Миналия месец разгледах пъзела на Питър Ларсон за съпоставяне на предлагането с търсенето. Показах простото решение на Питър, базирано на курсора, и обясних, че има линейно мащабиране. Предизвикателството, с което ви оставих, е да се опитате да излезете с базирано на набор решение на задачата и момче, накарайте хората да се справят с предизвикателството! Благодаря на Лука, Камил Косно, Даниел Браун, Брайън Уокър, Джо Оббиш, Райнер Хофман, Пол Уайт, Чарли и, разбира се, Питър Ларсон, за изпращането на вашите решения. Някои от идеите бяха брилянтни и направо умопомрачителни.
Този месец ще започна да изследвам представените решения, грубо преминавайки от по-лошо представящите се към най-добре представящите се. Защо изобщо да се занимавам с тези с лошо представяне? Защото все още можете да научите много от тях; например чрез идентифициране на анти-модели. Всъщност първият опит за решаване на това предизвикателство за много хора, включително мен и Питър, се основава на концепция за интервално пресичане. Случва се така, че класическата техника, базирана на предикати за идентифициране на пресичане на интервали, има лоша производителност, тъй като няма добра схема за индексиране, която да я поддържа. Тази статия е посветена на този подход с лошо представяне. Въпреки лошото представяне, работата по решението е интересно упражнение. Това изисква практикуване на умението за моделиране на проблема по начин, който се поддава на лечение, базирано на множество. Също така е интересно да се идентифицира причината за лошото представяне, което улеснява избягването на анти-шаблона в бъдеще. Имайте предвид, че това решение е само отправната точка.
DDL и малък набор от примерни данни
Като напомняне, задачата включва заявка за таблица, наречена "Търги." Използвайте следния код, за да създадете таблицата и да я попълните с малък набор от примерни данни:
ПУСНЕТЕ ТАБЛИЦА, АКО СЪЩЕСТВУВА dbo.Auctions; СЪЗДАВАНЕ НА ТАБЛИЦА dbo.Auctions( ID INT NOT NULL IDENTITY(1, 1) ОГРАНИЧЕНИЕ pk_Auctions ПЪРВИЧЕН КЛУСТРИРАН, Код CHAR(1) НЕ НУЛВО ОГРАНИЧЕНИЕ ck_Auctions_Code CHECK (Код ='D' ИЛИ Код ='S'), Количество19 , 6) NOT NULL CONSTRAINT ck_Auctions_Quantity CHECK (количество> 0)); ВКЛЮЧЕТЕ NOCOUNT; ИЗТРИВАНЕ ОТ dbo.Auctions; SET IDENTITY_INSERT dbo.Auctions ON; ВМЕСТЕ В dbo.Auctions(ID, Code, Quantity) СТОЙНОСТИ (1, 'D', 5.0), (2, 'D', 3.0), (3, 'D', 8.0), (5, 'D', 2.0), (6, 'D', 8.0), (7, 'D', 4.0), (8, 'D', 2.0), (1000, 'S', 8.0), (2000, 'S', 6.0), (3000, 'S', 2.0), (4000, 'S', 2.0), (5000, 'S', 4.0), (6000, 'S', 3.0), (7000, 'S', 2.0); SET IDENTITY_INSERT dbo. Търговете са ИЗКЛЮЧЕНИ;
Вашата задача беше да създадете сдвояване, което съответства на предлагането и търсенето на базата на подреждане на ID, като ги записвате във временна таблица. Следва желаният резултат за малкия набор от примерни данни:
DemandID SupplyID TradeQuantity----------- ----------- --------------1 1000 5.0000002 1000 3.0000003 2000 6.0000003 3000 2,0000005 4000 2,0000006 5000 4,0000006 6000 3,0000006 7000 1,0000007 7000 1,000000
Миналия месец също предоставих код, който можете да използвате, за да попълните таблицата за търгове с голям набор от примерни данни, контролирайки броя на вписванията за предлагане и търсене, както и техния диапазон от количества. Уверете се, че използвате кода от статията от миналия месец, за да проверите ефективността на решенията.
