Това е втората част от поредица за решения на предизвикателството за генериране на числови серии. Миналия месец разгледах решения, които генерират редовете в движение с помощта на конструктор на стойност на таблица с редове, базирани на константи. В тези решения нямаше I/O операции. Този месец се фокусирам върху решения, които отправят заявка към физическа базова таблица, която предварително попълвате с редове. Поради тази причина, освен да докладвам времевия профил на решенията, както направих миналия месец, ще докладвам и I/O профила на новите решения. Благодаря отново на Алън Бърщайн, Джо Оббиш, Адам Мачаник, Кристофър Форд, Джеф Модън, Чарли, НоамГр, Камил Косно, Дейв Мейсън, Джон Нелсън #2 и Ед Вагнер за споделянето на вашите идеи и коментари.
Най-бързото решение досега
Първо, като бързо напомняне, нека прегледаме най-бързото решение от статията от миналия месец, реализирано като вграден TVF, наречен dbo.GetNumsAlanCharlieItzikBatch.
Ще направя тестването си в tempdb, като активирам статистически данни за IO и TIME:
SET NOCOUNT ON; USE tempdb; SET STATISTICS IO, TIME ON;
Най-бързото решение от миналия месец прилага присъединяване с фиктивна таблица, която има индекс на columnstore, за да получи пакетна обработка. Ето кода за създаване на фиктивната таблица:
DROP TABLE IF EXISTS dbo.BatchMe; GO CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
А ето и кода с дефиницията на функцията dbo.GetNumsAlanCharlieItzikBatch:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum;
GO Миналия месец използвах следния код, за да тествам производителността на функцията със 100 милиона реда, след като активирах Отхвърляне на резултатите след изпълнение в SSMS за потискане на връщането на изходните редове:
SELECT n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Ето статистическите данни за времето, които получих за това изпълнение:
Процесорно време =16031 ms, изминало време =17172 ms.Джо Оббиш правилно отбеляза, че този тест може да липсва в отразяването на някои сценарии от реалния живот в смисъл, че голяма част от времето за изпълнение се дължи на изчакване на асинхронни мрежови I/O (тип ASYNC_NETWORK_IO на изчакване). Можете да наблюдавате най-високите изчаквания, като погледнете страницата със свойства на основния възел на действителния план за заявка или стартирате разширена сесия за събития с информация за изчакване. Фактът, че активирате Отхвърляне на резултатите след изпълнение в SSMS, не пречи на SQL Server да изпраща редовете с резултати към SSMS; той просто пречи на SSMS да ги отпечата. Въпросът е колко е вероятно да върнете големи набори от резултати на клиента в сценарии от реалния живот, дори когато използвате функцията за създаване на големи серии от числа? Може би по-често записвате резултатите от заявката в таблица или използвате резултата от функцията като част от заявка, която в крайна сметка произвежда малък набор от резултати. Трябва да разберете това. Можете да запишете набора от резултати във временна таблица, като използвате оператора SELECT INTO, или можете да използвате трика на Алън Бърщайн с оператор SELECT за присвояване, който присвоява стойността на колоната за резултата на променлива.
Ето как бихте променили последния тест, за да използвате опцията за присвояване на променлива:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Ето статистическите данни за времето, които получих за този тест:
Процесорно време =8641 ms, изминало време =8645 ms.Този път информацията за изчакване няма асинхронни мрежови I/O изчаквания и можете да видите значителния спад във времето за изпълнение.
Тествайте отново функцията, като този път добавите подреждане:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) ORDER BY n OPTION(MAXDOP 1);
Получих следните статистически данни за производителността за това изпълнение:
Процесорно време =9360 ms, изминало време =9551 ms.Припомнете си, че няма нужда от оператор за сортиране в плана за тази заявка, тъй като колоната n се основава на израз, който запазва реда по отношение на колоната rownum. Това е благодарение на постоянния трик за сгъване на Чарли, който разгледах миналия месец. Плановете и за двете заявки – тази без поръчка и тази с поръчка са еднакви, така че производителността обикновено е сходна.
Фигура 1 обобщава числата за ефективност, които получих за решенията от миналия месец, само че този път използвах присвояване на променливи в тестовете, вместо да отхвърлям резултатите след изпълнение.
