Това е четвъртата част от поредицата за решения на предизвикателството за генериране на числови серии. Много благодаря на Алън Бърщайн, Джо Оббиш, Адам Мачаник, Кристофър Форд, Джеф Модън, Чарли, НоамГр, Камил Косно, Дейв Мейсън, Джон Нелсън #2, Ед Вагнер, Майкъл Бърбеа и Пол Уайт за споделянето на вашите идеи и коментари.
Обичам работата на Пол Уайт. Продължавам да съм шокиран от откритията му и се чудя как, по дяволите, разбира какво прави. Харесвам и неговия ефективен и красноречив стил на писане. Често, докато чета неговите статии или публикации, поклащам глава и казвам на жена си Лилач, че когато порасна, искам да бъда като Пол.
Когато първоначално публикувах предизвикателството, тайно се надявах, че Пол ще публикува решение. Знаех, че ако го направи, ще бъде много специално. Е, той го направи и това е очарователно! Той има отлична производителност и има доста неща, които можете да научите от него. Тази статия е посветена на решението на Пол.
Ще направя тестовете си в tempdb, като активирам I/O и статистика за времето:
SET NOCOUNT ON; USE tempdb; SET STATISTICS TIME, IO ON;
Ограничения на по-ранни идеи
Оценявайки по-ранните решения, един от важните фактори за постигане на добра производителност беше способността да се използва пакетна обработка. Но използвахме ли го във възможно най-голяма степен?
Нека разгледаме плановете за две от по-ранните решения, които използваха пакетна обработка. В част 1 разгледах функцията dbo.GetNumsAlanCharlieItzikBatch, която комбинира идеи от Алън, Чарли и мен.
Ето дефиницията на функцията:
-- Helper dummy table
DROP TABLE IF EXISTS dbo.BatchMe;
GO
CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
GO
-- Function definition
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum;
GO Това решение дефинира конструктор на базова таблица със стойности с 16 реда и серия от каскадни CTE с кръстосани съединения за увеличаване на броя на редовете до потенциално 4B. Решението използва функцията ROW_NUMBER, за да създаде основната последователност от числа в CTE, наречена Nums, и ТОП филтъра за филтриране на желаната мощност на серия от числа. За да активира пакетната обработка, решението използва фиктивно ляво присъединяване с фалшиво условие между Nums CTE и таблица, наречена dbo.BatchMe, която има индекс на columnstore.
Използвайте следния код, за да тествате функцията с техниката за присвояване на променлива:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Изображението на Plan Explorer на действителното планът за това изпълнение е показан на фигура 1.
 Фигура 1:План за функция dbo.GetNumsAlanCharlieItzikBatch
Фигура 1:План за функция dbo.GetNumsAlanCharlieItzikBatch
Когато анализирате пакетен режим срещу обработка в редов режим, е доста хубаво да можете да разберете само като погледнете план на високо ниво кой режим на обработка е използвал всеки оператор. Всъщност Plan Explorer показва светлосиня партидна фигура в долната лява част на оператора, когато действителният му режим на изпълнение е Пакет. Както можете да видите на фигура 1, единственият оператор, който използва пакетен режим, е операторът Window Aggregate, който изчислява номерата на редовете. Все още има много работа, свършена от други оператори в режим на ред.
Ето числата за ефективност, които получих в моя тест:
Време на процесора =10032 ms, изминало време =10025 ms.логически чете 0
За да определите кои оператори са отнели най-много време за изпълнение, използвайте опцията за действителен план за изпълнение в SSMS или опцията за получаване на действителен план в Plan Explorer. Уверете се, че сте прочели скорошната статия на Пол Разбиране на времето на оператора на план за изпълнение. Статията описва как да нормализирате отчетените времена за изпълнение на оператора, за да получите правилните числа.
В плана на Фигура 1 по-голямата част от времето се изразходва от най-левите оператори Nested Loops и Top, като и двата се изпълняват в режим на ред. Освен че редовият режим е по-малко ефективен от пакетния режим за процесорно интензивни операции, имайте предвид също, че превключването от редов към пакетен режим и обратно отнема допълнително.
В част 2 разгледах друго решение, което използва пакетна обработка, реализирана във функцията dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2. Това решение комбинира идеи от Джон Номер2, Дейв Мейсън, Джо Оббиш, Алън, Чарли и мен. Основната разлика между предишното решение и това е, че като базова единица, първото използва конструктор на виртуална стойност на таблица, а второто използва действителна таблица с индекс на columnstore, което ви дава пакетна обработка „безплатно“. Ето кода, който създава таблицата и я попълва с помощта на оператор INSERT със 102 400 реда, за да бъде компресиран:
DROP TABLE IF EXISTS dbo.NullBits102400;
GO
CREATE TABLE dbo.NullBits102400
(
b BIT NULL,
INDEX cc_NullBits102400 CLUSTERED COLUMNSTORE
WITH (DATA_COMPRESSION = COLUMNSTORE_ARCHIVE)
);
GO
WITH
L0 AS (SELECT CAST(NULL AS BIT) AS b
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) AS D(b)),
L1 AS (SELECT A.b FROM L0 AS A CROSS JOIN L0 AS B),
nulls(b) AS (SELECT A.b FROM L1 AS A CROSS JOIN L1 AS B CROSS JOIN L1 AS C)
INSERT INTO dbo.NullBits102400 WITH (TABLOCK) (b)
SELECT TOP(102400) b FROM nulls;
GO Ето дефиницията на функцията:
CREATE OR ALTER FUNCTION dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2
(@low AS BIGINT = 1, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM dbo.NullBits102400 AS A
CROSS JOIN dbo.NullBits102400 AS B)
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums
ORDER BY rownum;
GO Едно кръстосано свързване между две копия на основната таблица е достатъчно, за да произведе много над желания потенциал от 4B реда. Отново тук решението използва функцията ROW_NUMBER, за да произведе основната последователност от числа и ТОП филтъра, за да ограничи желаната мощност на серия от числа.
Ето кода за тестване на функцията с помощта на техниката за присвояване на променлива:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2(1, 100000000) OPTION(MAXDOP 1);
Планът за това изпълнение е показан на Фигура 2.
