В процес на разчистване на дома си (твърде късно през лятото, за да се опитам да го предам като пролетно почистване). Знаеш ли, почистване на килери, разглеждане на детските играчки и организиране на мазето. Това е болезнен процес. Когато се преместихме в нашата къща преди 10 години, имахме ТОЛКОВА много място. Сега имам чувството, че има неща навсякъде и това затруднява намирането на това, което наистина търся, и отнема все повече време за почистване и организиране.
Това звучи ли като всяка база данни, която управлявате?
Много клиенти, с които съм работил, се занимават с прочистване на данни като закъснение. В момента на внедряването всеки иска да спаси всичко. "Никога не знаем кога може да ни потрябва." След година или две някой разбира, че има много допълнителни неща в базата данни, но сега хората се страхуват да се отърват от тях. „Трябва да проверим с правния отдел, за да видим дали можем да го изтрием.“ Но никой не проверява с Legal или ако някой го направи, Legal се връща при собствениците на бизнес, за да попита какво да задържи и след това проектът спира. „Не можем да постигнем консенсус за това какво може да бъде изтрито. Проектът е забравен и след това след две или четири години базата данни изведнъж е терабайт, трудна за управление и хората обвиняват за всички проблеми с производителността размера на базата данни. Чувате думите „разделяне“ и „архивна база данни“ и понякога просто трябва да изтриете куп данни, което има свои собствени проблеми.
В идеалния случай трябва да вземете решение за стратегията си за прочистване преди внедряването или в рамките на първите шест до дванадесет месеца от стартирането. Но тъй като сме преминали този етап, нека да разгледаме какво въздействие могат да имат тези допълнителни данни.
Методология на изпитване
За да подготвя сцената, взех копие от базата данни Credit и я възстанових в моя SQL Server 2012 екземпляр. Изхвърлих трите съществуващи неклъстерирани индекса и добавих два от моите собствени:
USE [master]; GO RESTORE DATABASE [Credit] FROM DISK = N'C:\SQLskills\SampleDatabases\Credit\CreditBackup100.bak' WITH FILE = 1, MOVE N'CreditData' TO N'D:\Databases\SQL2012\CreditData.mdf', MOVE N'CreditLog' TO N'D:\Databases\SQL2012\CreditLog.ldf', STATS = 5; GO ALTER DATABASE [Credit] MODIFY FILE ( NAME = N'CreditData', SIZE = 14680064KB , FILEGROWTH = 524288KB ); GO ALTER DATABASE [Credit] MODIFY FILE ( NAME = N'CreditLog', SIZE = 2097152KB , FILEGROWTH = 524288KB ); GO USE [Credit]; GO DROP INDEX [dbo].[charge].[charge_category_link]; DROP INDEX [dbo].[charge].[charge_provider_link]; DROP INDEX [dbo].[charge].[charge_statement_link]; CREATE NONCLUSTERED INDEX [charge_chargedate] ON [dbo].[charge] ([charge_dt]); CREATE NONCLUSTERED INDEX [charge_provider] ON [dbo].[charge] ([provider_no]);
