Тази статия е четвъртата част от поредица за таблични изрази. В Част 1 и Част 2 разгледах концептуалната обработка на извлечените таблици. В част 3 започнах да обхващам съображения за оптимизация на производни таблици. Този месец разглеждам допълнителни аспекти на оптимизирането на извлечените таблици; по-специално се фокусирам върху заместването/отмяната на производни таблици.
В моите примери ще използвам примерни бази данни, наречени TSQLV5 и PerformanceV5. Можете да намерите скрипта, който създава и попълва TSQLV5 тук, и неговата ER диаграма тук. Можете да намерите скрипта, който създава и попълва PerformanceV5 тук.
Отмяна/замяна
Отмяната/замяната на таблични изрази е процес на приемане на заявка, която включва вмъкване на таблични изрази и сякаш заместването й със заявка, при която вложената логика е елиминирана. Трябва да подчертая, че на практика няма реален процес, в който SQL Server да преобразува оригиналния низ на заявка с вложената логика в нов низ на заявка без влагането. Това, което всъщност се случва, е, че процесът на синтактичен анализ на заявката произвежда първоначално дърво от логически оператори, отразяващи точно оригиналната заявка. След това SQL Server прилага трансформации към това дърво на заявки, елиминирайки някои от ненужните стъпки, свива няколко стъпки в по-малко стъпки и премества операторите наоколо. При своите трансформации, стига да са изпълнени определени условия, SQL Server може да премести нещата през това, което първоначално са били граници на изрази на таблицата - понякога ефективно, сякаш елиминира вложените единици. Всичко това в опит да се намери оптимален план.
В тази статия разглеждам както случаите, когато се случва такова разпръскване, така и инхибиторите на разпръскване. Тоест, когато използвате определени елементи на заявка, това пречи на SQL Server да може да премести логически оператори в дървото на заявката, принуждавайки го да обработва операторите въз основа на границите на табличните изрази, използвани в оригиналната заявка.
Ще започна с демонстрация на прост пример, при който извлечените таблици се отменят. Ще демонстрирам също пример за инхибитор на разгъването. След това ще говоря за необичайни случаи, при които разглобяването може да бъде нежелателно, което води до грешки или влошаване на производителността, и ще демонстрирам как да предотвратим разглобяването в тези случаи чрез използване на инхибитор на разпръскване.
Следната заявка (ще я наречем Заявка 1) използва множество вложени слоеве от извлечени таблици, където всеки от изразите на таблицата прилага основна логика на филтриране въз основа на константи:
ИЗБЕРЕТЕ идентификатор на поръчка, дата на поръчкаFROM ( SELECT * FROM ( SELECT * FROM ( SELECT * FROM Sales.Orders WHERE orderdate>='20180101' ) КАТО D1 WHERE дата на поръчка>='20180201' ) КАТО D2 WHERE дата на поръчка>='03'101 КАТО D3WHERE дата на поръчка>='20180401';
Както можете да видите, всеки от изразите на таблицата филтрира диапазон от дати на поръчка, започващи с различна дата. SQL Server премахва тази многослойна логика на заявки, която му позволява след това да обедини четирите филтриращи предиката в един, представляващ пресечната точка на всичките четири предиката.
Разгледайте плана за заявка 1, показан на фигура 1.
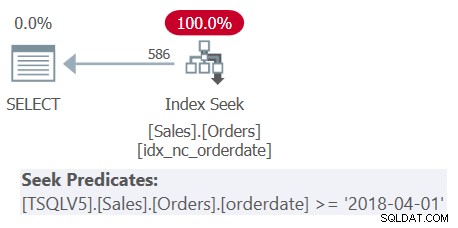 Фигура 1:План за заявка 1
Фигура 1:План за заявка 1
Забележете, че всичките четири филтриращи предиката са обединени в един предикат, представляващ пресечната точка на четирите. Планът прилага търсене в индекса idx_nc_orderdate въз основа на единичния обединен предикат като предикат за търсене. Този индекс е дефиниран на orderdate (изрично), orderid (имплицитно поради наличието на клъстериран индекс на orderid) като ключове на индекса.