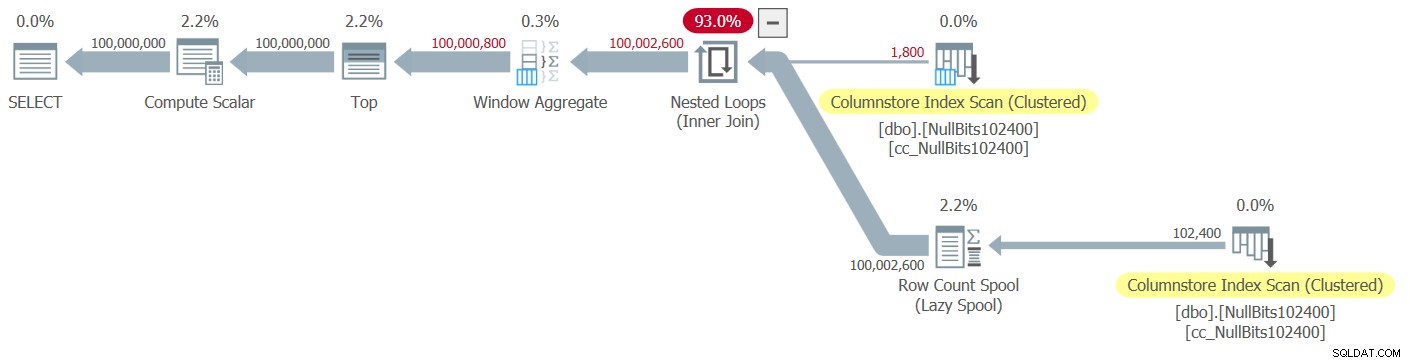 Фигура 2:План за функция dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2
Фигура 2:План за функция dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2
Обърнете внимание, че само два оператора в този план използват пакетен режим — най-горното сканиране на клъстерирания индекс на columnstore на таблицата, който се използва като външен вход на присъединяването на вложените цикли, и операторът Window Aggregate, който се използва за изчисляване на номерата на основните редове .
Получих следните показатели за ефективност за моя тест:
Време на процесора =9812 мс, изминало време =9813 мс.Таблица „NullBits102400“. Брой на сканиране 2, логическо четене 0, физическо четене 0, сървър на страницата чете 0, четене напред 0, сървър за страница чете напред 0, логически четене на лоб 8, физическо четене на лоб 0, сървър на лоб страница чете 0, четене на лоб- напред чете 0, сървърът на лоб страница чете напред чете 0.
Таблица „NullBits102400“. Сегментът чете 2, сегментът е пропуснат 0.
Отново, по-голямата част от времето при изпълнението на този план се изразходва от най-левите оператори вложени цикли и Топ, които се изпълняват в режим на ред.
Решението на Павел
Преди да представя решението на Пол, ще започна с моята теория относно мисловния процес, през който е преминал. Това всъщност е страхотно учебно упражнение и ви предлагам да преминете през него, преди да разгледате решението. Пол разпозна изтощителните ефекти на план, който смесва както пакетен, така и редов режим, и постави предизвикателство пред себе си да излезе с решение, което получава план за пакетен режим. Ако е успешно, потенциалът за добро представяне на такова решение е доста голям. Със сигурност е интригуващо да се види дали такава цел е дори постижима, като се има предвид, че все още има много оператори, които все още не поддържат пакетен режим и много фактори, които възпрепятстват пакетната обработка. Например, към момента на писане, единственият алгоритъм за присъединяване, който поддържа пакетна обработка, е алгоритъмът за хеш присъединяване. Кръстосаното свързване се оптимизира с помощта на алгоритъма за вложени цикли. Освен това операторът Top в момента се изпълнява само в редов режим. Тези два елемента са критични основни елементи, използвани в плановете за много от решенията, които разгледах досега, включително горните две.
Ако приемем, че сте поставили предизвикателството да създадете решение с план за пакетен режим, приличен опит, нека да продължим към второто упражнение. Първо ще представя решението на Пол, както го е предоставил, с неговите вградени коментари. Също така ще го стартирам, за да сравня неговата производителност с другите решения. Научих много, като деконструирах и реконструирах неговото решение, стъпка по стъпка, за да се уверя, че внимателно разбирам защо е използвал всяка от техниките, които е правил. Предлагам ви да направите същото, преди да продължите да четете моите обяснения.
Ето решението на Пол, което включва помощна таблица с колони, наречена dbo.CS и функция, наречена dbo.GetNums_SQLkiwi:
-- Helper columnstore table
DROP TABLE IF EXISTS dbo.CS;
-- 64K rows (enough for 4B rows when cross joined)
-- column 1 is always zero
-- column 2 is (1...65536)
SELECT
-- type as integer NOT NULL
-- (everything is normalized to 64 bits in columnstore/batch mode anyway)
n1 = ISNULL(CONVERT(integer, 0), 0),
n2 = ISNULL(CONVERT(integer, N.rn), 0)
INTO dbo.CS
FROM
(
SELECT
rn = ROW_NUMBER() OVER (ORDER BY @@SPID)
FROM master.dbo.spt_values AS SV1
CROSS JOIN master.dbo.spt_values AS SV2
ORDER BY
rn ASC
OFFSET 0 ROWS
FETCH NEXT 65536 ROWS ONLY
) AS N;
-- Single compressed rowgroup of 65,536 rows
CREATE CLUSTERED COLUMNSTORE INDEX CCI
ON dbo.CS
WITH (MAXDOP = 1);
GO
-- The function
CREATE OR ALTER FUNCTION dbo.GetNums_SQLkiwi
(
@low bigint = 1,
@high bigint
)
RETURNS table
AS
RETURN
SELECT
N.rn,
n = @low - 1 + N.rn,
op = @high + 1 - N.rn
FROM
(
SELECT
-- Use @@TRANCOUNT instead of @@SPID if you like all your queries serial
rn = ROW_NUMBER() OVER (ORDER BY @@SPID ASC)
FROM dbo.CS AS N1
JOIN dbo.CS AS N2
-- Batch mode hash cross join
-- Integer not null data type avoid hash probe residual
-- This is always 0 = 0
ON N2.n1 = N1.n1
WHERE
-- Try to avoid SQRT on negative numbers and enable simplification
-- to single constant scan if @low > @high (with literals)
-- No start-up filters in batch mode
@high >= @low
-- Coarse filter:
-- Limit each side of the cross join to SQRT(target number of rows)
-- IIF avoids SQRT on negative numbers with parameters
AND N1.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, IIF(@high >= @low, @high - @low + 1, 0)))))
AND N2.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, IIF(@high >= @low, @high - @low + 1, 0)))))
) AS N
WHERE
-- Precise filter:
-- Batch mode filter the limited cross join to the exact number of rows needed
-- Avoids the optimizer introducing a row-mode Top with following row mode compute scala
@low - 2 + N.rn < @high;
GO Ето кода, който използвах, за да тествам функцията с техниката за присвояване на променлива:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNums_SQLkiwi(1, 100000000);
Получих плана, показан на фигура 3, за моя тест.
