Може би сте чували за термина „раздвоен мозък“. Какво е? Как се отразява на вашите клъстери? В тази публикация в блога ще обсъдим какво точно представлява, каква опасност може да представлява за вашата база данни, как можем да го предотвратим и ако всичко се обърка, как да се възстановим от него.
Отдавна са отминали дните на единичните екземпляри, в днешно време почти всички бази данни работят в групи за репликация или клъстери. Това е чудесно за висока наличност и мащабируемост, но разпределената база данни въвежда нови опасности и ограничения. Един случай, който може да бъде смъртоносен, е разделяне на мрежата. Представете си клъстер от множество възли, който поради проблеми с мрежата е разделен на две части. По очевидни причини (последователност на данните) и двете части не трябва да обработват трафик едновременно, тъй като са изолирани една от друга и данните не могат да се прехвърлят между тях. Също така е погрешно от гледна точка на приложението - дори ако в крайна сметка ще има начин да се синхронизират данните (въпреки че съгласуването на 2 набора от данни не е тривиално). За известно време част от приложението няма да е наясно с промените, направени от други хостове на приложения, които имат достъп до другата част от клъстера на базата данни. Това може да доведе до сериозни проблеми.
Състоянието, при което клъстерът е разделен на две или повече части, които желаят да приемат запис, се нарича „разделен мозък“.
Най-големият проблем с разделения мозък е отклонението на данните, тъй като записите се случват и в двете части на клъстера. Нито един от разновидностите на MySQL не предоставя автоматизирани средства за сливане на набори от данни, които са се разминавали. Няма да намерите такава функция в MySQL репликация, групова репликация или Galera. След като данните се разминават, единствената възможност е или да използваме една от частите на клъстера като източник на истина и да отхвърлим промените, извършени в другата част - освен ако не можем да следваме някакъв ръчен процес, за да обединим данните.
Ето защо ще започнем с това как да предотвратим разцепването на мозъка. Това е много по-лесно, отколкото да се налага да коригирате несъответствие в данните.
Как да предотвратим разделяне на мозъка
Точното решение зависи от типа на базата данни и настройката на средата. Ще разгледаме някои от най-често срещаните случаи за Galera Cluster и MySQL репликация.
Galera Cluster
Galera има вграден „прекъсвач на веригата“ за справяне с разделения мозък:той разчита на механизъм на кворума. Ако мнозинството (50% + 1) от възлите са налични в клъстера, Galera ще работи нормално. Ако няма мнозинство, Galera ще спре да обслужва трафик и ще премине към така нареченото „неосновно“ състояние. Това е почти всичко, от което се нуждаете, за да се справите със ситуация на разделен мозък, докато използвате Galera. Разбира се, има ръчни методи за принуждаване на Galera в „основно“ състояние, дори ако няма мнозинство. Работата е там, че освен ако не направите това, трябва да сте в безопасност.
Начинът, по който се изчислява кворумът, има важни последици - на ниво един център за данни искате да имате нечетен брой възли. Три възела ви дават толеранс за повреда на един възел (2 възела отговарят на изискването за повече от 50% от наличните възли в клъстера). Пет възела ще ви дадат толеранс за повреда на два възела (5 - 2 =3, което е повече от 50% от 5 възела). От друга страна, използването на четири възли няма да подобри толерантността ви към клъстер от три възли. Все пак ще се справи само с повреда на един възел (4 - 1 =3, повече от 50% от 4), докато повредата на два възела ще направи клъстера неизползваем (4 - 2 =2, само 50%, не повече).
