SQL Server ни предоставя различни решения за репликиране или архивиране на таблица или таблици на база данни в друга база данни или същата база данни с различни имена. Като разработчик на SQL Server или администратор на база данни, може да се сблъскате със ситуации, когато трябва да проверите дали данните в тези две таблици са идентични и ако по погрешка данните не се репликират между тези две таблици, трябва да синхронизирате данните между масите. Освен това, ако получите съобщение за грешка, което нарушава процеса на синхронизиране или репликация, поради разлики в схемите между таблиците източник и дестинация, трябва да намерите лесен и бърз начин да идентифицирате разликите в схемите, ПРОМЕНЯТЕ таблиците, за да направите схемата е идентична от двете страни и възобновете процеса на синхронизиране на данни.
В други ситуации се нуждаете от лесен начин да получите отговора ДА или НЕ, ако данните и схемата на две таблици са идентични или не. В тази статия ще преминем през различните начини за сравняване на данните и схемата между две таблици. Предоставените методи в тази статия ще сравняват таблици, които се хостват в различни бази данни, което е по-сложният сценарий, и могат лесно да се използват за сравняване на таблиците, намиращи се в една и съща база данни с различни имена.
Преди да опишем различните методи и инструменти, които могат да се използват за сравняване на данните и схемите на таблиците, ще подготвим нашата демонстрационна среда, като създадем две нови бази данни и ще създадем една таблица във всяка база данни, с една малка разлика в типа данни между тези две таблици, т.к. показано в операторите CREATE DATABASE и CREATE TABLE T-SQL по-долу:
CREATE DATABASE TESTDB CREATE DATABASE TESTDB2 CREATE TABLE TESTDB.dbo.FirstComTable ( ID INT IDENTITY (1,1) PRIMARY KEY, FirstName VARCHAR (50), LastName VARCHAR (50), Address VARCHAR (500) ) GO CREATE TABLE TESTDB2.dbo.FirstComTable ( ID INT IDENTITY (1,1) PRIMARY KEY, FirstName VARCHAR (50), LastName VARCHAR (50), Address NVARCHAR (400) ) GO
След като създадем базите данни и таблиците, ще запълним двете таблици с пет еднакви реда, след което ще вмъкнем друг нов запис само в първата таблица, както е показано в операторите INSERT INTO T-SQL по-долу:
INSERT INTO TESTDB.dbo.FirstComTable VALUES ('AAA','BBB','CCC')
GO 5
INSERT INTO TESTDB2.dbo.FirstComTable VALUES ('AAA','BBB','CCC')
GO 5
INSERT INTO TESTDB.dbo.FirstComTable VALUES ('DDD','EEE','FFF')
GO Сега средата за тестване е готова да започне да описва методите за сравнение на данни и схеми.
Сравнете данни на таблици с помощта на LEFT JOIN
