Като администратори на база данни на SQL Server, ние чухме, че индексните структури могат драстично да подобрят производителността на всяка заявка (или набор от заявки). Все пак има някои подробности, които много DBA пренебрегват, като следното:
- Структурите на индексите могат да бъдат фрагментирани, което потенциално да доведе до проблеми с влошаване на производителността.
- След като структура на индекс е разгърната за таблица на база данни, SQL Server я актуализира всеки път, когато се извършват операции по запис за тази таблица. Това се случва, ако колоните, които отговарят на индекса, са засегнати.
- В SQL Server има метаданни, които могат да се използват, за да се знае кога статистическите данни за конкретна индексна структура са били актуализирани (ако някога) за последен път. Недостатъчните или остарели статистически данни могат да повлияят на ефективността на определени заявки.
- В SQL Server има метаданни, които могат да се използват, за да се знае колко структура на индекса е била или консумирана от операции за четене, или актуализирана чрез операции за запис от самия SQL Server. Тази информация може да бъде полезна, за да разберете дали има индекси, чийто обем на запис значително надвишава този за четене. Потенциално може да е индексна структура, която не е толкова полезна за поддържане.*
*Много е важно да имате предвид, че системният изглед, който съдържа тези конкретни метаданни, се изтрива всеки път, когато екземплярът на SQL Server се рестартира, така че няма да е информация от неговата концепция.
Поради важността на тези подробности създадох Съхранена процедура, за да следя информация относно индексните структури в неговата/нейната среда, за да действам възможно най-активно.
Първоначални съображения
- Уверете се, че акаунтът, изпълняващ тази съхранена процедура, има достатъчно привилегии. Вероятно бихте могли да започнете с тези на системния администратор и след това да преминете възможно най-подробно, за да сте сигурни, че потребителят има минималните привилегии, необходими за правилното функциониране на SP.
- Обектите на базата данни (таблица на базата данни и съхранена процедура) ще бъдат създадени вътре в базата данни, избрани в момента, в който скриптът се изпълнява, така че избирайте внимателно.
- Скриптът е изработен по начин, който може да бъде изпълнен няколко пъти, без да се извежда грешка. За съхранената процедура използвах израза CREATE OR ALTER PROCEDURE, наличен от SQL Server 2016 SP1.
- Чувствайте се свободни да промените името на създадените обекти на базата данни, ако искате да използвате различно именуване.
- Когато изберете да запазите данните, върнати от съхранената процедура, целевата таблица първо ще бъде съкратена, така че ще бъде съхранен само най-скорошният набор от резултати. Можете да направите необходимите корекции, ако искате това да се държи по различен начин, по каквато и да е причина (за да запазите историческа информация може би?).
Как да използвам съхранената процедура?
- Копирайте и поставете T-SQL кода (наличен в тази статия).
- SP очаква 2 параметъра:
- @persistData:„Y“, ако DBA желае да запази изхода в целева таблица, и „N“, ако DBA иска само да види изхода директно.
- @db:'all' за получаване на информацията за всички бази данни (система и потребител), 'user' за насочване към потребителски бази данни, 'system' за насочване само към системни бази данни (с изключение на tempdb) и накрая действителното име на конкретна база данни.
Представени полета и тяхното значение
- dbName: името на базата данни, където се намира индексният обект.
- schemaName: името на схемата, където се намира индексният обект.
- Име на таблица: името на таблицата, където се намира индексният обект.
- indexName: името на структурата на индекса.
- тип: вида на индекса (напр. клъстериран, неклъстериран).
- тип_единица_разпределение: определя типа на данните, към които се отнасят (например данни в ред, данни за дял).
- фрагментиране: количеството фрагментация (в %), което структурата на индекса има в момента.
- страници: броя на страниците от 8KB, които формират структурата на индекса.
- пише: броят записвания, които структурата на индекса е изпитала след последното рестартиране на екземпляра на SQL Server.
- чете: броят четения, които структурата на индекса е преживяла след последното рестартиране на екземпляра на SQL Server.
- деактивирано: 1, ако структурата на индекса в момента е деактивирана или 0, ако структурата е активирана.
- stats_timestamp: стойността на клеймото за време, когато статистическите данни за конкретната структура на индекса са били последно актуализирани (NULL, ако никога).
