Някой случайно е изтрил част от базата данни. Някой е забравил да включи клауза WHERE в заявка DELETE или е изпуснал грешната таблица. Такива неща може и ще се случват, това е неизбежно и човешко. Но въздействието може да бъде катастрофално. Какво можете да направите, за да се предпазите от подобни ситуации и как можете да възстановите данните си? В тази публикация в блога ще разгледаме някои от най-типичните случаи на загуба на данни и как можете да се подготвите, за да можете да се възстановите от тях.
Подготовки
Има неща, които трябва да направите, за да осигурите гладко възстановяване. Да преминем през тях. Моля, имайте предвид, че ситуацията не е „изберете едно“ – в идеалния случай ще приложите всички мерки, които ще обсъдим по-долу.
Резервно копие
Трябва да имате резервно копие, няма как да се отървете от него. Трябва да проверите вашите архивни файлове - освен ако не тествате архивите си, не можете да сте сигурни дали са добри и дали някога ще можете да ги възстановите. За възстановяване след бедствие трябва да съхранявате копие на резервното си копие някъде извън вашия център за данни - само в случай, че целият център за данни стане недостъпен. За да ускорите възстановяването, е много полезно да съхранявате копие на архива и на възлите на базата данни. Ако вашият набор от данни е голям, копирането му през мрежата от резервен сървър към възела на базата данни, който искате да възстановите, може да отнеме значително време. Поддържането на последното архивно копие локално може значително да подобри времето за възстановяване.
Логическо архивиране
Първото ви резервно копие най-вероятно ще бъде физическо архивиране. За MySQL или MariaDB това ще бъде или нещо като xtrabackup, или някакъв вид моментна снимка на файловата система. Такива архиви са чудесни за възстановяване на цял набор от данни или за осигуряване на нови възли. Въпреки това, в случай на изтриване на подмножество от данни, те страдат от значителни режийни разходи. Първо, не можете да възстановите всички данни или ще презапишете всички промени, настъпили след създаването на архива. Това, което търсите, е възможността да възстановите само подмножество от данни, само редовете, които са били случайно премахнати. За да направите това с физическо архивиране, ще трябва да го възстановите на отделен хост, да намерите премахнатите редове, да ги изхвърлите и след това да ги възстановите в производствения клъстер. Копирането и възстановяването на стотици гигабайта данни само за възстановяване на шепа редове е нещо, което определено бихме нарекли значителни разходи. За да го избегнете, можете да използвате логически архиви – вместо да съхраняват физически данни, такива архиви съхраняват данни в текстов формат. Това улеснява намирането на точните данни, които са били премахнати, които след това могат да бъдат възстановени директно в производствения клъстер. За да го направите още по-лесно, можете също да разделите такова логично архивиране на части и да архивирате всяка таблица в отделен файл. Ако вашият набор от данни е голям, ще има смисъл да разделите един огромен текстов файл колкото е възможно повече. Това ще направи архивирането непоследователно, но в повечето случаи това не е проблем - ако ще трябва да възстановите целия набор от данни до последователно състояние, ще използвате физическо архивиране, което е много по-бързо в това отношение. Ако трябва да възстановите само подмножество от данни, изискванията за последователност са по-малко строги.
Възстановяване в момента
Архивирането е само начало - ще можете да възстановите данните си до точката, в която е направено архивирането, но най-вероятно данните са били премахнати след това време. Само като възстановите липсващи данни от най-новия архив, може да загубите всички данни, които са били променени след архивирането. За да избегнете това, трябва да внедрите възстановяване по време. За MySQL това основно означава, че ще трябва да използвате двоични регистрационни файлове, за да възпроизведете всички промени, които са се случили между момента на архивирането и загубата на данни. Екранната снимка по-долу показва как ClusterControl може да помогне с това.
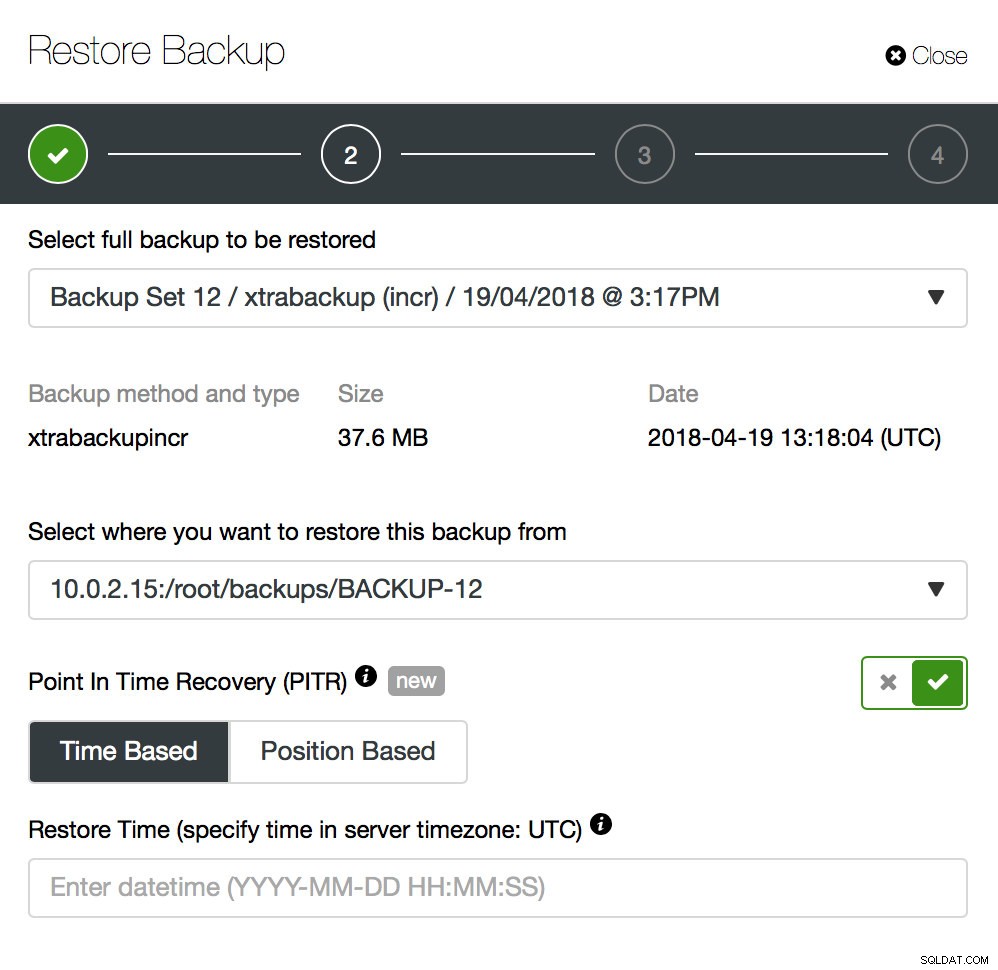
Това, което ще трябва да направите, е да възстановите това архивно копие до момента точно преди загубата на данни. Ще трябва да го възстановите на отделен хост, за да не правите промени в производствения клъстер. След като възстановите резервното копие, можете да влезете в този хост, да намерите липсващите данни, да ги изхвърлите и да ги възстановите в производствения клъстер.