Ключовата дума LEFT JOIN T-SQL се използва за извличане на данни от две таблици, като връща всички записи от лявата таблица и само съвпадащите записи от дясната таблица и NULL стойности от дясната таблица, когато няма съвпадение между двете таблици.
За целите на сравнението на данни ключовата дума LEFT JOIN може да се използва за сравняване на две таблици въз основа на общата уникална колона, като колоната ID в нашия случай, както в оператора SELECT по-долу:
SELECT * FROM TESTDB.dbo.FirstComTable F LEFT JOIN TESTDB2.dbo.FirstComTable S ON F.ID =S.ID
Предишната заявка ще върне общите пет реда, съществуващи в двете таблици, в допълнение към реда, който съществува в първата таблица и липсва във втората, като покаже NULL стойности от дясната страна на резултата, както е показано по-долу:
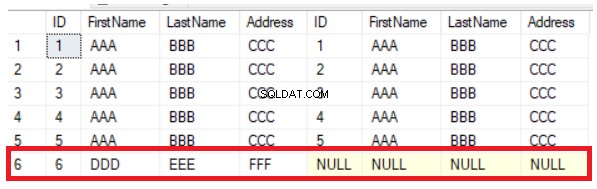
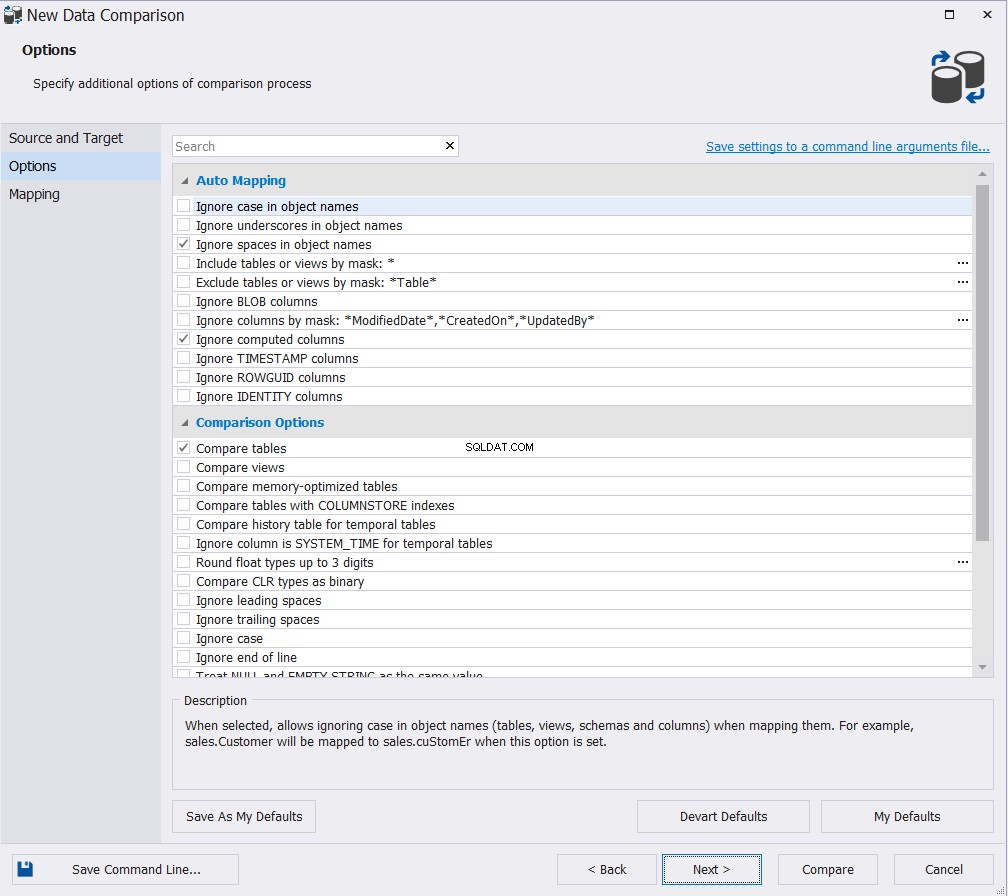
Можете лесно да извлечете от предишния резултат, че шестата колона, която съществува в първата таблица, е пропусната от втората таблица. За да синхронизирате редовете между таблиците, трябва ръчно да вмъкнете новия запис във втората таблица. Методът LEFT JOIN е полезен при проверка на новите редове, но няма да помогне в случай на актуализиране на стойностите на колоните. Ако промените стойността на колоната за адрес на 5-ия ред, методът LEFT JOIN няма да открие тази промяна, както е показано ясно по-долу:
Сравнете данни на таблици с помощта на клауза EXCEPT
Инструкцията EXCEPT връща редовете от първата заявка (лява заявка), които не са върнати от втората заявка (дясна заявка). С други думи, операторът EXCEPT ще върне разликата между два израза SELECT или таблици, което ни помага лесно да сравним данните в тези таблици.
Изразът EXCEPT може да се използва за сравняване на данните в предварително създадените таблици, като вземем разликата между заявката SELECT * от първата таблица и заявката SELECT * от втората таблица, използвайки T-SQL изразите по-долу:
SELECT * FROM TESTDB.dbo.FirstComTable F EXCEPT SELECT * FROM TESTDB2.dbo. FirstComTable S
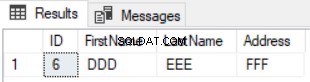
Резултатът от предишната заявка ще бъде редът, който е наличен в първата таблица и не е наличен във втората, както е показано по-долу:
Използването на оператора EXCEPT за сравнение на две таблици е по-добро от оператора LEFT JOIN, тъй като актуализираните записи ще бъдат уловени в резултата от разликите в данните. Да приемем, че сме актуализирали адреса на ред номер 5 във втората таблица и проверихме разликата с помощта на оператор EXCEPT отново, ще видите, че ред номер 5 ще бъде върнат с резултатите от разликите, както е показано по-долу:
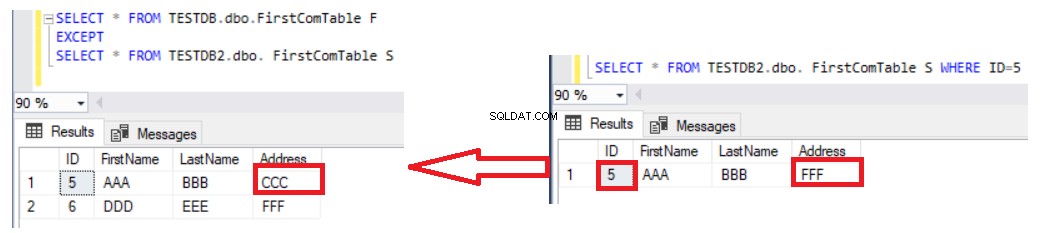