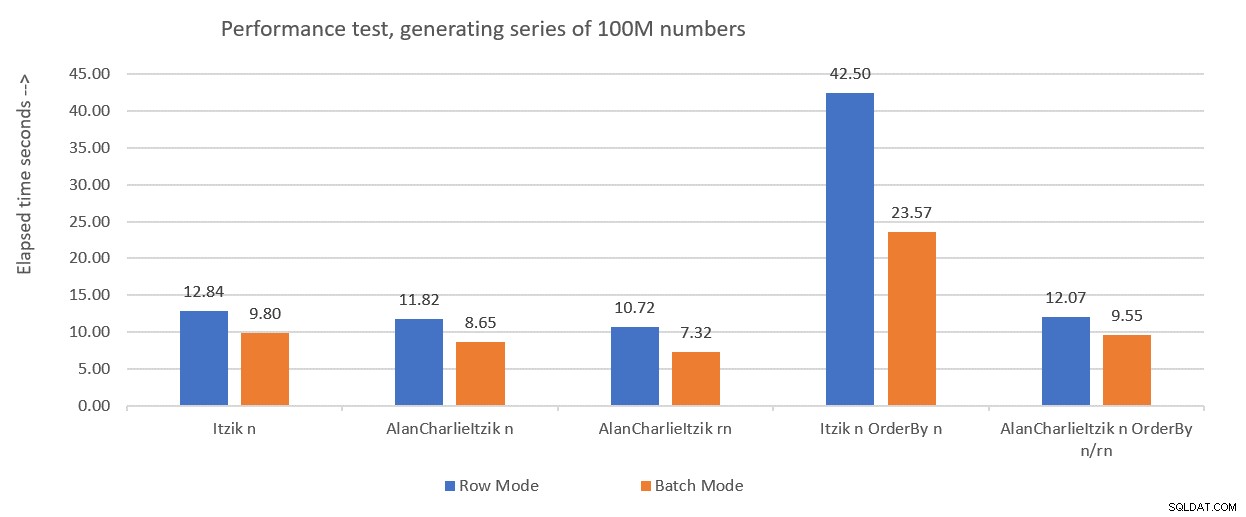 Фигура 1:Резюме на ефективността досега с присвояване на променлива
Фигура 1:Резюме на ефективността досега с присвояване на променлива
Ще използвам техниката за присвояване на променливи, за да тествам останалите решения, които ще представя в тази статия. Уверете се, че коригирате тестовете си, за да отразяват най-добре реалната ви ситуация, като използвате присвояване на променливи, SELECT INTO, Отхвърлете резултатите след изпълнение или всяка друга техника.
Съвет за форсиране на серийни планове без MAXDOP 1
Преди да представя нови решения, просто исках да покрия един малък съвет. Припомнете си, че някои от решенията се представят най-добре, когато използвате сериен план. Очевидният начин да принудите това е с намек за заявка MAXDOP 1. И това е правилният път, ако понякога искате да активирате паралелизъм, а понякога не. Но какво ще стане, ако винаги искате да наложите сериен план, когато използвате функцията, макар и по-малко вероятен сценарий?
Има трик за постигане на това. Използването на неинлайнируем скаларен UDF в заявката е инхибитор на паралелизма. Един от скаларните инхибитори на UDF инлайнинг извиква вътрешна функция, която е зависима от времето, като SYSDATETIME. Ето пример за неинлайнируем скаларен UDF:
CREATE OR ALTER FUNCTION dbo.MySYSDATETIME() RETURNS DATETIME2 AS BEGIN RETURN SYSDATETIME(); END; GO
Друга възможност е да дефинирате UDF само с някаква константа като върната стойност и да използвате опцията INLINE =OFF в заглавката му. Но тази опция е достъпна само от SQL Server 2019, който въведе скаларно вграждане на UDF. С предложената по-горе функция можете да я създадете както е с по-старите версии на SQL Server.
След това променете дефиницията на функцията dbo.GetNumsAlanCharlieItzikBatch, за да имате фиктивно извикване на dbo.MySYSDATETIME (дефинирайте колона въз основа на нея, но не препращайте към колоната в върнатата заявка), както следва:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT
ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum,
dbo.MySYSDATETIME() AS dontinline
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum;
GO Вече можете да стартирате отново теста за производителност, без да указвате MAXDOP 1, и все пак да получите сериен план:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) ORDER BY n;
Важно е обаче да се подчертае, че всяка заявка, използваща тази функция, вече ще получи сериен план. Ако има някакъв шанс функцията да се използва в заявки, които ще се възползват от паралелни планове, по-добре не използвайте този трик, а когато имате нужда от сериен план, просто използвайте MAXDOP 1.
Решение от Джо Оббиш
Решението на Джо е доста креативно. Ето неговото собствено описание на решението:
„Избрах да създам клъстериран индекс на columnstore (CCI) със 134 217 728 реда последователни цели числа. Функцията препраща към таблицата до 32 пъти, за да получи всички редове, необходими за набора от резултати. Избрах CCI, защото данните ще се компресират добре (по-малко от 3 байта на ред), получавате пакетен режим "безплатно", а предишният опит показва, че четенето на последователни числа от CCI ще бъде по-бързо, отколкото генерирането им чрез някакъв друг метод. ”Както споменахме по-рано, Джо също отбеляза, че първоначалното ми тестване на производителността беше значително изкривено поради изчакванията за вход/изход на асинхронна мрежа, генерирани от предаването на редовете към SSMS. Така че всички тестове, които ще изпълня тук, ще използват идеята на Алън с присвояването на променливата. Не забравяйте да коригирате тестовете си въз основа на това, което най-точно отразява вашата реална ситуация.
