Един от най-популярните начини за постигане на висока наличност за MySQL е репликацията. Репликацията съществува от много години и стана много по-стабилна с въвеждането на GTID. Но дори и с тези подобрения, процесът на репликация може да прекъсне поради различни причини - например, когато главен и подчинен не са синхронизирани, защото записите са изпратени директно на подчинения. Как отстранявате проблеми с репликацията и как ги поправяте?
В тази публикация в блога ще обсъдим някои от често срещаните проблеми с репликацията и как да ги коригираме с ClusterControl. Нека започнем с първия.
Репликацията спря с някаква грешка
Повечето администратори на база данни на MySQL обикновено срещат такъв проблем поне веднъж в кариерата си. По различни причини подчинен може да се повреди или може би да спре да синхронизира с главния. Когато това се случи, първото нещо, което трябва да направите, за да започнете отстраняването на неизправности, е да проверите дневника за грешки за съобщения. През повечето време съобщението за грешка може лесно да се проследи в регистъра за грешки или чрез изпълнение на заявката SHOW SLAVE STATUS.
Нека да разгледаме следния пример от SHOW STATUS SLAVE:
********** 0. row **********
Slave_IO_State:
Master_Host: 10.2.9.71
Master_User: cmon_replication
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000111
Read_Master_Log_Pos: 255477362
Relay_Log_File: relay-bin.000001
Relay_Log_Pos: 4
Relay_Master_Log_File: binlog.000111
Slave_IO_Running: No
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 255477362
Relay_Log_Space: 256
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master:
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 1236
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'Could not find GTID state requested by slave in any binlog files. Probably the slave state is too old and required binlog files have been purged.'
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1000
Master_SSL_Crl:
Master_SSL_Crlpath:
Using_Gtid: Slave_Pos
Gtid_IO_Pos: 1000-1000-2268440
Replicate_Do_Domain_Ids:
Replicate_Ignore_Domain_Ids:
Parallel_Mode: optimistic
SQL_Delay: 0
SQL_Remaining_Delay:
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Slave_DDL_Groups: 0