Отложено подчинено устройство
Всички методи, които обсъдихме по-горе, имат една обща болезнена точка - отнема време за възстановяване на данните. Може да отнеме повече време, когато възстановите всички данни и след това се опитате да изхвърлите само интересната част. Може да отнеме по-малко време, ако имате логическо архивиране и можете бързо да разберете данните, които искате да възстановите, но това в никакъв случай не е бърза задача. Все още трябва да намерите няколко реда в голям текстов файл. Колкото по-голям е той, толкова по-сложна става задачата - понякога самият размер на файла забавя всички действия. Един от начините за избягване на тези проблеми е да имате отложен роб. Подчинените обикновено се опитват да бъдат в крак с капитана, но също така е възможно да ги конфигурирате така, че да поддържат дистанция от своя господар. На екранната снимка по-долу можете да видите как да използвате ClusterControl за разгръщане на такъв подчинен:
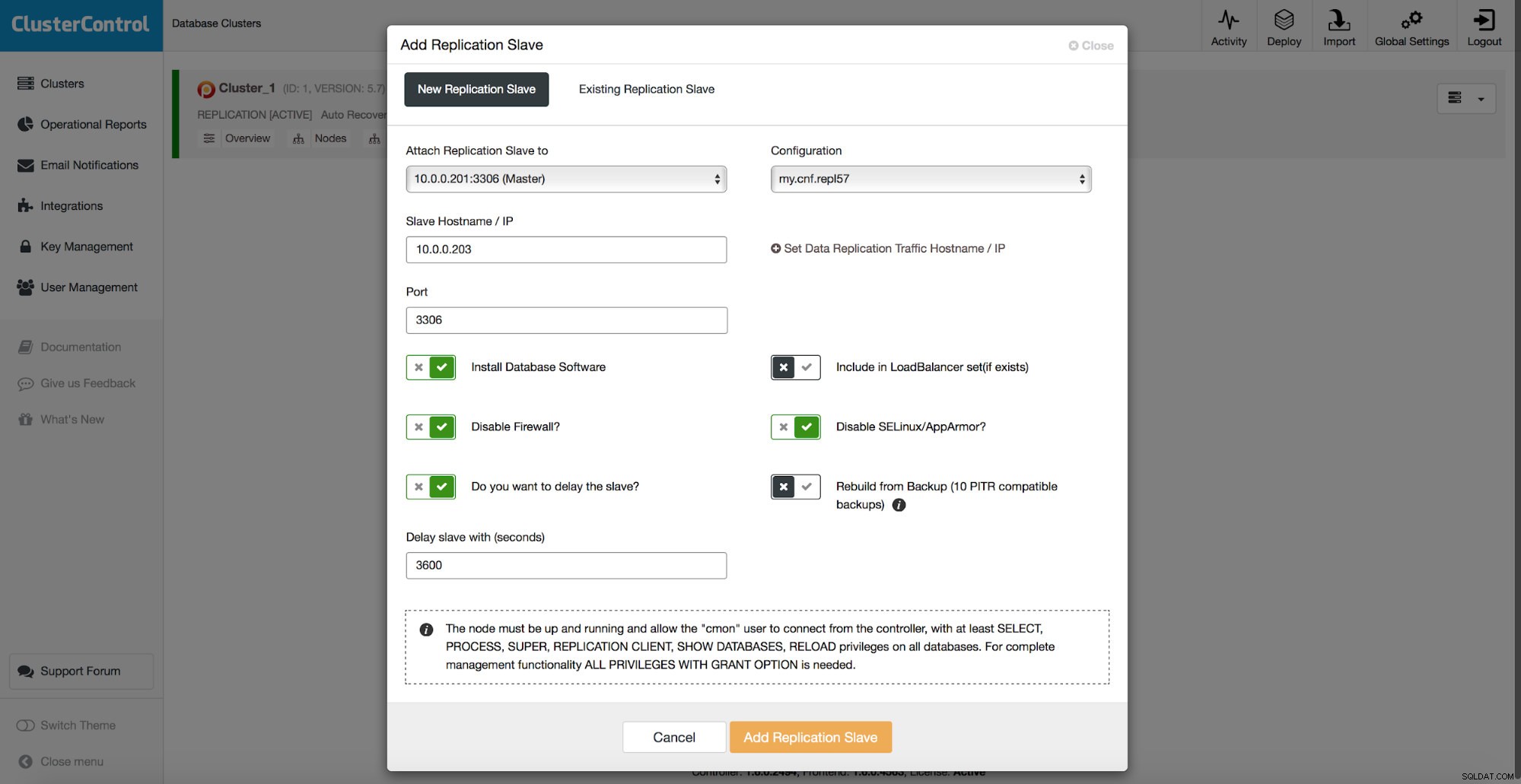
Накратко, тук имаме опция да добавим подчинен за репликация към настройката на базата данни и да го конфигурираме да бъде отложен. На екранната снимка по-горе подчинението ще бъде забавено с 3600 секунди, което е един час. Това ви позволява да използвате този подчинен за възстановяване на премахнатите данни до един час след изтриването на данните. Няма да се налага да възстановявате резервно копие, ще бъде достатъчно да стартирате mysqldump или SELECT ... INTO OUTFILE за липсващите данни и ще получите данните за възстановяване на вашия производствен клъстер.