Докато разгръщате клъстер Galera в един център за данни, моля, имайте предвид, че в идеалния случай бихте искали да разпределите възли в множество зони на наличност (отделен източник на захранване, мрежа и т.н.) - стига да съществуват във вашия център за данни, т.е. . Една проста настройка може да изглежда така:
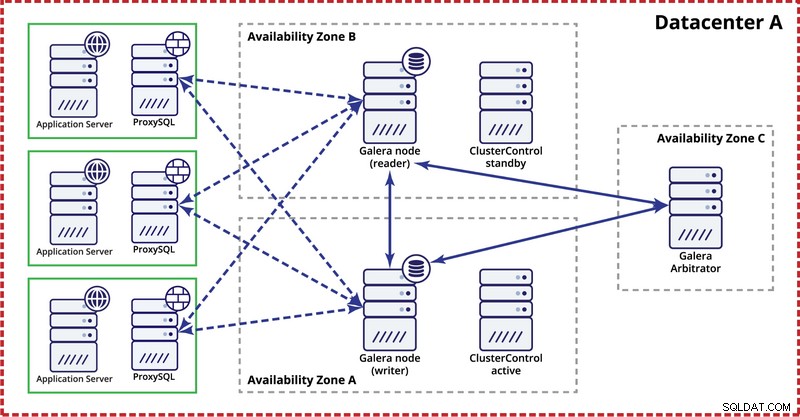
На ниво много центрове за данни тези съображения също са приложими. Ако искате клъстерът Galera да обработва автоматично грешки в центъра за данни, трябва да използвате нечетен брой центрове за данни. За да намалите разходите, можете да използвате арбитър на Galera в един от тях вместо възел на база данни. Арбитър на Galera (garbd) е процес, който участва в изчисляването на кворума, но не съдържа никакви данни. Това прави възможно използването му дори на много малки екземпляри, тъй като не е ресурсоемко – въпреки че мрежовата свързаност трябва да е добра, тъй като „вижда“ целия трафик на репликация. Примерна настройка може да изглежда като на диаграмата по-долу:
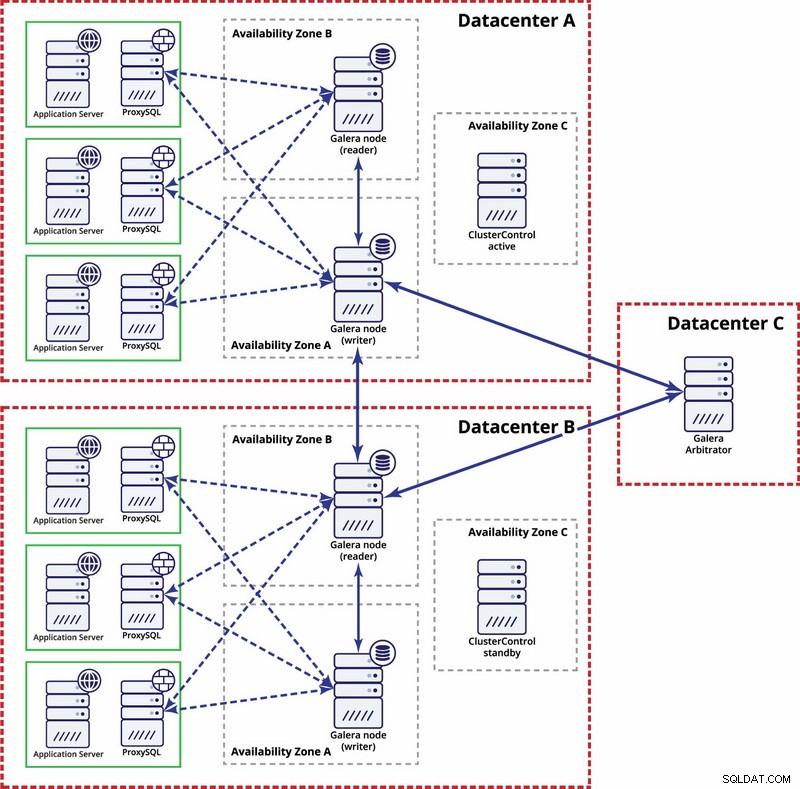
Репликация на MySQL
При репликацията на MySQL най-големият проблем е, че няма вграден механизъм за кворум, както е в клъстера Galera. Следователно са необходими повече стъпки, за да се гарантира, че настройката ви няма да бъде засегната от разделяне на мозъка.
Един от методите е да се избегнат автоматизирани откази между центрове за данни. Можете да конфигурирате своето решение за отказ (то може да бъде чрез ClusterControl, MHA или Orchestrator) за превключване само в рамките на един център за данни. Ако е имало пълно прекъсване на центъра за данни, администраторът трябва да реши как да премине при отказ и как да гарантира, че сървърите в неуспешния център за данни няма да бъдат използвани.