Ето кода, който Джо използва, за да създаде таблицата dbo.GetNumsObbishTable и да я попълни със 134 217 728 реда:
DROP TABLE IF EXISTS dbo.GetNumsObbishTable; CREATE TABLE dbo.GetNumsObbishTable (ID BIGINT NOT NULL, INDEX CCI CLUSTERED COLUMNSTORE); GO SET NOCOUNT ON; DECLARE @c INT = 0; WHILE @c < 128 BEGIN INSERT INTO dbo.GetNumsObbishTable SELECT TOP (1048576) @c * 1048576 - 1 + ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) FROM master..spt_values t1 CROSS JOIN master..spt_values t2 OPTION (MAXDOP 1); SET @c = @c + 1; END; GO
Завършването на този код отне 1:04 минути на моята машина.
Можете да проверите използването на пространството на тази таблица, като изпълните следния код:
EXEC sys.sp_spaceused @objname = N'dbo.GetNumsObbishTable';
Използвах около 350 MB пространство. В сравнение с другите решения, които ще представя в тази статия, това използва значително повече пространство.
В архитектурата на columnstore на SQL Server групата от редове е ограничена до 2^20 =1 048 576 реда. Можете да проверите колко групи редове са създадени за тази таблица, като използвате следния код:
SELECT COUNT(*) AS numrowgroups
FROM sys.column_store_row_groups
WHERE object_id = OBJECT_ID('dbo.GetNumsObbishTable'); Имам 128 групи от редове.
Ето кода с дефиницията на функцията dbo.GetNumsObbish:
CREATE OR ALTER FUNCTION dbo.GetNumsObbish(@low AS BIGINT, @high AS BIGINT) RETURNS TABLE AS RETURN SELECT @low + ID AS n FROM dbo.GetNumsObbishTable WHERE ID <= @high - @low UNION ALL SELECT @low + ID + CAST(134217728 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(134217728 AS BIGINT) AND ID <= @high - @low - CAST(134217728 AS BIGINT) UNION ALL SELECT @low + ID + CAST(268435456 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(268435456 AS BIGINT) AND ID <= @high - @low - CAST(268435456 AS BIGINT) UNION ALL SELECT @low + ID + CAST(402653184 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(402653184 AS BIGINT) AND ID <= @high - @low - CAST(402653184 AS BIGINT) UNION ALL SELECT @low + ID + CAST(536870912 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(536870912 AS BIGINT) AND ID <= @high - @low - CAST(536870912 AS BIGINT) UNION ALL SELECT @low + ID + CAST(671088640 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(671088640 AS BIGINT) AND ID <= @high - @low - CAST(671088640 AS BIGINT) UNION ALL SELECT @low + ID + CAST(805306368 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(805306368 AS BIGINT) AND ID <= @high - @low - CAST(805306368 AS BIGINT) UNION ALL SELECT @low + ID + CAST(939524096 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(939524096 AS BIGINT) AND ID <= @high - @low - CAST(939524096 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1073741824 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1073741824 AS BIGINT) AND ID <= @high - @low - CAST(1073741824 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1207959552 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1207959552 AS BIGINT) AND ID <= @high - @low - CAST(1207959552 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1342177280 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1342177280 AS BIGINT) AND ID <= @high - @low - CAST(1342177280 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1476395008 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1476395008 AS BIGINT) AND ID <= @high - @low - CAST(1476395008 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1610612736 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1610612736 AS BIGINT) AND ID <= @high - @low - CAST(1610612736 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1744830464 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1744830464 AS BIGINT) AND ID <= @high - @low - CAST(1744830464 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1879048192 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1879048192 AS BIGINT) AND ID <= @high - @low - CAST(1879048192 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2013265920 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2013265920 AS BIGINT) AND ID <= @high - @low - CAST(2013265920 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2147483648 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2147483648 AS BIGINT) AND ID <= @high - @low - CAST(2147483648 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2281701376 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2281701376 AS BIGINT) AND ID <= @high - @low - CAST(2281701376 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2415919104 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2415919104 AS BIGINT) AND ID <= @high - @low - CAST(2415919104 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2550136832 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2550136832 AS BIGINT) AND ID <= @high - @low - CAST(2550136832 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2684354560 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2684354560 AS BIGINT) AND ID <= @high - @low - CAST(2684354560 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2818572288 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2818572288 AS BIGINT) AND ID <= @high - @low - CAST(2818572288 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2952790016 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2952790016 AS BIGINT) AND ID <= @high - @low - CAST(2952790016 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3087007744 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3087007744 AS BIGINT) AND ID <= @high - @low - CAST(3087007744 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3221225472 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3221225472 AS BIGINT) AND ID <= @high - @low - CAST(3221225472 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3355443200 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3355443200 AS BIGINT) AND ID <= @high - @low - CAST(3355443200 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3489660928 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3489660928 AS BIGINT) AND ID <= @high - @low - CAST(3489660928 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3623878656 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3623878656 AS BIGINT) AND ID <= @high - @low - CAST(3623878656 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3758096384 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3758096384 AS BIGINT) AND ID <= @high - @low - CAST(3758096384 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3892314112 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3892314112 AS BIGINT) AND ID <= @high - @low - CAST(3892314112 AS BIGINT) UNION ALL SELECT @low + ID + CAST(4026531840 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(4026531840 AS BIGINT) AND ID <= @high - @low - CAST(4026531840 AS BIGINT) UNION ALL SELECT @low + ID + CAST(4160749568 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(4160749568 AS BIGINT) AND ID <= @high - @low - CAST(4160749568 AS BIGINT); GO
32-те отделни заявки генерират непреходните 134 217 728-целочислени поддиапазони, които, когато са обединени, произвеждат пълния непрекъснат диапазон от 1 до 4 294 967 296. Това, което е наистина умно в това решение, е предикатите на филтъра WHERE, които използват отделните заявки. Припомнете си, че когато SQL Server обработва вграден TVF, той първо прилага вграждане на параметри, замествайки параметрите с входните константи. След това SQL Server може да оптимизира заявките, които произвеждат поддиапазони, които не се пресичат с входния диапазон. Например, когато поискате диапазона на въвеждане от 1 до 100 000 000, само първата заявка е уместна, а всички останали се оптимизират. Тогава планът в този случай ще включва препратка само към един екземпляр на таблицата. Това е доста брилянтно!