Също така имайте предвид, че въпреки че всички таблични изрази използват SELECT * и само най-външната заявка проектира двете колони от интерес:orderdate и orderid, гореспоменатият индекс се счита за покриващ. Както обясних в част 3, за оптимизационни цели, като избор на индекс, SQL Server игнорира колоните от изразите на таблицата, които в крайна сметка не са релевантни. Не забравяйте обаче, че трябва да имате разрешения, за да заявите тези колони.
Както споменахме, SQL Server ще се опита да отмени таблични изрази, но ще избегне разпръскването, ако се натъкне на инхибитор на разместване. С известно изключение, което ще опиша по-късно, използването на TOP или OFFSET FETCH ще попречи на разместването. Причината е, че опитът за премахване на табличен израз с TOP или OFFSET FETCH може да доведе до промяна в значението на оригиналната заявка.
Като пример разгледайте следната заявка (ще я наречем Заявка 2):
ИЗБЕРЕТЕ идентификатор на поръчка, дата на поръчкаFROM ( SELECT TOP (9223372036854775807) * FROM ( SELECT TOP (9223372036854775807) * FROM ( SELECT TOP (92233372036854775807) Ord OD WHER) ' ) КАТО D2 WHERE дата на поръчка>='20180301' ) КАТО D3WHERE дата на поръчка>='20180401';
Входящият брой редове към TOP филтъра е стойност, въведена от BIGINT. В този пример използвам максималната BIGINT стойност (2^63 – 1, изчисли в T-SQL, използвайки SELECT POWER(2., 63) – 1). Въпреки че вие и аз знаем, че нашата таблица с поръчки никога няма да има толкова много редове и следователно филтърът TOP е наистина безсмислен, SQL Server трябва да вземе предвид теоретичната възможност филтърът да бъде смислен. Следователно SQL Server не премахва табличните изрази в тази заявка. Планът за заявка 2 е показан на фигура 2.
 Фигура 2:План за заявка 2
Фигура 2:План за заявка 2
Инхибиторите на разместването попречиха на SQL Server да може да обедини предикатите за филтриране, което кара формата на плана да наподобява по-близко концептуалната заявка. Интересно е обаче да се отбележи, че SQL Server все още игнорира колоните, които в крайна сметка не са от значение за най-външната заявка, и следователно е в състояние да използва покриващия индекс на дата на поръчка, orderid.
За да илюстрираме защо TOP и OFFSET-FETCH са инхибитори на разгръщането, нека вземем проста техника за оптимизиране на предикат надолу. Избутване на предикат означава, че оптимизаторът избутва предикат на филтър до по-ранна точка в сравнение с първоначалната точка, в която се появява при обработката на логическа заявка. Например, да предположим, че имате заявка както с вътрешно съединение, така и с филтър WHERE, базиран на колона от една от страните на съединението. По отношение на обработката на логическа заявка, филтърът WHERE трябва да бъде оценен след присъединяването. Но често оптимизаторът ще изтласка предиката на филтъра на стъпка преди присъединяването, тъй като това оставя присъединяването с по-малко редове за работа, което обикновено води до по-оптимален план. Не забравяйте обаче, че такива трансформации са разрешени само в случаите, когато значението на оригиналната заявка е запазено, в смисъл, че е гарантирано, че ще получите правилния набор от резултати.