- data_collection_timestamp: видимо само ако „Y“ е предадено на параметъра @persistData и се използва, за да се знае кога SP е бил изпълнен и информацията е била успешно запазена в таблицата DBA_Indexes.
Тестове за изпълнение
Ще демонстрирам няколко изпълнения на Съхранената процедура, за да можете да получите представа какво да очаквате от нея:
*Можете да намерите пълния T-SQL код на скрипта в края на тази статия, така че не забравяйте да го изпълните, преди да преминете към следващия раздел.
*Наборът от резултати ще бъде твърде широк, за да се побере добре в 1 екранна снимка, така че ще споделя всички необходими екранни снимки, за да представя пълната информация.
/* Показва цялата информация за индексите за всички системни и потребителски бази данни */
EXEC GetIndexData @persistData = 'N',@db = 'all'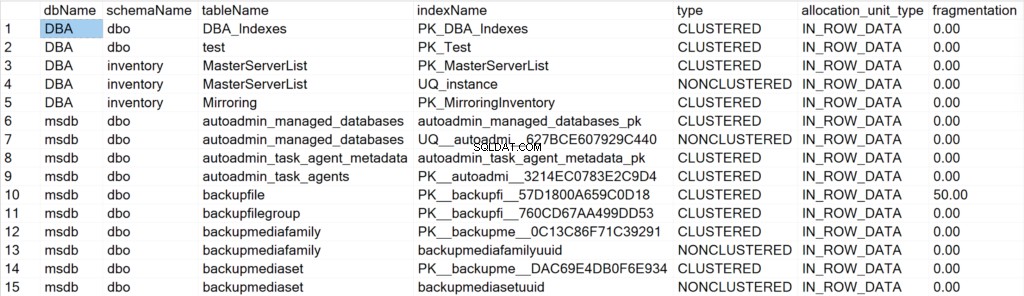
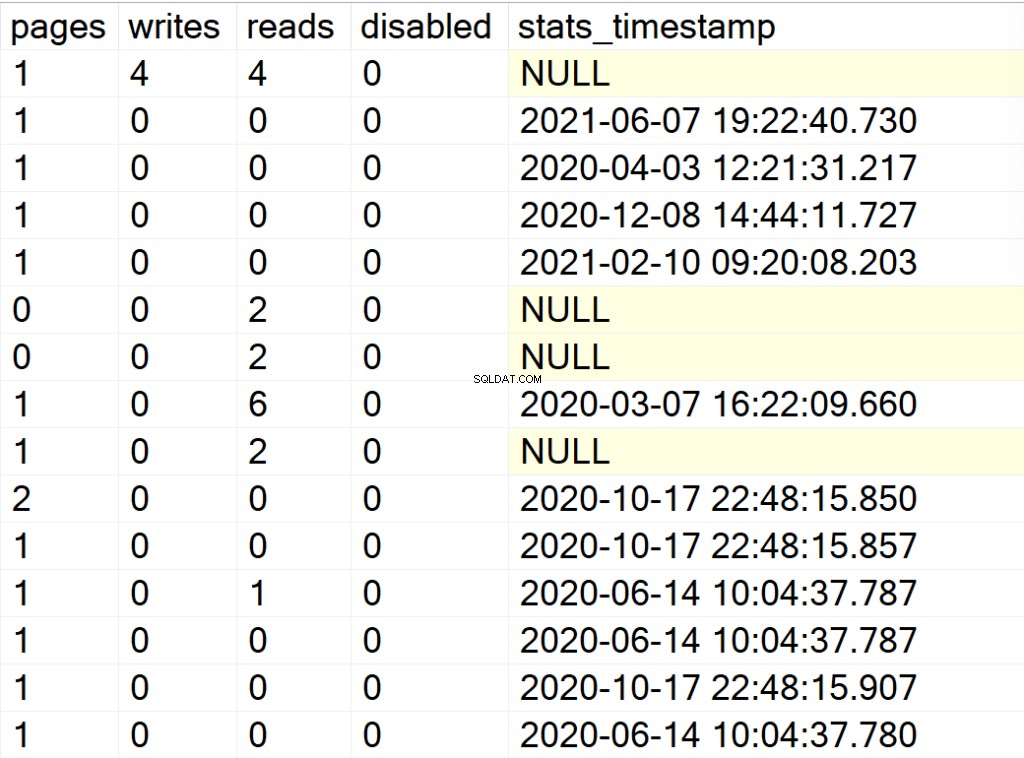
/* Показва цялата информация за индекси за всички системни бази данни */
EXEC GetIndexData @persistData = 'N',@db = 'system'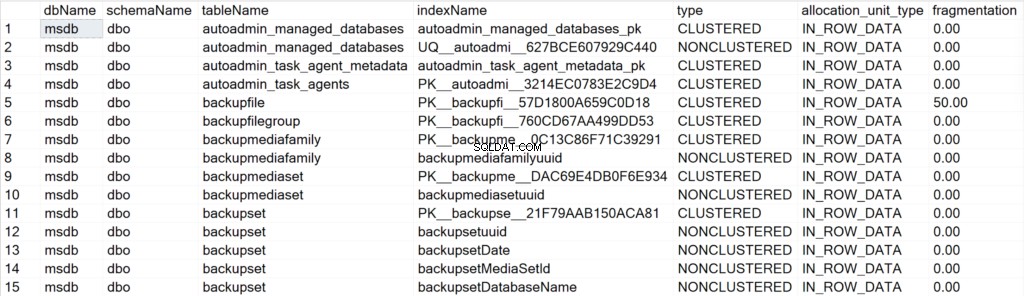
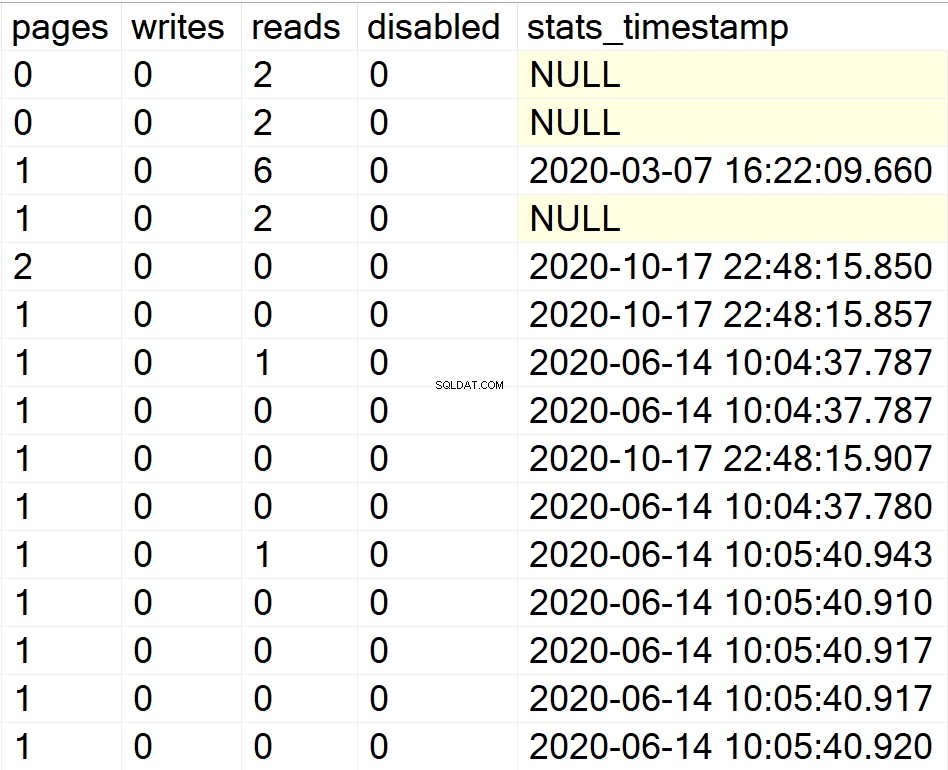
/* Показва цялата информация за индекси за всички потребителски бази данни */
EXEC GetIndexData @persistData = 'N',@db = 'user'
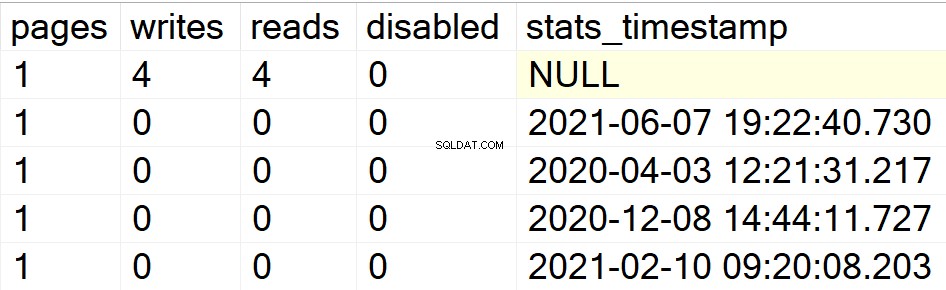
/* Показва цялата информация за индекси за конкретни потребителски бази данни */
В предишните ми примери само базата данни DBA се показа като единствената ми потребителска база данни с индекси в нея. Ето защо, нека създам структура на индекс в друга база данни, която имам в същия екземпляр, така че да можете да видите дали SP прави своето или не.