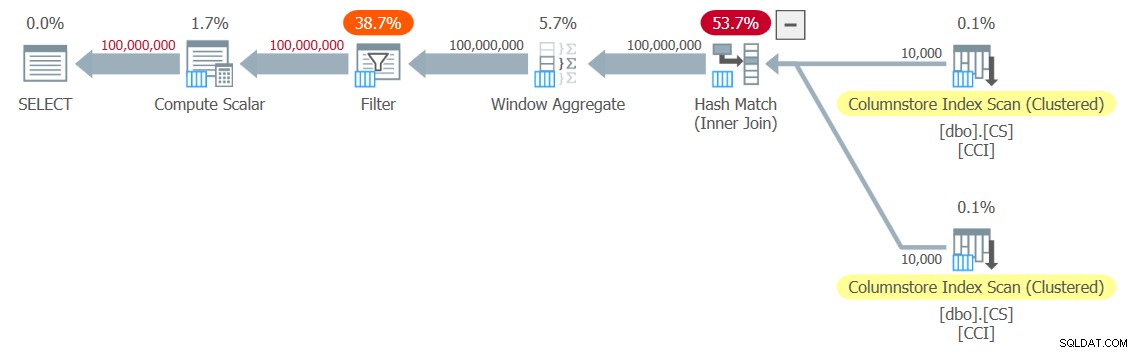 Фигура 3:План за функция dbo.GetNums_SQLkiwi
Фигура 3:План за функция dbo.GetNums_SQLkiwi
Това е план за пакетен режим! Това е доста впечатляващо.
Ето числата за производителност, които получих за този тест на моята машина:
Време на процесора =7812 мс, изминало време =7876 мс.Таблица „CS“. Брой на сканиране 2, логическо четене 0, физическо четене 0, сървър на страници чете 0, четене напред 0, сървър за четене напред чете 0, логически четения на лоб 44, физическо четене на лоб 0, сървър на лоб страница чете 0, четене на лоб- напред чете 0, сървърът на лоб страница чете напред чете 0.
Таблица „CS“. Сегментът чете 2, сегментът е пропуснат 0.
Нека също така да проверим, че ако трябва да върнете числата, подредени по n, решението е запазване на реда по отношение на rn – поне когато използвате константи като входни данни – и по този начин избягвате изричното сортиране в плана. Ето кода, за да го тествате с поръчка:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNums_SQLkiwi(1, 100000000) ORDER BY n;
Получавате същия план като на Фигура 3 и следователно подобни номера на ефективността:
Време на процесора =7765 ms, изминало време =7822 ms.Таблица „CS“. Брой на сканиране 2, логическо четене 0, физическо четене 0, сървър на страници чете 0, четене напред 0, сървър за четене напред чете 0, логически четения на лоб 44, физическо четене на лоб 0, сървър на лоб страница чете 0, четене на лоб- напред чете 0, сървърът на лоб страница чете напред чете 0.
Таблица „CS“. Сегментът чете 2, сегментът е пропуснат 0.
Това е важна страна на решението.
Промяна на методологията ни за тестване
Производителността на решението на Paul е прилично подобрение както на изминалото време, така и на процесорното време в сравнение с двете предишни решения, но не изглежда като по-драматично подобрение, което може да се очаква от план с пълен пакетен режим. Може би пропускаме нещо?
Нека се опитаме да анализираме времето за изпълнение на оператора, като разгледаме действителния план за изпълнение в SSMS, както е показано на фигура 4.
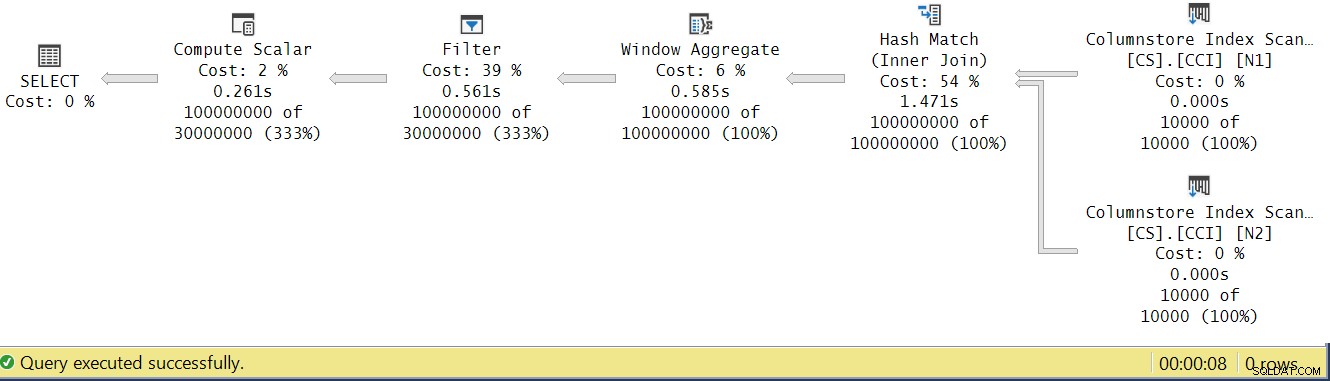 Фигура 4:Времена за изпълнение на оператора за функцията dbo.GetNums_SQLkiwi
Фигура 4:Времена за изпълнение на оператора за функцията dbo.GetNums_SQLkiwi
В статията на Пол относно анализирането на времето за изпълнение на оператора той обяснява, че при пакетен режим всеки от операторите отчита своето собствено време за изпълнение. Ако сумирате времената за изпълнение на всички оператори в този действителен план, ще получите 2,878 секунди, но изпълнението на плана отне 7,876. 5 секунди от времето за изпълнение изглежда липсват. Отговорът на това се крие в техниката за тестване, която използваме, с присвояването на променливата. Припомнете си, че решихме да използваме тази техника, за да елиминираме необходимостта от изпращане на всички редове от сървъра към повикващия и да избегнем I/O, които биха участвали в записването на резултата в таблица. Изглеждаше идеалният вариант. Въпреки това, истинската цена на присвояването на променливата е скрита в този план и, разбира се, тя се изпълнява в режим на ред. Мистерията е решена.