Единственият недостатък на използването на оператора EXCEPT за сравняване на данните в две таблици е, че трябва да синхронизирате данните ръчно, като напишете оператор INSERT за липсващите записи във втората таблица. Вземете под внимание, че двете таблици, които се сравняват, са таблици с ключове, за да получите правилния резултат, с уникален ключ, използван за сравнение. Ако премахнем уникалната колона за идентификатор от оператора SELECT и в двете страни на израза EXCEPT и изброим останалите колони, които не са ключови, както е в изявлението по-долу:
SELECT FirstName, LastName, Address FROM TESTDB.dbo. FirstComTable F EXCEPT SELECT FirstName, LastName, Address FROM TESTDB2.dbo. FirstComTable S
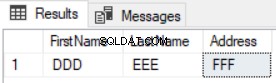
Резултатът ще покаже, че се връщат само новите записи, а актуализираните няма да бъдат изброени, както е показано в резултата по-долу:
Сравнете данни от таблици с помощта на UNION ALL ... GROUP BY
Инструкцията UNION ALL може да се използва и за сравняване на данните в две таблици въз основа на уникална ключова колона. За да използвате израза UNION ALL за връщане на разликата между две таблици, трябва да посочите колоните за сравнение в оператора SELECT и да използвате тези колони в клаузата GROUP BY, както е показано в T-SQL заявката по-долу:
SELECT DISTINCT *
FROM
(
SELECT * FROM
( SELECT * FROM TESTDB.dbo. FirstComTable
UNION ALL
SELECT * FROM TESTDB2.dbo. FirstComTable) Tbls
GROUP BY ID,FirstName, LastName, Address
HAVING COUNT(*)<2) Diff И само редът, който съществува в първата таблица и е пропуснат от втората таблица, ще бъде върнат, както е показано по-долу:
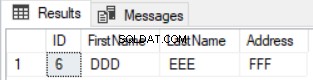
Предишната заявка също ще работи добре в случай на актуализиране на записи, но по различен начин. Той ще върне нововмъкнатите записи в допълнение към актуализираните колони от двете таблици, както в случая на ред номер 5, показан по-долу:
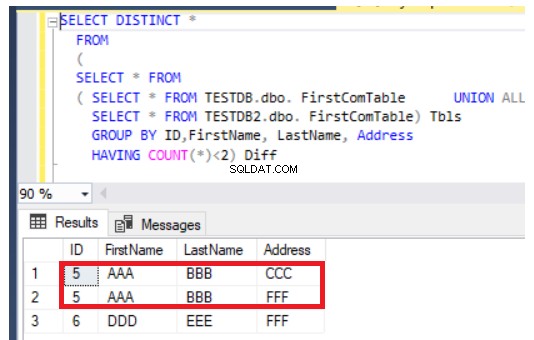
Сравнете данни от таблици с помощта на инструменти за данни на SQL Server
Инструментите за данни на SQL Server, известни също като SSDT, изградени върху Microsoft Visual Studio, могат лесно да се използват за сравняване на данните в две таблици с едно и също име, въз основа на уникална ключова колона, хоствана в две различни бази данни и синхронизиране на данните в тези таблици , или генерирайте скрипт за синхронизиране, който да се използва по-късно.
От отворения прозорец SSDT щракнете върху менюто Инструменти -> списък на SQL Server и изберетеНово сравнение на данни опция, както е показано по-долу:
