Независимо от коя страна на уравнението сте, понякога е трудно да намерите квалифициран човек за конкретна работа. В тази публикация разглеждаме модел на данни, за да помогнем на служителите и отделите по човешки ресурси да останат организирани по време на процеса на наемане.
Повечето от нас са участвали в процеса на наемане – най-често като кандидат за работа. Въпреки това, ние също можем да се окажем въвлечени от страна на наемането, може би чрез тестване на техническите познания на кандидата. Процесът на набиране на персонал отнема известно време и групата кандидати непрекъснато нараства, докато се приближаваме до окончателното решение. Резултатът трябва да бъде изборът на най-добрия човек за работата.
Набирането на персонал само по себе си е доста сложно, така че ще обсъдим доста изчерпателен модел на данни, който да покрие всички аспекти на процеса. Облегнете се на стола си и се насладете на днешната статия!
Как работи процесът на набиране на персонал
Повечето части от процеса на набиране на персонал са общоизвестни, но ще обсъдим как точно работи, преди да преминем към модела на данните.
-
Откриване на нужда
Това е абсолютно задължително в процеса на набиране на персонал; няма да има процес, ако ръководството не е наясно с необходимостта от наемане на нов служител. Тази нужда може да бъде резултат от стартиране на нова компания, растеж в съществуваща компания или напускане на настоящ служител.
Освен ако една компания няма строго определени позиции (например банки), не винаги е лесно да се определи кога да се наеме нов служител. Разговорите със служителите и виждането на много извънреден труд могат да стимулират ново наемане. Вътрешните или външните разпоредби могат също да изискват определени позиции да се дават само на хора със специфичен набор от умения и съответен професионален опит (напр. вътрешен рецензент).
-
Очертаване на позицията и необходимите й умения
За да получите представа за тази стъпка, помислете за наистина добре написана длъжностна характеристика. Съдържа:
- Списък с всички задачи, свързани с работата
- Минимални квалификации за образование и професионален опит
- Специфични умения, необходими за работните функции
- Допълнителни или предпочитани умения
- Резюме на това, което работодателят очаква от кандидата и какво може да очаква кандидатът от тази работа
- Обхват на заплатите и може би пакет от обезщетения
Тази информация е важна както за набиращите персонал, така и за кандидатите. Няма смисъл да се канят десет кандидати в процеса на подбор, ако никой от тях не е доволен от финансовата оферта. И колкото по-подробна е длъжностната характеристика, толкова по-лесно ще бъде привличането на квалифицирани кандидати.
-
Определяне кой ще управлява процеса и кога трябва да се изпълнява всяка задача
Следващата стъпка е да дефинирате конкретни дати, когато всяка част от процеса ще се случи. Освен това компаниите могат да назначават служители на всяка стъпка. Ако компанията има отдел „Човешки ресурси“, тя вероятно ще управлява всяка част от процеса на набиране на персонал, въпреки че други служители могат да допринесат със своите специфични знания, когато е необходимо (например, ако наемаме ИТ специалист, мениджърът на ИТ отдела трябва да оцени кандидатите технически умения).
Ако няма HR отдел, можем да очакваме, че управленският персонал ще отговаря за процеса. В малките и средни компании това е не само необходимо, но и желано.
-
Публикуване на работа
Сега сме готови да публикуваме описание на длъжността на нашия сайт, в табла за работа или агрегатори или във вестник. Обявата за работа трябва да съдържа точките, изброени в Стъпка 2. Това ще помогне на потенциалните кандидати да решат дали искат да кандидатстват за позицията. Важно е длъжностната характеристика да е точна; всички сме си губили времето в интервюта за работа, която не отговаряше на описанието или очакванията ни.
-
Избор, тестване и интервюиране на кандидати
След изтичане на периода за кандидатстване, кандидатите с най-подходящия набор от умения и опит ще бъдат поканени на фаза на първоначална оценка (обикновено интервю или тест). Другите кандидати ще бъдат информирани, че не са избрани за длъжността. Голяма компания трябва да покани предварително определен минимален брой кандидати за първоначална оценка. Това спестява време както на кандидатите, така и на компанията.