Очевидно в края на деня добрият тест е тест, който отразява адекватно вашето производствено използване на решението. Ако обикновено записвате данните в таблица, трябва вашият тест да отрази това. Ако изпратите резултата на обаждащия се, имате нужда от вашия тест, за да отрази това. Във всеки случай присвояването на променлива изглежда представлява голяма част от времето за изпълнение в нашия тест и очевидно е малко вероятно да представлява типично производствено използване на функцията. Пол предложи, че вместо присвояване на променлива, тестът може да приложи обикновен агрегат като MAX към върнатата числова колона (n/rn/op). Един обобщен оператор може да използва пакетна обработка, така че планът няма да включва преобразуване от пакетен режим в ред в резултат на използването му, а приносът му към общото време на изпълнение трябва да бъде сравнително малък и известен.
Така че нека тестваме отново и трите решения, обхванати в тази статия. Ето кода за тестване на функцията dbo.GetNumsAlanCharlieItzikBatch:
SELECT MAX(n) AS mx FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Получих плана, показан на фигура 5 за този тест.
 Фигура 5:План за dbo.GetNumsAlanCharlieItzikBatch функция с агрегат
Фигура 5:План за dbo.GetNumsAlanCharlieItzikBatch функция с агрегат
Ето числата за ефективност, които получих за този тест:
Време на процесора =8469 мс, изминало време =8733 мс.логически чете 0
Забележете, че времето за изпълнение е спаднало от 10,025 секунди с помощта на техниката за присвояване на променлива до 8,733 с помощта на агрегатната техника. Това е малко повече от секунда време за изпълнение, което можем да припишем на присвояването на променливата тук.
Ето кода за тестване на функцията dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2:
SELECT MAX(n) AS mx FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2(1, 100000000) OPTION(MAXDOP 1);
Получих плана, показан на фигура 6 за този тест.
 Фигура 6:План за dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2 функция
Фигура 6:План за dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2 функция
Ето числата за ефективност, които получих за този тест:
Време на процесора =7031 ms, изминало време =7053 ms.Таблица „NullBits102400“. Брой на сканиране 2, логическо четене 0, физическо четене 0, сървър на страницата чете 0, четене напред 0, сървър за страница чете напред 0, логически четене на лоб 8, физическо четене на лоб 0, сървър на лоб страница чете 0, четене на лоб- напред чете 0, сървърът на лоб страница чете напред чете 0.
Таблица „NullBits102400“. Сегментът чете 2, сегментът е пропуснат 0.
Забележете, че времето за изпълнение е спаднало от 9,813 секунди с помощта на техниката за присвояване на променлива до 7,053 с помощта на агрегатната техника. Това е малко повече от две секунди време за изпълнение, което можем да припишем на присвояването на променливата тук.
А ето и кода за тестване на решението на Пол:
SELECT MAX(n) AS mx FROM dbo.GetNums_SQLkiwi(1, 100000000) OPTION(MAXDOP 1);
Получавам плана, показан на фигура 7 за този тест.
 Фигура 7:План за функция dbo.GetNums_SQLkiwi с агрегат
Фигура 7:План за функция dbo.GetNums_SQLkiwi с агрегат
И сега за големия момент. Получих следните показатели за ефективност за този тест:
Време на процесора =3125 мс, изминало време =3149 мс.Таблица „CS“. Брой на сканиране 2, логическо четене 0, физическо четене 0, сървър на страници чете 0, четене напред 0, сървър за четене напред чете 0, логически четения на лоб 44, физическо четене на лоб 0, сървър на лоб страница чете 0, четене на лоб- напред чете 0, сървърът на лоб страница чете напред чете 0.
Таблица „CS“. Сегментът чете 2, сегментът е пропуснат 0.
Времето за изпълнение спадна от 7,822 секунди на 3,149 секунди! Нека разгледаме времето за изпълнение на оператора в действителния план в SSMS, както е показано на фигура 8.
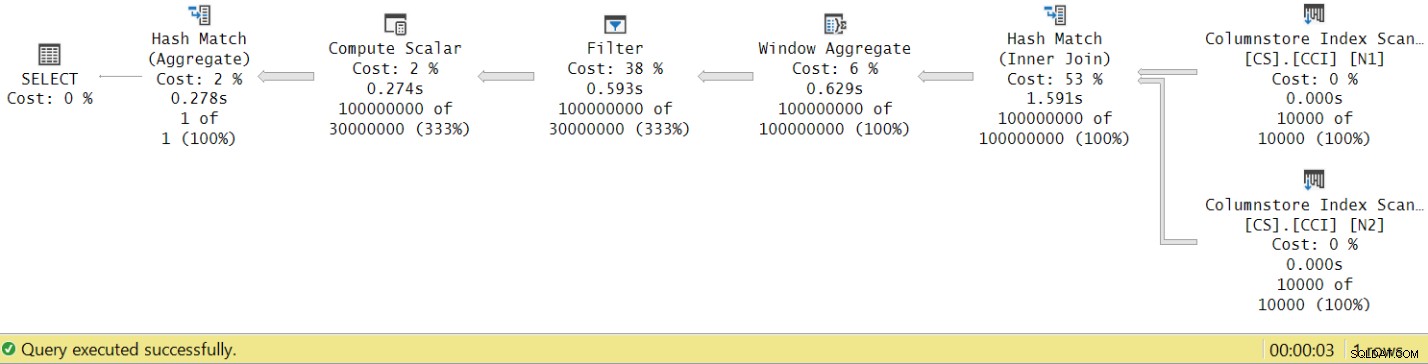 Фигура 8:Времена за изпълнение на оператора за функция dbo.GetNums с агрегат
Фигура 8:Времена за изпълнение на оператора за функция dbo.GetNums с агрегат
Сега, ако натрупате времената за изпълнение на отделните оператори, ще получите число, подобно на общото време за изпълнение на плана.