Помислете за следния код, който има външна заявка с филтър WHERE спрямо извлечена таблица, която от своя страна се основава на табличен израз с TOP филтър:
ИЗБЕРЕТЕ идентификатор на поръчка, дата на поръчкаFROM ( ИЗБЕРЕТЕ ТОП (3) * ОТ Sales.Orders ) КАТО DWHERE дата на поръчка>='20180101';
Тази заявка, разбира се, е недетерминирана поради липсата на клауза ORDER BY в израза на таблицата. Когато го стартирах, SQL Server получи достъп до първите три реда с дати на поръчка по-рано от 2018 г., така че получих празен набор като изход:
ordeid orderdate----------- ----------(0 засегнати реда)
Както споменахме, използването на TOP в табличния израз предотврати разместването/заместването на табличния израз тук. Ако SQL Server беше премахнал табличния израз, процесът на заместване щеше да доведе до еквивалент на следната заявка:
ИЗБЕРЕТЕ TOP (3) orderid, orderdateFROM Sales.OrdersWHERE orderdate>='20180101';
Тази заявка също е недетерминистична поради липсата на клауза ORDER BY, но очевидно има различно значение от оригиналната заявка. Ако в таблицата Sales.Orders има поне три поръчки, направени през 2018 г. или по-късно – и това е така – тази заявка непременно ще върне три реда, за разлика от оригиналната заявка. Ето резултата, който получих, когато изпълних тази заявка:
дата на поръчката----------- ----------10400 2018-01-0110401 2018-01-0110402 2018-01-02 (3 реда засегнати)
В случай, че недетерминистичният характер на горните две заявки ви обърка, ето пример с детерминирана заявка:
ИЗБЕРЕТЕ идентификатор на поръчка, orderdateFROM ( SELECT TOP (3) * FROM Sales.Orders ORDER BY orderid ) AS DWHERE orderdate>='20170708'ORDER BY orderid;
Изразът на таблицата филтрира трите поръчки с най-ниски идентификатори. След това външната заявка филтрира от тези три поръчки само тези, които са били направени на или след 8 юли 2017 г. Оказва се, че има само една отговаряща на условията поръчка. Тази заявка генерира следния изход:
поръчка дата----------- ----------10250 2017-07-08 (1 ред засегнат)
Да предположим, че SQL Server е премахнал табличния израз в оригиналната заявка, като процесът на заместване води до следния еквивалент на заявка:
ИЗБЕРЕТЕ ТОП (3) orderid, orderdateFROM Sales.OrdersWHERE orderdate>='20170708'ORDER BY orderid;
Значението на тази заявка е различно от оригиналната заявка. Тази заявка първо филтрира поръчките, направени на или след 8 юли 2017 г., и след това филтрира първите три сред тези с най-ниски идентификатори на поръчки. Тази заявка генерира следния изход:
дата на поръчката----------- ----------10250 2017-07-0810251 2017-07-0810252 2017-07-09 (3 реда засегнати)
За да избегнете промяна на значението на оригиналната заявка, SQL Server не прилага разместване/замяна тук.
Последните два примера включваха проста комбинация от филтриране WHERE и TOP, но може да има допълнителни конфликтни елементи, произтичащи от разместването. Например, какво ще стане, ако имате различни спецификации за подреждане в израза на таблицата и външната заявка, като в следния пример:
ИЗБЕРЕТЕ идентификатор на поръчка, orderdateFROM ( SELECT TOP (3) * FROM Sales.Orders ORDER BY orderdate DESC, orderid DESC ) КАТО DORDER BY orderid;
Разбирате, че ако SQL Server отстрани табличния израз, свивайки двете различни спецификации за подреждане в една, получената заявка би имала различно значение от оригиналната заявка. Той или би филтрирал грешните редове, или би представил редовете с резултати в грешен ред на представяне. Накратко, разбирате защо безопасното нещо за SQL Server е да избягва разместването/заместването на таблични изрази, които се основават на заявки TOP и OFFSET-FETCH.
Споменах по-рано, че има изключение от правилото, че използването на TOP и OFFSET-FETCH предотвратява разместването. Това е, когато използвате TOP (100) PERCENT в израз на вложена таблица, със или без клауза ORDER BY. SQL Server осъзнава, че няма реално филтриране и оптимизира опцията. Ето пример, демонстриращ това:
ИЗБЕРЕТЕ идентификатор на поръчка, дата на поръчка ОТ ( ИЗБЕРЕТЕ ВЪРХА (100) ПРОЦЕНТ * ОТ ( ИЗБЕРЕТЕ ТОП (100) ПРОЦЕНТ * ОТ ( ИЗБЕРЕТЕ ТОП (100) ПРОЦЕНТ * ОТ Продажби. Поръчки WHERE дата на поръчка>='20180101' ) КАТО D1 WHERE дата на поръчка> ='20180201' ) КАТО D2 WHERE дата на поръчка>='20180301' ) КАТО D3WHERE дата на поръчка>='20180401';
ТОП филтърът се игнорира, разместването се извършва и получавате същия план като този, показан по-рано за заявка 1 на фигура 1.
