MySQL има дълга традиция в географската репликация. Разпределянето на клъстери към отдалечени центрове за данни намалява ефектите от географската латентност, като приближава данните до потребителя. Освен това предоставя възможност за възстановяване след бедствие. Поради значителните разходи за дублиране на хардуер в отделен сайт, не много компании са били в състояние да си го позволят в миналото. Друга цена е квалифициран персонал, който е в състояние да проектира, внедри и поддържа сложна среда за множество центрове за данни.
С революцията за автоматизация в облака и DevOps, разпределеният център за данни никога не е бил по-достъпен за масите. Доставчиците на облак увеличават гамата от услуги, които предлагат на по-добра цена. Човек може да изгради кръстосани облачни хибридни среди с данни, разпространени по целия свят. Човек може да направи гъвкави и мащабируеми планове за DR, за да подходи към широк спектър от сценарии на прекъсване. В някои случаи това може да бъде просто резервно копие, съхранявано извън сайта. В други случаи може да бъде копие 1 към 1 на производствена среда, работеща някъде другаде.
В този блог ще разгледаме някои от тези случаи и ще разгледаме често срещаните сценарии.
Съхранение на резервни копия в облака
Планът за DR е общ термин, който описва процес за възстановяване на нарушени ИТ системи и други критични активи, които организацията използва. Архивирането е основният метод за постигане на това. Когато резервното копие е в същия център за данни като вашите производствени сървъри, рискувате всички данни да бъдат изтрити, в случай че загубите този център за данни. За да избегнете това, трябва да имате правилата за създаване на копие на друго физическо място. Все още е добра практика да съхранявате резервно копие на диск, за да намалите времето, необходимо за възстановяване. В повечето случаи ще съхранявате основното си резервно копие в същия център за данни (за да сведете до минимум времето за възстановяване), но също така трябва да имате резервно копие, което може да се използва за възстановяване на бизнес процедури, когато основният център за данни не работи.
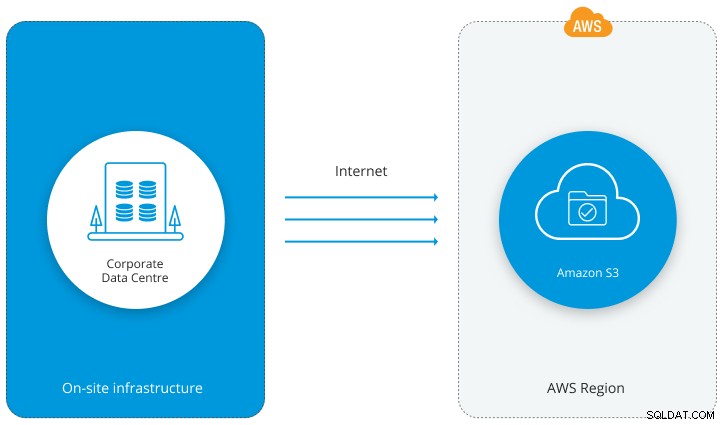
 ClusterControl:Качване на архивно копие в облака
ClusterControl:Качване на архивно копие в облака ClusterControl позволява безпроблемна интеграция между вашата среда на база данни и облака. Той предоставя опции за мигриране на данни в облака. Ние предлагаме пълна комбинация от архивиране на бази данни за Amazon Web Services (AWS), Google Cloud Services или Microsoft Azure. Архивите вече могат да се изпълняват, планират, изтеглят и възстановяват директно от избрания от вас доставчик на облак. Тази способност осигурява повишено съкращаване, по-добри опции за възстановяване след бедствие и предимства както в производителността, така и в спестяването на разходи.
 ClusterControl:Управление на облачни идентификационни данни
ClusterControl:Управление на облачни идентификационни данни Първата стъпка за настройка на „провал в центъра за данни – доказателство за архивиране“ е да предоставите идентификационни данни за вашия облачен оператор. Тук можете да избирате от множество доставчици. Нека да разгледаме процеса, настроен за най-популярния облачен оператор - AWS.