Фигура 9 има сравнение на производителността по отношение на изминалото време между трите решения, използвайки както техниките за присвояване на променлива, така и техниките за обобщено тестване.
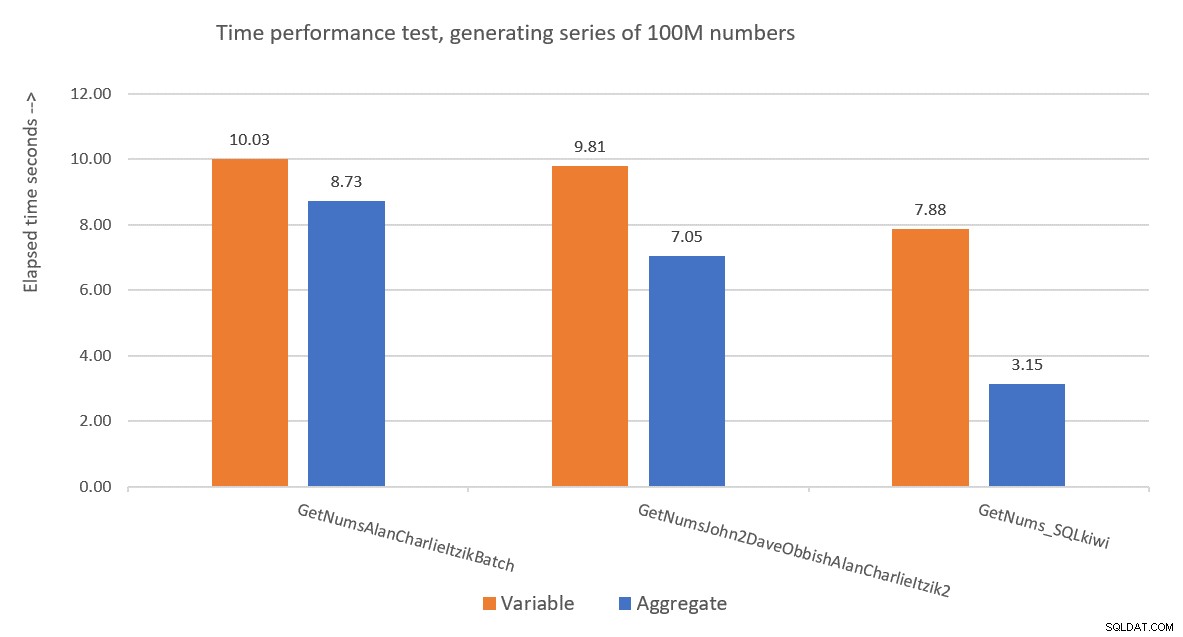 Фигура 9:Сравнение на производителността
Фигура 9:Сравнение на производителността
Решението на Пол е ясен победител и това е особено очевидно, когато се използва техниката за обобщено тестване. Какъв впечатляващ подвиг!
Деконструиране и реконструкция на решението на Павел
Деконструирането и след това реконструирането на решението на Пол е страхотно упражнение и можете да научите много, докато го правите. Както беше предложено по-рано, препоръчвам ви да преминете през процеса сами, преди да продължите да четете.
Първият избор, който трябва да направите, е техниката, която бихте използвали, за да генерирате желания потенциален брой редове от 4B. Пол избра да използва таблица с columnstore и да я попълни с толкова редове, колкото е корен квадратен от необходимото число, което означава 65 536 реда, така че с едно кръстосано свързване да получите необходимото число. Може би си мислите, че с по-малко от 102 400 реда няма да получите компресирана група редове, но това важи, когато попълвате таблицата с оператор INSERT, както направихме с таблицата dbo.NullBits102400. Не се прилага, когато създавате индекс на columnstore в предварително попълнена таблица. Така че Пол използва оператор SELECT INTO, за да създаде и попълни таблицата като базирана на rowstore купчина с 65 536 реда и след това създаде клъстериран индекс на columnstore, което води до компресирана група от редове.
Следващото предизвикателство е да разберете как да получите кръстосано присъединяване, което да бъде обработено с оператор на пакетен режим. За целта ви трябва алгоритъмът за присъединяване да бъде хеш. Не забравяйте, че кръстосаното свързване е оптимизирано с помощта на алгоритъма за вложени цикли. Някак си трябва да подмамите оптимизатора да си помисли, че използвате вътрешно equijoin (хешът изисква поне един предикат, базиран на равенство), но на практика получите кръстосано присъединяване.
Очевиден първи опит е да се използва вътрешно присъединяване с предикат за изкуствено присъединяване, който винаги е вярно, така:
SELECT *
FROM dbo.CS AS N1
INNER HASH JOIN dbo.CS AS N2
ON 0 = 0; Но този код се проваля със следната грешка:
Съобщение 8622, ниво 16, състояние 1, ред 246Обработчикът на заявки не можа да създаде план на заявка поради намеците, дефинирани в тази заявка. Изпратете отново заявката, без да указвате никакви намеци и без да използвате SET FORCEPLAN.
Оптимизаторът на SQL Server разпознава, че това е изкуствен предикат за вътрешно присъединяване, опростява вътрешното присъединяване до кръстосано присъединяване и генерира грешка, казвайки, че не може да поеме намек за принудително използване на алгоритъм за хеш присъединяване.