Малките и средни компании биха могли да решат да продължат процеса, докато намерят най-доброто. В такива случаи периодът за кандидатстване ще остане отворен, докато не бъде намерен правилният кандидат и всички други дати ще бъдат определени по пътя.
Процесът на интервю и тестване ще варира в зависимост от размера и организацията на компанията. В големите компании с отдели по човешки ресурси вероятно ще има набор от тестове за проверка на работните умения на кандидатите. Други тестове могат да измерват психологически и личностни черти, за да определят съответствието кандидат-работа, съвпадението кандидат-компания или дори здравия разум на кандидата. ☺
Тези тестове обикновено ще бъдат разделени на няколко стъпки и всяка стъпка ще намали броя на кандидатите.
-
Последното интервю
Тази стъпка вероятно ще бъде интервю на първите няколко кандидати. Това е най-важната стъпка в процеса, защото кандидатите могат да говорят сами, да демонстрират своята компетентност и личност и да определят дали компанията и позицията ще бъдат подходящи за тях. След тази стъпка най-добрият кандидат ще получи оферта. Ако приемат, процесът на набиране на тази позиция приключва. Ако кандидатът откаже предложението за работа, компанията ще направи предложение за следващия им избор.
-
Има ли разлики в процеса на набиране на персонал за малки, средни и големи предприятия? Как ще ги решим в нашия модел?
Ще има определени различия в процесите на набиране на персонал на малки, средни и големи компании. Освен това процесът ще варира в зависимост от позициите, които се наемат. Помислете колко различни са необходимите умения и опит за мениджър на съдържание, орнитолог и капитан на круизен кораб. Някои работни места ще имат повече тестове и интервюта, други може да имат само няколко. Но в крайна сметка всичко се свежда до получаването на правилните отговори и до класирането на кандидатите.
В този модел ще третирам всички тестове и интервюта по същия начин. Ще съхраняваме отговорите на всеки кандидат, ще ги свързваме със съответния въпрос и ще съхраняваме оценката на кандидата за всяка стъпка от процеса.
-
Кой може да използва този модел на данни?
Този модел е много специфичен и трябва да се използва само за процеса на набиране на персонал. Но това не се ограничава до отделите по човешки ресурси; можете също да използвате този модел, за да управлявате професионална услуга за набиране на персонал.
-
Моделът на данните
Моделът на данните се състои от пет основни предметни области:
JobsApplicants, Recruiters and DocumentsApplicationsTest detailsApplication tests
Ще опиша всяка тематична област поотделно, в същия ред, в който са изброени.
Раздел 1:Работни места
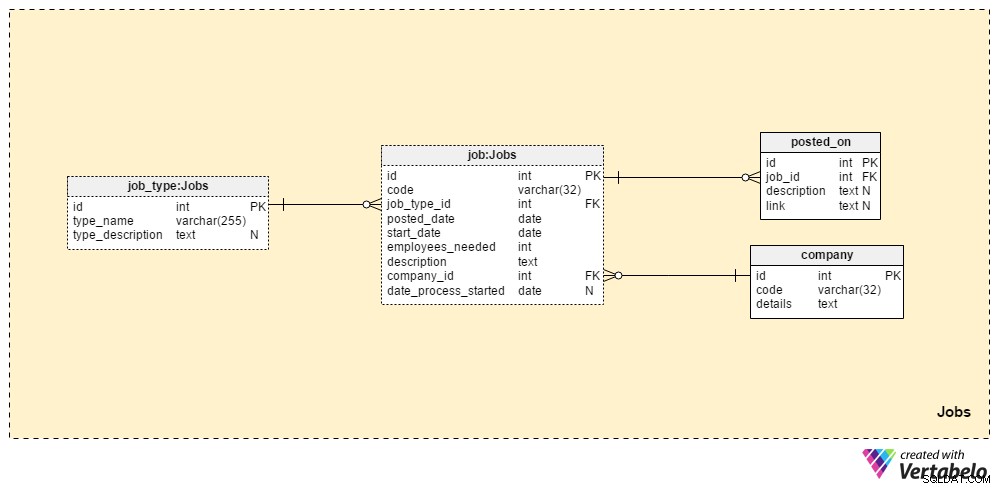
Jobs раздел ще съхранява всички подробности за всички позиции, които някога сме публикували. Двете речникови таблици, company таблица и job_type таблица, са част от първоначалната настройка. Останалите две таблици, job и posted_on , съдържат „реални“ данни, свързани с обяви за работа.