 ClusterControl:добавяне на облачни идентификационни данни
ClusterControl:добавяне на облачни идентификационни данни Всичко, от което се нуждаете, е идентификаторът на AWS Key ID и тайната за региона, в който искате да съхранявате резервното си копие. Можете да го получите от конзолата на AWS. Можете да следвате няколко стъпки, за да го получите.
- Използвайте имейл адреса и паролата на вашия акаунт в AWS, за да влезете в конзолата за управление на AWS като root потребител на акаунта на AWS.
- На страницата IAM Dashboard изберете името на акаунта си в лентата за навигация и след това изберете Моите идентификационни данни за сигурност .
- Ако видите предупреждение за достъп до идентификационните данни за сигурност за вашия акаунт в AWS, изберете Продължете към идентификационните данни за сигурност .
- Разгънете секцията Ключове за достъп (идентификатор на ключ за достъп и таен ключ за достъп).
- Изберете Създаване на нов ключ за достъп . След това изберете Изтегляне на ключов файл за да запишете идентификатора на ключа за достъп и секретния ключ за достъп във файл на вашия компютър. След като затворите диалоговия прозорец, няма да можете да извлечете отново този таен ключ за достъп.
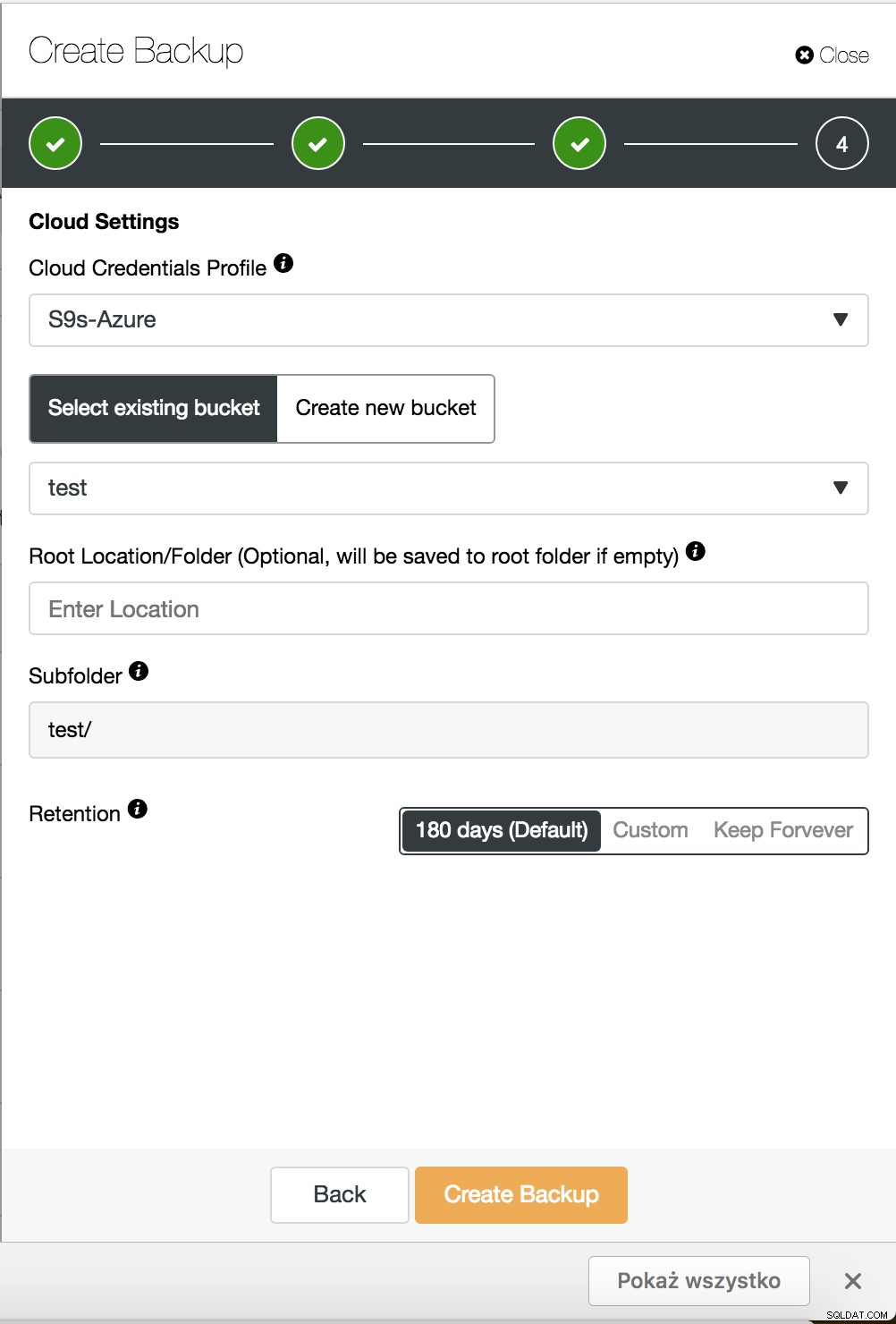 ClusterControl:хибридно архивиране в облак
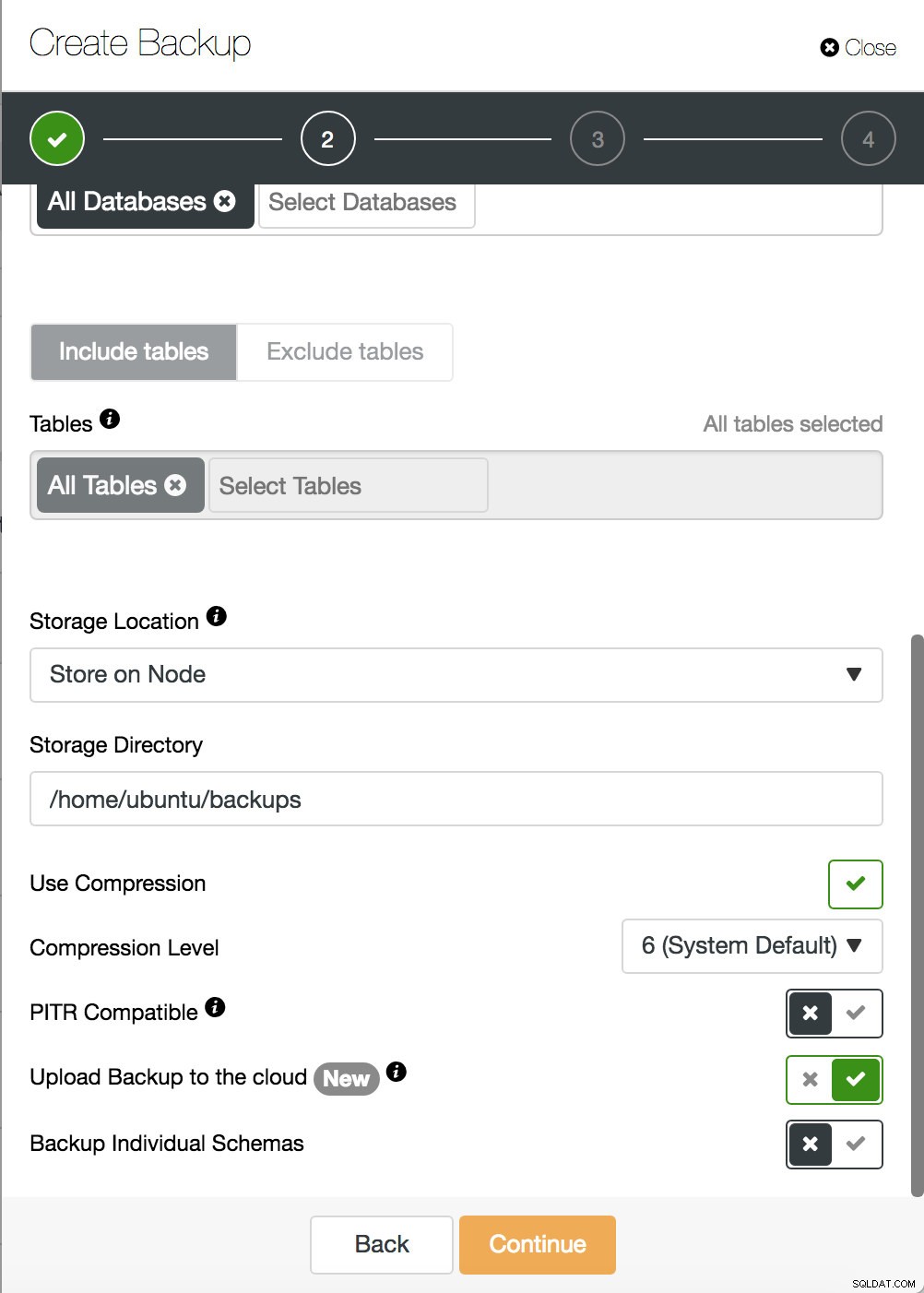
ClusterControl:хибридно архивиране в облак Когато всичко е настроено, можете да коригирате своя график за архивиране и да активирате опцията за архивиране в облак. За да намалите мрежовия трафик, не забравяйте да активирате компресирането на данни. Това прави резервните копия по-малки и свежда до минимум времето, необходимо за качване. Друга добра практика е криптирането на архива. ClusterControl създава ключ автоматично и го