За да разреши това, Пол създаде колона INT NOT NULL (повече за това защо тази спецификация скоро), наречена n1 в своята таблица dbo.CS, и я попълни с 0 във всички редове. След това той използва предиката за свързване N2.n1 =N1.n1, като ефективно получава предложението 0 =0 във всички оценки на съвпадението, като същевременно спазва минималните изисквания за алгоритъм за хеш присъединяване.
Това работи и създава план за пакетен режим:
SELECT *
FROM dbo.CS AS N1
INNER HASH JOIN dbo.CS AS N2
ON N2.n1 = N1.n1; Що се отнася до причината n1 да се дефинира като INT NOT NULL; защо да забраните NULL и защо да не използвате BIGINT? Причината за тези избори е да се избегне остатъчен хеш сонда (допълнителен филтър, който се прилага от оператора на хеш присъединяване извън оригиналния предикат за свързване), което може да доведе до допълнителни ненужни разходи. Вижте статията на Пол Присъединяване на производителност, неявни преобразувания и остатъци за подробности. Ето частта от статията, която е от значение за нас:
„Ако присъединяването е в една колона, въведена като tinyint, smallint или integer и ако и двете колони са ограничени да бъдат НЕ NULL, хеш функцията е „перфектна“ – което означава, че няма шанс за хеш сблъсък и процесорът на заявки не трябва да проверява стойностите отново, за да се увери, че наистина съвпадат.Обърнете внимание, че тази оптимизация не се прилага за bigint колони."
За да проверим този аспект, нека създадем друга таблица, наречена dbo.CS2 с nullable n1 колона:
DROP TABLE IF EXISTS dbo.CS2; SELECT * INTO dbo.CS2 FROM dbo.CS; ALTER TABLE dbo.CS2 ALTER COLUMN n1 INT NULL; CREATE CLUSTERED COLUMNSTORE INDEX CCI ON dbo.CS2 WITH (MAXDOP = 1);
Нека първо тестваме заявка срещу dbo.CS (където n1 е дефинирано като INT NOT NULL), генерирайки 4B номера на основни редове в колона, наречена rn, и прилагайки MAX агрегата към колоната:
SELECT
mx = MAX(N.rn)
FROM
(
SELECT
rn = ROW_NUMBER() OVER (ORDER BY @@TRANCOUNT ASC)
FROM dbo.CS AS N1
JOIN dbo.CS AS N2
ON N2.n1 = N1.n1
) AS N; Ще сравним плана за тази заявка с плана за подобна заявка срещу dbo.CS2 (където n1 е дефинирано като INT NULL):
SELECT
mx = MAX(N.rn)
FROM
(
SELECT
rn = ROW_NUMBER() OVER (ORDER BY @@TRANCOUNT ASC)
FROM dbo.CS2 AS N1
JOIN dbo.CS2 AS N2
ON N2.n1 = N1.n1
) AS N; Плановете и за двете заявки са показани на Фигура 10.
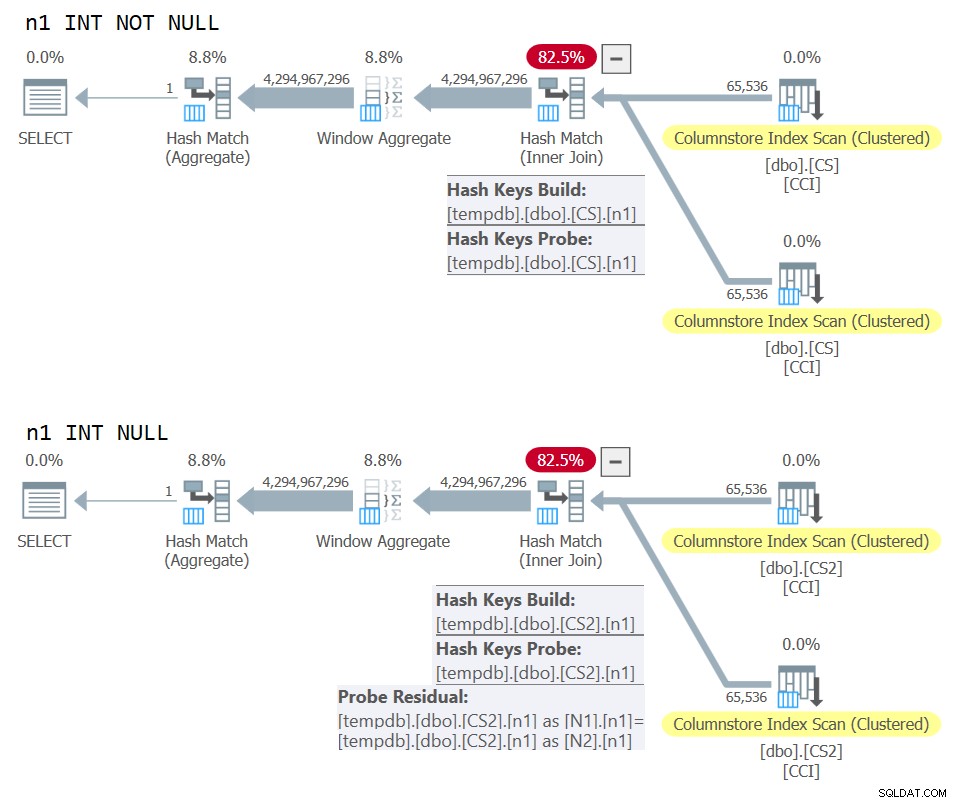 Фигура 10:Сравнение на планове за NOT NULL срещу NULL ключ за присъединяване
Фигура 10:Сравнение на планове за NOT NULL срещу NULL ключ за присъединяване
Можете ясно да видите допълнителния остатък от сондата, който се прилага във втория план, но не и в първия.
На моята машина заявката към dbo.CS завърши за 91 секунди, а заявката към dbo.CS2 завърши за 92 секунди. В статията на Пол той съобщава за 11% разлика в полза на случая NOT NULL за примера, който използва.