Възстановяване на данни
В този раздел ще разгледаме няколко примера за случайно изтриване на данни и как можете да се възстановите от тях. Ще преминем през възстановяване от пълна загуба на данни, също така ще покажем как да се възстановим от частична загуба на данни при използване на физически и логически архиви. Най-накрая ще ви покажем как да възстановите случайно изтрити редове, ако имате отложен подчинен в настройката си.
Пълна загуба на данни
Случайно „rm -rf“ или „DROP SCHEMA myonlyschema;“ е изпълнено и в крайна сметка нямате никакви данни. Ако случайно сте премахнали и файлове, различни от директорията с данни на MySQL, може да се наложи да преработите хоста. За да опростим нещата, ще приемем, че е засегнат само MySQL. Нека разгледаме два случая, със забавен подчинен и без такъв.
Без отложено подчинено устройство
В този случай единственото нещо, което можем да направим, е да възстановим последното физическо архивиране. Тъй като всички наши данни са премахнати, не е нужно да се притесняваме за дейността, която се е случила след загубата на данни, защото без данни няма активност. Трябва да се притесняваме за дейността, която се случи след архивирането. Това означава, че трябва да направим възстановяване по време. Разбира се, това ще отнеме повече време, отколкото просто да възстановите данни от архива. Ако бързото извеждане на вашата база данни е по-важно от това да възстановите всички данни, можете също така просто да възстановите резервно копие и да се справите добре с него.
На първо място, ако все още имате достъп до двоични регистрационни файлове на сървъра, който искате да възстановите, можете да ги използвате за PITR. Първо, искаме да преобразуваме съответната част от двоичните регистрационни файлове в текстов файл за по-нататъшно проучване. Знаем, че загубата на данни е станала след 13:00:00. Първо, нека проверим кой binlog файл трябва да проучим:
example@sqldat.com:~# ls -alh /var/lib/mysql/binlog.*
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:32 /var/lib/mysql/binlog.000001
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:33 /var/lib/mysql/binlog.000002
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:35 /var/lib/mysql/binlog.000003
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:38 /var/lib/mysql/binlog.000004
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:39 /var/lib/mysql/binlog.000005
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:41 /var/lib/mysql/binlog.000006
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:43 /var/lib/mysql/binlog.000007
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:45 /var/lib/mysql/binlog.000008
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:47 /var/lib/mysql/binlog.000009
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:49 /var/lib/mysql/binlog.000010
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:51 /var/lib/mysql/binlog.000011
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:53 /var/lib/mysql/binlog.000012
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:55 /var/lib/mysql/binlog.000013
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:57 /var/lib/mysql/binlog.000014
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:59 /var/lib/mysql/binlog.000015
-rw-r----- 1 mysql mysql 306M Apr 23 13:18 /var/lib/mysql/binlog.000016Както се вижда, ние се интересуваме от последния binlog файл.