Моделиране на данните като интервали
Една интригуваща идея, която се поддава на подкрепа на решения, базирани на множество, е да се моделират данните като интервали. С други думи, представяйте всяко вписване на търсенето и предлагането като интервал, започващ с текущите общи количества от същия вид (търсене или предлагане) до, но с изключение на тока, и завършващ с текущата сума, включително тока, разбира се въз основа на ID поръчване. Например, разглеждайки малкия набор от примерни данни, първият запис на търсенето (ID 1) е за количество от 5,0, а вторият (ID 2) е за количество от 3,0. Първият запис за търсене може да бъде представен с началото на интервала:0.0, край:5.0, а вторият с началото на интервала:5.0, край:8.0 и така нататък.
По същия начин първият запис за предлагане (ID 1000) е за количество от 8,0, а вторият (ID 2000) е за количество от 6,0. Първият запис на доставките може да бъде представен с начало на интервала:0.0, край:8.0, а вторият с начало на интервала:8.0, край:14.0 и т.н.
Двойките търсене-предложение, които трябва да създадете, са припокриващите се сегменти на пресичащите се интервали между двата вида.
Това вероятно се разбира най-добре с визуално изображение на базираното на интервали моделиране на данните и желания резултат, както е показано на Фигура 1.
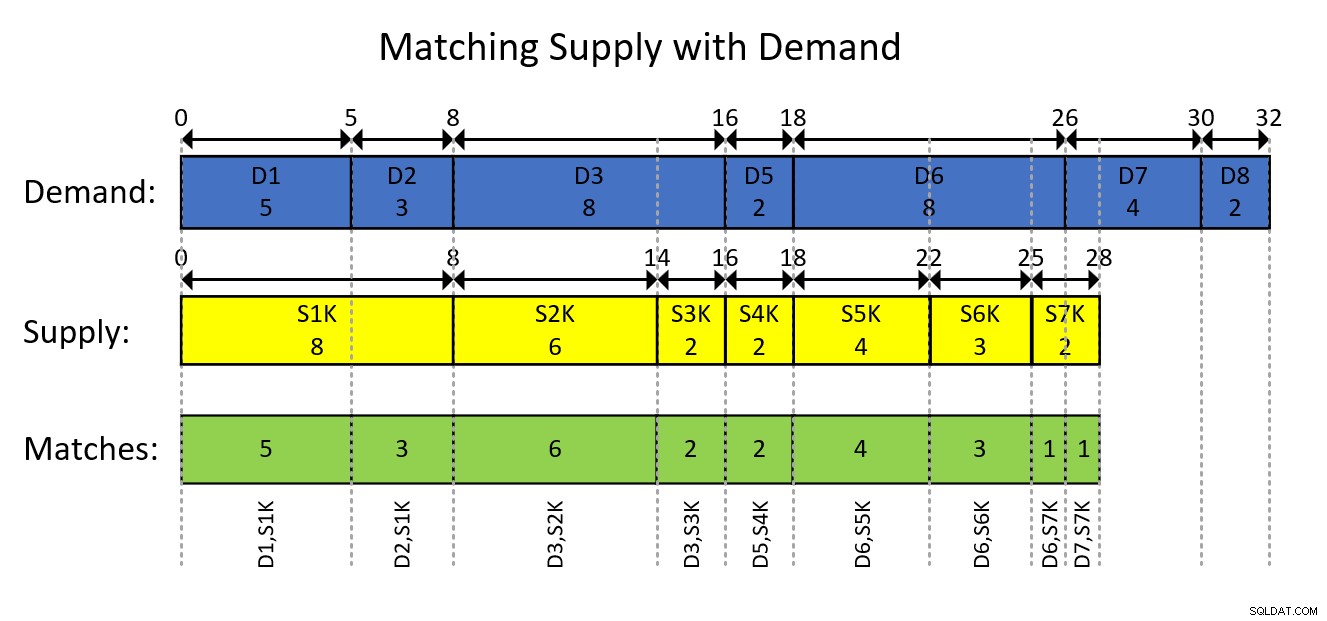 Фигура 1:Моделиране на данните като интервали
Фигура 1:Моделиране на данните като интервали
Визуалното изображение на фигура 1 е доста разбираемо, но накратко...
Сините правоъгълници представляват записите за търсене като интервали, показващи изключителните текущи общи количества като начало на интервала и включващото текущо общо като край на интервала. Жълтите правоъгълници правят същото за вписванията за доставки. След това забележете как припокриващите се сегменти от пресичащите се интервали от двата вида, които са изобразени със зелените правоъгълници, са двойки търсене-предложение, които трябва да създадете. Например, първото сдвояване на резултата е с идентификатор на търсенето 1, идентификатор на доставката 1000, количество 5. Второто сдвояване на резултата е с идентификатор на търсенето 2, идентификатор на доставка 1000, количество 3. И така нататък.