Slave_Non_Transactional_Groups: 0
Slave_Transactional_Groups: 0Можем ясно да видим, че грешката е свързана с Получих фатална грешка 1236 от главния при четене на данни от двоичен дневник:„Не можа да се намери GTID състояние, поискано от подчинен в нито един binlog файлове. Вероятно подчиненото състояние е твърде старо и необходимите binlog файлове са изчистени.'. С думи, това, което грешката ни казва по същество е, че има несъответствие в данните и необходимите двоични регистрационни файлове вече са изтрити.
Това е един добър пример, когато процесът на репликация спира да работи. Освен ПОКАЗВАНЕ НА СТАТУС НА СЛАВЕТО, можете също да проследявате състоянието в раздела „Преглед“ на клъстера в ClusterControl. И така, как да поправите това с ClusterControl? Имате две възможности да опитате:
-
Можете да опитате да стартирате подчинения отново от „Действие на възел“
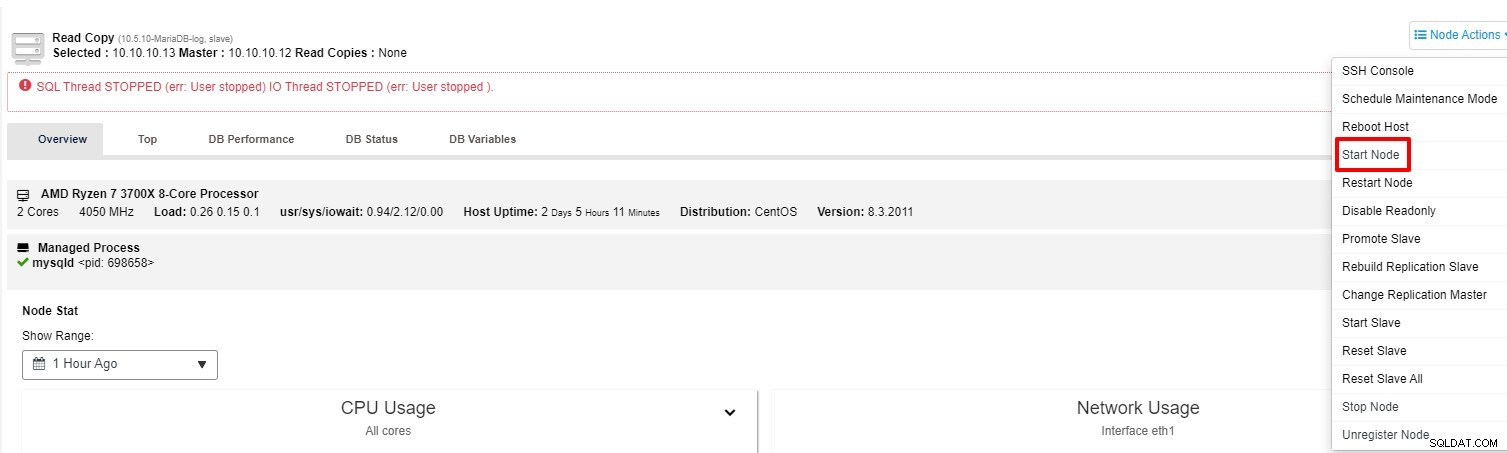
-
Ако ведомото устройство все още не работи, можете да стартирате задание „Rebuild Replication Slave“ от „Действие на възел“
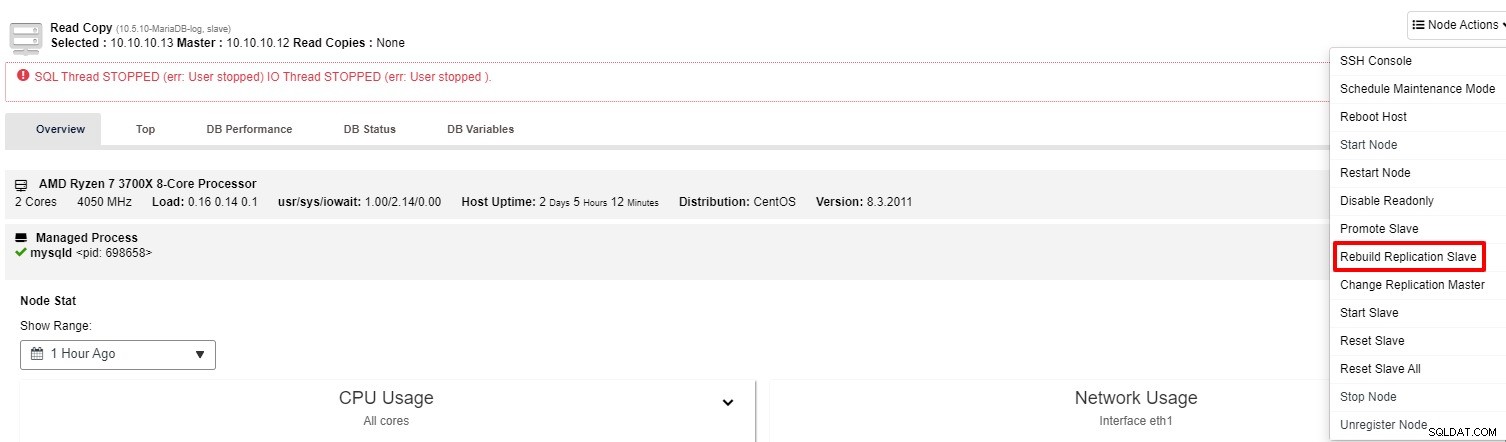
През повечето време втората опция ще реши проблема. ClusterControl ще направи резервно копие на главния и ще възстанови повредения подчинен, като възстанови данните. След като данните бъдат възстановени, подчиненият е свързан с главния, за да може да навакса.
Има също множество ръчни начина за възстановяване на подчинен, както е изброено по-долу, можете също да се обърнете към тази връзка за повече подробности:
-
Използване на Mysqldump за повторно изграждане на непоследователен MySQL Slave
-
Използване на Mydumper за повторно изграждане на непоследователен MySQL Slave
-
Използване на моментна снимка за повторно изграждане на непоследователно подчинено устройство на MySQL
-
Използване на Xtrabackup или Mariabackup за повторно изграждане на непоследователно MySQL Slave
Повишете роба да стане господар
С течение на времето ОС или базата данни трябва да бъдат коригирани или надстроени, за да се поддържа стабилност и сигурност. Една от най-добрите практики за минимизиране на времето за престой, особено за голяма надстройка, е насърчаването на един от подчинените за овладяване, след като надстройката е била успешно извършена на този конкретен възел.