В показания прозорец за връзка можете да изберете от свързаните по-рано сесии или да попълните прозореца Свойства на връзката с името на SQL Server, идентификационните данни и името на базата данни, след което щракнете върху Свързване , както е показано по-долу:

В показания съветник за ново сравнение на данни посочете имената на изходната и целевата база данни и опциите за сравнение, използвани в процеса на сравнение на таблици, след което щракнете върху Напред , както е показано по-долу:
В следващия прозорец посочете името на таблицата, което трябва да е едно и също име в изходната и целевата база данни, която ще се сравнява и в двете бази данни и щракнете върхуКрай , както по-долу:
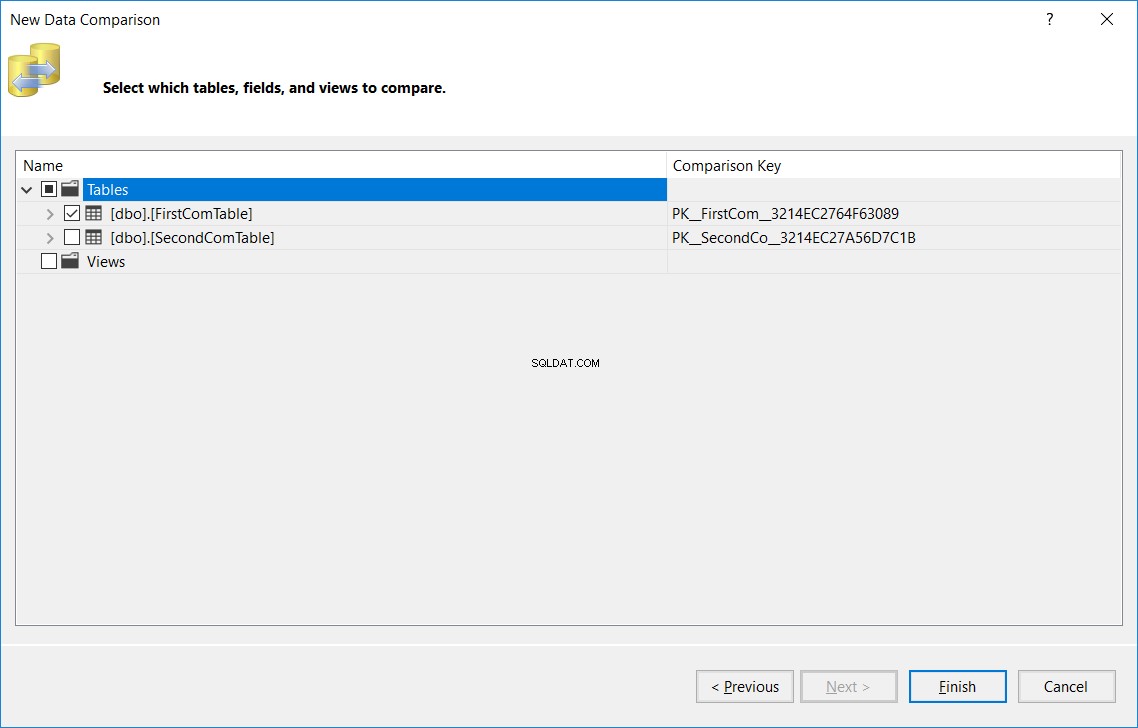
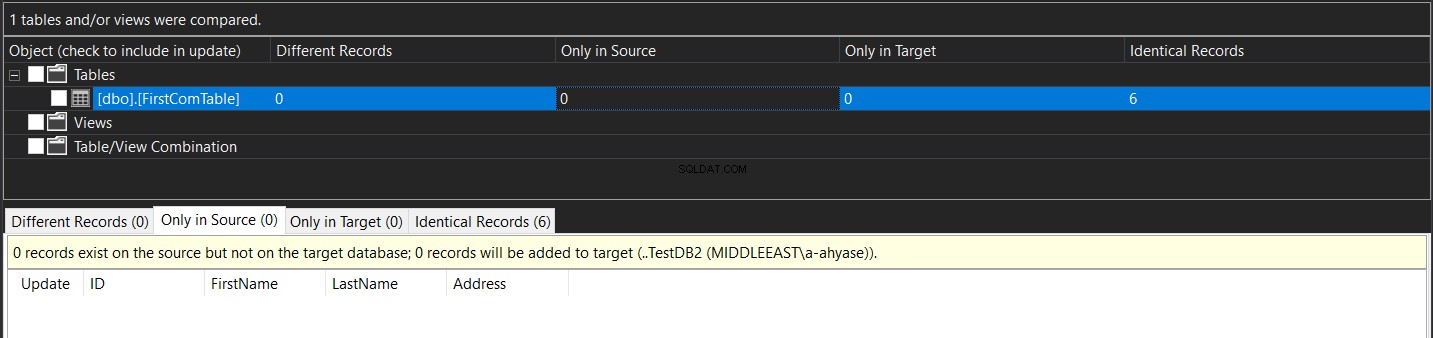
Показаният резултат ще ви покаже броя на записите, които са намерени в източника и пропуснати от целевия, намерени в целта и пропуснати от източника, броя на актуализираните записи със същия ключ и различни стойности на колони (Различни записи) и накрая броя на идентичните записи, намерени в двете таблици, както е показано по-долу:
Щракнете върху името на таблицата в предишния резултат, ще намерите подробен изглед на тези констатации, както е показано по-долу:

Можете да използвате същия инструмент, за да генерирате скрипт за синхронизиране на изходната и целевата таблица или да актуализирате целевата таблица директно с липсващите или различни промени, както е показано по-долу:
Ако щракнете върху опцията Генериране на скрипт, ще се покаже оператор INSERT с липсващата колона в целевата таблица, както е показано по-долу:
ЗАПОЧНЕТЕ TRANSACTION
BEGIN TRANSACTION SET IDENTITY_INSERT [dbo].[FirstComTable] ON INSERT INTO [dbo].[FirstComTable] ([ID], [FirstName], [LastName], [Address]) VALUES (6, N'DDD', N'EEE', N'FFF') SET IDENTITY_INSERT [dbo].[FirstComTable] OFF COMMIT TRANSACTION
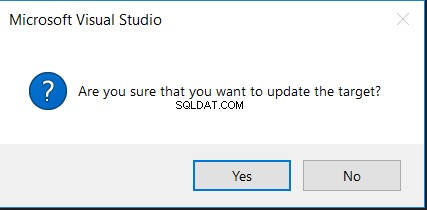
Избирането на опцията Update Target ще ви помоли първо за вашето потвърждение за извършване на промяната, както е в съобщението по-долу:
След синхронизирането ще видите, че данните в двете таблици ще бъдат идентични, както е показано по-долу:
Сравнете данните на таблици с помощта на инструмента на трети страни “dbForge Studio for SQL Server”
В света на SQL Server можете да намерите голям брой инструменти на трети страни, които улесняват живота на администраторите и разработчиците на бази данни. Един от тези инструменти, които правят задачите за администриране на база данни безпроблемни, е dbForge Studio за SQL Server, който ни предоставя лесни начини за изпълнение на задачите за администриране и разработка на база данни. Този инструмент може също да ни помогне да сравняваме данните в таблиците на базата данни и да синхронизираме тези таблици.