След това увеличих броя на редовете в таблицата до 14,4 милиона, като повторно вмъкнах оригиналния набор от редове няколко пъти, като промених леко датите:
INSERT INTO [dbo].[charge] ( [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] ) SELECT [member_no], [provider_no], [category_no], [charge_dt] - 175, [charge_amt], [statement_no], [charge_code] FROM [dbo].[charge] WHERE [charge_no] BETWEEN 1 AND 2000000; GO 3 INSERT INTO [dbo].[charge] ( [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] ) SELECT [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] FROM [dbo].[charge] WHERE [charge_no] BETWEEN 1 AND 2000000; GO 2 INSERT INTO [dbo].[charge] ( [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] ) SELECT [member_no], [provider_no], [category_no], [charge_dt] + 79, [charge_amt], [statement_no], [charge_code] FROM [dbo].[charge] WHERE [charge_no] BETWEEN 1 AND 2000000; GO 3
Накрая настроих тестова система за изпълнение на поредица от оператори срещу базата данни четири пъти всеки. Изявленията са по-долу:
ALTER INDEX ALL ON [dbo].[charge] REBUILD; DBCC CHECKDB (Credit) WITH ALL_ERRORMSGS, NO_INFOMSGS; BACKUP DATABASE [Credit] TO DISK = N'D:\Backups\SQL2012\Credit.bak' WITH NOFORMAT, INIT, NAME = N'Credit-Full Database Backup', STATS = 10; SELECT [charge_no], [member_no], [charge_dt], [charge_amt] FROM [dbo].[charge] WHERE [charge_no] = 841345; DECLARE @StartDate DATETIME = '1999-07-01'; DECLARE @EndDate DATETIME = '1999-07-31'; SELECT [charge_dt], COUNT([charge_dt]) FROM [dbo].[charge] WHERE [charge_dt] BETWEEN @StartDate AND @EndDate GROUP BY [charge_dt]; SELECT [provider_no], COUNT([provider_no]) FROM [dbo].[charge] WHERE [provider_no] = 475 GROUP BY [provider_no]; SELECT [provider_no], COUNT([provider_no]) FROM [dbo].[charge] WHERE [provider_no] = 140 GROUP BY [provider_no];
Преди всяко изявление, което изпълнявах
DBCC DROPCLEANBUFFERS; GO
за да изчистите буферния пул. Очевидно това не е нещо за изпълнение в производствена среда. Направих го тук, за да осигуря последователна отправна точка за всеки тест.
След всяко изпълнение увеличавах размера на таблицата dbo.charge, като вмъквах 14,4 милиона реда, с които започнах, но увеличавах charge_dt с една година за всяко изпълнение. Например:
INSERT INTO [dbo].[charge] ( [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] ) SELECT [member_no], [provider_no], [category_no], [charge_dt] + 365, [charge_amt], [statement_no], [charge_code] FROM [dbo].[charge] WHERE [charge_no] BETWEEN 1 AND 14800000; GO