job_type речникът съдържа списък с различни и УНИКАЛНИ типове задачи. Можем да очакваме стойности като „старши администратор на база данни“ или „ИТ журналист“ да се съхранява в type_name атрибут. type_description атрибут може да съхранява по-подробно описание на заданието.
company речникът съдържа списък на всички компании, с които работим. Ако наемаме служители само за нашата компания, този речник ще съдържа само името на нашата компания. Ако сме агенция за набиране на персонал, тя ще съхранява имената на всяка компания, която ни е наела.
Списък с всяка длъжност, която някога сме публикували, се съхранява в таблицата „работа“. Атрибутите в тази таблица са:
code– Нашият вътрешен УНИКАЛЕН идентификатор, използван за обозначаване на работа.job_type_id– Препраща към съответния тип работа.posted_date– Датата, на която тази позиция е публикувана.start_date– Очакваната начална дата (първият работен ден) за тази работа.employees_needed– Броят на служителите, които искаме да наемем по време на този процес на набиране. Най-често това ще има стойност “1”, но в някои случаи – напр. при стартиране на нова компания или създаване на нов отдел – можем да очакваме по-големи стойности.description– Подробно описание на тази позиция. Това е мястото, където ще изброим всички необходими, предпочитани и желани работни умения.company_id– Позовава се на идентификационния номер на фирмата, която ни е наела. Ако сме агенция за набиране на персонал, това ще се отнася до име на фирма, съхранявано вcompanyмаса. В противен случай това ще бъде идентификационният номер на нашата собствена компания.date_process_started– Начална дата на процеса на подбор. Това може да бъде NULL, ако трябва да дефинираме бъдещи стъпки и действия по отношение на тази работа.
Последната таблица в тази тематична област е posted_on маса. За всеки job_id , ще съхраняваме link към длъжността и свързаното description . Можем да използваме тези данни, за да разберем къде кандидатите намират нашите обяви за работа.
Раздел 2:Кандидати, служители и документи
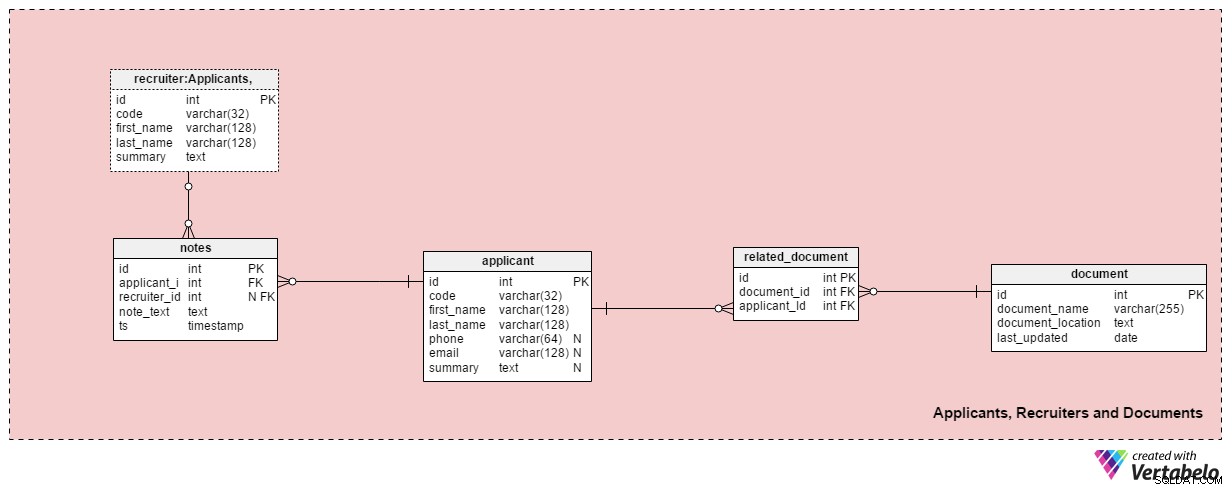
Тази тематична област съдържа всички таблици, необходими за съхраняване на информация за наемателите, кандидатите и свързаните с тях документи.