example@sqldat.com:~# mysqlbinlog --start-datetime='2018-04-23 13:00:00' --verbose /var/lib/mysql/binlog.000016 > sql.outСлед като приключим, нека да разгледаме съдържанието на този файл. Ще търсим „drop schema“ във vim. Ето съответна част от файла:
# at 320358785
#180423 13:18:58 server id 1 end_log_pos 320358850 CRC32 0x0893ac86 GTID last_committed=307804 sequence_number=307805 rbr_only=no
SET @@SESSION.GTID_NEXT= '52d08e9d-46d2-11e8-aa17-080027e8bf1b:443415'/*!*/;
# at 320358850
#180423 13:18:58 server id 1 end_log_pos 320358946 CRC32 0x487ab38e Query thread_id=55 exec_time=1 error_code=0
SET TIMESTAMP=1524489538/*!*/;
/*!\C utf8 *//*!*/;
SET @@session.character_set_client=33,@@session.collation_connection=33,@@session.collation_server=8/*!*/;
drop schema sbtest
/*!*/;Както виждаме, искаме да възстановим до позиция 320358785. Можем да предадем тези данни на потребителския интерфейс на ClusterControl:
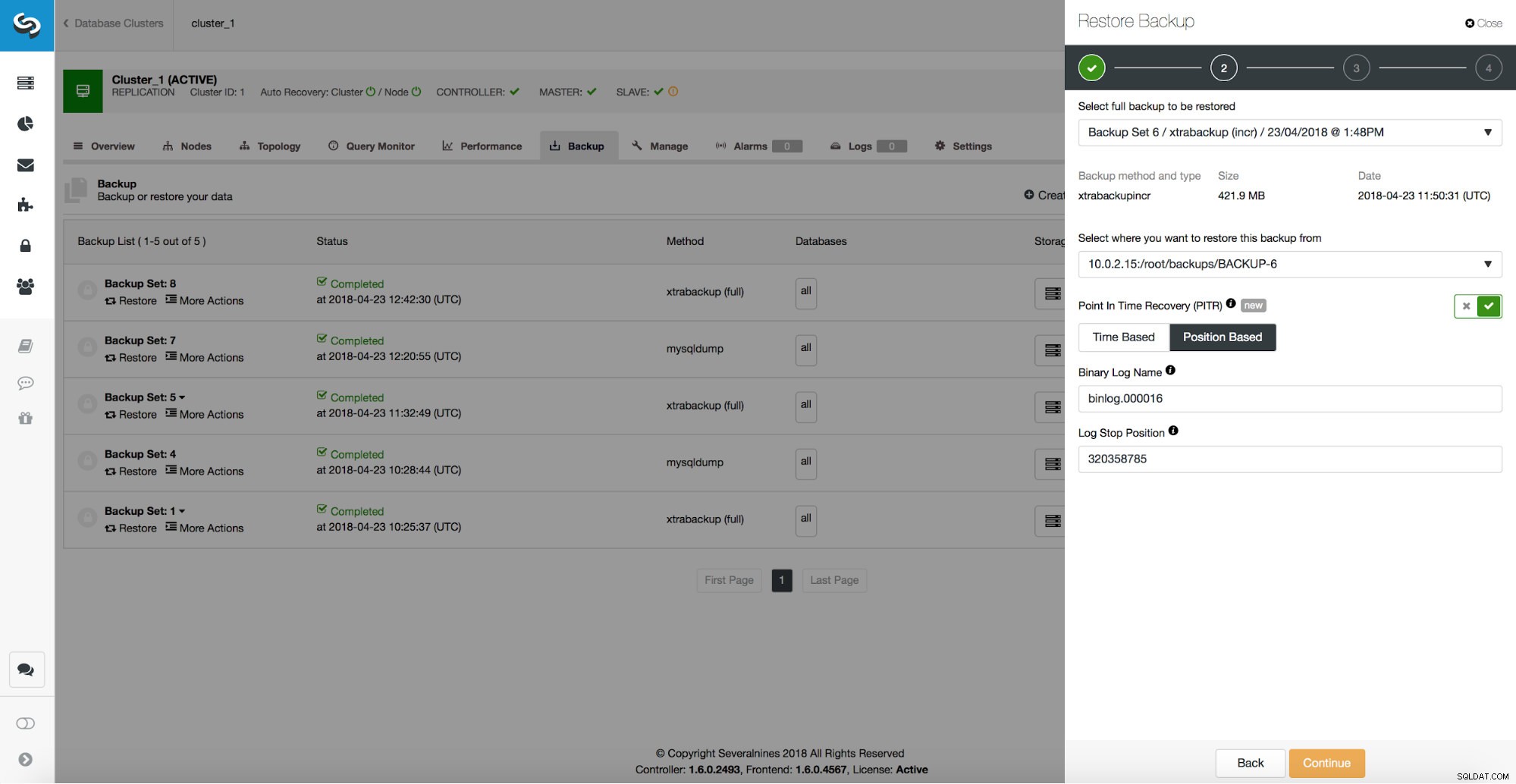
Отложено подчинено устройство
Ако имаме забавено подчинено устройство и този хост е достатъчен, за да обработи целия трафик, можем да го използваме и да го повишим до главен. Първо обаче, трябва да се уверим, че е настигнал стария главен файл до точката на загуба на данни. Ще използваме малко CLI тук, за да го осъществим. Първо, трябва да разберем на коя позиция се е случила загубата на данни. След това ще спрем подчинения и ще го оставим да работи до събитието за загуба на данни. Показахме как да получите правилната позиция в предишния раздел - като разгледахме двоични регистрационни файлове. Можем или да използваме тази позиция (binlog.000016, позиция 320358785) или, ако използваме многонишков подчинен, трябва да използваме GTID на събитието за загуба на данни (52d08e9d-46d2-11e8-aa17-080027e8bf1b:443415) и повторно възпроизвеждане този GTID.
Първо, нека спрем подчинения и деактивираме забавянето:
mysql> STOP SLAVE;
Query OK, 0 rows affected (0.01 sec)
mysql> CHANGE MASTER TO MASTER_DELAY = 0;
Query OK, 0 rows affected (0.02 sec)След това можем да го стартираме до дадена двоична регистрационна позиция.
mysql> START SLAVE UNTIL MASTER_LOG_FILE='binlog.000016', MASTER_LOG_POS=320358785;
Query OK, 0 rows affected (0.01 sec)Ако искаме да използваме GTID, командата ще изглежда различно:
mysql> START SLAVE UNTIL SQL_BEFORE_GTIDS = ‘52d08e9d-46d2-11e8-aa17-080027e8bf1b:443415’;
Query OK, 0 rows affected (0.01 sec)След като репликацията спре (което означава, че всички събития, които поискахме, са били изпълнени), трябва да проверим дали хостът съдържа липсващите данни. Ако е така, можете да го повишите до главен и след това да изградите отново други хостове, като използвате нов главен източник като източник на данни.
Това не винаги е най-добрият вариант. Всичко зависи от това колко закъснение е вашето подчинено устройство - ако се забави с няколко часа, може да няма смисъл да чакате да навакса изоставането, особено ако трафикът на запис е натоварен във вашата среда. В такъв случай най-вероятно е по-бързо да се изградят отново хостове с помощта на физическо архивиране. От друга страна, ако имате доста малък обем трафик, това може да бъде добър начин действително бързо да отстраните проблема, да популяризирате нов главен и да продължите с обслужването на трафика, докато останалите възли се възстановяват на заден план .