Когато използвате OFFSET 0 ROWS без клауза FETCH в израз на вложена таблица, също няма реално филтриране. Така че теоретично SQL Server би могъл да оптимизира и тази опция и да активира разместването, но към датата на това писане не го прави. Ето пример, демонстриращ това:
ИЗБЕРЕТЕ идентификатор на поръчка, дата на поръчкаFROM ( SELECT * FROM ( SELECT * FROM ( SELECT * FROM Sales.Orders WHERE orderdate>='20180101' ORDER BY (SELECT NULL) OFFSET 0 ROWS ) КАТО D1 WHERE дата на поръчка>='20180101' (ИЗБЕРЕТЕ NULL) ОТМЕСТВАНЕ 0 РЕДА ) КАТО D2 WHERE дата на поръчка>='20180301' ПОРЪЧАЙТЕ ПО (ИЗБЕРЕТЕ NULL) ОТМЕСТВАНЕ 0 РЕДА ) КАТО D3WHERE дата на поръчка>='20180401';
Получавате същия план като този, показан по-рано за заявка 2 на фигура 2, което показва, че не е имало разместване.
По-рано обясних, че процесът на разместване/заместване всъщност не генерира нов низ на заявка, който след това се оптимизира, а е свързан по-скоро с трансформациите, които SQL Server прилага към дървото на логическите оператори. Има разлика между начина, по който SQL Server оптимизира заявка с изрази на вложени таблици спрямо действителна логически еквивалентна заявка без влагането. Използването на таблични изрази като извлечени таблици, както и подзаявки предотвратява простата параметризация. Припомнете си заявка 1, показана по-рано в статията:
ИЗБЕРЕТЕ идентификатор на поръчка, дата на поръчкаFROM ( SELECT * FROM ( SELECT * FROM ( SELECT * FROM Sales.Orders WHERE orderdate>='20180101' ) КАТО D1 WHERE дата на поръчка>='20180201' ) КАТО D2 WHERE дата на поръчка>='03'101 КАТО D3WHERE дата на поръчка>='20180401';
Тъй като заявката използва извлечени таблици, простата параметризация не се извършва. Тоест SQL Server не заменя константите с параметри и след това оптимизира заявката, а оптимизира заявката с константите. С предикати, базирани на константи, SQL Server може да обедини пресичащите се периоди, което в нашия случай доведе до един предикат в плана, както е показано по-рано на Фигура 1.
След това помислете за следната заявка (ще я наречем Заявка 3), която е логически еквивалент на Заявка 1, но където сами прилагате разместването:
ИЗБЕРЕТЕ идентификатор на поръчката, orderdateFROM Sales.OrdersWHERE orderdate>='20180101' AND orderdate>='20180201' AND orderdate>='20180301' AND orderdate>='20180401';
Планът за тази заявка е показан на Фигура 3.
 Фигура 3:План за заявка 3
Фигура 3:План за заявка 3
Този план се счита за безопасен за проста параметризация, така че константите се заменят с параметри и следователно предикатите не се обединяват. Мотивацията за параметризиране е, разбира се, увеличаване на вероятността за повторно използване на план при изпълнение на подобни заявки, които се различават само по константите, които използват.
Както споменахме, използването на извлечени таблици в заявка 1 предотврати простата параметризация. По същия начин, използването на подзаявки би предотвратило простата параметризация. Например, ето нашата предишна заявка 3 с безсмислен предикат, базиран на подзаявка, добавена към клаузата WHERE:
SELECT orderid, orderdateFROM Sales.OrdersWHERE orderdate>='20180101' AND orderdate>='20180201' AND orderdate>='20180301' AND orderdate>='20180402' AND (SELECT 42Този път не се извършва проста параметризация, което позволява на SQL Server да обедини пресичащите се периоди, представени от предикатите, с константите, което води до същия план, както е показано по-рано на Фигура 1.