applicant таблицата изброява всички кандидати, с които някога сме имали контакт. Всеки кандидат е УНИКАЛНО дефиниран в нашата система с „код“. Освен това ще съхраняваме името и фамилията на всеки кандидат, phone номер, email адрес и тяхното summary . Тази таблица може да се коригира за специфични нужди, напр. добавяне на допълнителни телефонни номера, имейли или физически адреси.
Ще свържем кандидатите с наличните документи. Списък с всички налични документи (автобиография или автобиография, степени или дипломи, преписи, сертификати и др.) се съхранява в document маса. За всеки документ ще съхраняваме името му в системата, местоположението му и часа на най-новата актуализация.
Ще свържем кандидатите с документи с помощта на related_document маса. Той съдържа само два външни ключа, които образуват document_id – applicant_id УНИКАЛЕН чифт.
recruiter таблицата изброява служителите, които биха могли да бъдат назначени за кандидатстване за работа или които въвеждат бележки, свързани с кандидат. Всеки рекрутер е УНИКАЛНО дефиниран от него или неговия code . Ще съхраняваме само основни подробности като first_name , last_name и summary на наемателя .
Последната таблица в тази тема са notes маса. Тук ще съхраняваме всички бележки, свързани с кандидат. Бихме могли да съхраняваме бележки като „Кандидатът пропусна срещата“ или „Кандидатът се справи отлично на първото интервю“ . За всяка бележка ще съхраняваме идентификационния номер на наемателя, който е направил тази бележка, идентификационния номер на свързания кандидат, note_text и времевата марка, когато бележката е създадена.
Раздел 3:Подробности за теста
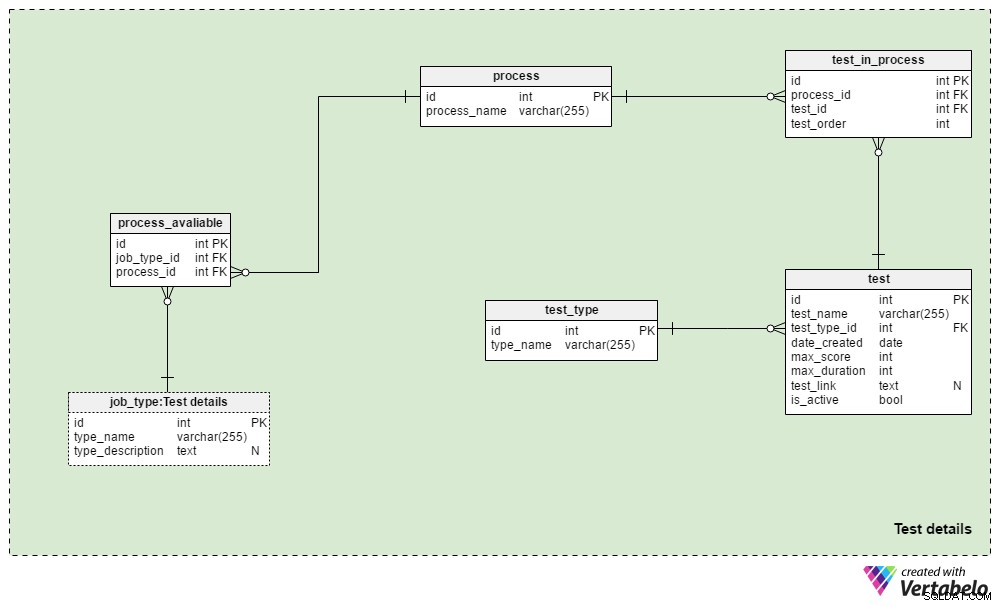
Test details предметната област съдържа таблиците, използвани за дефиниране на процесите за набиране на персонал и тестовете, използвани по време на тези процеси. Обикновено винаги ще използваме един и същ процес на подбор за един и същ тип работа:промени се правят само когато се изискват от бизнес обстоятелства. Бихме могли да използваме няколко различни процеса за всеки тип работа и почти сигурно ще използваме един и същ процес за различни типове работа.
process table е прост речник, съдържащ само УНИКАЛНО process_name атрибут. Той изброява всички процеси за набиране на персонал, които някога сме използвали и използваме в момента.