Частична загуба на данни – физическо архивиране
В случай на частична загуба на данни, физическите архиви могат да бъдат неефективни, но тъй като те са най-често срещаният тип архивиране, е много важно да знаете как да ги използвате за частично възстановяване. Първата стъпка винаги ще бъде да възстановите резервно копие до определен момент преди събитието за загуба на данни. Също така е много важно да го възстановите на отделен хост. ClusterControl използва xtrabackup за физически архиви, така че ще покажем как да го използваме. Да предположим, че сме изпълнили следната неправилна заявка:
DELETE FROM sbtest1 WHERE id < 23146;Искахме да изтрием само един ред (‘=’ в клауза WHERE), вместо това изтрихме куп от тях (<в клауза WHERE). Нека да разгледаме двоичните регистрационни файлове, за да разберем в коя позиция се е случил проблемът. Ще използваме тази позиция, за да възстановим архива.
mysqlbinlog --verbose /var/lib/mysql/binlog.000003 > bin.outСега нека разгледаме изходния файл и да видим какво можем да намерим там. Ние използваме репликация, базирана на редове, поради което няма да видим точния SQL, който е бил изпълнен. Вместо това (стига да използваме флага --verbose към mysqlbinlog) ще видим събития като по-долу:
### DELETE FROM `sbtest`.`sbtest1`
### WHERE
### @1=999296
### @2=1009782
### @3='96260841950-70557543083-97211136584-70982238821-52320653831-03705501677-77169427072-31113899105-45148058587-70555151875'
### @4='84527471555-75554439500-82168020167-12926542460-82869925404'Както може да се види, MySQL идентифицира редове за изтриване, използвайки много точно условие WHERE. Мистериозни знаци в разбираемия от човека коментар „@1“, „@2“ означават „първа колона“, „втора колона“. Знаем, че първата колона е „id“, което е нещо, което ни интересува. Трябва да намерим голямо събитие DELETE в таблица „sbtest1“. Коментарите, които ще последват, трябва да споменават идентификатор от 1, след това идентификатор на „2“, след това „3“ и така нататък – всичко до идентификатор на „23145“. Всичко трябва да се изпълнява в една транзакция (единично събитие в двоичен дневник). След като анализирахме изхода с помощта на „по-малко“, открихме:
### DELETE FROM `sbtest`.`sbtest1`
### WHERE
### @1=1
### @2=1006036
### @3='123'
### @4='43683718329-48150560094-43449649167-51455516141-06448225399'
### DELETE FROM `sbtest`.`sbtest1`
### WHERE
### @1=2
### @2=1008980
### @3='123'
### @4='05603373460-16140454933-50476449060-04937808333-32421752305'Събитието, към което са прикачени тези коментари, започна на:
#180427 8:09:21 server id 1 end_log_pos 29600687 CRC32 0x8cfdd6ae Xid = 307686
COMMIT/*!*/;
# at 29600687
#180427 8:09:21 server id 1 end_log_pos 29600752 CRC32 0xb5aa18ba GTID last_committed=42844 sequence_number=42845 rbr_only=yes
/*!50718 SET TRANSACTION ISOLATION LEVEL READ COMMITTED*//*!*/;
SET @@SESSION.GTID_NEXT= '0c695e13-4931-11e8-9f2f-080027e8bf1b:55893'/*!*/;
# at 29600752
#180427 8:09:21 server id 1 end_log_pos 29600826 CRC32 0xc7b71da5 Query thread_id=44 exec_time=0 error_code=0
SET TIMESTAMP=1524816561/*!*/;
/*!\C utf8 *//*!*/;
SET @@session.character_set_client=33,@@session.collation_connection=33,@@session.collation_server=8/*!*/;
BEGIN
/*!*/;
# at 29600826И така, искаме да възстановим архива до предишния комит на позиция 29600687. Нека направим това сега. Ще използваме външен сървър за това. Ще възстановим архива до тази позиция и ще поддържаме сървъра за възстановяване работещ, за да можем по-късно да извлечем липсващите данни.
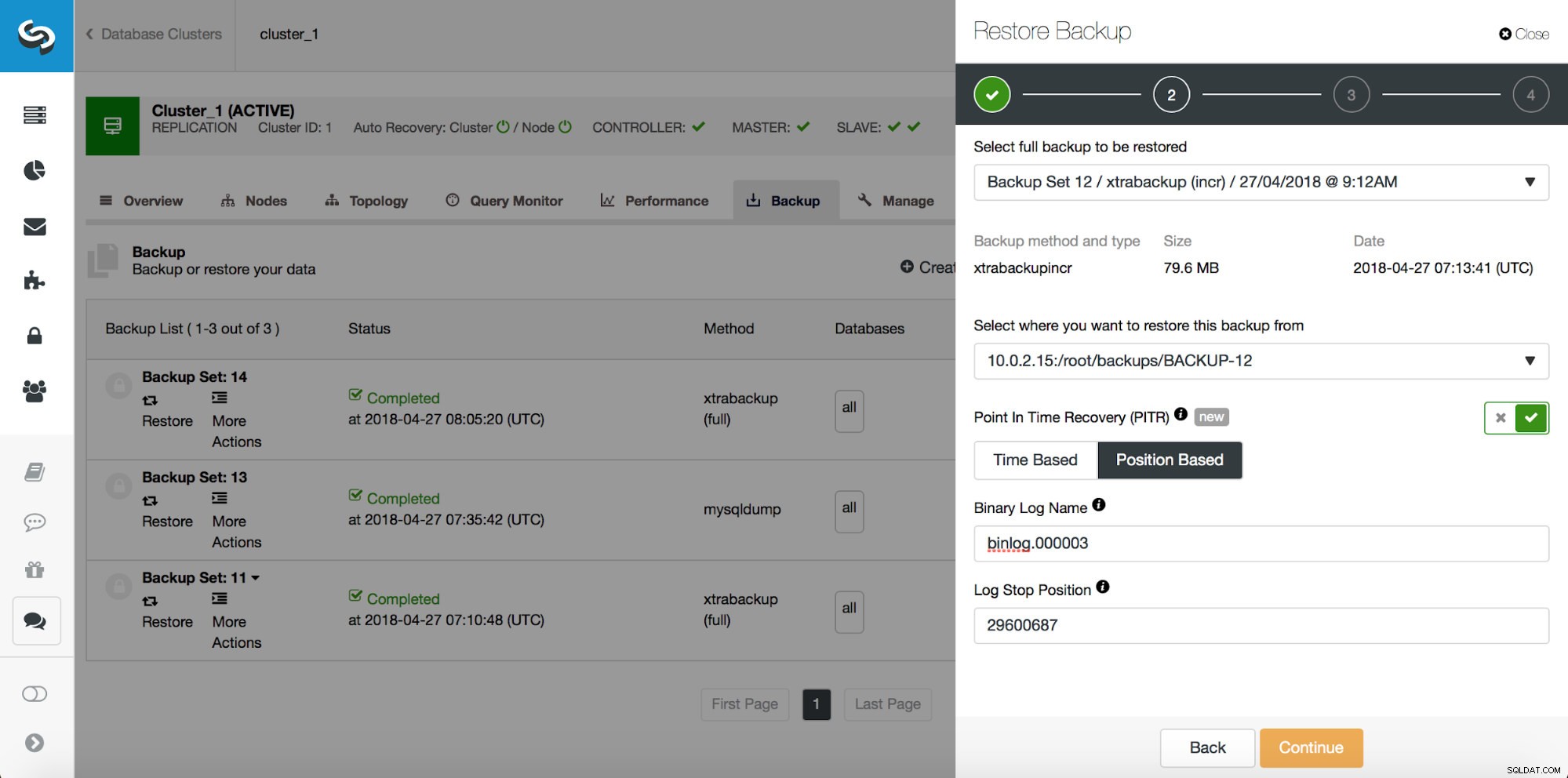
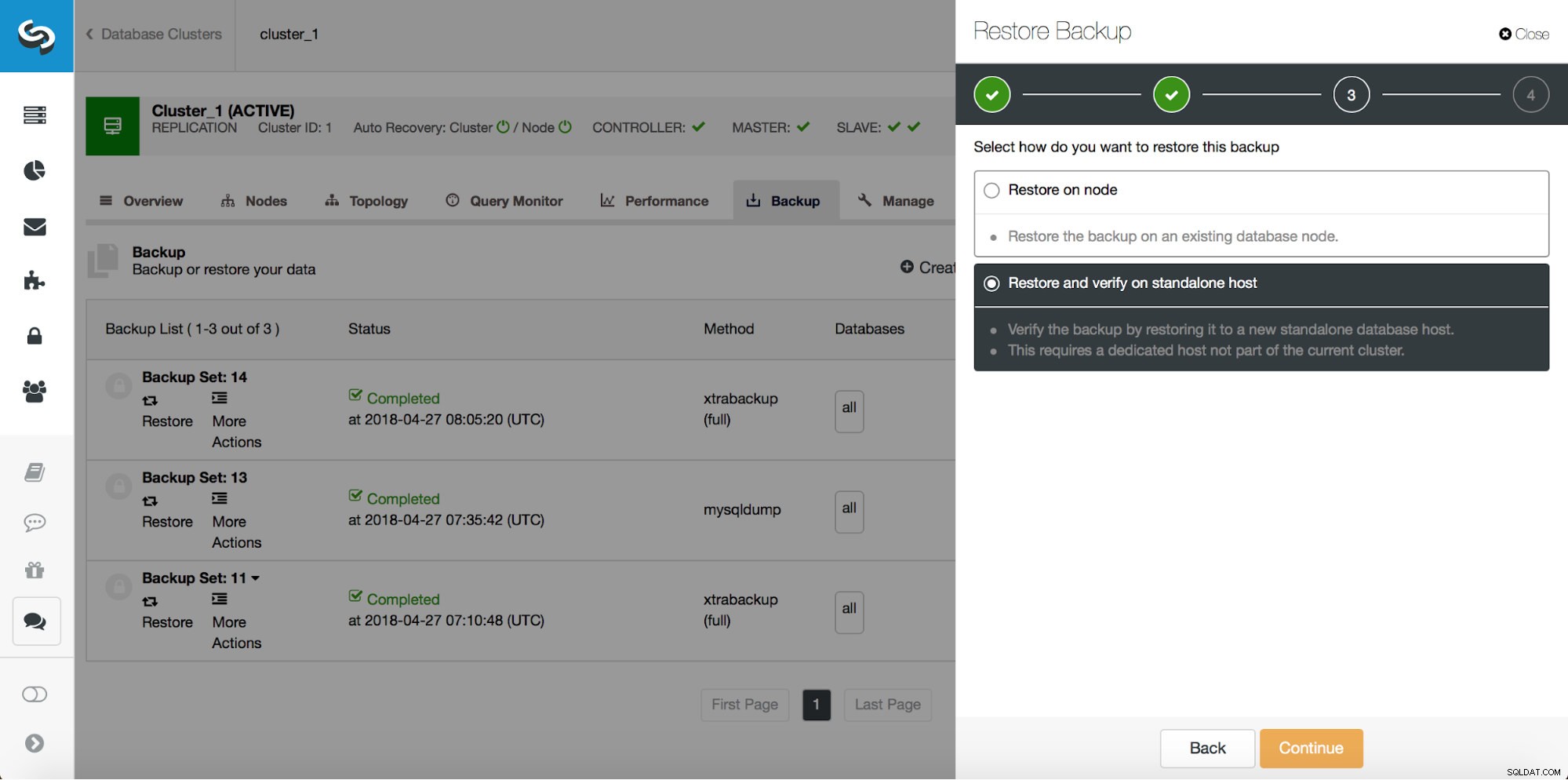
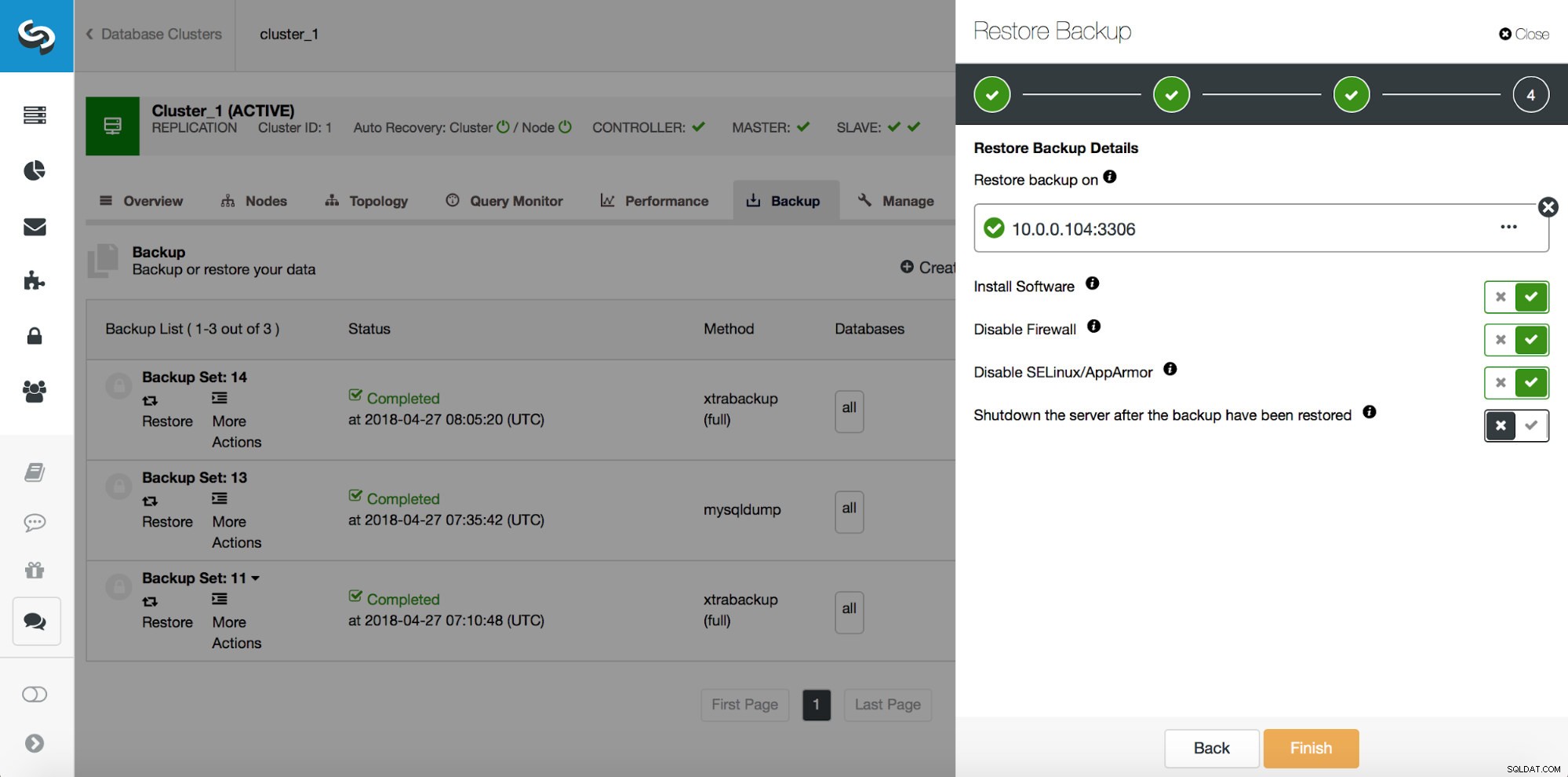
След като възстановяването приключи, нека се уверим, че данните ни са възстановени:
mysql> SELECT COUNT(*) FROM sbtest.sbtest1 WHERE id < 23146;
+----------+
| COUNT(*) |
+----------+
| 23145 |
+----------+
1 row in set (0.03 sec)Изглежда добре. Сега можем да извлечем тези данни във файл, който ще заредим обратно в главния.
mysql> SELECT * FROM sbtest.sbtest1 WHERE id < 23146 INTO OUTFILE 'missing.sql';
ERROR 1290 (HY000): The MySQL server is running with the --secure-file-priv option so it cannot execute this statementНещо не е наред – това е, защото сървърът е конфигуриран да може да записва файлове само на определено място – всичко е свързано със сигурността, ние не искаме да позволяваме на потребителите да запазват съдържание където пожелаят. Нека проверим къде можем да запазим нашия файл:
mysql> SHOW VARIABLES LIKE "secure_file_priv";
+------------------+-----------------------+
| Variable_name | Value |
+------------------+-----------------------+
| secure_file_priv | /var/lib/mysql-files/ |
+------------------+-----------------------+
1 row in set (0.13 sec)Добре, нека опитаме още веднъж:
mysql> SELECT * FROM sbtest.sbtest1 WHERE id < 23146 INTO OUTFILE '/var/lib/mysql-files/missing.sql';
Query OK, 23145 rows affected (0.05 sec)Сега изглежда много по-добре. Нека копираме данните в главния:
example@sqldat.com:~# scp /var/lib/mysql-files/missing.sql 10.0.0.101:/var/lib/mysql-files/
missing.sql 100% 1744KB 1.7MB/s 00:00Сега е време да заредите липсващите редове на главния и да тествате дали е успял:
mysql> LOAD DATA INFILE '/var/lib/mysql-files/missing.sql' INTO TABLE sbtest.sbtest1;
Query OK, 23145 rows affected (2.22 sec)
Records: 23145 Deleted: 0 Skipped: 0 Warnings: 0
mysql> SELECT COUNT(*) FROM sbtest.sbtest1 WHERE id < 23146;
+----------+
| COUNT(*) |
+----------+
| 23145 |
+----------+
1 row in set (0.00 sec)Това е всичко, възстановихме липсващите ни данни.