Ако имате заявки с таблични изрази, които използват константи, и за вас е важно SQL Server да е параметрирал кода и поради някаква причина не можете да го параметризирате сами, не забравяйте, че имате възможност да използвате принудителна параметризация с ръководство за план. Като пример, следният код създава такова ръководство за план за заявка 3:
ДЕКЛАРИРАНЕ @stmt КАТО NVARCHAR(MAX), @params КАТО NVARCHAR(MAX); EXEC sys.sp_get_query_template @querytext =N'SELECT orderid, orderdateFROM ( SELECT * FROM ( SELECT * FROM ( SELECT * FROM Sales.Orders WHERE дата на поръчка>=''20180101'' ) КАТО D1 WHERE дата на поръчка>=''20180201'') КАТО D2 WHERE дата на поръчка>=''20180301'' ) КАТО D3WHERE дата на поръчка>=''20180401'';', @templatetext =@stmt ИЗХОД, @parameters =@params ИЗХОД; EXEC sys.sp_create_plan_guide @name =N'TG1', @stmt =@stmt, @type =N'TEMPLATE', @module_or_batch =NULL, @params =@params, @hints =N'ОПЦИЯ(ПАРАМЕТЕРИЗАЦИЯТА ПРИСИЛНА)';Стартирайте отново заявка 3, след като създадете ръководството за план:
ИЗБЕРЕТЕ идентификатор на поръчка, дата на поръчкаFROM ( SELECT * FROM ( SELECT * FROM ( SELECT * FROM Sales.Orders WHERE orderdate>='20180101' ) КАТО D1 WHERE дата на поръчка>='20180201' ) КАТО D2 WHERE дата на поръчка>='03'101 КАТО D3WHERE дата на поръчка>='20180401';Получавате същия план като показания по-рано на Фигура 3 с параметризираните предикати.
Когато сте готови, изпълнете следния код, за да пуснете ръководството за план:
EXEC sys.sp_control_plan_guide @operation =N'DROP', @name =N'TG1';Предотвратяване на разглобяването
Не забравяйте, че SQL Server отменя таблични изрази от съображения за оптимизация. Целта е да се увеличи вероятността за намиране на план с по-ниска цена в сравнение с без разглобяване. Това е вярно за повечето правила за трансформация, прилагани от оптимизатора. Въпреки това, може да има някои необичайни случаи, в които бихте искали да предотвратите разглобяването. Това може да бъде или за избягване на грешки (да, в някои необичайни случаи разглобяването може да доведе до грешки) или поради причини за производителност, за да се наложи определена форма на план, подобно на използването на други съвети за производителност. Не забравяйте, че имате лесен начин да предотвратите разглобяването, като използвате TOP с много голямо число.
Пример за избягване на грешки
Ще започна със случай, при който премахването на таблични изрази може да доведе до грешки.
Помислете за следната заявка (ще я наречем Заявка 4):
ИЗБЕРЕТЕ идентификатор на поръчка, идентификатор на продукт, отстъпкаFROM Sales.OrderDetailsWHERE отстъпка> (ИЗБЕРЕТЕ МИН.(отстъпка) ОТ Sales.OrderDetails) И 1.0 / отстъпка> 10.0;Този пример е малко измислен в смисъл, че е лесно да се пренапише втория предикат на филтъра, така че никога да не доведе до грешка (отстъпка <0,1), но за мен е удобен пример, за да илюстрирам моята гледна точка. Отстъпките са неотрицателни. Така че дори ако има редове за поръчки с нулева отстъпка, заявката трябва да ги филтрира (първият предикат на филтъра казва, че отстъпката трябва да е по-голяма от минималната отстъпка в таблицата). Въпреки това, няма гаранция, че SQL Server ще оцени предикатите в писмен ред, така че не можете да разчитате на късо съединение.
Разгледайте плана за заявка 4, показан на фигура 4.
Фигура 4:План за заявка 4
Обърнете внимание, че в плана предикатът 1.0 / отстъпка> 10.0 (вторият в клаузата WHERE) се оценява преди предикатната отстъпка> <резултат от подзаявка> (първото в клаузата WHERE). Следователно тази заявка генерира грешка при деление на нула:
Съобщение 8134, ниво 16, състояние 1 Възникна грешка при разделяне на нула.Може би си мислите, че можете да избегнете грешката, като използвате извлечена таблица, разделяйки задачите за филтриране на вътрешна и външна, така:
ИЗБЕРЕТЕ идентификатор на поръчка, идентификатор на продукт, отстъпкаFROM ( SELECT * FROM Sales.OrderDetails WHERE отстъпка> (ИЗБЕРЕТЕ MIN(discount) FROM Sales.OrderDetails) ) КАТО DWHERE 1.0 / отстъпка> 10.0;Въпреки това SQL Server прилага разместване на получената таблица, което води до същия план, показан по-рано на Фигура 4, и следователно този код също се проваля с грешка при деление на нула:
Съобщение 8134, ниво 16, състояние 1 Възникна грешка при разделяне на нула.Проста поправка тук е да се въведе инхибитор на разместване, като така (ще наречем това решение Заявка 5):
ИЗБЕРЕТЕ идентификатор на поръчката, идентификатор на продукт, отстъпка ОТ ( ИЗБЕРЕТЕ ТОП (9223372036854775807) * ОТ Sales.OrderDetails КЪДЕ отстъпка> (ИЗБЕРЕТЕ МИН.(отстъпка) ОТ Sales.OrderDetails) ) КАТО DWHERE 1.0 / отстъпка> 10.0;Планът за заявка 5 е показан на фигура 5.