използва, ако решите да го възстановите. Разширените политики за архивиране трябва да имат различно време за запазване на архивите, съхранявани на сървъри в един и същ център за данни, и резервните копия, съхранявани на друго физическо място. Трябва да зададете по-дълъг период на съхранение за базирани в облак архиви и по-кратък период за архивиране, съхранявано в близост до производствената среда, тъй като вероятността за възстановяване намалява с продължителността на живота на архивирането.
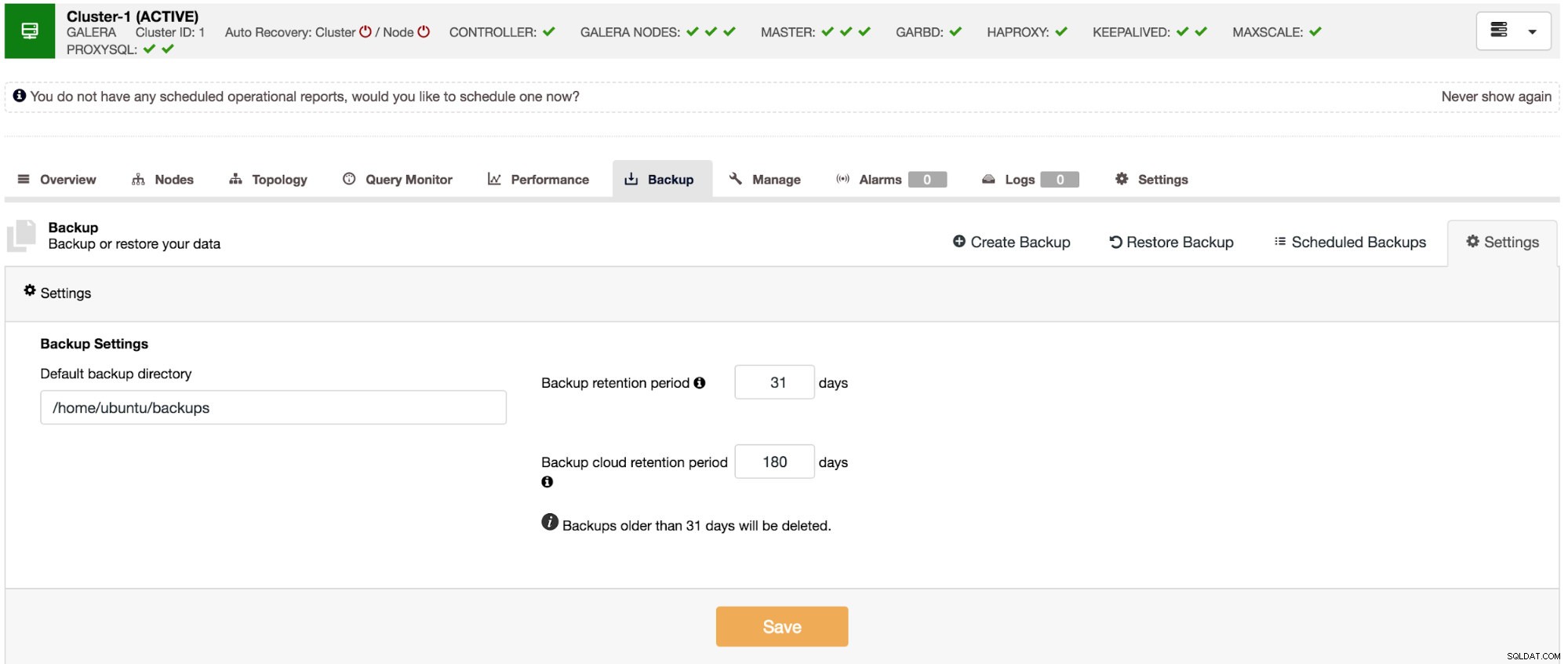 ClusterControl:правила за запазване на резервни копия
ClusterControl:правила за запазване на резервни копия Разширете своя клъстер с асинхронна репликация
Galera с асинхронна репликация може да бъде отлично решение за изграждане на активен DR възел в отдалечен център за данни. Има няколко добри причини да прикачите асинхронен подчинен към клъстер