Изпълнявайки това, можете да насочите приложението си към новия главен и главен-подчинен репликация ще продължи да работи. Междувременно можете спокойно да продължите с надстройката на стария мастер. С ClusterControl това може да се изпълни с няколко щраквания, само ако се приеме, че репликацията е конфигурирана като базирана на глобален идентификатор на транзакция или накратко базирана на GTID. За да избегнете загуба на данни, си струва да спрете всички заявки за приложения, в случай че старият главен файл работи правилно. Това не е единствената ситуация, в която можете да повишите роба. В случай, че главният възел не работи, можете също да извършите това действие.
Без ClusterControl има няколко стъпки за популяризиране на подчинения. Всяка от стъпките изисква и няколко заявки за изпълнение:
-
Ръчно сваляне на главния
-
Изберете най-напредналия подчинен да бъде главен и го подгответе
-
Свържете отново други подчинени устройства към новия главен обект
-
Промяна на стария хозяин да бъде подчинен
Въпреки това, стъпките за популяризиране на подчинен с ClusterControl са само с няколко щраквания:Cluster> Nodes> изберете slave node> Promote Slave според екранната снимка по-долу:
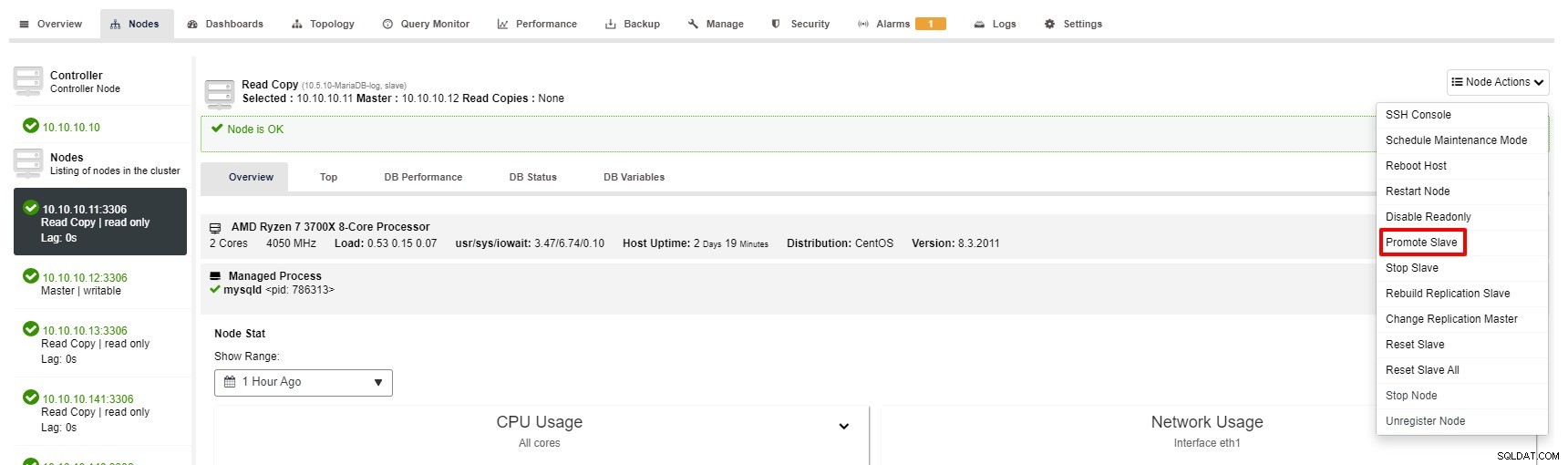
Главният става недостъпен
Представете си, че имате големи транзакции за изпълнение, но базата данни не работи. Няма значение колко сте внимателни, това е може би най-сериозната или критична ситуация за настройка на репликация. Когато това се случи, вашата база данни не може да приеме нито едно записване, което е лошо. Освен това, вашето приложение(а), разбира се, няма да работи правилно.