Нека тестваме производителността на функцията с диапазона от 1 до 100 000 000:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsObbish(1, 100000000);
Планът за тази заявка е показан на Фигура 2.
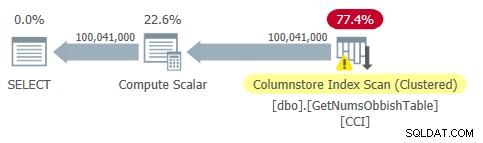 Фигура 2:План за dbo.GetNumsObbish, 100 милиона реда, неподредени
Фигура 2:План за dbo.GetNumsObbish, 100 милиона реда, неподредени
Забележете, че наистина в този план е необходима само една препратка към CCI на таблицата.
Получих следната статистика за времето за това изпълнение:
Това е доста впечатляващо и далеч по-бързо от всичко друго, което съм тествал.
Ето I/O статистиката, която получих за това изпълнение:
Таблица „GetNumsObbishTable“. Брой на сканиране 1, логическо четене 0, физическо четене 0, сървър на страницата чете 0, четене напред 0, сървър за четене напред чете 0, лоб логически четения 32928 , лобно физическо четене 0, сървърът на лобната страница чете 0, лобното четене напред чете 0, сървърът на лоб страница чете напред четене 0.Таблица „GetNumsObbishTable“. Сегментът чете 96 , сегментът е пропуснат 32.
Входно-изходният профил на това решение е един от недостатъците му в сравнение с останалите, като поражда над 30K логически четения за това изпълнение.
За да видите, че когато пресечете множество 134 217 728-целочислени поддиапазони, планът ще включва множество препратки към таблицата, потърсете функцията с диапазона от 1 до 400 000 000, например:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsObbish(1, 400000000);
Планът за това изпълнение е показан на Фигура 3.
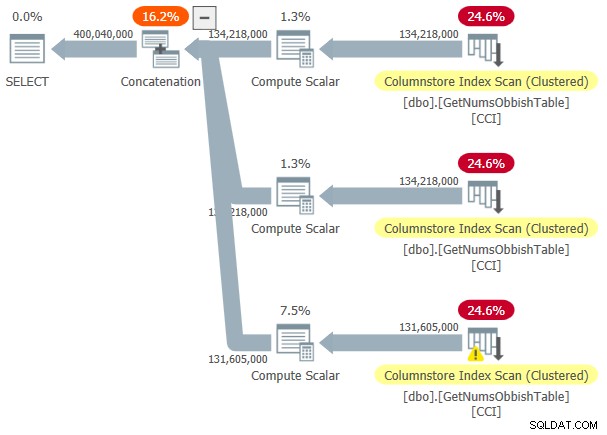 Фигура 3:План за dbo.GetNumsObbish, 400M реда, неподредени
Фигура 3:План за dbo.GetNumsObbish, 400M реда, неподредени
Исканият диапазон прекоси три поддиапазони от 134 217 728 цели, следователно планът показва три препратки към CCI на таблицата.
Ето статистическите данни за времето, които получих за това изпълнение:
Процесорно време =20610 ms, изминало време =20628 ms.А ето и неговата I/O статистика:
Таблица „GetNumsObbishTable“. Брой на сканиране 3, логическо четене 0, физическо четене 0, сървър на страници чете 0, четене напред 0, сървър за четене напред чете 0, лоб логически четения 131026 , лобно физическо четене 0, сървърът на лобната страница чете 0, лобното четене напред чете 0, сървърът на лоб страница чете напред четене 0.Таблица „GetNumsObbishTable“. Сегментът чете 382 , сегментът е пропуснат 2.
Този път изпълнението на заявката доведе до над 130K логически четения.