Galera. Продължителните заявки от тип OLAP на възел на Galera може да забавят цял клъстер. С опцията за отложено прилагане, отложената репликация може да ви спаси от човешки грешки, така че всички тези златни влизания няма да бъдат незабавно приложени към вашия резервен възел.
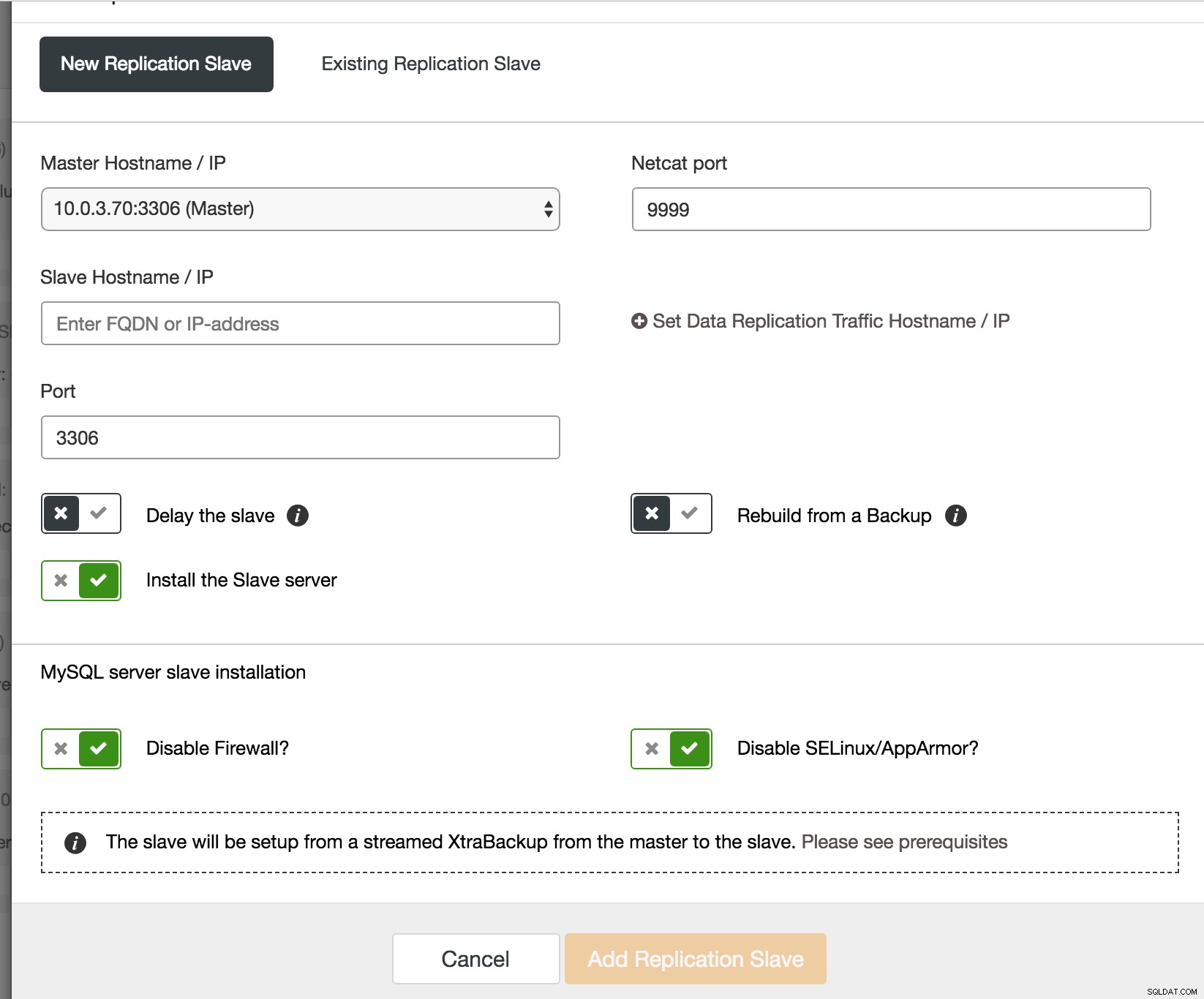 ClusterControl:забавена репликация
ClusterControl:забавена репликация В ClusterControl разширяването на група възли на Galera с асинхронна репликация се извършва в съветника на една страница. Трябва да предоставите необходимата информация за вашия бъдещ или съществуващ подчинен сървър. Подчинението ще бъде настроено от съществуващо резервно копие или прясно поточно поточно XtraBackup от главния към подчинения.
Балансиране на натоварването в мулти-центр за данни