След добавянето на 14,4 милиона реда, пуснах отново тестовия ремък. Повторих това шест пъти, като по същество добавих шест „години“ данни. Таблицата dbo.charge започва с данни от 1999 г. и след многократните вмъквания съдържа данни до 2005 г.
Резултати
Резултатите от екзекуциите можете да видите тук:
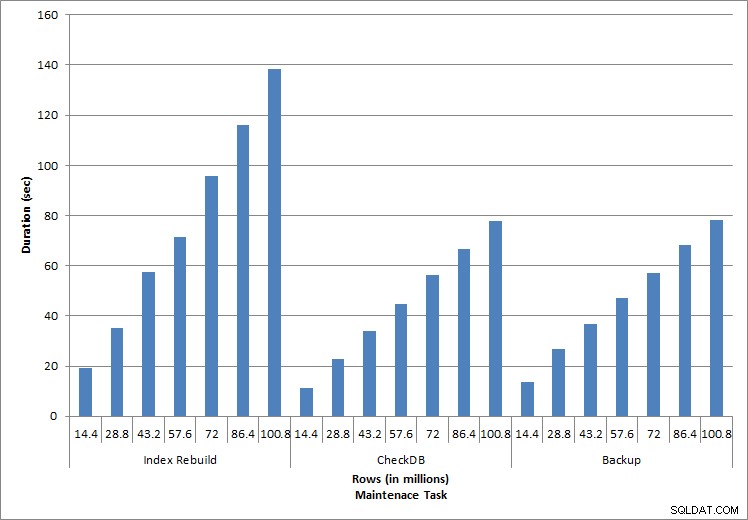
Продължителност на задачите по поддръжка
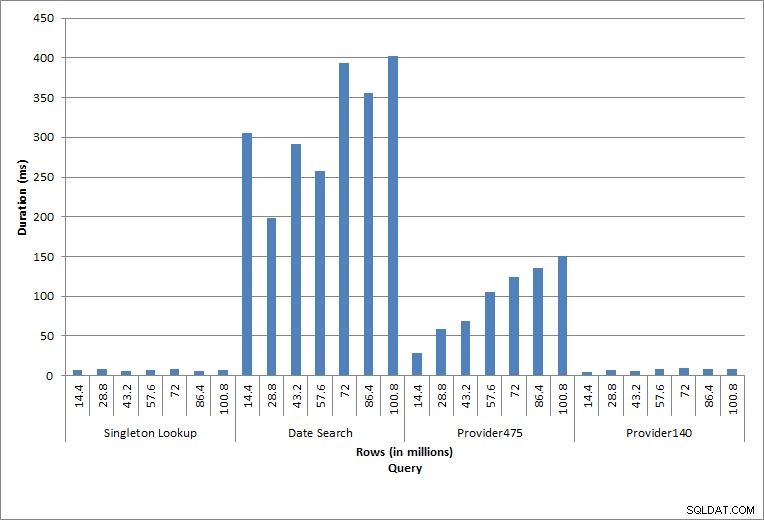
Продължителност на заявките
Изпълнените отделни оператори отразяват типичната активност на базата данни. Възстановяването на индекси, проверките на целостта и архивирането са част от редовната поддръжка на базата данни. Заявките към таблицата за таксуване представляват еднократно търсене, както и три варианта на сканиране на диапазон, специфични за данните в таблицата.
Възстановяване на индекс, CHECKDB и архивиране
Както се очакваше за задачите за поддръжка, продължителността и стойностите на IO се увеличиха с добавянето на повече редове към базата данни. Размерът на базата данни се увеличи с коефициент 10 и докато продължителността не се увеличава със същата скорост, се наблюдава постоянно увеличение. Всяка задача за поддръжка първоначално отнемаше по-малко от 20 секунди, но с добавянето на повече редове продължителността на задачите се увеличи до почти 1 минута и 20 секунди за 100 милиона реда (и до над 2 минути за възстановяване на индекса). Това отразява допълнителното време, необходимо на SQL Server за изпълнение на задачата поради допълнителни данни.
Еднократно търсене
Заявката към dbo.charge за конкретен charge_no винаги е произвеждала един ред – и би произвела един ред, независимо от използваната стойност, тъй като charge_no е уникална идентичност. Има минимална вариация за това търсене. Тъй като редовете се добавят непрекъснато към таблицата, индексът може да се увеличи в дълбочина с едно или две нива (повече, когато таблицата става по-широка), следователно добавяне на няколко IO, но това е еднократно търсене с много малко IO.
Сканиране на обхват
Заявката за период от време (charge_dt) беше променена след всяко вмъкване, за да търси данните за най-новата година за юли (напр. „2005-07-01“ до „2005-07-01“ за последния набор от тестове), но беше върната малко над 1,2 милиона реда всеки път. В реален сценарий не бихме очаквали същият брой редове да бъдат върнати за един и същи месец, година след година, нито бихме очаквали същият брой редове да бъде върнат за всеки месец в годината. Но броят на редовете може да остане в същия диапазон между месеците, с леко увеличение с течение на времето. Съществуват колебания в продължителността на тази заявка, но прегледът на данните за IO, заснети от sys.dm_io_virtual_file_stats, показва последователност в броя на прочитанията.