EXEC GetIndexData @persistData = 'N',@db = 'db2'
Всички показани досега примери демонстрират изхода, който получавате, когато не искате да съхранявате данни, за различните комбинации от опции за параметъра @db. Резултатът е празен, когато или посочите опция, която не е валидна, или целевата база данни не съществува. Но какво да кажем, когато DBA иска да запази данните в таблица на база данни? Нека разберем.
*Ще стартирам SP само за един случай, защото останалите опции за параметъра @db бяха показани по-горе и резултатът е същият, но се запазва в таблица на база данни.
EXEC GetIndexData @persistData = 'Y',@db = 'user'
Сега, след като изпълните съхранената процедура, няма да получите никакъв изход. За да направите заявка за набора от резултати, трябва да издадете оператор SELECT срещу таблицата DBA_Indexes. Основната атракция тук е, че можете да заявите получения набор от резултати за последващ анализ и добавяне на полето data_collection_timestamp, което ще ви уведоми колко скорошни/стари са данните, които разглеждате.
Странични заявки
Сега, за да предам повече стойност на DBA, подготвих няколко заявки, които могат да ви помогнат да получите полезна информация от данните, запазени в таблицата.
*Запитване за намиране на много фрагментирани индекси като цяло.
*Изберете процента, който смятате за подходящ.
*1500-те страници са базирани на статия, която прочетох, въз основа на препоръката на Microsoft.
SELECT * FROM DBA_Indexes WHERE fragmentation >= 85 AND pages >= 1500;*Запитване за намиране на деактивирани индекси във вашата среда.
SELECT * FROM DBA_Indexes WHERE disabled = 1;*Запитване за намиране на индекси (предимно неклъстерирани), които не се използват толкова много от заявките, поне не от последния път, когато екземплярът на SQL Server е бил рестартиран.
SELECT * FROM DBA_Indexes WHERE writes > reads AND type <> 'CLUSTERED';*Запитване за намиране на статистически данни, които никога не са били актуализирани или са стари.
*Вие определяте какво е старо във вашата среда, така че не забравяйте да коригирате съответно броя дни.
SELECT * FROM DBA_Indexes WHERE stats_timestamp IS NULL OR DATEDIFF(DAY, stats_timestamp, GETDATE()) > 60;Ето пълния код на Съхранената процедура:
*В самото начало на скрипта ще видите стойността по подразбиране, която запаметената процедура приема, ако не се подаде стойност за всеки параметър.