Има опции за по-автоматизиране. Можете да използвате Consul, за да съхранявате данни за възлите в настройката за репликация и кой от тях е главният. Тогава ще зависи от администратора (или чрез някакъв скрипт) да актуализира този запис и да премести записите във втория център за данни. Можете да се възползвате от настройка на Orchestrator/Raft, където възлите на Orchestrator могат да бъдат разпределени в множество центрове за данни и да откриват разделен мозък. Въз основа на това можете да предприемете различни действия като, както споменахме по-рано, актуализиране на записи в нашия консул или etcd. Въпросът е, че това е много по-сложна среда за настройка и автоматизация от клъстера Galera. По-долу можете да намерите пример за настройка на множество центрове за данни за MySQL репликация.
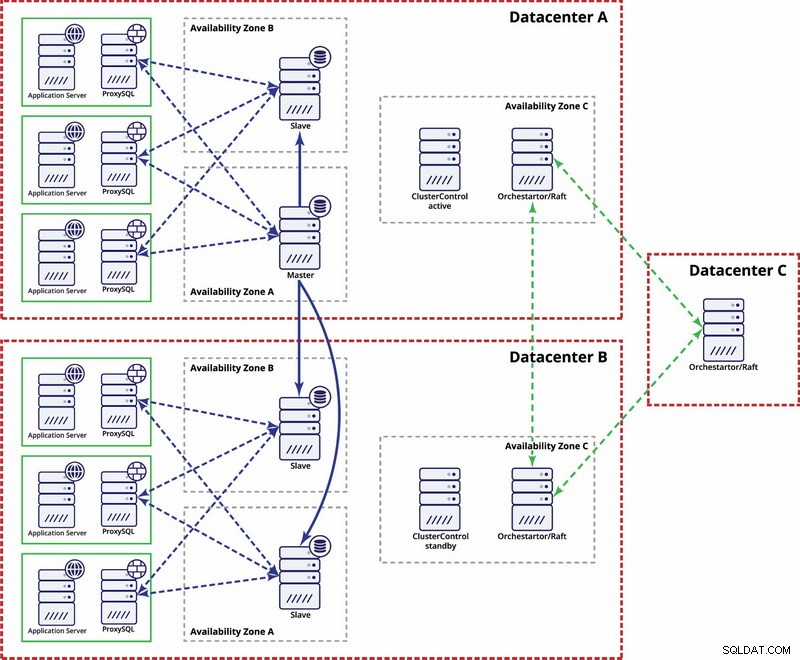
Моля, имайте предвид, че все още трябва да създадете скриптове, за да работи, т.е. да наблюдавате възлите на Orchestrator за разделен мозък и да предприемете необходимите действия за внедряване на STONITH и да гарантирате, че главният в център за данни A няма да се използва, след като мрежата се сближи и свързаността ще бъде бъде възстановен.
Случи се разделен мозък – какво да правя след това?
Случи се най-лошият сценарий и имаме дрейф на данните. Ще се опитаме да ви дадем някои съвети какво може да се направи тук. За съжаление, точните стъпки ще зависят най-вече от дизайна на вашата схема, така че няма да е възможно да напишете точно ръководство с инструкции.
Това, което трябва да имате предвид, е, че крайната цел ще бъде да копирате данни от един главен файл на другия и да пресъздадете всички връзки между таблиците.
На първо място, трябва да определите кой възел ще продължи да обслужва данни като главен. Това е набор от данни, към който ще обедините данни, съхранявани в другия „главен” екземпляр. След като това е направено, трябва да идентифицирате данни от стария главен файл, който липсва на текущия главен файл. Това ще бъде ръчна работа. Ако имате времеви марки във вашите таблици, можете да ги използвате, за да определите липсващите данни. В крайна сметка двоичните регистрационни файлове ще съдържат всички модификации на данните, за да можете да разчитате на тях. Може също да се наложи да разчитате на познанията си за структурата на данните и връзките между таблиците. Ако вашите данни са нормализирани, един запис в една таблица може да бъде свързан със записи в други таблици. Например, вашето приложение може да вмъкне данни в таблицата „user“, която е свързана с таблицата „address“ с помощта на user_id. Ще трябва да намерите всички свързани редове и да ги извлечете.
Следващата стъпка ще бъде зареждането на тези данни в новия главен файл. Тук идва трудната част - ако сте подготвили настройките си предварително, това може да е просто въпрос на стартиране на няколко вмъквания. Ако не, това може да е доста сложно. Всичко е за първичен ключ и уникални индексни стойности. Ако вашите стойности на първичния ключ се генерират като уникални на всеки сървър с помощта на някакъв UUID генератор или чрез използване на настройките за auto_increment_increment и auto_increment_offset в MySQL, можете да сте сигурни, че данните от стария главен ключ, който трябва да вмъкнете, няма да предизвикат първичен ключ или уникален ключови конфликти с данни на новия главен код. В противен случай може да се наложи ръчно да промените данните от стария главен файл, за да сте сигурни, че могат да бъдат вмъкнати правилно. Звучи сложно, така че нека да разгледаме пример.