Интервални пресечки, използващи CTEs
Преди да започнете да пишете T-SQL кода с решения, базирани на идеята за интервално моделиране, вече трябва да имате интуитивно усещане за това кои индекси вероятно ще бъдат полезни тук. Тъй като е вероятно да използвате функции на прозореца за изчисляване на текущи суми, бихте могли да се възползвате от покриващ индекс с ключ, базиран на колоните Код, ИД и включително колоната Количество. Ето кода за създаване на такъв индекс:
СЪЗДАВАЙТЕ УНИКАЛЕН НЕКЛУСТРИРАН ИНДЕКС idx_Code_ID_i_Quantity НА dbo.Auctions(Code, ID) INCLUDE(Quantity);
Това е същият индекс, който препоръчах за базираното на курсора решение, което разгледах миналия месец.
Освен това тук има потенциал да се възползвате от пакетната обработка. Можете да активирате разглеждането му без изискванията за пакетен режим в rowstore, например, като използвате SQL Server 2019 Enterprise или по-нова версия, като създадете следния фиктив индекс на columnstore:
СЪЗДАВАЙТЕ НЕКЛУСТРИРАН ИНДЕКС НА COLUMNSTORE idx_cs НА dbo.Auctions(ID) КЪДЕТО ID =-1 И ID =-2;
Вече можете да започнете да работите върху T-SQL кода на решението.
Следният код създава интервалите, представляващи записите за търсене:
С D0 AS-- D0 изчислява текущото търсене като EndDemand( SELECT ID, Quantity, SUM(Quantity) OVER(ПОРЪЧКА ПО ИД РЕДОВЕ НЕОГРАНИЧЕНИ ПРЕДШЕСТВА) КАТО EndDemand ОТ dbo.Търги, КЪДЕТО Код ='D'),-- D извлича предишно EndDemand като StartDemand, изразяващо търсенето в началото като интервалD AS( SELECT ID, Quantity, EndDemand - Quantity AS StartDemand, EndDemand FROM D0)SELECT *FROM D;
Заявката, дефинираща CTE D0, филтрира вписванията за търсене от таблицата за търгове и изчислява текущо общо количество като краен ограничител на интервалите на търсене. След това заявката, дефинираща втория CTE, наречена D, заявява D0 и изчислява началния ограничител на интервалите на търсене, като извади текущото количество от крайния ограничител.
Този код генерира следния изход:
ID Количество StartDemand EndDemand---- --------- ------------ ----------1 5.000000 0.000000 5.0000002 3.000000 5.000000 8.0000003 8.000000 8.000000 16.0000005 2.000000 16.000000 18.0000006 8.000000 18.000000 26.0000007 4.000000 26.000000 26.000000 26.0000026.00000000000000000000000000000000000000000Интервалите на доставките се генерират много подобно чрез прилагане на същата логика към записите за доставки, като се използва следния код:
С S0 AS-- S0 изчислява текущото снабдяване като крайно снабдяване( ИЗБЕРЕТЕ ИД, количество, СУМА(количество) НАД (ПОРЪЧКА ПО ИД РЕДОВЕ, НЕОГРАНИЧЕНИ ПРЕДШЕСТВАЩИ) КАТО Крайно снабдяване ОТ dbo.Търги, КЪДЕТО Код ='S'),-- S извлечения предишна Крайна доставка като StartSupply, изразяваща доставка в началото като интервалS AS( SELECT ID, Quantity, EndSupply - Количество AS StartSupply, EndSupply ОТ S0)SELECT *FROM S;Този код генерира следния изход:
ID Количество Начална доставка Крайна доставка----- --------- ------------ ----------1000 8.000000 0.000000 8.0000002000 6.000000 8.000000 14.0000003000 2.000000 14.000000 16.0000004000 2.000000 16.000000 18.0000005000 4.000000 18.000000 22.0000006000 3.000000 22.000000 25.0000007000 2.000000 25.000000 27.000000След това остава да се идентифицират пресичащите се интервали на търсене и предлагане от CTE D и S и да се изчислят припокриващите се сегменти на тези пресичащи се интервали. Не забравяйте, че сдвояването на резултата трябва да бъде записано във временна таблица. Това може да стане с помощта на следния код:
-- Извадете временната таблица, ако съществува. С D0 AS-- D0 изчислява текущото търсене като EndDemand( SELECT ID, Quantity, SUM(Quantity) OVER(ПОРЪЧКА ПО ID РЕДОВЕ НЕОГРАНИЧЕНИ ПРЕДШЕСТВА) КАТО EndDemand ОТ dbo.Auctions WHERE Code ='D'),-- D извлича предишно EndDemand като StartDemand, изразяващо търсенето в началото като интервал D AS( SELECT ID, Quantity, EndDemand - Quantity AS StartDemand, EndDemand FROM D0),S0 AS-- S0 изчислява текущото предлагане като EndSupply( SELECT ID, Quantity, SUM(Quantity) OVER (ПОРЪЧАЙТЕ ПО ИД РЕДОВЕ НЕОГРАНИЧЕНО ПРЕДШЕСТВУВАЩО) КАТО Крайно доставка ОТ dbo.Auctions WHERE Code ='S'),-- S извлича предишно Крайно предлагане като StartSupply, изразяващо начално снабдяване като интервалS AS( SELECT ID, Quantity, EndSupply - Количество AS StartSupply, EndSupply ОТ S0)-- Външната заявка идентифицира сделките като припокриващи се сегменти на пресичащите се интервали-- В пресичащите се интервали на търсене и предлагане количеството на търговията е тогава -- НАЙ-МАЛКО(EndDemand, EndSupply) - GREATEST(StartDemsnad, StartSupply)SELECT D.ID КАТО DemandID, S.ID AS SupplyID, CASE WH EN EndDemandStartSupply THEN StartDemand ELSE StartSupply END AS TradeQuantityINTO #MyPairingsFROM D INNER JOIN S ON D.StartDemand Освен кода, който създава интервалите за търсене и предлагане, който вече видяхте по-рано, основното допълнение тук е външната заявка, която идентифицира пресичащите се интервали между D и S и изчислява припокриващите се сегменти. За да идентифицира пресичащите се интервали, външната заявка свързва D и S, използвайки следния предикат за свързване: D.StartDemandS.StartSupply Това е класическият предикат за идентифициране на пресичане на интервали. Това е и основният източник за лошата производителност на решението, както ще обясня скоро.
Външната заявка също така изчислява търговското количество в списъка SELECT като:
LEAST(EndDemand, EndSupply) - GREATEST(StartDemand, StartSupply)Ако използвате Azure SQL, можете да използвате този израз. Ако използвате SQL Server 2019 или по-стара версия, можете да използвате следната логически еквивалентна алтернатива:
CASE WHEN EndDemandStartSupply THEN StartDemand ELSE StartSupply END Тъй като изискването беше да се запише резултатът във временна таблица, външната заявка използва израз SELECT INTO, за да постигне това.
Идеята да се моделират данните като интервали е очевидно интригуваща и елегантна. Но какво да кажем за производителността? За съжаление, това специфично решение има голям проблем, свързан с това как се идентифицира интервалното пресичане. Разгледайте плана за това решение, показан на фигура 2.
Фигура 2:План на заявка за кръстовища, използващи решение за CTEs
Нека започнем с евтините части от плана.
Външният вход на присъединяването на вложените цикли изчислява интервалите на търсене. Той използва оператор Index Seek за извличане на записите за търсене и оператор Window Aggregate в пакетен режим, за да изчисли крайния разделител на интервала на търсене (наричан в този план Expr1005). След това началният ограничител на интервала на търсене е Expr1005 – Количество (от D).
Като странична забележка, може да откриете, че използването на изричен оператор за сортиране преди оператора Window Aggregate в пакетния режим е изненадващо, тъй като записите за търсене, извлечени от търсенето на индекс, вече са подредени по ID, както се нуждае от функцията на прозореца. Това е свързано с факта, че понастоящем SQL Server не поддържа ефективна комбинация от паралелна операция с индекс за запазване на реда преди оператора Window Aggregate в паралелен пакетен режим. Ако наложите сериен план само за експериментални цели, ще видите как операторът за сортиране изчезва. SQL Server реши като цяло, използването на паралелизъм тук е предпочитано, въпреки че това води до добавено изрично сортиране. Но отново, тази част от плана представлява малка част от работата в голямата схема на нещата.