От менюто Сравнение изберете Ново сравнение на данни опция, както е показано по-долу:
От съветника за ново сравнение на данни посочете изходната и целевата база данни, след което щракнете върху Напред :
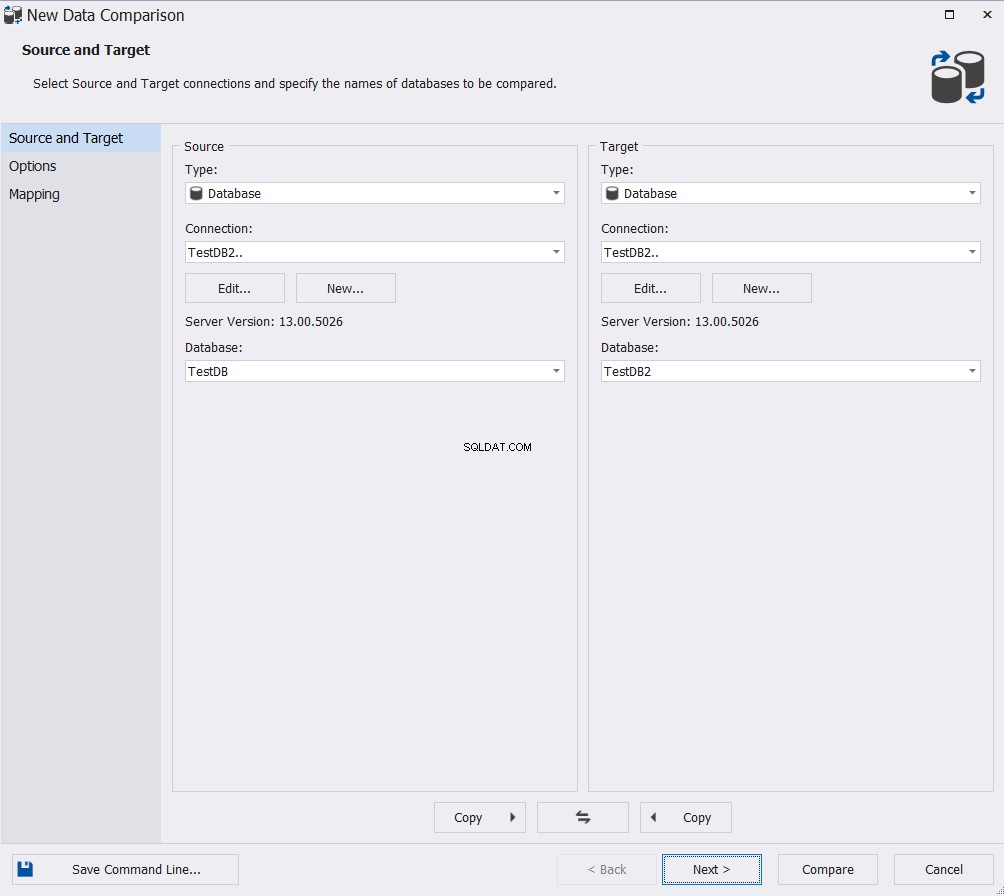
Изберете подходящите опции от широката гама налични опции за картографиране и сравнение и щракнете върху Напред :
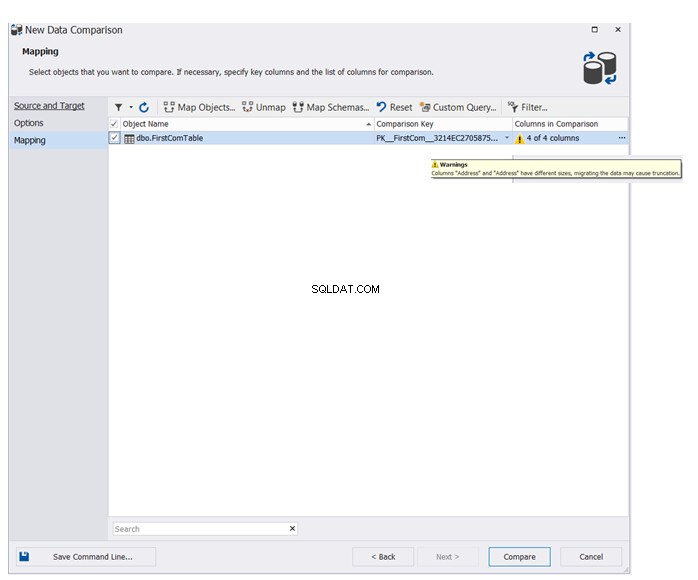
Посочете името на таблицата или таблиците, които ще участват в процеса на сравнение на данни. Помощникът ще покаже предупредително съобщение в случай, че има някакви разлики в схемата между таблиците на изходната и целевата база данни. Кликнете върху Сравни за да продължите:
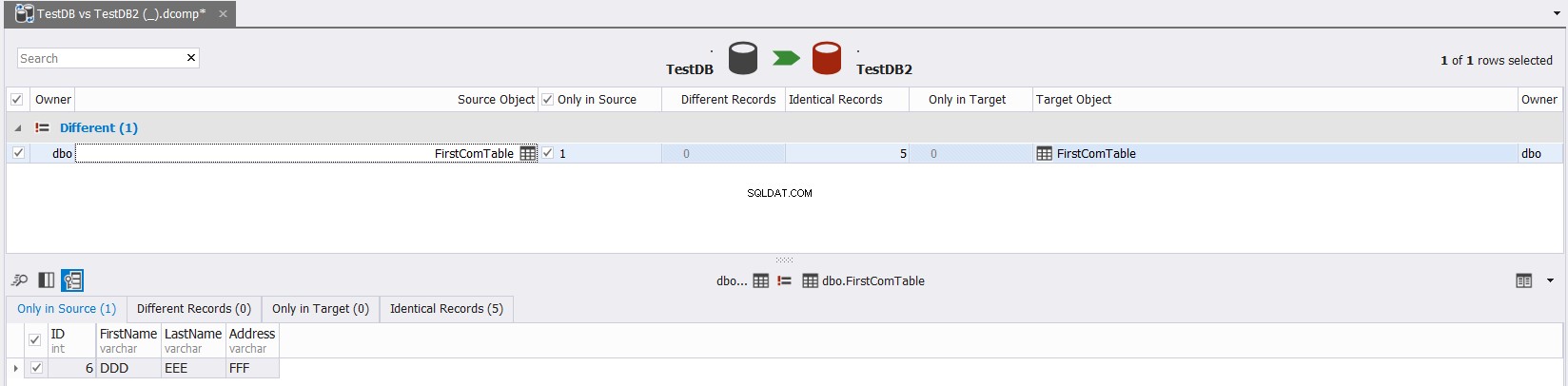
Крайният резултат ще ви покаже в детайли разликите в данните между изходната и целевата таблица, с възможност за щракване  за синхронизиране на таблиците източник и местоназначение, както е показано по-долу:
за синхронизиране на таблиците източник и местоназначение, както е показано по-долу:
Сравнете схемата на таблици с помощта на sys.columns
Както бе споменато в началото на тази статия, за да репликирате или архивирате таблица, трябва да се уверите, че схемата на изходната и целевата таблица е идентична. SQL Server ни предоставя различни начини за сравняване на схемата на таблиците в една и съща база данни или различни бази данни. Първият метод е запитване в изгледа на системния каталог sys.columns, който връща един ред за всяка колона на обект, който има колона, със свойствата на всяка колона.
За да сравните схемата на таблиците, разположени в различни бази данни, трябва да предоставите на sys.columns името на таблицата под текущата база данни, без да можете да предоставите таблица, хоствана в друга база данни. За да постигнем това, ще направим заявка към sys.columns два пъти, ще запазим резултата от всяка заявка във временна таблица и накрая ще сравним резултата от тези две заявки с помощта на командата EXCEPT T-SQL, както е показано ясно по-долу:
USE TESTDB SELECT name, system_type_id, user_type_id,max_length, precision,scale, is_nullable, is_identity INTO #DBSchema FROM sys.columns WHERE object_id = OBJECT_ID(N'dbo.FirstComTable') GO USE TestDB2 GO SELECT name, system_type_id, user_type_id,max_length, precision,scale, is_nullable, is_identity INTO #DB2Schema FROM sys.columns WHERE object_id = OBJECT_ID(N'dbo.FirstComTable '); GO SELECT * FROM #DBSchema EXCEPT SELECT * FROM #DB2Schema
Резултатът ще ни покаже, че дефиницията на колоната Адрес е различна в тези две таблици, без конкретна информация за точната разлика, както е показано по-долу:

Сравнете схемата на таблици с помощта на INFORMATION_SCHEMA.COLUMNS
Системният изглед INFORMATION_SCHEMA.COLUMNS може също да се използва за сравняване на схемата на различни таблици, като се предостави името на таблицата. Отново, за да сравним две таблици, хоствани в различни бази данни, ще поискаме INFORMATION_SCHEMA.COLUMNS два пъти, ще запазим резултата от всяка заявка във временна таблица и накрая ще сравним резултата от тези две заявки с помощта на командата EXCEPT T-SQL, както е показано ясно по-долу:
USE TestDB SELECT COLUMN_NAME, IS_NULLABLE,DATA_TYPE,CHARACTER_MAXIMUM_LENGTH, NUMERIC_PRECISION,NUMERIC_SCALE INTO #DBSchema FROM [INFORMATION_SCHEMA].[COLUMNS] SC1 WHERE SC1.TABLE_NAME='FirstComTable' GO USE TestDB2 SELECT COLUMN_NAME, IS_NULLABLE,DATA_TYPE,CHARACTER_MAXIMUM_LENGTH, NUMERIC_PRECISION,NUMERIC_SCALE INTO #DB2Schema FROM [INFORMATION_SCHEMA].[COLUMNS] SC2 WHERE SC2.TABLE_NAME='FirstComTable' GO SELECT * FROM #DBSchema EXCEPT SELECT * FROM #DB2Schema
И резултатът ще бъде някак подобен на предишния, показвайки, че дефиницията на колоната за адрес е различна в тези две таблици, без конкретна информация за точната разлика, както е показано по-долу:

Сравнете схемата на таблици с помощта на dm_exec_describe_first_result_set
Схемите на таблиците могат също да бъдат сравнени чрез запитване на функцията за динамично управление dm_exec_describe_first_result_set, която приема Transact-SQL оператор като параметър и описва метаданните на първия набор от резултати за израза.