Нека си представим, че вмъкваме редове с помощта на auto_increment на възел А, който е главен. За по-голяма простота ще се съсредоточим само върху един ред. Има колони „id“ и „value“.
Ако го вмъкнем без конкретна настройка, ще видим записи като по-долу:
1000, ‘some value0’
1001, ‘some value1’
1002, ‘some value2’
1003, ‘some value3’Те ще се репликират на роба (B). Ако се случи разделянето на мозъка и записите ще бъдат изпълнени както на стария, така и на новия главен, ще се окажем със следната ситуация:
А
1000, ‘some value0’
1001, ‘some value1’
1002, ‘some value2’
1003, ‘some value3’
1004, ‘some value4’
1005, ‘some value5’
1006, ‘some value7’Б
1000, ‘some value0’
1001, ‘some value1’
1002, ‘some value2’
1003, ‘some value3’
1004, ‘some value6’
1005, ‘some value8’
1006, ‘some value9’Както можете да видите, няма начин просто да изхвърлите записи с идентификатор 1004, 1005 и 1006 от възел A и да ги съхраните на възел B, защото ще се окажем с дублирани записи на първичен ключ. Това, което трябва да се направи, е да промените стойностите на колоната id в редовете, които ще бъдат вмъкнати, на стойност, по-голяма от максималната стойност на колоната id от таблицата. Това е всичко, което е необходимо за единични редове. За по-сложни връзки, при които са включени множество таблици, може да се наложи да направите промените на няколко местоположения.
От друга страна, ако бяхме предвидили този потенциален проблем и конфигурирахме възлите си да съхраняват нечетни идентификатори на възел A и четни идентификатори на възел B, проблемът щеше да бъде много по-лесен за решаване.
Възел А е конфигуриран с auto_increment_offset =1 и auto_increment_increment =2
Възел B е конфигуриран с auto_increment_offset =2 и auto_increment_increment =2
Ето как биха изглеждали данните на възел А преди разделения мозък:
1001, ‘some value0’
1003, ‘some value1’
1005, ‘some value2’
1007, ‘some value3’Когато се случи разделяне на мозъка, това ще изглежда по-долу.
Възел А:
1001, ‘some value0’
1003, ‘some value1’
1005, ‘some value2’
1007, ‘some value3’
1009, ‘some value4’
1011, ‘some value5’
1013, ‘some value7’Възел B:
1001, ‘some value0’
1003, ‘some value1’
1005, ‘some value2’
1007, ‘some value3’
1008, ‘some value6’
1010, ‘some value8’
1012, ‘some value9’Сега можем лесно да копираме липсващи данни от възел A:
1009, ‘some value4’
1011, ‘some value5’
1013, ‘some value7’И го заредете в възел B, завършвайки със следния набор от данни:
1001, ‘some value0’
1003, ‘some value1’
1005, ‘some value2’
1007, ‘some value3’
1008, ‘some value6’
1009, ‘some value4’
1010, ‘some value8’
1011, ‘some value5’
1012, ‘some value9’
1013, ‘some value7’Разбира се, редовете не са в оригиналния ред, но това трябва да е наред. В най-лошия случай ще трябва да подреждате по колона „стойност“ в заявките и може би да добавите индекс към нея, за да направите сортирането бързо.
Сега си представете стотици или хиляди редове и силно нормализирана структура на таблицата - възстановяването на един ред може да означава, че ще трябва да възстановите няколко от тях в допълнителни таблици. С необходимостта да промените идентификаторите (защото не сте имали защитни настройки) във всички свързани редове и всичко това е ръчна работа, можете да си представите, че това не е най-добрата ситуация. Отнема време за възстановяване и това е процес, податлив на грешки. За щастие, както обсъдихме в началото, има средства за минимизиране на шансовете, че разделеният мозък ще повлияе на вашата система или за намаляване на работата, която трябва да се свърши, за да синхронизирате обратно вашите възли. Уверете се, че ги използвате и бъдете готови.