Ако можете да преборите I/O разходите и не е необходимо да обработвате серия от числа по подреден начин, това е страхотно решение. Ако обаче трябва да обработите поредицата, това решение ще доведе до оператор за сортиране в плана. Ето тест, изискващ подредените резултати:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsObbish(1, 100000000) ORDER BY n;
Планът за това изпълнение е показан на Фигура 4.
 Фигура 4:План за dbo.GetNumsObbish, 100M реда, подредени
Фигура 4:План за dbo.GetNumsObbish, 100M реда, подредени
Ето статистическите данни за времето, които получих за това изпълнение:
Процесорно време =44516 ms, изминало време =34836 ms.Както можете да видите, производителността се влоши значително с увеличаване на времето за изпълнение с порядък поради изричното сортиране.
Ето статистическите данни за I/O, които получих за това изпълнение:
Таблица „GetNumsObbishTable“. Брой на сканиране 4, логическо четене 0, физическо четене 0, сървър на страницата чете 0, четене напред 0, сървър за четене напред чете 0, лоб логически четения 32928 , лобно физическо четене 0, сървърът на лобната страница чете 0, лобното четене напред чете 0, сървърът на лоб страница чете напред четене 0.Таблица „GetNumsObbishTable“. Сегментът чете 96 , сегментът е пропуснат 32.
Таблица „Работна маса“. Брой на сканиране 0, логическо четене 0, физическо четене 0, сървър на страницата чете 0, четене напред 0, сървър за страница чете напред 0, лобно логическо четене 0, физическо четене на лоб 0, сървър на лоб страница чете 0, лобно четене- напред чете 0, сървърът на лоб страница чете напред чете 0.
Забележете, че работна таблица се показва в изхода на STATISTICS IO. Това е така, защото сортирането може потенциално да се разлее към tempdb, в който случай ще използва работна таблица. Това изпълнение не се разля, следователно всички числа са нули в този запис.
Решение от Джон Нелсън №2, Дейв, Джо, Алън, Чарли, Ицик
Джон Нелсън #2 публикува решение, което е просто красиво в своята простота. Освен това включва идеи и предложения от други решения на Дейв, Джо, Алън, Чарли и мен.
Подобно на решението на Джо, Джон реши да използва CCI, за да получи високо ниво на компресия и „безплатна“ пакетна обработка. Само Джон реши да запълни таблицата с 4B реда с някакъв фиктивен NULL маркер в битова колона и функцията ROW_NUMBER да генерира числата. Тъй като съхранените стойности са еднакви, при компресиране на повтарящи се стойности се нуждаете от значително по-малко място, което води до значително по-малко I/Os в сравнение с решението на Joe. Компресията на Columnstore се справя много добре с повтарящи се стойности, тъй като може да представи всяка такава последователна секция в рамките на сегмента на колоните на група редове само веднъж заедно с броя на последователно повтарящите се събития. Тъй като всички редове имат една и съща стойност (маркерът NULL), теоретично имате нужда само от едно появяване на група редове. С 4B реда трябва да се окажете с 4096 групи редове. Всеки трябва да има един сегмент от колони, с много малко изискване за използване на пространство.
Ето кода за създаване и попълване на таблицата, реализиран като CCI с архивна компресия:
DROP TABLE IF EXISTS dbo.NullBits4B;
CREATE TABLE dbo.NullBits4B
(
b BIT NULL,
INDEX cc_NullBits4B CLUSTERED COLUMNSTORE
WITH (DATA_COMPRESSION = COLUMNSTORE_ARCHIVE)
);
GO
WITH
L0 AS (SELECT CAST(NULL AS BIT) AS b
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) AS D(b)),
L1 AS (SELECT A.b FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT A.b FROM L1 AS A CROSS JOIN L1 AS B),
nulls(b) AS (SELECT A.b FROM L2 AS A CROSS JOIN L2 AS B)
INSERT INTO dbo.NullBits4B WITH (TABLOCK) (b)
SELECT b FROM nulls;
GO Основният недостатък на това решение е времето, необходимо за попълване на тази таблица. Завършването на този код отне 12:32 минути на моята машина, когато разрешавам паралелизъм, и 15:17 минути, когато форсира сериен план.
Имайте предвид, че можете да работите върху оптимизирането на натоварването на данни. Например, Джон тества решение, което зарежда редовете, използвайки 32 едновременни връзки с OSTRESS.EXE, като всеки изпълнява 128 кръга на вмъкване от 2^20 реда (максимален размер на групата редове). Това решение намали времето за зареждане на Джон до една трета. Ето кода, който Джон използва:
ostress -S(local)\YourSQLInstance -E -dtempdb -n32 -r128 -Q"WITH L0 AS (ИЗБЕРЕТЕ CAST(NULL AS BIT) AS b ОТ (СТОЙНОСТИ(1),(1),(1),(1)) ,(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) AS D(b)), L1 AS (ИЗБЕРЕТЕ A.b ОТ L0 КАТО КРЪСТО СЪЕДИНЕНИЕ L0 КАТО B), L2 AS (ИЗБЕРЕТЕ A.b ОТ L1 КАТО КРЪСТО СЪЕДИНЕНИЕ L1 AS B), nulls(b) AS (ИЗБЕРЕТЕ A.b ОТ L2 КАТО A КРЪСТО ПРИСЪЕДИНЯВАНЕ L2 КАТО B) ВМЕСТЕ В dbo.NullBits4B(b) SELECT TOP(1048576) b ОТ NULL ОПЦИЯ(MAXDOP 1);"Все пак времето за зареждане е в минути. Добрата новина е, че трябва да извършите това зареждане на данни само веднъж.