За да сравните схемата на две таблици, трябва да се присъедините към dm_exec_describe_first_result_set DMF със себе си, като предоставите израза SELECT от всяка таблица като параметър, както в T-SQL заявката по-долу:
SELECT FT.name , ST.name , FT.system_type_name , ST.system_type_name , FT.max_length , ST.max_length , FT.precision , ST.precision , FT.scale , ST.scale , FT.is_nullable , ST.is_nullable , FT.is_identity_column , ST.is_identity_column FROM sys.dm_exec_describe_first_result_set (N'SELECT * FROM TestDB.DBO.FirstComTable', NULL, 0) FT LEFT OUTER JOIN sys.dm_exec_describe_first_result_set (N'SELECT * FROM TestDB2.DBO.FirstComTable', NULL, 0) ST ON FT.Name =ST.Name GO
Този път резултатът ще бъде по-ясен, тъй като можете да сравните на око разликата между двете таблици, тоест размера и типа на колоната Адрес, както е показано по-долу:

Сравнете схемата на таблици с помощта на инструменти за данни на SQL Server
Инструментите за данни на SQL Server могат да се използват и за сравняване на схемата на таблици, разположени в различни бази данни. Под менюто Инструменти изберете Ново сравнение на схема опция от списъка с опции на SQL Server, както е показано по-долу:
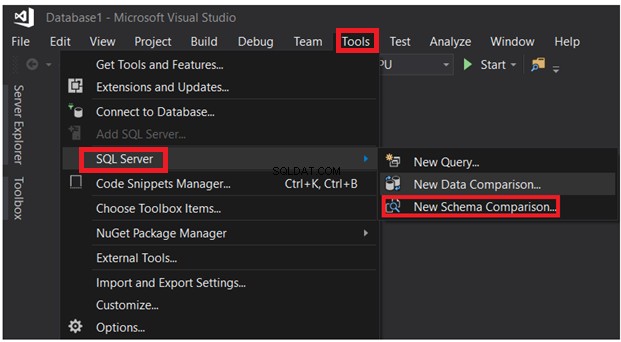
След като предоставите параметрите на връзката, щракнете върху бутона Сравни:

Резултатът от сравнението ще ви покаже по-конкретно разликата в схемата между двете таблици под формата на команди CREATE TABLE T-SQL, засенчени, както е на снимката по-долу:
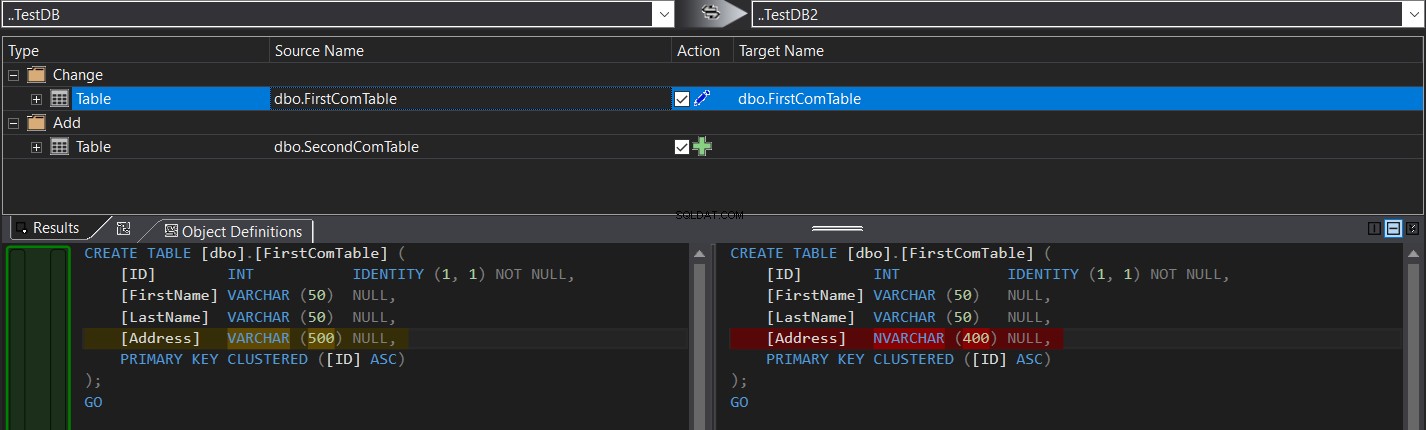
Можете лесно да щракнете  , за да синхронизирате схемата на таблицата или щракнете върху
, за да синхронизирате схемата на таблицата или щракнете върху  , за да напишете промяната и да я извършите по-късно, както е показано по-долу:
, за да напишете промяната и да я извършите по-късно, както е показано по-долу:
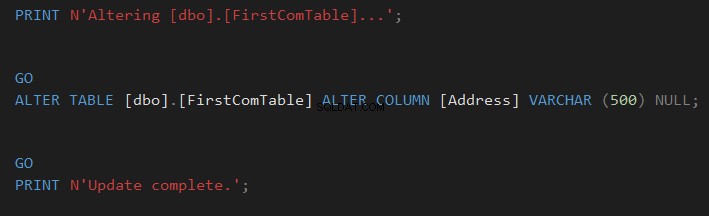
Сравнете схемата на таблици с помощта на инструмента на трети страни dbForge Studio за SQL Server