Ще свържем процеси с различни видове работа. Ще съхраняваме тези отношения в process_available маса. Единствените му атрибути са УНИКАЛНАТА двойка job_type_id – process_id . Когато има множество налични процеси за даден тип работа, това позволява на наемателя да избере един.
test_in_process таблицата се използва за дефиниране на реда на тестовете по време на този процес. Атрибутите в тази таблица са:
process_idиtest_id– Позовава се на свързания процес и тест.test_order– Поредният номер на този тест или стъпка в процеса. Заедно сprocess_id, това формира УНИКАЛНИЯ ключ на таблицата. Можем да имаме само една стъпка в даден момент по време на процеса.
test таблицата изброява всички тестове, използвани в момента и по-рано в процеса на набиране на персонал. Ние също така ще третираме прегледите на CV и интервютата като тестове. Въпреки че не се нуждаят от определени въпроси и отговори, те са част от оценка. За всеки тест ще съхраняваме:
test_name– УНИКАЛНО обозначение за всеки тест.test_type_id– Препращаtest_typeречник.date_created– Датата, на която създадохме този тест в нашата система.max_score– Максималният резултат, постижим за този тест. Тази стойност е сборът от всички верни отговори на този тест или най-високата оценка, която служителите могат да дадат на автобиография или интервю.max_duration– Колко време (в минути) кандидатът трябва да завърши теста.test_link– Съдържа връзка към мястото за тестване. Тази стойност може да бъде NULL, когато не използваме тест в процеса.is_active– Означава дали в момента използваме този тест.
Вече споменахме test_type речник. Той съдържа всички УНИКАЛНИ тестови имена по формат, напр. „Преглед на CV“ , „онлайн тест за умения“ , "тест за умения на хартия" и „интервю“ .
Този модел не включва структурата, необходима за съхраняване на тестови въпроси и отговори. По-скоро той съхранява връзка към местоположенията, които съдържат тази информация. Същият дизайн ще бъде използван в Applications предметна област.
Раздел 4:Приложения
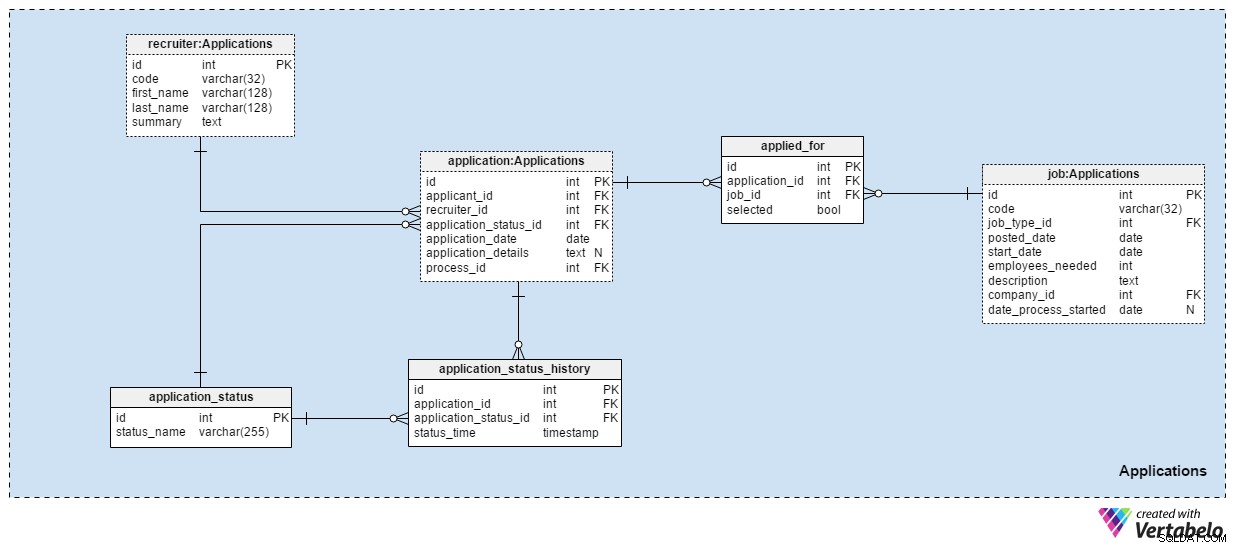
Applications предметната област е може би най-важната в този модел на данни. Всички други предметни области, споменати досега, описват приложения. Този съхранява истинските неща.