Страхотната новина е малкото пространство, необходимо за масата. Използвайте следния код, за да проверите използването на пространството:
EXEC sys.sp_spaceused @objname = N'dbo.NullBits4B';
Имам 1,64 MB. Това е невероятно, като се има предвид факта, че таблицата има 4B реда!
Използвайте следния код, за да проверите колко групи редове са създадени:
SELECT COUNT(*) AS numrowgroups
FROM sys.column_store_row_groups
WHERE object_id = OBJECT_ID('dbo.NullBits4B'); Както се очакваше, броят на групите от редове е 4096.
Тогава дефиницията на функцията dbo.GetNumsJohn2DaveObbishAlanCharlieItzik става доста проста:
CREATE OR ALTER FUNCTION dbo.GetNumsJohn2DaveObbishAlanCharlieItzik
(@low AS BIGINT = 1, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM dbo.NullBits4B)
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums
ORDER BY rownum;
GO
Както можете да видите, простата заявка към таблицата използва функцията ROW_NUMBER за изчисляване на основните номера на редовете (колона rownum), а след това външната заявка използва същите изрази като в dbo.GetNumsAlanCharlieItzikBatch за изчисляване на rn, op и n. Също тук и rn, и n запазват реда по отношение на rownum.
Нека тестваме производителността на функцията:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik(1, 100000000);
Получих плана, показан на фигура 5 за това изпълнение.
 Фигура 5:План за dbo.GetNumsJohn2DaveObbishAlanCharlieItzik
Фигура 5:План за dbo.GetNumsJohn2DaveObbishAlanCharlieItzik
Ето статистическите данни за времето, които получих за този тест:
Процесорно време =7593 ms, изминало време =7590 ms.
Както можете да видите, времето за изпълнение не е толкова бързо, колкото с решението на Джо, но все пак е по-бързо от всички други решения, които съм тествал.
Ето статистическите данни за I/O, които получих за този тест:
Таблица „NullBits4B“. Сегментът чете 96 , сегментът е пропуснат 0
Обърнете внимание, че изискванията за I/O са значително по-ниски, отколкото при решението на Joe.
Другото страхотно нещо в това решение е, че когато трябва да обработите поръчаната серия от числа, не плащате допълнително. Това е така, тъй като няма да доведе до изрична операция за сортиране в плана, независимо дали поръчвате резултата по rn или n.
Ето тест за демонстриране на това:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik(1, 100000000) ORDER BY n;
Получавате същия план, както е показано по-рано на Фигура 5.
Ето статистическите данни за времето, които получих за този тест;
Процесорно време =7578 ms, изминало време =7582 ms.А ето и I/O статистика:
Таблица „NullBits4B“. Брой на сканиране 1, логическо четене 0, физическо четене 0, сървър на страници чете 0, четене напред 0, сървър за четене напред чете 0, лоб логически четения 194 , лобно физическо четене 0, сървърът на лобната страница чете 0, лобното четене напред чете 0, сървърът на лоб страница чете напред четене 0.Таблица „NullBits4B“. Сегментът чете 96 , сегментът е пропуснат 0.
По принцип те са същите като в теста без подреждането.
Решение 2 от Джон Нелсън #2, Дейв Мейсън, Джо Оббиш, Алън, Чарли, Ицик
Решението на Джон е бързо и просто. Това е фантастично. Единственият недостатък е времето за зареждане. Понякога това няма да е проблем, тъй като зареждането се случва само веднъж. Но ако това е проблем, можете да попълните таблицата със 102 400 реда вместо 4B реда и да използвате кръстосано свързване между две копия на таблицата и TOP филтър, за да генерирате желания максимум от 4B реда. Имайте предвид, че за да получите 4B реда, би било достатъчно да попълните таблицата с 65 536 реда и след това да приложите кръстосано свързване; обаче, за да накарате данните да бъдат компресирани незабавно — за разлика от зареждането в делта магазин, базиран на rowstore — трябва да заредите таблицата с минимум 102 400 реда.