По подобен начин вътрешният вход на присъединяването на вложените цикли започва с изчисляване на интервалите за доставка. Любопитното е, че SQL Server избра да използва оператори в режим на ред, за да се справи с тази част. От една страна, операторите в редовия режим, използвани за изчисляване на текущи суми, включват повече разходи, отколкото алтернативата Window Aggregate в пакетния режим; от друга страна, SQL Server има ефективна паралелна реализация на операция за запазване на реда, последвана от изчислението на функцията на прозореца, избягвайки изричното сортиране за тази част. Любопитно е, че оптимизаторът избра една стратегия за интервалите на търсене и друга за интервалите на предлагане. Във всеки случай, операторът Index Seek извлича записите за доставки и последващата последователност от оператори до оператора Compute Scalar изчислява крайния разделител на интервала на доставка (наричан Expr1009 в този план). Ограничителят на началния интервал на доставка тогава е Expr1009 – Количество (от S).
Въпреки количеството текст, който използвах, за да опиша тези две части, наистина скъпата част от работата в плана е това, което следва.
Следващата част трябва да обедини интервалите на търсене и интервалите на предлагане, използвайки следния предикат:
D.StartDemandS.StartSupply Без поддържащ индекс, като се приемат интервали на търсене на DI и интервали на доставка в SI, това би включвало обработка на DI * SI редове. Планът на фигура 2 е създаден след попълване на таблицата за търгове с 400 000 реда (200 000 записа за търсене и 200 000 записа за предлагане). Така че, без поддържащ индекс, планът би трябвало да обработи 200 000 * 200 000 =40 000 000 000 реда. За да смекчи тази цена, оптимизаторът избра да създаде временен индекс (виж оператора Index Spool) с разделител на края на интервала на доставка (Expr1009) като ключ. Това е най-доброто, което може да направи. Това обаче решава само част от проблема. С два предиката за диапазон, само един може да бъде поддържан от предикат за търсене на индекс. С другия трябва да се използва остатъчен предикат. Всъщност можете да видите в плана, че търсенето във временния индекс използва предиката за търсене Expr1009> Expr1005 – D.Quantity, последвано от оператор Filter, обработващ остатъчния предикат Expr1005> Expr1009 – S.Quantity.
Ако приемем средно, предикатът за търсене изолира половината от редовете за предлагане от индекса на ред за търсене, общият брой редове, излъчени от оператора Index Spool и обработени от оператора Filter, тогава е DI * SI / 2. В нашия случай, с 200 000 редове за търсене и 200 000 реда за предлагане, това означава 20 000 000 000. Действително, стрелката, преминаваща от оператора Index Spool към оператора Filter, отчита редица редове, близки до това.
Този план има квадратично мащабиране в сравнение с линейното мащабиране на базираното на курсора решение от миналия месец. Можете да видите резултата от тест за производителност, сравняващ двете решения на фигура 3. Можете ясно да видите добре оформената парабола за базираното на множество решение.
Фигура 3:Изпълнение на пресечки с използване на CTEs решение спрямо базирано на курсор решение
Интервални пресечки с помощта на временни таблици
Можете донякъде да подобрите нещата, като замените използването на CTE за интервалите на търсенето и предлагането с временни таблици и за да избегнете шпулата с индекси, създавайки свой собствен индекс във временната таблица, съдържащ интервалите за доставка с крайния разделител като ключ. Ето пълния код на решението:
-- Премахнете временните таблици, ако съществуват. ИЗПУСКАТЕ ТАБЛИЦА, АКО СЪЩЕСТВУВА #MyPairings, #Demand, #Supply; С D0 AS-- D0 изчислява текущото търсене като EndDemand( SELECT ID, Quantity, SUM(Quantity) OVER(ПОРЪЧКА ПО ID РЕДОВЕ НЕОГРАНИЧЕНИ ПРЕДШЕСТВА) КАТО EndDemand ОТ dbo.Auctions WHERE Code ='D'),-- D извлича предишно EndDemand като StartDemand, изразяващо търсенето в началото като интервалD AS( SELECT ID, Quantity, EndDemand - Количество AS StartDemand, EndDemand FROM D0)SELECT ID, Quantity, CAST(ISNULL(StartDemand, 0.0) AS DECIMAL(19, 6)) AS StartDemand, CAST(ISNULL(EndDemand, 0.0) AS DECIMAL(19, 6)) AS EndDemandINTO #DemandFROM D;WITH S0 AS-- S0 изчислява текущото снабдяване като EndSupply( SELECT ID, Quantity, SUM(Quantity) OVER(ORDER BY ID РЕДОВЕ НЕОГРАНИЧЕНИ ПРЕДИШНИ) КАТО Крайно снабдяване ОТ dbo.Auctions WHERE Code ='S'),-- S извлича предишно Крайно предлагане като StartSupply, изразяващо начално снабдяване като интервалS AS( SELECT ID, Quantity, EndSupply - Количество КАТО StartSupply F, EndSupply S0)ИЗБЕРЕТЕ ИД, количество, CAST(ISNULL(Начално снабдяване, 0.0) КАТО ДЕСЕТИЧНО(19, 6)) КАТО Начално снабдяване, CAST(ISNULL(Крайно снабдяване, 0.0) КАТО DECIMAL(19, 6)) КАТО Крайно снабдяванеINTO #SupplyFROM S; СЪЗДАВАЙТЕ УНИКАЛЕН КЛУСТРИРАН ИНДЕКС idx_cl_ES_ID ON #Supply(EndSupply, ID); -- Външната заявка идентифицира сделките като припокриващи се сегменти на пресичащите се интервали-- В пресичащите се интервали на търсене и предлагане количеството на търговията е тогава -- НАЙ-МАЛКО(крайно търсене, крайно предлагане) - НАЙ-ГОЛЕМО(StartDemsnad, StartSupply)SELECT D.ID КАТО DemandID, S.ID КАТО SupplyID, CASE WHEN EndDemandStartSupply THEN StartDemand ELSE StartSupply END AS TradeQuantityINTO #MyPairingsFROM #Demand AS D INNER JOIN (DWITHER INNER JOIN) S.EndSupply И D.EndDemand> S.StartSupply; Плановете за това решение са показани на Фигура 4:
Фигура 4:План на заявка за пресечки с помощта на решение за Temp Tables
Първите два плана използват комбинация от оператори Index Seek + Sort + Window Aggregate в пакетен режим за изчисляване на интервалите на предлагане и търсене и записването им във временни таблици. Третият план обработва създаването на индекс в таблицата #Supply с разделителя EndSupply като водещ ключ.
Четвъртият план представлява далеч по-голямата част от работата, с оператор за присъединяване на вложени цикли, който съответства на всеки интервал от #Demand, пресичащите се интервали от #Supply. Забележете, че и тук операторът Index Seek разчита на предиката #Supply.EndSupply> #Demand.StartDemand като предикат за търсене и #Demand.EndDemand> #Supply.StartSupply като остатъчен предикат. Така че по отношение на сложността/мащабирането получавате същата квадратична сложност като за предишното решение. Просто плащате по-малко на ред, тъй като използвате свой собствен индекс вместо индексната шпула, използвана от предишния план. Можете да видите производителността на това решение в сравнение с предишните две на Фигура 5.
Фигура 5:Изпълнение на пресечки с помощта на временни таблици в сравнение с други две решения
Както можете да видите, решението с временните таблици се представя по-добре от това с CTEs, но все пак има квадратично мащабиране и се справя много зле в сравнение с курсора.
Какво следва?
Тази статия обхваща първия опит за справяне с класическата задача за съпоставяне на търсенето и предлагането с помощта на решение, базирано на набор. Идеята беше да се моделират данните като интервали, да се съпоставят предлагането с вписванията за търсене чрез идентифициране на пресичащи се интервали на предлагане и търсене и след това да се изчисли количеството за търговия въз основа на размера на припокриващите се сегменти. Разбира се, интригуваща идея. Основният проблем с него е и класическият проблем за идентифициране на пресичане на интервали чрез използване на два предиката на диапазона. Дори с най-добрия индекс на място, можете да поддържате само един предикат на диапазон с търсене на индекс; другият предикат на диапазона трябва да се обработва с помощта на остатъчен предикат. Това води до план с квадратична сложност.
И така, какво можете да направите, за да преодолеете това препятствие? Има няколко различни идеи. Една брилянтна идея принадлежи на Джо Оббиш, за която можете да прочетете подробно в неговата публикация в блога. Ще разгледам други идеи в предстоящите статии от поредицата.
[ Прескочи към:Оригинално предизвикателство | Решения:Част 1 | Част 2 | част 3]



