главен (или да се върне към предишния главен обект) и да видим дали избира правилния възел въз основа на приоритет. Текущият списък с екземпляри към момента и неговите крайни точки са показани по-долу.
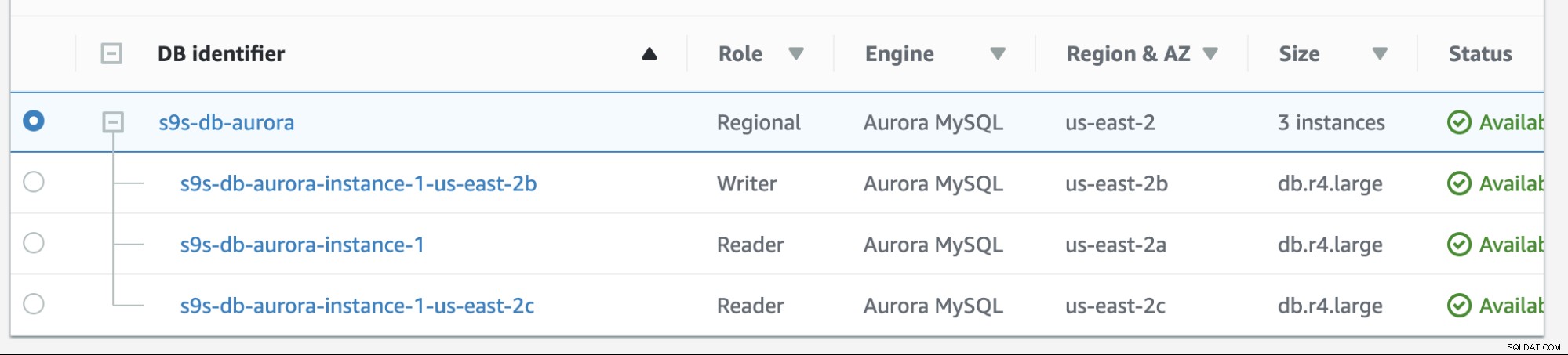

Новата реплика се намира на us-east-2c AZ с db име на хост на IP-10-20-2-239.
Ще се опитаме да направим възстановяване при отказ, като използваме екземпляра s9s-db-aurora-instance-1 като желана цел за възстановяване при отказ. В тази настройка имаме два екземпляра на четеца. За да сте сигурни, че правилният възел е избран по време на отказ, ще трябва да установите дали приоритетът или наличността са отгоре (ниво-0> ниво-1> ниво-2 и така нататък до ниво-15). Това може да стане чрез модифициране на екземпляра или по време на създаването на репликата.
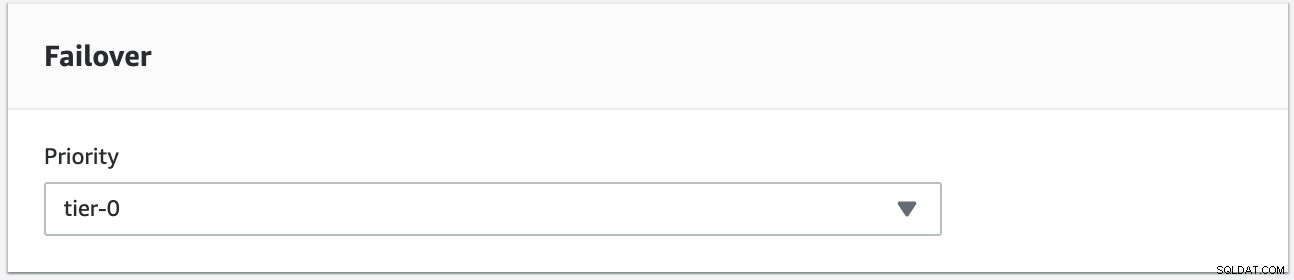
Можете да потвърдите това във вашата RDS конзола.