Балансьорите на натоварване са решаващ компонент в MySQL и висока наличност на базата данни MariaDB. Не е достатъчно да имате клъстер, обхващащ множество центрове за данни. Все още имате нужда от вашите услуги, за да получите достъп до тях. Неизправност на балансира на натоварването, който е наличен в един център за данни, ще направи цялата ви среда недостъпна.
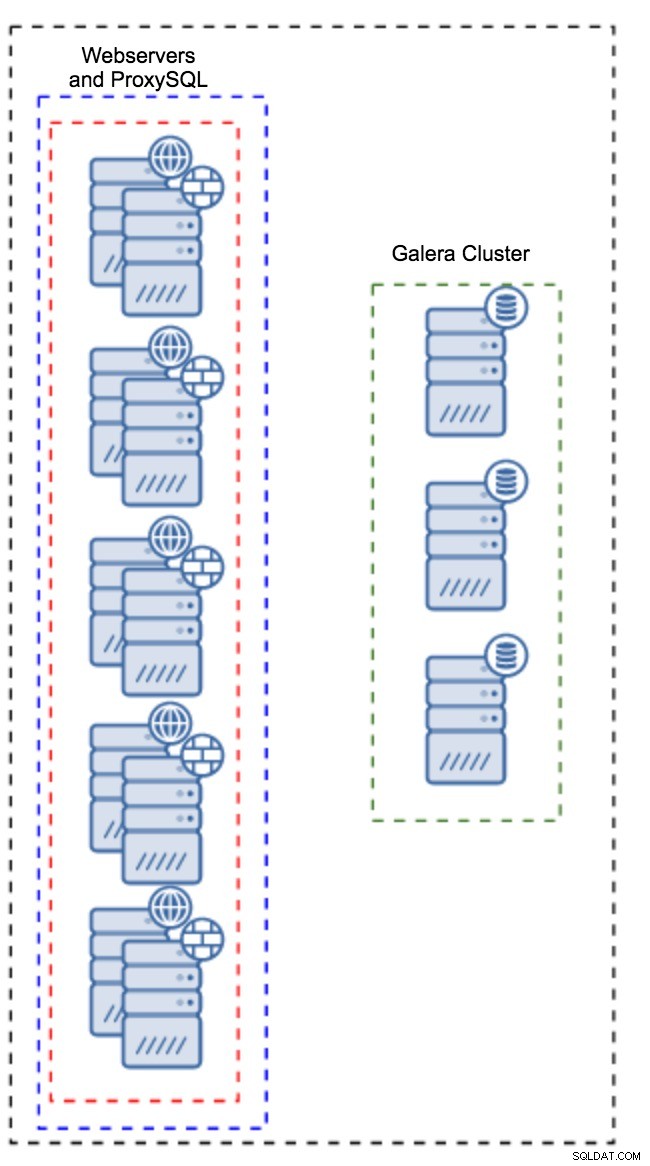 Уеб прокси сървъри в клъстерна среда
Уеб прокси сървъри в клъстерна среда Един от популярните методи за скриване на сложността на слоя на базата данни от приложение е използването на прокси. Прокситата действат като входна точка към базите данни, те проследяват състоянието на възлите на базата данни и винаги трябва да насочват трафика само към наличните възли. ClusterControl улеснява внедряването и конфигурирането на няколко различни технологии за балансиране на натоварването за MySQL и MariaDB, включително ProxySQL, HAProxy, с графичен интерфейс „насочи и щракни“.