Всяко заявление, което някога сме получавали, се записва в application маса. За всяко приложение ще съхраняваме идентификационния номер на свързаните кандидати, идентификатора на наемателите и препратка към текущото състояние на това приложение. Ще актуализираме това състояние в същото време, когато правим нов запис в application_status_history маса. application_date атрибутът се използва за съхраняване на съответната дата, докато всички допълнителни подробности се съхраняват в текстов формат. process_id атрибутът съхранява препратка към процеса, избран за това приложение.
Приложенията ще променят състоянието си с течение на времето. Списък с всички състояния на приложението се съхранява в application_status речник. Единственият атрибут е status_name и може да съдържа само УНИКАЛНИ стойности. Очакваните стойности включват:„applied“ , „CV прегледано“ , "избрани за теста" , „отхвърлено след преглед на автобиографията“ , "издържал теста" , "поканени на интервю" и „прекратено от кандидата“ .
Ще съхраняваме всички състояния на приложението в application_status_history маса. Тази таблица съдържа препратки към application таблица и application_status речник. Също така ще съхраняваме точния status_time когато този статус е бил присвоен на приложението. application_id – status_time двойка формира УНИКАЛНИЯ ключ на тази таблица.
В повечето случаи кандидатът ще кандидатства само за една позиция с едно заявление. Възможно е един кандидат да кандидатства за повече от една позиция и ние ще изберем най-подходящата роля за тях по време на процеса на подбор. В applied_for таблица, ще съхраняваме УНИКАЛНАТА двойка application_id – job_id . Също така ще запишем дали кандидатът, свързан с това приложение, е selected за тази позиция. Можем да очакваме, че всички selected стойностите ще бъдат зададени на „False“ в началото на процеса на подбор и че ще актуализираме само по една за всяка позиция на „Вярно“ .
Раздел 5:Тестове на приложения
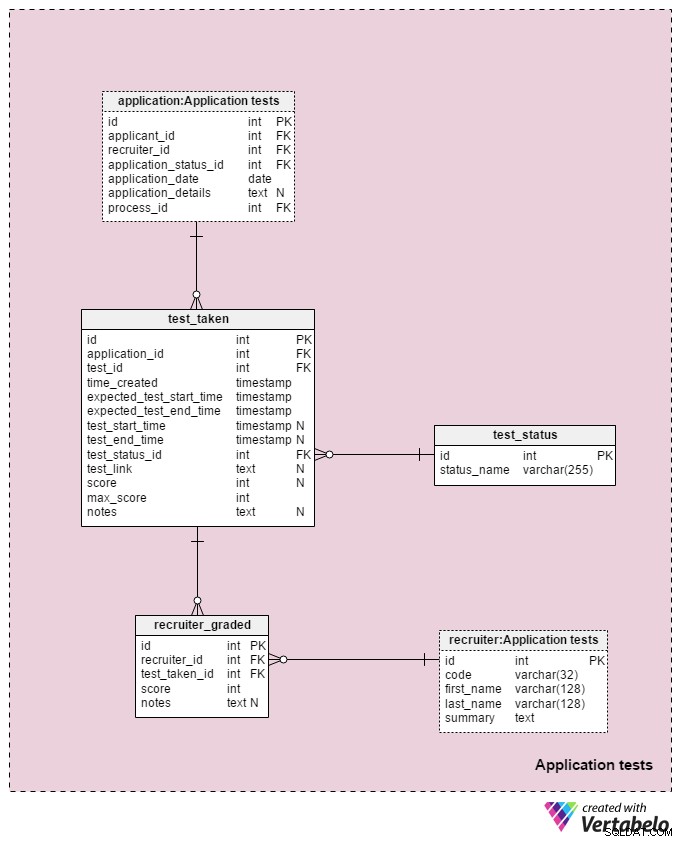
Последната тематична област в нашия модел ще се използва за съхраняване на резултатите от всеки тест, направен по време на процеса на подбор. Две таблици, използвани в тази предметна област, са копия от други предметни области:application и recruiter . Те се използват тук за опростяване на модела.