BTW, тези от вас с набито око ще са забелязали използването на ORDER BY @@TRANCOUNT като спецификация за подреждане на функцията ROW_NUMBER. Ако внимателно прочетете вградените коментари на Пол в неговото решение, той споменава, че използването на функцията @@TRANCOUNT е инхибитор на паралелизма, докато използването на @@SPID не е. Така че можете да използвате @@TRANCOUNT като времева константа на изпълнение в спецификацията за поръчка, когато искате да наложите сериен план и @@SPID, когато не го правите.
Както споменахме, на заявката срещу dbo.CS бяха необходими 91 секунди, за да се изпълни на моята машина. В този момент може да е интересно да се тества същия код с истинско кръстосано свързване, като се позволи на оптимизатора да използва алгоритъм за присъединяване на вложени цикли в режим на ред:
SELECT
mx = MAX(N.rn)
FROM
(
SELECT
rn = ROW_NUMBER() OVER (ORDER BY @@TRANCOUNT ASC)
FROM dbo.CS AS N1
CROSS JOIN dbo.CS AS N2
) AS N; Завършването на този код отне 104 секунди на моята машина. Така че получаваме значително подобрение на производителността с хеш присъединяването в пакетен режим.
Следващият ни проблем е фактът, че когато използвате TOP за филтриране на желания брой редове, получавате план с оператор Top в режим на ред. Ето опит за внедряване на функцията dbo.GetNums_SQLkiwi с TOP филтър:
CREATE OR ALTER FUNCTION dbo.GetNums_SQLkiwi
(
@low bigint = 1,
@high bigint
)
RETURNS table
AS
RETURN
SELECT
N.rn,
n = @low - 1 + N.rn,
op = @high + 1 - N.rn
FROM
(
SELECT TOP (100000000 - 1 + 1)
rn = ROW_NUMBER() OVER (ORDER BY @@SPID ASC)
FROM dbo.CS AS N1
JOIN dbo.CS AS N2
ON N2.n1 = N1.n1
ORDER BY rn
) AS N;
GO Нека тестваме функцията:
SELECT MAX(n) FROM dbo.GetNums_SQLkiwi(1, 100000000);
Получих плана, показан на фигура 11 за този тест.
 Фигура 11:Планиране с ТОП филтър
Фигура 11:Планиране с ТОП филтър
Обърнете внимание, че операторът Top е единственият в плана, който използва обработка в режим на ред.
Получих следната статистика за времето за това изпълнение:
Процесорно време =6078 ms, изминало време =6071 ms.По-голямата част от времето за изпълнение в този план се изразходва от оператора Top в режим на ред и от факта, че планът трябва да премине през пакетно преобразуване в режим на ред и обратно.
Предизвикателството ни е да намерим алтернатива за филтриране в пакетен режим на TOP в редов режим. Филтрите, базирани на предикати, като тези, приложени с клаузата WHERE, потенциално могат да се обработват с пакетна обработка.
Подходът на Пол беше да въведе втора колона, въведена от INT (вижте вградения коментар „все пак всичко е нормализирано до 64-битово в columnstore/batch режим“ ) извиква n2 към таблицата dbo.CS и я попълва с целочислената последователност от 1 до 65,536. В кода на решението той използва два филтъра, базирани на предикати. Единият е груб филтър във вътрешната заявка с предикати, включващи колоната n2 от двете страни на съединението. Този груб филтър може да доведе до някои фалшиви положителни резултати. Ето първия опростен опит за такъв филтър:
WHERE
-- Coarse filter:
N1.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, @high - @low + 1))))
AND N2.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, @high - @low + 1)))) С входовете 1 и 100 000 000 като @low и @high не получавате фалшиви положителни резултати. Но опитайте с 1 и 100 000 001 и ще получите малко. Ще получите последователност от 100 020 001 числа вместо 100 000 001.
За да премахне фалшивите положителни резултати, Пол добави втори, прецизен филтър, включващ колоната rn във външната заявка. Ето първия опростен опит за такъв прецизен филтър:
WHERE
-- Precise filter:
N.rn < @high - @low + 2 Нека преразгледаме дефиницията на функцията, за да използваме горните филтри, базирани на предикати вместо TOP, вземем 1:
CREATE OR ALTER FUNCTION dbo.GetNums_SQLkiwi
(
@low bigint = 1,
@high bigint
)
RETURNS table
AS
RETURN
SELECT
N.rn,
n = @low - 1 + N.rn,
op = @high + 1 - N.rn
FROM
(
SELECT
rn = ROW_NUMBER() OVER (ORDER BY @@TRANCOUNT ASC)
FROM dbo.CS AS N1
JOIN dbo.CS AS N2
ON N2.n1 = N1.n1
WHERE
-- Coarse filter:
N1.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, @high - @low + 1))))
AND N2.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, @high - @low + 1))))
) AS N
WHERE
-- Precise filter:
N.rn < @high - @low + 2;
GO Нека тестваме функцията:
SELECT MAX(n) FROM dbo.GetNums_SQLkiwi(1, 100000000);
Получих плана, показан на фигура 12 за този тест.
 Фигура 12:Планирайте с филтър WHERE, вземете 1
Фигура 12:Планирайте с филтър WHERE, вземете 1
Уви, нещо явно се обърка. SQL Server преобразува нашия филтър, базиран на предикатите, включващ колоната rn, в базиран на TOP филтър и го оптимизира с оператор Top – което е точно това, което се опитахме да избегнем. За да добави обида към нараняването, оптимизаторът също реши да използва алгоритъма за вложени цикли за присъединяването.
Отне на този код 18,8 секунди, за да завърши на моята машина. Не изглежда добре.
По отношение на присъединяването на вложени цикли, това е нещо, за което лесно бихме могли да се погрижим с помощта на подсказка за присъединяване във вътрешната заявка. Само за да видите въздействието върху производителността, ето тест с намек за заявка за принудително хеш присъединяване, използван в самата тестова заявка:
SELECT MAX(n) FROM dbo.GetNums_SQLkiwi(1, 100000000) OPTION(HASH JOIN);
Времето за изпълнение намалява до 13,2 секунди.
