Тази публикация в блога е третата част от поредицата блогове за индекси в MySQL . Във втората част от поредицата публикации в блога за MySQL индексите разгледахме индексите и механизмите за съхранение и засегнахме някои ОСНОВНИ КЛЮЧОВИ съображения. Обсъждането включваше как да съпоставим префикс на колона, някои съображения за индекс FULLTEXT и как трябва да използвате индекси на B-Tree със заместващи знаци и как да използвате ClusterControl за наблюдение на ефективността на вашите заявки, а впоследствие и индекси.
В тази публикация в блога ще разгледаме някои повече подробности за индексите в MySQL :ще покрием хеш индексите, кардиналността на индекса, селективността на индекса, ще ви разкажем интересни подробности за покриването на индекси, а също така ще преминем през някои стратегии за индексиране. И, разбира се, ще засегнем ClusterControl. Да започнем, нали?
Хеш индекси в MySQL
MySQL DBA и разработчиците, занимаващи се с MySQL, също имат друг трик в ръкава си, що се отнася до MySQL - хеш индексите също са опция. Хеш индексите често се използват в механизма MEMORY на MySQL - както при почти всичко в MySQL, тези видове индекси имат своите предимства и недостатъци. Основният недостатък на тези видове индекси е, че те се използват само за сравнения на равенство, които използват операторите =или <=>, което означава, че не са наистина полезни, ако искате да търсите диапазон от стойности, но основният плюс е че търсенията са много бързи. Още няколко недостатъка включват факта, че разработчиците не могат да използват най-левия префикс на ключа, за да намерят редове (ако искате да направите това, използвайте вместо това индекси на B-Tree), факта, че MySQL не може приблизително да определи колко реда има между две стойности - ако се използват хеш индекси, оптимизаторът също не може да използва хеш индекс за ускоряване на операциите ORDER BY. Имайте предвид, че хеш-индексите не са единственото нещо, което поддържа MEMORY машината - MEMORY двигателите могат да имат и индекси B-Tree.
Кардиналност на индекса в MySQL
Що се отнася до индексите на MySQL, може да чуете и друг термин - този термин се нарича мощност на индекса. С много прости думи, мощността на индекса се отнася до уникалността на стойностите, съхранявани в колона, която използва индекс. За да видите кардиналността на индекса на конкретен индекс, можете просто да отидете в раздела Структура на phpMyAdmin и да наблюдавате информацията там или можете също да изпълните заявка SHOW INDEXES:
mysql> SHOW INDEXES FROM demo_table;
+---------------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+---------------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| demo_table | 1 | demo | 1 | demo | A | 494573 | NULL | NULL | | BTREE | | |
+---------------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
1 row in set (0.00 sec)Изходът на заявката SHOW INDEXES, който може да се види по-горе, както можете да видите, има много полета, едно от които изобразява мощността на индекса:това поле връща приблизителен брой уникални стойности в индекса - колкото по-висока е мощността, толкова по-голям е шансът оптимизаторът на заявки да използва индекса за справки. Като се има предвид това, кардиналността на индекса също има брат - името му е селективност на индекса.
Селективност на индексите в MySQL
Селективността на индекса е броят на отделните стойности по отношение на броя на записите в таблицата. Казано по-просто, селективността на индекса определя колко плътно индексът на базата данни помага на MySQL да стесни търсенето на стойности. Идеалната селективност на индекса е стойността на 1. Селективността на индекса се изчислява, като отделните стойности в таблицата се разделят на общия брой записи, например, ако имате 1 000 000 записа във вашата таблица, но само 100 000 от тях са различни стойности , вашата селективност на индекса ще бъде 0,1. Ако имате 10 000 записа във вашата таблица и 8 500 от тях са различни стойности, селективността на вашия индекс ще бъде 0,85. Това е много по-добре. Разбирате смисъла. Колкото по-висока е селективността на вашия индекс, толкова по-добре.
Покриващи индекси в MySQL
Покриващият индекс е специален вид индекс в InnoDB. Когато се използва покриващ индекс, всички задължителни полета за заявка са включени или „покрити“ от индекса, което означава, че можете също да се възползвате от ползите от четенето само на индекса вместо на данните. Ако нищо друго не помага, покриващ индекс може да бъде вашият билет за подобрена производителност. Някои от предимствата на използването на покриващи индекси включват:
-
Един от основните сценарии, при които покриващ индекс може да бъде от полза, включва обслужване на заявки без допълнителни I/O четения на големи маси.
-
MySQL също има достъп до по-малко данни поради факта, че записите в индекса са по-малки от размера на редовете.
-
Повечето машини за съхранение кешират индексите по-добре от данните.
Създаването на покриващи индекси в таблица е доста просто - просто покрийте полетата, достъпни от клаузите SELECT, WHERE и GROUP BY:
ALTER TABLE demo_table ADD INDEX index_name(column_1, column_2, column_3);Имайте предвид, че когато се занимавате с покриващи индекси, е много важно да изберете правилния ред на колоните в индекса. За да бъдат вашите покриващи индекси ефективни, поставете първо колоните, които използвате с клаузите WHERE, следващи ORDER BY и GROUP BY и последно колоните, използвани с клаузата SELECT.