Всички подробности, свързани с всеки тест, се съхраняват в test_taken маса. Тази таблица съдържа и всички други стъпки в процеса, които могат да бъдат оценени, като преглед на автобиографията. Атрибутите в тази таблица са:
application_id– Препраща къмapplicationмаса. Това се отнася за тест с кандидата, който е минал този тест.test_id– Препраща къмtestкаталог. Бихме могли също да направим справка сtest_in_processтаблица тук, която би ни предоставила повече информация за взетия тест. Реших да не го правя, защото тази структура ни осигурява повече гъвкавост. (Напр. ако искаме да позволим на кандидатите да вземат тест два пъти или извън обичайното време).time_created– Действителното време, когато вмъкнахме този тест в нашата система.expected_test_start_timeиexpected_test_end_time– Началният и крайният час, както е обсъдено с кандидата. Бихме могли да променим тези стойности, в случай че кандидатът или наемателят трябва да отложи теста.test_start_timeиtest_end_time– Действителните начални и крайни времена на теста. Те ще съдържат NULL стойности, когато тестът бъде създаден; стойностите ще бъдат актуализирани, когато кандидатът започне и приключи този тест.test_status_id– Препраща къмtest_statusречник.test_link– Връзки към теста с отговорите на кандидата. Той ще бъде актуализиран, когато кандидатът изпрати теста.score– Резултатът на кандидата от този тест. Това се определя или ръчно от наемател (например за преглед на автобиография), или автоматично (сумата от всички резултати от тестовите елементи). Може също да съдържа стойност NULL за тестове, които не са оценени или оценени по някаква предварително определена скала. Освен това тест, който е насрочен, но все още не е завършен, може да има стойност NULL.max_score– Максималният постижим резултат от теста. Това е същото като стойността, съхранена вtest.”max_scoreатрибут. Искам да запазя тази стойност, защото наемателят може да промени теста, докато се дава, и следователно да промени максималния резултат, който може да бъде постигнат.notes– Всички допълнителни бележки или забележки, въведени от наемателите относно този конкретен тест.
Комбинацията от test_id – application_id – expected_test_start_time атрибути формира УНИКАЛНИЯ ключ на тази таблица. Преди да добавим нова тестова сесия, все пак трябва да проверим за припокриващи се тестови интервали за свързания кандидат и всички свързани наематели.
test_status речникът съдържа списък на всеки УНИКАЛЕН status_name които могат да бъдат причислени към тест. Някои очаквани стойности включват:„не стартира“ , „в ход“ , "завършено успешно" , "завършено неуспешно" , „отложено“ , „отменено“ и „заявителят е анулиран“ .
Последната таблица в нашия модел е recruiter_graded таблица, която съхранява всички оценки, дадени от наемателите при оценяване на всеки тест. Поради това ще съхраняваме препратки към recruiter и test_taken маси. Ще съхраним и score постигнато, както и всички notes . Тази информация е много важна, особено когато оценяваме тестове ръчно (т.е. за прегледи на CV и интервюта).
Днес обсъдихме модел на данни, който може да покрие почти всяка ситуация в процеса на подбор и набиране – включително необичайни изключения.
Повечето от нас имат известни познания по тази тема. Моля, споделете опита си, докато сте били в ролята на рекрутер или от другата страна на бюрото. Този модел покрива ли ситуациите, с които сте се сблъсквали? Ако не, какви промени бихте предложили?