Фигура 5:План за заявка 5
Не се обърквайте от факта, че изразът 1.0 / отстъпка се появява във вътрешната част на оператора Nested Loops, сякаш се оценява първи. Това е само определението на члена Expr1006. Действителната оценка на предиката Expr1006> 10.0 се прилага от оператора Filter като последна стъпка в плана, след като редовете с минимална отстъпка са били филтрирани от оператора Nested Loops по-рано. Това решение работи успешно без грешки.
Пример за съображения за ефективност
Ще продължа със случай, при който премахването на таблични изрази може да навреди на производителността.
Започнете, като изпълните следния код, за да превключите контекста към базата данни PerformanceV5 и да активирате STATISTICS IO и TIME:
ИЗПОЛЗВАЙТЕ PerformanceV5; ЗАДАВАНЕ НА СТАТИСТИКА IO, ВРЕМЕ ON;Помислете за следната заявка (ще я наречем Заявка 6):
ИЗБЕРЕТЕ shipperid, MAX(orderdate) AS maxodFROM dbo.OrdersGROUP BY shipperid;Оптимизаторът идентифицира поддържащ покриващ индекс с shipperid и orderdate като водещи ключове. Така той създава план с подредено сканиране на индекса, последвано от базиран на поръчка оператор Stream Aggregate, както е показано в плана за заявка 6 на фигура 6.
Фигура 6:План за заявка 6
Таблицата „Поръчки“ има 1 000 000 реда, а групиращата колона shipperid е много плътна — има само 5 отделни идентификатора на изпращача, което води до 20% плътност (среден процент за отделна стойност). Прилагането на пълно сканиране на индексния лист включва четене на няколко хиляди страници, което води до време за изпълнение от около една трета от секундата на моята система. Ето статистическите данни за производителността, които получих за изпълнението на тази заявка:
Време на процесора =344 мс, изминало време =346 мс, логически четения =3854Индексното дърво в момента е дълбоко на три нива.
Нека мащабираме броя на поръчките с коефициент от 1 000 до 1 000 000 000, но все пак само с 5 отделни изпращачи. Броят на страниците в индексния лист ще нарасне с коефициент 1000 и индексното дърво вероятно ще доведе до едно допълнително ниво (дълбоко четири нива). Този план има линейно мащабиране. В крайна сметка ще получите близо 4 000 000 логически четения и време за изпълнение от няколко минути.
Когато трябва да изчислите MIN или MAX агрегат спрямо голяма таблица, с много висока плътност в колоната за групиране (важно!) и поддържащ индекс на B-дърво, насочен върху колоната за групиране и колоната за агрегиране, има много по-оптимално форма на план от тази на фигура 6. Представете си форма на план, която сканира малкия набор от идентификационни номера на изпращача от някакъв индекс в таблицата Изпращачи и в цикъл прилага за всеки изпращач търсене срещу поддържащия индекс на Поръчки за получаване на съвкупността. При 1 000 000 реда в таблицата 5 търсения ще включват 15 четения. При 1 000 000 000 реда 5 търсения ще включват 20 четения. С трилион реда, общо 25 четения. Ясно е, че много по-оптимален план. Можете действително да постигнете такъв план, като направите заявка в таблицата на изпращачите и получите агрегата с помощта на скаларна обобщена подзаявка срещу поръчки, като така (ще наречем това решение Заявка 7):
ИЗБЕРЕТЕ S.shipperid, (ИЗБЕРЕТЕ MAX(O.orderdate) ОТ dbo.Orders AS O WHERE O.shipperid =S.shipperid) AS maxodFROM dbo.Shippers AS S;Планът за тази заявка е показан на Фигура 7.