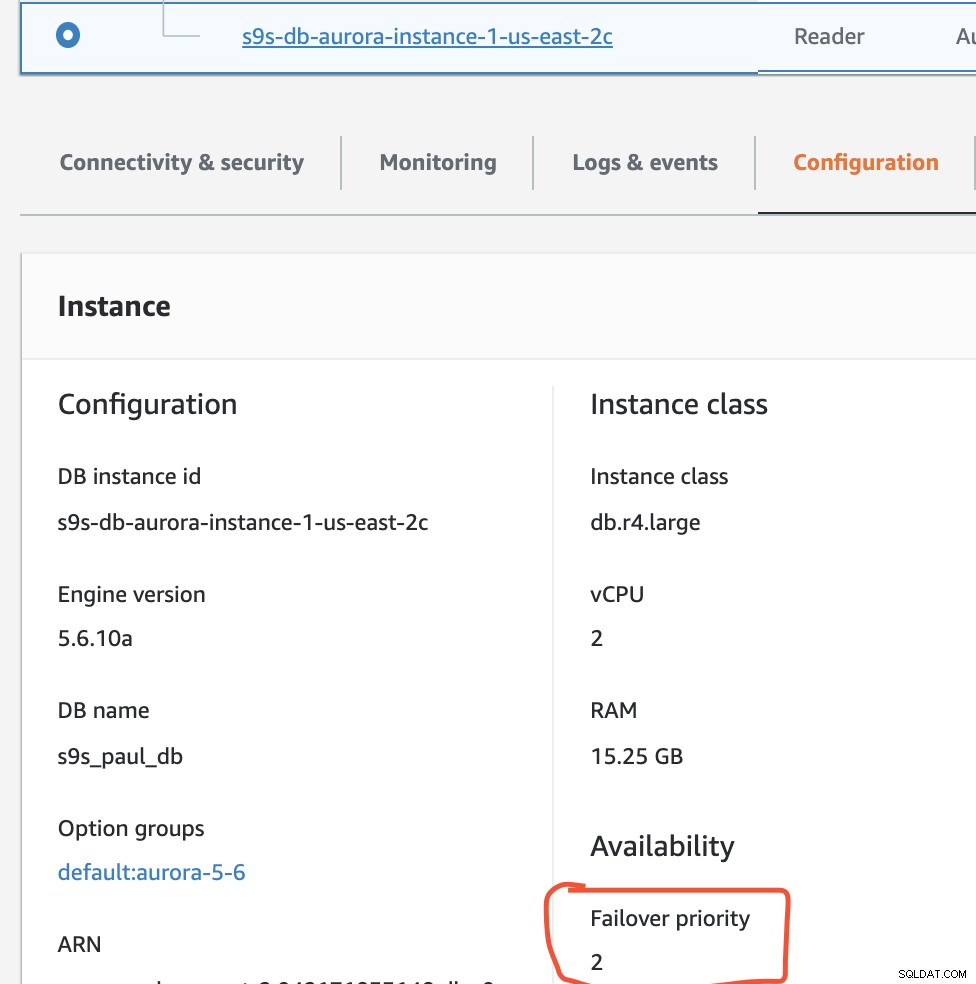
В тази настройка s9s-db-aurora-instance-1 има приоритет =0 (и е реплика за четене), s9s-db-aurora-instance-1-us-east-2b има приоритет =1 (и е текущият записващ), а s9s-db-aurora-instance-1-us- east-2c има приоритет =2 (и също е реплика за четене). Нека видим какво се случва, когато се опитаме да върнем обратно.
Можете да наблюдавате състоянието, като използвате тази команда.
$ host=('s9s-db-aurora.cluster-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' 's9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' 's9s-us-east-2c.cluster-custom-cmu8qdlvkepg.us-east-2.rds.amazonaws.com'); while true; do echo -e "\n==========================================="; date; echo -e "===========================================\n"; for h in "${host[@]}"; do mysql -h $h -e "select @@hostname; select @@global.innodb_read_only"; done; sleep 1; done;След като се задейства отказът, той ще се върне към желаната от нас цел, която е възел s9s-db-aurora-instance-1.
===========================================
Tue Sep 24 13:30:59 UTC 2019
===========================================
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-2-239 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
…
……
………
===========================================
Tue Sep 24 13:31:35 UTC 2019
===========================================
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
ERROR 2003 (HY000): Can't connect to MySQL server on 's9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' (111)
ERROR 2003 (HY000): Can't connect to MySQL server on 's9s-us-east-2c.cluster-custom-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' (111)
….
…..
===========================================
Tue Sep 24 13:31:38 UTC 2019
===========================================
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-2-239 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-2-239 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+Опитът за връщане при отказ започна в 13:30:59 и завърши около 13:31:38 (най-близката точка от 30 секунди). Завършва около 32 секунди на този тест, което все още е бързо.
Проверих преминаването/отказът при отказ няколко пъти и той постоянно обменя състоянието си четене-запис между екземпляри s9s-db-aurora-instance-1 и s9s-db-aurora-instance-1- нас-изток-2б. Това оставя s9s-db-aurora-instance-1-us-east-2c неизбрани, освен ако и двата възела не изпитват проблеми (което е много рядко, тъй като всички те са разположени в различни AZ).
По време на опитите за превключване/отказ при отказ, RDS преминава с бърз преход по време на отказ от около 15 - 25 секунди (което е много бързо). Имайте предвид, че нямаме огромни файлове с данни, съхранявани в този екземпляр, но все пак е доста впечатляващо, като се има предвид, че няма какво повече да управлявате.
Заключение
Изпълнението на Single-AZ създава опасност при извършване на отказ. Amazon RDS ви позволява да модифицирате и конвертирате вашата Single-AZ в настройка с възможност за Multi-AZ, въпреки че това ще добави някои разходи за вас. Single-AZ може да е добре, ако сте добре с по-високо RTO и RPO време, но определено не се препоръчва за висок трафик, критични за мисията, бизнес приложения.
С Multi-AZ можете да автоматизирате преодоляване на отказ и възстановяване на отказ на Amazon RDS, като прекарвате времето си в настройване или оптимизиране на заявки. Това облекчава много проблеми, пред които са изправени DevOps или DBA.
Въпреки че Amazon RDS може да предизвика дилема в някои организации (тъй като не е независим от платформата), все пак заслужава внимание; особено ако приложението ви изисква дългосрочен план за DR и не искате да прекарвате време в грижи за хардуера и планирането на капацитета.