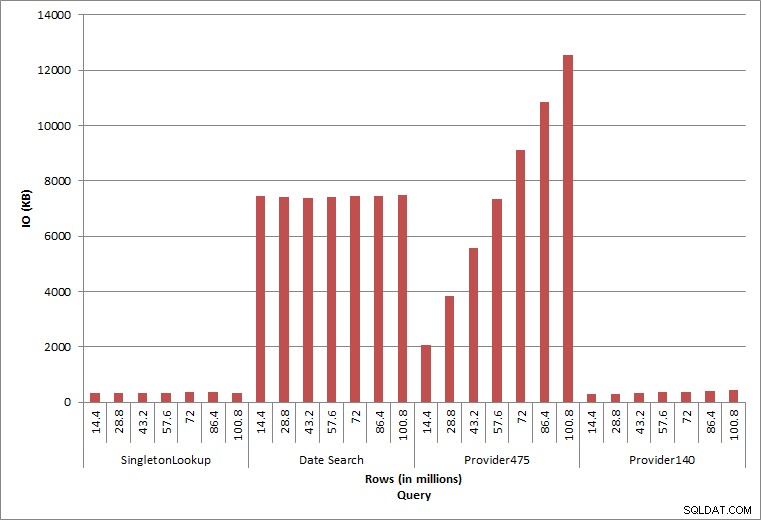
Заявка за IO
Последните две заявки, за две различни стойности provider_no, показват истинския ефект от съхраняването на данни. В първоначалната таблица на dbo.charge provider_no 475 имаше над 126 000 реда, а provider_no 140 имаше над 1700 реда. За всеки 14,4 милиона реда, които бяха добавени, беше добавен приблизително същия брой редове за всеки provider_no. В производствена среда този тип разпределение на данни не е необичайно и заявките за тези данни може да се представят добре през първите години на решението, но могат да се влошат с времето, когато се добавят повече редове. Продължителността на заявката се увеличава с коефициент пет (от 31 ms до 153 ms) между първоначалното и крайното изпълнение за provider_no 475. Въпреки че това въздействие може да не изглежда значително, обърнете внимание на паралелното увеличение на IO (по-горе). Ако това беше заявка, която се изпълняваше с висока честота и/или имаше подобни заявки, които се изпълняваха с редовна честота, допълнителното натоварване може да се добави и да повлияе на общото използване на ресурсите. Освен това, помислете за въздействието, когато работите с таблици, които имат милиарди редове и се използват в заявки със сложни присъединявания, както и въздействието върху вашите редовни – и изключително критични – задачи за поддръжка. И накрая, вземете предвид времето за възстановяване. Вашият план за възстановяване при бедствия трябва да се основава на времената за възстановяване и с нарастването на размера на базата данни ще отнеме повече време за цялостното й възстановяване. Ако не тествате редовно и не определяте времето на възстановяването си, възстановяването от бедствие може да отнеме повече време, отколкото сте предполагали.
Резюме
Показаните тук примери са прости илюстрации на това какво може да се случи, когато стратегията за архивиране на данни не е определена по време на внедряването на базата данни и има много други сценарии за изследване и тестване. Старите данни, до които рядко, ако изобщо се осъществява достъп, засягат повече от просто пространство на диска. Това може да повлияе на производителността на заявката и продължителността на задачите за поддръжка. Като DBA, управляващ множество бази данни на екземпляр, една база данни, която съдържа исторически данни, може да повлияе на изпълнението и задачите за поддръжка на други бази данни. Освен това, ако отчетите се изпълняват спрямо исторически данни, това може да причини хаос в вече натоварената OLTP среда.
От самото начало е изключително важно продължителността на живота на данните в базата данни да бъде определена и да бъде въведен план за действие. За някои решения е необходимо всички данни да се съхраняват завинаги. В този случай използвайте стратегии, за да поддържате размера на базата данни управляем, например:редовно архивирайте данните в отделна таблица или отделна база данни. В случай, че данните не трябва да се съхраняват години и години, приложете стратегия за прочистване, която премахва данните редовно. По този начин можете да изхвърлите играчките, с които вече не се играе, дрехите, които вече не стават, и произволните боклуци, които просто не използвате на всеки три месеца... а не веднъж на 10 години.