Инструментът dbForge Studio за SQL Server ни предоставя възможността да сравняваме схемата на различните таблици на базата данни. От менюто Сравнение изберете Ново сравнение на схема опция, както е по-долу:
След като посочите свойствата на връзката както на изходната, така и на целевата база данни, изберете подходящата опция за съпоставяне от наличните опции и щракнете върху Напред :
Изберете схемите, с които ще сравните неговия обект, и щракнете върху Напред :
Посочете таблицата или таблиците, които ще участват в процеса на сравнение на схемите и щракнете върху Сравни , ако искате да пропуснете промяната на настройките по подразбиране в прозореца Обектен филтър, както е по-долу:
Показаният резултат за сравнение ще ви покаже разликата между схемата на двете таблици, като точно подчертае частта от типа данни, която се различава между двете колони, с възможността да укажете какво действие трябва да се направи, за да се синхронизират двете таблици, както е показано по-долу :
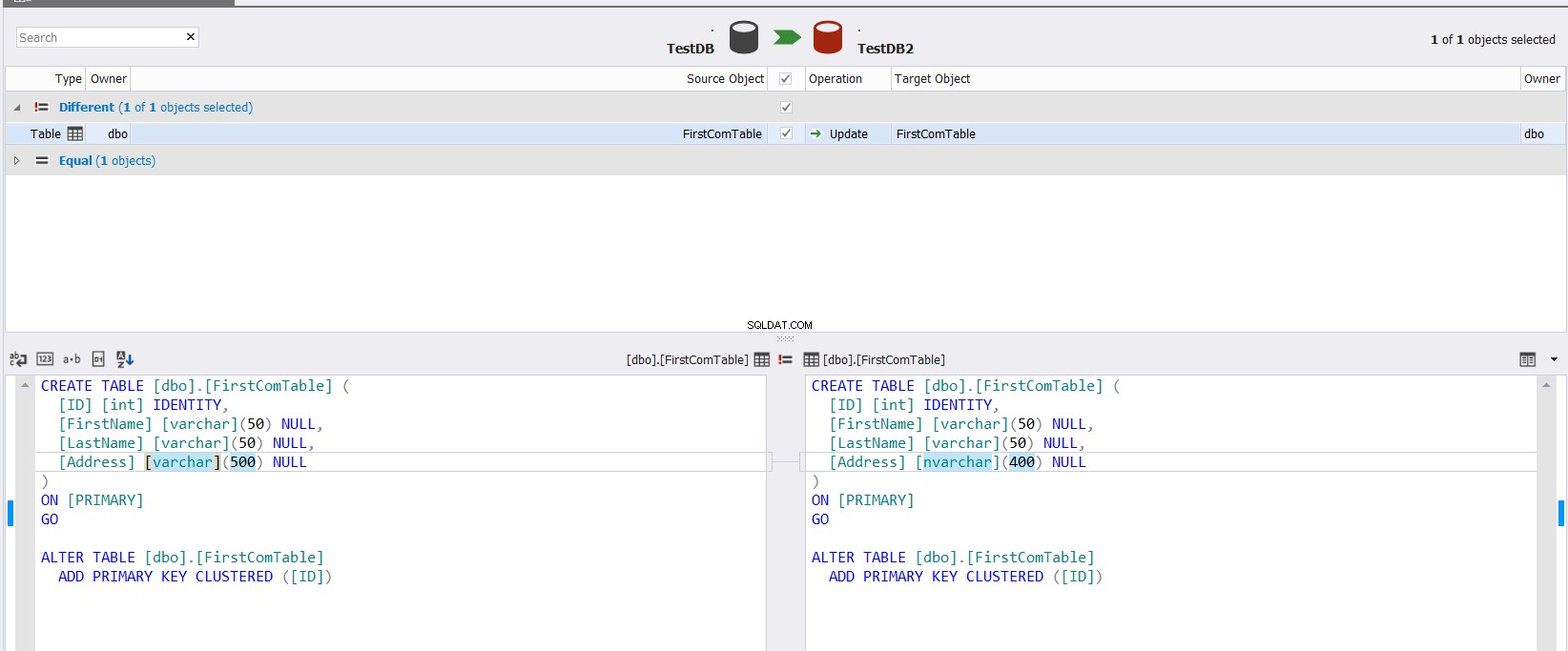
Ако уредите да синхронизирате схемата на двете таблици, щракнете върху бутона и посочете в съветника за синхронизиране на схема дали успеете да изпълните промяната директно върху целевата таблица или просто да я напишете, за да се използва в бъдеще, както е по-долу:
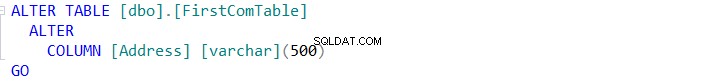
Полезни връзки:
- Задаване на оператори – EXCEPT и INTERSECT (Transact-SQL)
- Оператори за набор – UNION (Transact-SQL)
- Изтеглете SQL Server Data Tools (SSDT)
- Сравнете и синхронизирайте данни в една или повече таблици с данни в референтна база данни
- sys.dm_exec_describe_first_result_set (Transact-SQL)
- sys.columns (Transact-SQL)
- Изгледи на схемата за системна информация (Transact-SQL)
Полезни инструменти:
dbForge Schema Compare за SQL Server – надежден инструмент, който спестява вашето време и усилия при сравняване и синхронизиране на бази данни на SQL Server.
dbForge Data Compare за SQL Server – мощен инструмент за сравнение на SQL, способен да работи с големи данни.