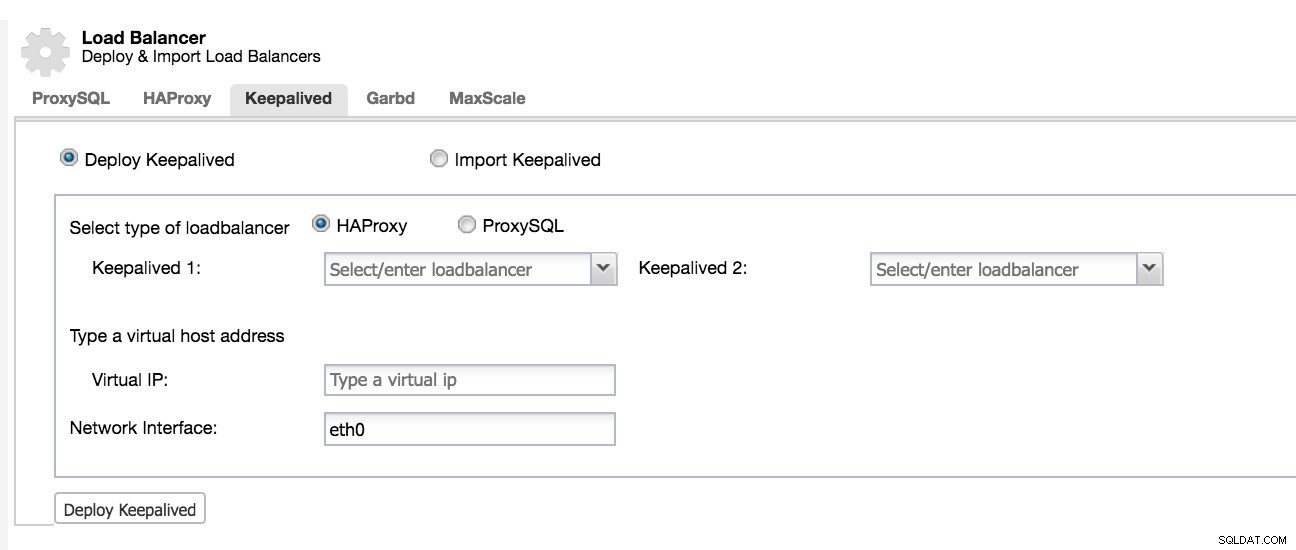 ClusterControl:балансиране на натоварването HA
ClusterControl:балансиране на натоварването HA Той също така позволява да направи този компонент излишен чрез добавяне на keepalived върху него. За да предотвратите балансирането на натоварването ви да бъдат една точка на отказ, човек ще настрои две идентични (един активен и един в различен DC като режим на готовност) HAProxy, ProxySQL или MariaDB Maxscale екземпляри и ще използва Keepalived за стартиране на протокола за резервиране на виртуален рутер (VRRP) между тях. VRRP предоставя виртуален IP адрес на активния балансьор на натоварване и прехвърля виртуалния IP към резервния HAProxy в случай на повреда. Това е безпроблемно, защото двата прокси екземпляра не се нуждаят от споделено състояние.
Разбира се, има много неща, които трябва да имате предвид, за да направите вашите бази данни имунизирани срещу повреди в центъра за данни.
Правилното планиране и автоматизация ще го накарат да работи! Приятно групиране!