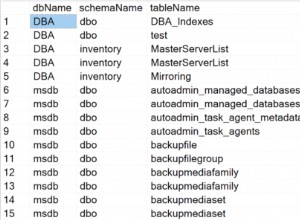
SELECT a.license_id, a.limit_call
, count(b.license_id) AS overall_count
FROM "License" a
LEFT JOIN "Log" b USING (license_id)
WHERE a.license_id = 7
GROUP BY a.license_id -- , a.limit_call -- add in old versions
HAVING a.limit_call > count(b.license_id)
От Postgres 9.1 първичният ключ покрива всички колони на таблица в GROUP BY клауза. В по-старите версии ще трябва да добавите a.limit_call към GROUP BY списък. Бележки към версията за 9.1:
Разрешаване на не-
GROUP BYколони в списъка с цели на заявката, когато първичният ключ е посочен вGROUP BYклауза
Допълнително четене:
- Защо не мога да изключа зависими колони от „GROUP BY“, когато агрегирам по ключ?
Състоянието, което сте имали в WHERE клаузата трябва да се премести в HAVING клауза, тъй като се отнася до резултата от агрегатна функция (след WHERE е приложен). И не можете да се позовавате на изходни колони (псевдоними на колони) в HAVING клауза, където можете да препращате само към входни колони. Така че трябва да повторите израза. Ръководството:
Името на изходна колона може да се използва за препращане към стойността на колоната в
ORDER BYиGROUP BYклаузи, но не и вWHEREилиHAVINGклаузи; там трябва да напишете израза вместо това.
Обърнах реда на таблиците в FROM клауза и почистих малко синтаксиса, за да го направи по-малко объркващо. USING тук е просто удобство при нотации.
Използвах LEFT JOIN вместо JOIN , така че изобщо не изключвате лицензи без никакви регистрационни файлове.
Само ненулеви стойности се отчитат от count() . Тъй като искате да преброите свързани записи в таблица "Log" по-безопасно и малко по-евтино е да използвате count(b.license_id) . Тази колона се използва в присъединяването, така че не е нужно да се притесняваме дали колоната може да бъде нула или не.count(*) е още по-кратък и малко по-бърз. Ако нямате нищо против да получите брой 1 за 0 редове в лявата таблица, използвайте това.
Настрана:Бих посъветвал не да използвате смесени идентификатори в Postgres, ако е възможно. Много податливи на грешки.