Ето кода за създаване и попълване на таблицата:
DROP TABLE IF EXISTS dbo.NullBits102400;
GO
CREATE TABLE dbo.NullBits102400
(
b BIT NULL,
INDEX cc_NullBits102400 CLUSTERED COLUMNSTORE
WITH (DATA_COMPRESSION = COLUMNSTORE_ARCHIVE)
);
GO
WITH
L0 AS (SELECT CAST(NULL AS BIT) AS b
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) AS D(b)),
L1 AS (SELECT A.b FROM L0 AS A CROSS JOIN L0 AS B),
nulls(b) AS (SELECT A.b FROM L1 AS A CROSS JOIN L1 AS B CROSS JOIN L1 AS C)
INSERT INTO dbo.NullBits102400 WITH (TABLOCK) (b)
SELECT TOP(102400) b FROM nulls;
GO Времето за зареждане е незначително — 43 ms на моята машина.
Проверете размера на таблицата на диска:
EXEC sys.sp_spaceused @objname = N'dbo.NullBits102400';
Имам 56 KB пространство, необходимо за данните.
Проверете броя на групите от редове, тяхното състояние (компресирани или отворени) и техния размер:
SELECT state_description, total_rows, size_in_bytes
FROM sys.column_store_row_groups
WHERE object_id = OBJECT_ID('dbo.NullBits102400'); Получих следния изход:
state_description total_rows size_in_bytes ------------------ ----------- -------------- COMPRESSED 102400 293
Тук е необходима само една група редове; той е компресиран и размерът е незначителните 293 байта.
Ако попълните таблицата с един ред по-малко (102 399), получавате базирано на rowstore некомпресирано отворено делта магазин. В такъв случай sp_spaceused отчита размера на данните на диска от над 1MB, а sys.column_store_row_groups отчита следната информация:
state_description total_rows size_in_bytes ------------------ ----------- -------------- OPEN 102399 1499136
Така че не забравяйте да попълните таблицата със 102 400 реда!
Ето дефиницията на функцията dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2:
CREATE OR ALTER FUNCTION dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2
(@low AS BIGINT = 1, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM dbo.NullBits102400 AS A
CROSS JOIN dbo.NullBits102400 AS B)
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums
ORDER BY rownum;
GO Let’s test the function's performance:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2(1, 100000000) OPTION(MAXDOP 1);
I got the plan shown in Figure 6 for this execution.
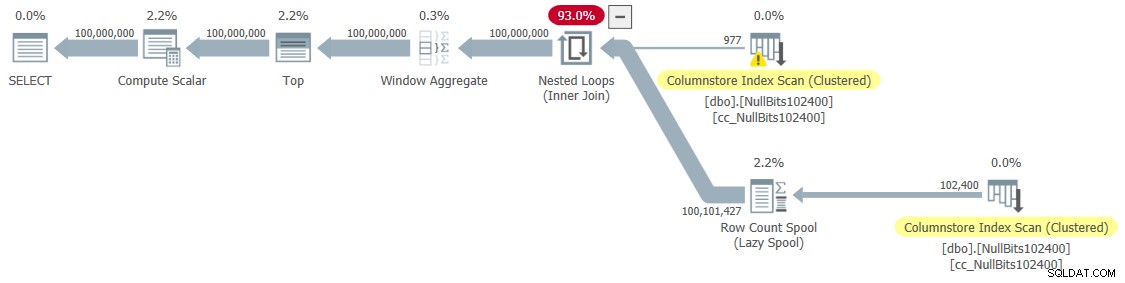 Figure 6:Plan for dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2
Figure 6:Plan for dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2
I got the following time statistics for this test:
CPU time =9188 ms, elapsed time =9188 ms.As you can see, the execution time increased by ~ 26%. It’s still pretty fast, but not as fast as the single-table solution. So that’s a tradeoff that you’ll need to evaluate.
I got the following I/O stats for this test:
Table 'NullBits102400'. Scan count 2, logical reads 0, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 8 , lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.Table 'NullBits102400'. Segment reads 2, segment skipped 0.
The I/O profile of this solution is excellent.
Let’s add order to the test:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2(1, 100000000) ORDER BY n OPTION(MAXDOP 1);
You get the same plan as shown earlier in Figure 6 since there’s no explicit sorting needed.
I got the following time statistics for this test:
CPU time =9140 ms, elapsed time =9237 ms.And the following I/O stats:
Table 'NullBits102400'. Scan count 2, logical reads 0, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 8 , lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.Table 'NullBits102400'. Segment reads 2, segment skipped 0.
Again, the numbers are very similar to the test without the ordering.
Performance summary
Figure 7 has a summary of the time statistics for the different solutions.