Има няколко причини или причини, които водят до този проблем. Някои от примерите са хардуерна повреда, повреда на ОС, повреда на базата данни и така нататък. Като DBA, трябва да действате бързо, за да възстановите главната база данни.
Благодарение на клъстерната функция „Автоматично възстановяване“, която е налична в ClusterControl, процесът на отказ може да бъде автоматизиран. Може да се активира или деактивира с едно щракване. Както казва името, това, което ще направи, е да изведе цялата топология на клъстера, когато е необходимо. Например, репликация главен-подчинен трябва да има поне един жив главен във всеки даден момент, независимо от броя на наличните подчинени устройства. Когато главният не е наличен, той автоматично ще повиши един от подчинените.
Нека да разгледаме екранната снимка по-долу:
На горната екранна снимка можем да видим, че „Автоматично възстановяване“ е активирано както за клъстер, така и за възел. В топологията забележете, че текущият главен IP адрес е 10.10.10.11. Какво ще се случи, ако свалим главния възел за тестване?
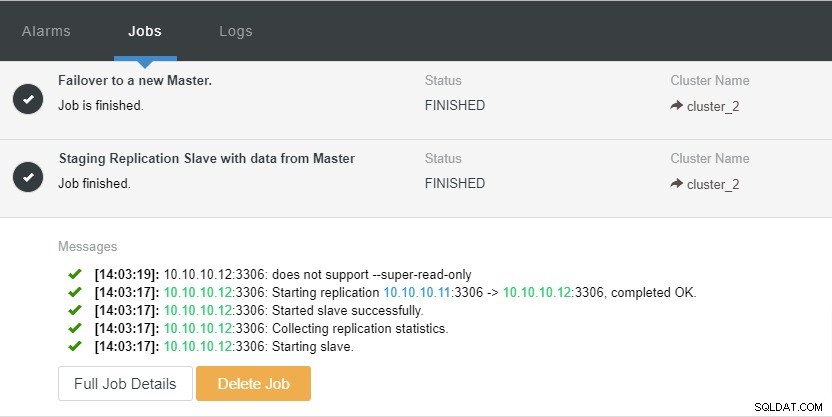
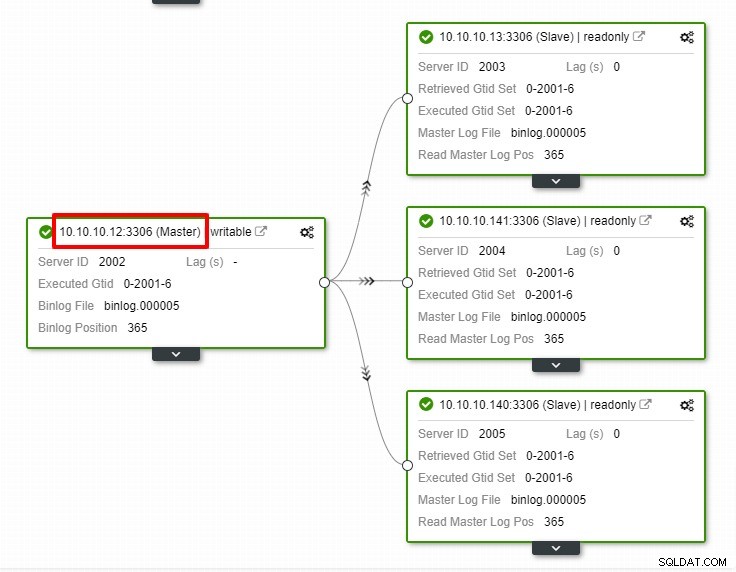
Както можете да видите, подчинения възел с IP 10.10.10.12 е автоматично повишен в главен, така че топологията на репликация да бъде преконфигурирана. Вместо да го правите ръчно, което, разбира се, ще включва много стъпки, ClusterControl ви помага да поддържате настройката си за репликация, като сваля неприятностите от ръцете ви.
Заключение
При всяко нежелано събитие с вашата репликация, корекцията е много проста и по-малко караница с ClusterControl. ClusterControl ви помага бързо да възстановите проблемите си с репликацията, което увеличава времето за работа на вашите бази данни.