Фигура 7:План за заявка 7
Желаната форма на плана е постигната и числата на производителността за изпълнението на тази заявка са незначителни, както се очаква:
Време на процесора =0 мс, изминало време =0 мс, логически четения =15Докато колоната за групиране е много гъста, размерът на таблицата „Поръчки“ става практически незначителен.
Но изчакайте малко, преди да тръгнете да празнувате. Има изискване да се запазят само изпращачите, чиято максимална свързана дата на поръчка в таблицата с поръчки е на или след 2018 г. Звучи като достатъчно просто допълнение. Дефинирайте извлечена таблица въз основа на Заявка 7 и приложете филтъра във външната заявка по този начин (ще наречем това решение Заявка 8):
ИЗБЕРЕТЕ shipperid, maxodFROM ( SELECT S.shipperid, (SELECT MAX(O.orderdate) FROM dbo.Orders AS O WHERE O.shipperid =S.shipperid) AS maxod FROM dbo.Shippers AS S ) КАТО DWHERE maxod>='20180101';Уви, SQL Server отключва извлечената заявка за таблица, както и подзаявката, преобразувайки логиката на агрегиране в еквивалента на логиката на групирана заявка, с shipperid като колона за групиране. И начинът, по който SQL Server знае да оптимизира групирана заявка, се основава на едно преминаване върху входните данни, което води до план, много подобен на този, показан по-рано на Фигура 6, само с допълнителен филтър. Планът за заявка 8 е показан на фигура 8.
Фигура 8:План за заявка 8
Следователно, мащабирането е линейно и числата на производителността са подобни на тези за заявка 6:
Време на процесора =328 мс, изминало време =325 мс, логически четения =3854Поправката е да се въведе инхибитор на разместване. Това може да стане чрез добавяне на TOP филтър към израза на таблицата, на който се базира получената таблица, по този начин (ще наречем това решение Заявка 9):
ИЗБЕРЕТЕ shipperid, maxodFROM ( SELECT TOP (9223372036854775807) S.shipperid, (SELECT MAX(O.orderdate) FROM dbo.Orders AS O WHERE O.shipperid =S.shipperid) AS maxod FROM dbo.Shippers AS S ) DWHERE maxod>='20180101';Планът за тази заявка е показан на фигура 9 и има желаната форма на план с търсенията:
Фигура 9:План за заявка 9
Тогава, разбира се, числата на производителност за това изпълнение са незначителни:
Време на процесора =0 мс, изминало време =0 мс, логически четения =15Друга възможност е да предотвратите разместването на подзаявката, като замените агрегата MAX с еквивалентен TOP (1) филтър, като така (ще наречем това решение Заявка 10):
ИЗБЕРЕТЕ shipperid, maxodFROM ( ИЗБЕРЕТЕ S.shipperid, (SELECT TOP (1) O.orderdate FROM dbo.Orders AS O WHERE O.shipperid =S.shipperid ORDER BY O.orderdate DESC) AS maxod FROM dbo.Shippers AS S ) КАТО DWHERE maxod>='20180101';Планът за тази заявка е показан на Фигура 10 и отново има желаната форма с търсенията.
Фигура 10:План за заявка 10
Получих познатите незначителни числа на производителност за това изпълнение:
Време на процесора =0 мс, изминало време =0 мс, логически четения =15Когато сте готови, изпълнете следния код, за да спрете да отчитате статистически данни за ефективността:
ЗАДАВАНЕ НА СТАТИСТИКА IO, TIME OFF;Резюме
В тази статия продължих дискусията, която започнах миналия месец относно оптимизирането на извлечените таблици. Този месец се съсредоточих върху разместването на производни таблици. Обясних, че обикновено разглобяването води до по-оптимален план в сравнение с без разглобяване, но също така обхванах примери, когато това е нежелателно. Показах пример, при който разместването доведе до грешка, както и пример, водещ до влошаване на производителността. Демонстрирах как да се предотврати разпръскването чрез прилагане на инхибитор на разпръскване като TOP.
Следващия месец ще продължа изследването на изрази за таблици с имена, като преместя фокуса върху CTEs.