Стратегии за индексиране в MySQL
Следването на съветите, обхванати в тези три части от публикации в блога относно индексите в MySQL, може да ви осигури наистина добра основа, но има и няколко стратегии за индексиране, които може да искате да използвате, ако искате наистина се възползвайте от силата на индексите във вашата MySQL архитектура. За да се придържат вашите индекси към най-добрите практики на MySQL, помислете за:
-
Изолиране на колоната, върху която използвате индекса - като цяло MySQL не използва индекси, ако колоните те се използват върху не са изолирани. Например, такава заявка няма да използва индекс, защото не е изолирана:
SELECT demo_column FROM demo_table WHERE demo_id + 1 = 10;
Такава заявка обаче би:
SELECT demo_column FROM demo_table WHERE demo_id = 10; -
Не използвайте индекси за колоните, които индексирате. Например, използването на заявка като so не би довела до голяма полза, така че е по-добре да избягвате такива заявки, ако можете:
SELECT demo_column FROM demo_table WHERE TO_DAYS(CURRENT_DATE) - TO_DAYS(column_date) <= 10; -
Ако използвате LIKE заявки заедно с индексирани колони, избягвайте да поставяте заместващия знак в началото на заявката за търсене, защото по този начин MySQL също няма да използва индекс. Това е вместо да пишете заявки като това:
SELECT * FROM demo_table WHERE demo_column LIKE ‘%search query%’;
Помислете да ги напишете така:SELECT * FROM demo_table WHERE demo_column LIKE ‘search_query%’;
Втората заявка е по-добра, защото MySQL знае с какво започва колоната и може да използва индексите по-ефективно. Както при всичко обаче, операторът EXPLAIN може да бъде от голяма полза, ако искате да сте сигурни, че вашите индекси действително се използват от MySQL.
Използване на ClusterControl за поддържане на ефективността на вашите заявки
Ако искате да подобрите производителността на MySQL, съветът по-горе трябва да ви насочи към правилния път. Ако смятате, че имате нужда от нещо повече, помислете за ClusterControl за MySQL. Едно от нещата, с които ClusterControl може да ви помогне, включва управление на производителността - както вече беше отбелязано в предишни публикации в блога, ClusterControl може също да ви помогне да поддържате вашите заявки да работят с най-доброто от възможностите си през цялото време - това е защото ClusterControl също включва заявка монитор, който ви позволява да наблюдавате производителността на вашите заявки, да виждате бавни, продължителни заявки, както и извънредни заявки, които ви предупреждават за възможните пречки в производителността на вашата база данни, преди да можете да ги забележите сами:
Можете дори да филтрирате заявките си, което ви позволява да направите предположение, ако индекс е бил използван от индивидуална заявка или не:
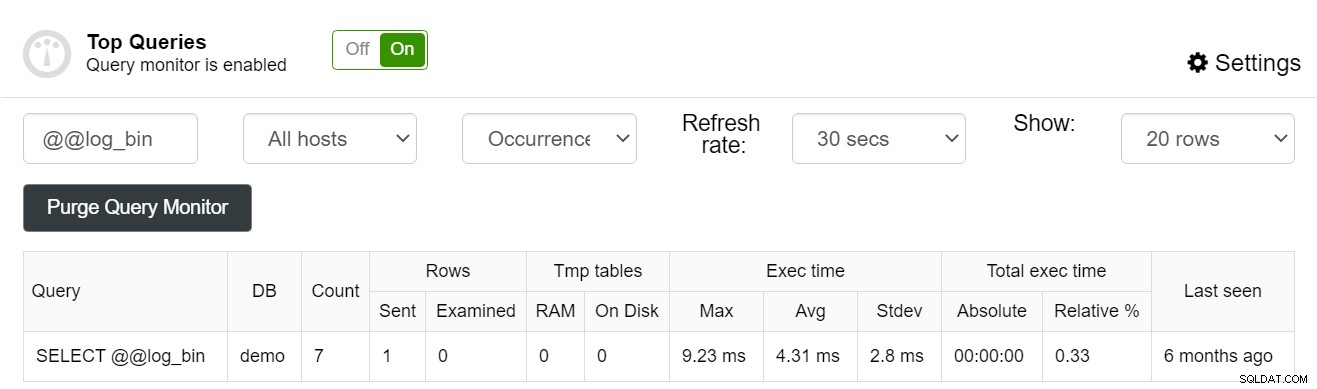
ClusterControl може да бъде чудесен инструмент за подобряване на производителността на вашата база данни, като същевременно сваляте от ръцете си проблемите с поддръжката. За да научите повече за това какво може да направи ClusterControl, за да подобри производителността на вашите MySQL екземпляри, помислете да разгледате страницата ClusterControl за MySQL.
Резюме
Както вероятно можете да разберете досега, индексите в MySQL са много сложен звяр. За да изберете най-добрия индекс за вашия MySQL екземпляр, да знаете какви са индексите и какво правят, да знаете типовете MySQL индекси, да знаете техните предимства и недостатъци, да се образовате как MySQL индексите взаимодействат с двигателите за съхранение, също така разгледайте ClusterControl за MySQL, ако смятате, че автоматизирането на определени задачи, свързани с индекси в MySQL, може да улесни деня ви.