IF NOT EXISTS (SELECT * FROM dbo.sysobjects where id = object_id(N'DBA_Indexes') and OBJECTPROPERTY(id, N'IsTable') = 1)
BEGIN
CREATE TABLE DBA_Indexes(
[dbName] VARCHAR(128) NOT NULL,
[schemaName] VARCHAR(128) NOT NULL,
[tableName] VARCHAR(128) NOT NULL,
[indexName] VARCHAR(128) NOT NULL,
[type] VARCHAR(128) NOT NULL,
[allocation_unit_type] VARCHAR(128) NOT NULL,
[fragmentation] DECIMAL(10,2) NOT NULL,
[pages] INT NOT NULL,
[writes] INT NOT NULL,
[reads] INT NOT NULL,
[disabled] TINYINT NOT NULL,
[stats_timestamp] DATETIME NULL,
[data_collection_timestamp] DATETIME NOT NULL
CONSTRAINT PK_DBA_Indexes PRIMARY KEY CLUSTERED ([dbName],[schemaName],[tableName],[indexName],[type],[allocation_unit_type],[data_collection_timestamp])
) ON [PRIMARY]
END
GO
DECLARE @sqlCommand NVARCHAR(MAX)
SET @sqlCommand = '
CREATE OR ALTER PROCEDURE GetIndexData
@persistData CHAR(1) = ''N'',
@db NVARCHAR(64)
AS
BEGIN
SET NOCOUNT ON
DECLARE @query NVARCHAR(MAX)
DECLARE @tmp_IndexInfo TABLE(
[dbName] VARCHAR(128),
[schemaName] VARCHAR(128),
[tableName] VARCHAR(128),
[indexName] VARCHAR(128),
[type] VARCHAR(128),
[allocation_unit_type] VARCHAR(128),
[fragmentation] DECIMAL(10,2),
[pages] INT,
[writes] INT,
[reads] INT,
[disabled] TINYINT,
[stats_timestamp] DATETIME)
SET @query = ''
USE [?]
''
IF(@db = ''all'')
SET @query += ''
IF DB_ID(''''?'''') > 0 AND DB_ID(''''?'''') != 2
''
IF(@db = ''system'')
SET @query += ''
IF DB_ID(''''?'''') > 0 AND DB_ID(''''?'''') < 5 AND DB_ID(''''?'''') != 2
''
IF(@db = ''user'')
SET @query += ''
IF DB_ID(''''?'''') > 4
''
IF(@db != ''user'' AND @db != ''all'' AND @db != ''system'')
SET @query += ''
IF DB_NAME() = ''+CHAR(39)example@sqldat.com+CHAR(39)+''
''
SET @query += ''
BEGIN
DECLARE @DB_ID INT;
SET @DB_ID = DB_ID();
SELECT
db_name(@DB_ID) AS db_name,
s.name,
t.name,
i.name,
i.type_desc,
ips.alloc_unit_type_desc,
CONVERT(DECIMAL(10,2),ips.avg_fragmentation_in_percent),
ips.page_count,
ISNULL(ius.user_updates,0),
ISNULL(ius.user_seeks + ius.user_scans + ius.user_lookups,0),
i.is_disabled,
STATS_DATE(st.object_id, st.stats_id)
FROM sys.indexes i
JOIN sys.tables t ON i.object_id = t.object_id
JOIN sys.schemas s ON s.schema_id = t.schema_id
JOIN sys.dm_db_index_physical_stats (@DB_ID, NULL, NULL, NULL, NULL) ips ON ips.database_id = @DB_ID AND ips.object_id = t.object_id AND ips.index_id = i.index_id
LEFT JOIN sys.dm_db_index_usage_stats ius ON ius.database_id = @DB_ID AND ius.object_id = t.object_id AND ius.index_id = i.index_id
JOIN sys.stats st ON st.object_id = t.object_id AND st.name = i.name
WHERE i.index_id > 0
END''
INSERT INTO @tmp_IndexInfo
EXEC sp_MSForEachDB @query
IF @persistData = ''N''
SELECT * FROM @tmp_IndexInfo ORDER BY [dbName],[schemaName],[tableName]
ELSE
BEGIN
TRUNCATE TABLE DBA_Indexes
INSERT INTO DBA_Indexes
SELECT *,GETDATE() FROM @tmp_IndexInfo ORDER BY [dbName],[schemaName],[tableName]
END
END
'
EXEC (@sqlCommand)
GOЗаключение
- Можете да разположите този SP във всеки екземпляр на SQL Server под вашата поддръжка и да внедрите механизъм за предупреждение в целия си пакет от поддържани екземпляри.
- Ако внедрите задача на агент, която отправя заявки към тази информация относително често, можете да останете на върха на играта, за да се погрижите за структурите на индексите в поддържаната(ите) среда(и).
- Уверете се, че сте тествали правилно този механизъм в пясъчна среда и когато планирате производствено внедряване, не забравяйте да изберете периоди с ниска активност.
Проблемите с фрагментацията на индекса могат да бъдат трудни и стресиращи. За да ги намерите и коригирате, можете да използвате различни инструменти, като dbForge Index Manager, който можете да изтеглите тук.