Все още имаме проблем с преобразуването на филтъра WHERE срещу rn в TOP филтър. Нека се опитаме да разберем как се случи това. Използвахме следния филтър във външната заявка:
WHERE N.rn < @high - @low + 2
Не забравяйте, че rn представлява неманипулиран израз, базиран на ROW_NUMBER. Филтър, базиран на такъв неманипулиран израз, намиращ се в даден диапазон, често се оптимизира с оператор Top, което за нас е лоша новина поради използването на обработка в режим на ред.
Заобиколното решение на Пол беше да използва еквивалентен предикат, но такъв, който прилага манипулация към rn, така:
WHERE @low - 2 + N.rn < @high
Filtering an expression that adds manipulation to a ROW_NUMBER-based expression inhibits the conversion of the predicate-based filter to a TOP-based one. That’s brilliant!
Let’s revise the function’s definition to use the above WHERE predicate, take 2:
CREATE OR ALTER FUNCTION dbo.GetNums_SQLkiwi
(
@low bigint = 1,
@high bigint
)
RETURNS table
AS
RETURN
SELECT
N.rn,
n = @low - 1 + N.rn,
op = @high + 1 - N.rn
FROM
(
SELECT
rn = ROW_NUMBER() OVER (ORDER BY @@TRANCOUNT ASC)
FROM dbo.CS AS N1
JOIN dbo.CS AS N2
ON N2.n1 = N1.n1
WHERE
-- Coarse filter:
N1.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, @high - @low + 1))))
AND N2.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, @high - @low + 1))))
) AS N
WHERE
-- Precise filter:
@low - 2 + N.rn < @high;
GO Test the function again, without any special hints or anything:
SELECT MAX(n) FROM dbo.GetNums_SQLkiwi(1, 100000000);
It naturally gets an all-batch-mode plan with a hash join algorithm and no Top operator, resulting in an execution time of 3.177 seconds. Looking good.
The next step is to check if the solution handles bad inputs well. Let’s try it with a negative delta:
SELECT MAX(n) FROM dbo.GetNums_SQLkiwi(100000000, 1);
This execution fails with the following error.
Msg 3623, Level 16, State 1, Line 436An invalid floating point operation occurred.
The failure is due to the attempt to apply a square root of a negative number.
Paul’s solution involved two additions. One is to add the following predicate to the inner query’s WHERE clause:
@high >= @low
This filter does more than what it seems initially. If you’ve read Paul’s inline comments carefully, you could find this part:
“Try to avoid SQRT on negative numbers and enable simplification to single constant scan if @low> @high (with literals). No start-up filters in batch mode.”The intriguing part here is the potential to use a constant scan with constants as inputs. I’ll get to this shortly.
The other addition is to apply the IIF function to the input expression to the SQRT function. This is done to avoid negative input when using nonconstants as inputs to our numbers function, and in case the optimizer decides to handle the predicate involving SQRT before the predicate @high>=@low.
Before the IIF addition, for example, the predicate involving N1.n2 looked like this:
N1.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, @high - @low + 1))))
After adding IIF, it looks like this:
N1.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, IIF(@high >= @low, @high - @low + 1, 0)))))
With these two additions, we’re now basically ready for the final definition of the dbo.GetNums_SQLkiwi function:
CREATE OR ALTER FUNCTION dbo.GetNums_SQLkiwi
(
@low bigint = 1,
@high bigint
)
RETURNS table
AS
RETURN
SELECT
N.rn,
n = @low - 1 + N.rn,
op = @high + 1 - N.rn
FROM
(
SELECT
-- Use @@TRANCOUNT instead of @@SPID if you like all your queries serial
rn = ROW_NUMBER() OVER (ORDER BY @@SPID ASC)
FROM dbo.CS AS N1
JOIN dbo.CS AS N2
-- Batch mode hash cross join
-- Integer not null data type avoid hash probe residual
-- This is always 0 = 0
ON N2.n1 = N1.n1
WHERE
-- Try to avoid SQRT on negative numbers and enable simplification
-- to single constant scan if @low > @high (with literals)
-- No start-up filters in batch mode
@high >= @low
-- Coarse filter:
-- Limit each side of the cross join to SQRT(target number of rows)
-- IIF avoids SQRT on negative numbers with parameters
AND N1.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, IIF(@high >= @low, @high - @low + 1, 0)))))
AND N2.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, IIF(@high >= @low, @high - @low + 1, 0)))))
) AS N
WHERE
-- Precise filter:
-- Batch mode filter the limited cross join to the exact number of rows needed
-- Avoids the optimizer introducing a row-mode Top with following row mode compute scalar
@low - 2 + N.rn < @high;
GO Now back to the comment about the constant scan. When using constants that result in a negative range as inputs to the function, e.g., 100,000,000 and 1 as @low and @high, after parameter embedding the WHERE filter of the inner query looks like this:
WHERE
1 >= 100000000
AND ... The whole plan can then be simplified to a single Constant Scan operator. Опитайте:
SELECT MAX(n) FROM dbo.GetNums_SQLkiwi(100000000, 1);
The plan for this execution is shown in Figure 13.
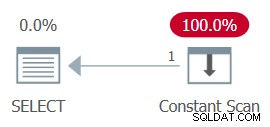 Figure 13:Plan with constant scan
Figure 13:Plan with constant scan
Unsurprisingly, I got the following performance numbers for this execution:
CPU time =0 ms, elapsed time =0 ms.logical reads 0
When passing a negative range with nonconstants as inputs, the use of the IIF function will prevent any attempt to compute a square root of a negative input.
Now let’s test the function with a valid input range:
SELECT MAX(n) FROM dbo.GetNums_SQLkiwi(1, 100000000);
You get the all-batch-mode plan shown in Figure 14.
 Figure 14:Plan for dbo.GetNums_SQLkiwi function
Figure 14:Plan for dbo.GetNums_SQLkiwi function
This is the same plan you saw earlier in Figure 7.
I got the following time statistics for this execution:
CPU time =3000 ms, elapsed time =3111 ms.Ladies and gentlemen, I think we have a winner! :)
Заключение
I’ll have what Paul’s having.
Are we done yet, or is this series going to last forever?
No and no.