Частична загуба на данни – логическо архивиране
В предишния раздел възстановихме загубени данни, използвайки физическо архивиране и външен сървър. Ами ако имахме създадено логично архивиране? Нека да разгледаме. Първо, нека проверим дали имаме логическо резервно копие:
example@sqldat.com:~# ls -alh /root/backups/BACKUP-13/
total 5.8G
drwx------ 2 root root 4.0K Apr 27 07:35 .
drwxr-x--- 5 root root 4.0K Apr 27 07:14 ..
-rw-r--r-- 1 root root 2.4K Apr 27 07:35 cmon_backup.metadata
-rw------- 1 root root 5.8G Apr 27 07:35 mysqldump_2018-04-27_071434_complete.sql.gzДа, там е. Сега е време да го декомпресирате.
example@sqldat.com:~# mkdir /root/restore
example@sqldat.com:~# zcat /root/backups/BACKUP-13/mysqldump_2018-04-27_071434_complete.sql.gz > /root/restore/backup.sqlКогато го погледнете, ще видите, че данните се съхраняват във формат INSERT с много стойности. Например:
INSERT INTO `sbtest1` VALUES (1,1006036,'18034632456-32298647298-82351096178-60420120042-90070228681-93395382793-96740777141-18710455882-88896678134-41810932745','43683718329-48150560094-43449649167-51455516141-06448225399'),(2,1008980,'69708345057-48265944193-91002879830-11554672482-35576538285-03657113365-90301319612-18462263634-56608104414-27254248188','05603373460-16140454933-50476449060-04937808333-32421752305')Всичко, което трябва да направим сега, е да определим къде се намира нашата таблица и след това къде се съхраняват редовете, които ни интересуват. Първо, знаейки моделите на mysqldump (изпускане на таблица, създаване на нова, деактивиране на индекси, вмъкване на данни) нека разберем кой ред съдържа израз CREATE TABLE за таблицата „sbtest1“:
example@sqldat.com:~/restore# grep -n "CREATE TABLE \`sbtest1\`" backup.sql > out
example@sqldat.com:~/restore# cat out
971:CREATE TABLE `sbtest1` (Сега, използвайки метод на проба и грешка, трябва да разберем къде да търсим нашите редове. Ще ви покажем последната команда, която измислихме. Целият трик е да опитате да отпечатате различен диапазон от редове с помощта на sed и след това да проверите дали последният ред съдържа редове, близки до, но по-късно от това, което търсим. В командата по-долу търсим редове между 971 (CREATE TABLE) и 993. Също така молим sed да излезе, след като достигне ред 994, тъй като останалата част от файла не представлява интерес за нас:
example@sqldat.com:~/restore# sed -n '971,993p; 994q' backup.sql > 1.sql
example@sqldat.com:~/restore# tail -n 1 1.sql | lessРезултатът изглежда по-долу:
INSERT INTO `sbtest1` VALUES (31351,1007187,'23938390896-69688180281-37975364313-05234865797-89299459691-74476188805-03642252162-40036598389-45190639324-97494758464','60596247401-06173974673-08009930825-94560626453-54686757363'),Това означава, че нашият диапазон на редове (до ред с идентификатор 23145) е близо. След това всичко е за ръчно почистване на файла. Искаме да започне с първия ред, който трябва да възстановим:
INSERT INTO `sbtest1` VALUES (1,1006036,'18034632456-32298647298-82351096178-60420120042-90070228681-93395382793-96740777141-18710455882-88896678134-41810932745','43683718329-48150560094-43449649167-51455516141-06448225399')И накрая с последния ред за възстановяване:
(23145,1001595,'37250617862-83193638873-99290491872-89366212365-12327992016-32030298805-08821519929-92162259650-88126148247-75122945670','60801103752-29862888956-47063830789-71811451101-27773551230');Трябваше да отрежем някои от ненужните данни (това е многоредово вмъкване), но след всичко това имаме файл, който можем да заредим обратно в главния.
example@sqldat.com:~/restore# cat 1.sql | mysql -usbtest -psbtest -h10.0.0.101 sbtest
mysql: [Warning] Using a password on the command line interface can be insecure.И накрая, последна проверка:
mysql> SELECT COUNT(*) FROM sbtest.sbtest1 WHERE id < 23146;
+----------+
| COUNT(*) |
+----------+
| 23145 |
+----------+
1 row in set (0.00 sec)Всичко е наред, данните са възстановени.
Частична загуба на данни, отложено подчинено устройство
В този случай няма да преминем през целия процес. Вече описахме как да идентифицираме позицията на събитие за загуба на данни в двоичните регистрационни файлове. Ние също така описахме как да спрем забавено подчинено устройство и да започнем репликацията отново, до точка преди събитието за загуба на данни. Обяснихме също как да използвате SELECT INTO OUTFILE и LOAD DATA INFILE, за да експортирате данни от външен сървър и да ги заредите на главния. Това е всичко, от което се нуждаете. Докато данните все още са на забавения подчинен, трябва да го спрете. След това трябва да намерите позицията преди събитието за загуба на данни, да стартирате подчинения до тази точка и след като това е направено, да използвате отложеното подчинено устройство, за да извлечете данни, които са били изтрити, да копирате файла в master и да го заредите, за да възстановите данните .
Заключение
Възстановяването на загубени данни не е забавно, но ако следвате стъпките, през които преминахме в този блог, ще имате добър шанс да възстановите загубеното.