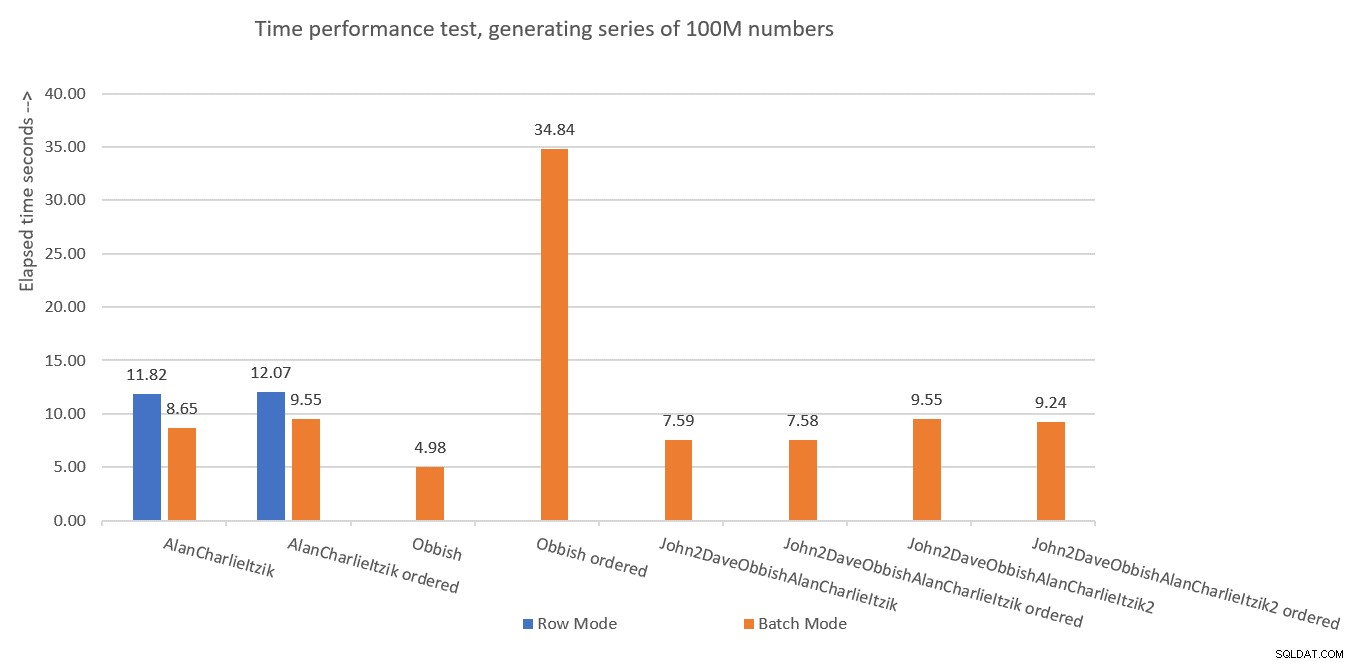 Figure 7:Time performance summary of solutions
Figure 7:Time performance summary of solutions
Figure 8 has a summary of the I/O statistics.
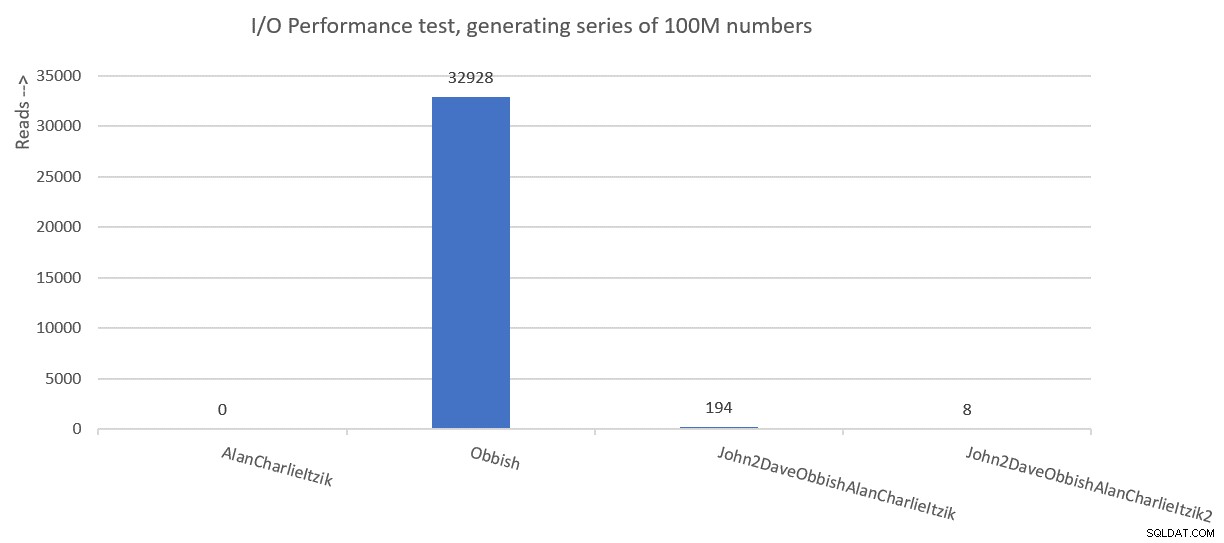 Figure 8:I/O performance summary of solutions
Figure 8:I/O performance summary of solutions
Thanks to all of you who posted ideas and suggestions in effort to create a fast number series generator. It’s a great learning experience!
We’re not done yet. Next month I’ll continue exploring additional solutions.



